[MODERATOR] Yes, they asked me to chair this session, and it also means I'll just be timing people, so we'll start with Josh first. [JOSH BERKE] Thanks. Thanks for the introduction.
And thanks for the organizers for inviting me to come. Um, I'm just gonna briefly mention that some of the work I'm gonna present was done by three very talented post-docs in my lab: Ali Mohebi, Arif Hamid, and Jeff Pettibone. And I'm also gonna introduce or reintroduce the idea that there are different learning systems in the brain that operate using fundamentally different algorithms.
Uh, I'm also gonna totally ignore the hippocampus because no one cares about the hippocampus. Um, so the, the specific system that I'm gonna talk about today is really basal ganglia-centered and uses a reinforcement learning algorithm, and I'm gonna talk about what that, that means. But the idea of introducing that there are different organization of circuits and micro-circuit architecture that's specialized for extracting different features of your experience and processing them in different ways, specifically for reinforcement learning.
And we've known, see, one of the introductions to this field comes from maybe the '50s and the discovery there are certain places in the brain that you can wire up to a lever and rats will rapidly learn to tickle their own brains in certain places and not others. And while there are many places in the brains that works really, they're clustered around the mesolimbic dopamine system. And the key thing to remember about this situation is that rats will both learn to push a lever to tickle their own brains and then they'll be highly motivated to go ahead and do it again and again and again, often at the exclusion of other activities.
And I'm gonna really go through the introductory slides fast because I'm sure most people, maybe not everyone, has heard about this projection. It's a famous projection from the midbrain, dopamine cell bodies sending their axons to various forebrain places, but especially the striatum. And famous work by Wolfram Schultes, which I promised Ila I would not spend more than a couple minutes discussing-- --uh, was really in the eight-, starting in the '80s and '90s showed the following kind of phenomenon, that a dopamine cell, if you give a unexpected f-- f-- A squirt of fruit juice into the monkey's mouth, will fire a burst of spikes, but as that fruit juice squirt becomes predicted, expected, the dopamine cell stops responding to it and instead responds to a cue that predicts that fruit juice.
So even though the monkey still likes the juice and still avidly licks the juice, its dopamine cell doesn't fire here. So there, and it's also not just about making a prediction of future rewarders, about predictions in time, for this is tick marks of one dopamine cell firing, and if you delay the juice, you see a pause in firing followed by a burst when the juice comes. If you bring the juice too early, you get the burst of firing early and so forth.
All right, so the current highly dominant paradigm this field is that dopamine cells signal a reward prediction error. Talk about that. So if you're gonna calculate reward prediction error, you need a reward prediction, right?
And in turn, the point of a reward prediction error is to update your predictions, right? It's a learning signal. It's there to do updating.
And, you know, the way that this was conceived of by people, especially Schultes, was that there was this sort of globally broadcast signal from the midbrain to the forebrain that was really all one big signal, scale or signal. All right. And one reason why this has been such a influential and powerful paradigm is it explains all kinds of results at multiple levels of analysis.
This is just one example from Kasai group looking at growth of individual spines on the dendrites of striatal neurons and showing that if you have this triple conjunction of glutamate uncaging onto that spine and postsynaptic depolarization and timed dopamine input happening together, then you can cause this spine to grow in real time. You can see it growing. All right?
And the dopamine has to come in at just the right time to make this happen within about a second or so. All right. So one of the reasons this has been such a successful marriage between neuroscience and computer science is that you can actually do useful stuff with reinforcement learning, and it's become extremely influential.
A lot of the current developments in AI use reinforcement learning in one way or another, and some of it you know, especially in a computing institute, I'm not qualified to give a proper lecture on computing of reinforcement learning, but I'll just give some very basic ideas you need to know. So the idea of an agent that can be in one of a set of discrete different states, all right? And each of these states has associated value, and a value is defined here as an expectation of future reward from that state discounted in time, and I'll come back to that.
All right, and if you transition between states to a state with unexpected value, then that jump in value is a reward prediction error, right? That sudden transition in values. So you're sitting around and suddenly a cue comes on saying, "Reward's coming up.
" Right? You jumped to a different state with different value, that jump is the reward prediction error, right? And then you use that reward prediction error to update the values of states or states and actions.
Okay. And as I mentioned, this has become very powerful and useful to do things like beat me at Go. And so one way of thinking about the brain, or at least this subsystem within the brain, that the cerebral cortex is there to represent states, like what state am I in, and to distinguish, discriminate different states, and then the striatum basal ganglia is here to paint those states with different values.
Given I'm in this state, how much reward do I expect to get? And the point of the dopamine signal is to come in and modify the synapses here in order to modify and update the weights corresponding to values. All right?
[AUDIENCE MEMBER] Is there a better laser pointer? [JOSH BERKE] You gonna ask me to do a two-handed? This one?
Well, how, can I use this one? [AUDIENCE MEMBER] Oh, you can use it. You're the best.
All right. I was showing him. [JOSH BERKE] Okay.
Now it's challenging, right. So, there's a problem with this, which is that this is a wonderful, absolutely wonderful framework, but it doesn't explain some of the core things we know to be true about dopamine, which is dopamine is not just there as a learning signal. All right?
So there's lots of results that say dopamine also is motivating, energizing, invigorating, and it's really important to emphasize that everyone agrees that's true, but that is no part in this framework. All right? So something is missing.
Watch this. We can talk about that. So one way of thinking about this question is you have an agent taking actions interacting with an environment and getting feedback about the environment, right?
So it's done-- It's still fundamentally about this feedback, this learning, this updating role, or is it fundamentally about motivating, invigorating effects on online ongoing performance? Right? Is that reasonably clear?
And if it does both of those things, how does the system not get confused? So if you have stridal neurons say listening to dopamine, we know dopamine can do lots of things to stridal neurons. It can affect synaptic plasticity, as I showed you, but also changes excitability of neurons, affects many iron channels.
So do you, how do you know whether to use dopamine as an invigorating, exciting signal or as a synaptic plasticity signal or what? Right? So the field has not really addressed this properly, but tends to do the following.
It says, "Well, dopamine does both of these things but on different time scales. " All right? So fast so-called phasic fluctuations in dopamine are supposed to be these reward prediction errors, whereas slower changes somehow do motivation.
And no one who talks about tonic dopamine ever defines what time scale they're talking about. Right? They just say, "Whatever time scale you're measuring with slow techniques like microdialysis.
" So the specific-- a more specific set of ideas from Niv, Dor, and Dayan is that the tonic dopamine level does not just motivation in general, but specifically signals the rate at which you're getting rewarded. This is a useful thing. If you engage in some activity and you're getting three rewards per minute, maybe that's worth continuing on more than some other activity that only gives you two rewards per minute.
[AUDIENCE MEMBER] All right? [JOSH BERKE] So it's a useful decision variable deciding whether it's worthwhile to be engaged in some task or not. All right.
So I'm gonna, some of the data I'm gonna present is trying to test some of these ideas and update them. And most stuff in my lab, not everything looks like this. There's a rat in box with some holes and some stuff in his head.
And the task I'm gonna talk about looks like this. A light comes on in one of those holes and the rat has to stick his nose in it, and it takes him some time to go and stick his nose in the hole that's lit up. I'm gonna call that time the latency.
All right? And then he waits there, and he's waiting for a variable period of time And then he gets a go cue which is just the white noise burst, and he pulls out and he makes a choice. He can stick his nose in the left hole, immediately to the left or immediately to the right, and sometimes as he enters that side hole, he hears a click which is the sound of a sugar pellet being delivered behind him.
Right? And then he can go eat it if there's a sugar pellet. And it's a bandit task or a probabilistically rewarded task, and the probabilities for getting reward for choosing left or right change every now and then without telling the rat, and he has to adapt his behavior accordingly.
All right, so in this little sample of data here, a tall tick means he got reward and a short tick means he didn't. So he tried left, got a reward, tried left again, no reward, left again, no reward, let's try right, no reward, and so forth. And these are the nominal block probabilities here.
So a full session of behavior might look something like this. These are the changing probabilities of reward and I hope you can see with a little squinting that the rat is adjusting his choices between left and right to whichever option is better at a given time. But he's not just adjusting his left and right choices, he's also adjusting his motivation to play the game.
So if we ignore whether it was left or right and just look at the density of rewards, sometimes he's getting a high density of rewards and sometimes a lower-- Sorry, I'm using the-- It should be there. Sorry. Sorry.
Okay, now you can really see. He's using a lower density of rewards and on the flipped scale here is the sort of latency, so when he's getting a high density of rewards, his latency to engage in the next trial is shorter. All right?
This is one session of performance. Easier to see this way. [AUDIENCE MEMBER] Just a clarification question.
Yeah. Is the reward, does the pellet remain in the bin until he harvests it? Yes, it [JOSH BERKE] Does.
[AUDIENCE MEMBER] So then there is an advantage to going to the 10% bin for example? [JOSH BERKE] Oh, I'm sorry. Or-- So it's not the case that on each trial we give a reward whether he goes there or not and then he can go harvest it.
Yeah. So he only gets delivery of the reward if he makes that choice. [AUDIENCE MEMBER] Okay, so it's matching, not maximizing.
That's right. Okay. I think.
[JOSH BERKE] Yes. So yes, that would change the model, internal model the animal would use in interesting ways and we actually are playing around with that, but this way it's very simple. So here's his adapting his choice.
So as he enters a block of trials where left is much better he switches his choices over to left and vice versa for right, and here's his vigor or latency data. So if he's got lots of rewards recently, 10 out of the last 10 were rewarded, he's really quick to initiate the next trial, and if he hasn't been rewarded any of the last 10, why should he bother? He's really slow to initiate the next trial.
[AUDIENCE MEMBER] Josh? [JOSH BERKE] Yeah. [AUDIENCE MEMBER] I'm confused by the ratios there.
What's 90/50? [JOSH BERKE] Sorry. Yeah, so 90/10 means that if he chooses left there's a 90% chance he'll get a reward and if he chooses right, there's only a 10% chance he'll get a [AUDIENCE MEMBER] Reward.
What's 90/50? [JOSH BERKE] 90/50? Yeah.
[AUDIENCE MEMBER] Oh, so it's 90% chance versus 50% chance. Yeah. Okay, so it doesn't add to 100.
Got it. Yeah. But following up on that, so 50/10 has a [JOSH BERKE] Higher So if you compare 90/50 to 50/10, in both cases you're better off going left.
Right? But nonetheless-- Right, just rela-- This one will have a higher absolute chance of getting reward, right? So this way it allows you to dissociate this process of making the better choice versus how valuable is that choice.
All right? So this kind of task's been used before to pull apart action values versus the choice itself. Okay?
Yeah, any more questions about the talk? All right. So you know, I just showed you this thing saying that they're more invigorated or more motivated when they received lots of rewards recently, but how does it actually work?
And you can look at the latency data and se-- and break it down a different way which is to say that after the light comes on, what's the survivor curve or the hazard rate, survivor curve, hazard rate, of initiating an approach behavior at each moment in time? The way the reward history affects his decision making is it changes the instantaneous likelihood he'll decide to approach. All right?
So higher reward history means a, a greater moment by moment chance he'll say, "Okay, I'm gonna make the decision to, to go for it. " Does that make sense? All right.
Now we have this task where we have a reward rates history and we have decisions to play the game and we can see how does dopamine involve in all of this stuff. And we measure dopamine in too many different ways. Five, I think?
Six? Uh, so I'm just gonna start by talking about a couple of them. So we use micro analysis, which is historically a slow method but has the advantage of it's much more specific to dopamine and to other things.
And the way, the fancy way we did it with Bob Kennedy was to measure lots and lots of things in the same one minute time resolution samples. Okay? So this is gonna be our measure of tonic dopamine.
And we also used fast scan cyclic voltammetry, which is much faster, has 10 samples per second it's focused on dopamine but has its own idiosyncrasies, like it usually doesn't work and stuff like that. We can talk about that. So you know, So and this is just one example of one sample recorded from the Ventral Striatum here and you can measure pretty much every major neurotransmitter at the same time within the striatum and all their metabolites, and you can then test various things, so does this concentration of each of these things in a minute by minute sample vary with things like the reward rate, right?
So this is the, just the simple correlation between reward rate and dopamine, and you see among all these things only dopamine and to a smaller extent the metabolite of dopamine have this correlation with the sheer density of rewards that you're getting. So this is something that is indeed --It seems to correlate with reward rate and it's highly specific to dopamine. All right?
And it's not about locomotive activity or explore versus exploit for those who are into these kinds of different ideas. If you just look at the total cumulative reward which could correlate with time or satiety or any kind of things, lots of things care about that, but dopamine does not. All right?
So, in unpublished work we have sort of extended this beyond the ventral striatum and looked lots of different places in the striatum and medial frontal cortex, and what we find is that this correlation between reward rate and dopamine is seen specifically in the accumbens core here and in the ventral part of prelimbic cortex here. And if you go more dorsally or ventrally, in the frontal cortex you don't see it, and if you go more dorsally or ventrally in the striatum you don't see it either. All right?
So this is already a little inconsistent with the sort of idea of a broadcast dopamine signal. Something more specific is happening in specific sub-regions. All right.
And this is sort of your map of hot spots of correlation between dopamine and reward rate, and one thing that I'm not quite sure how much weight to put on but I quite like is if you do like meta-analysis of human fMRI studies and say which parts of the human brain consistently correlate with value, subjective value, then you see two hotspots which are in the ventral striatum and the ventral medial prefrontal cortex which seems to correlate quite nicely to our rat hotspots. I [AUDIENCE MEMBER] Think that's cute. [JOSH BERKE] So, you know, so far this seems consistent with this idea that there's some tonic dopamine signal that can go up and down slowly and correlate with reward rate, but is it really what's going on?
Is there really something slow going on that correlates with motivation and reward rate? And so we look at faster signals as well with voltammetry and it looks like this is a rat performing the task. One of the holes is gonna light up.
He's gonna stick his nose in it. There you go, and then he's gonna make a left/right choice. He went left.
All right. He heard a click. He can go eat his sugar pellet and meanwhile we're measuring sort of real time patterns of dopamine release in the accumbens core here and watch another trial.
So, all right, left/right. Right. Okay.
That time, he didn't hear his click. He's trying again. Okay.
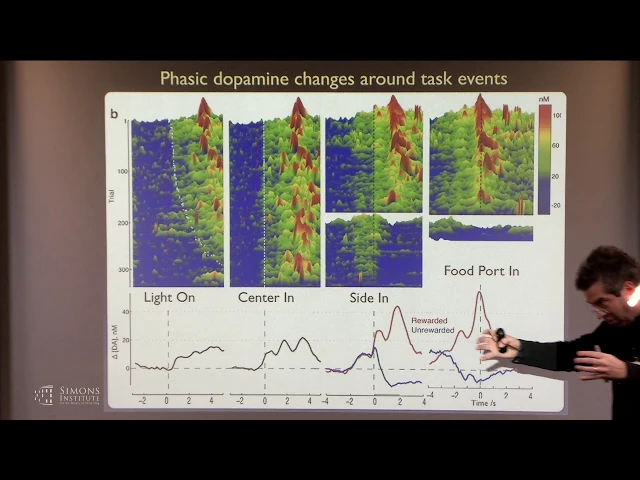
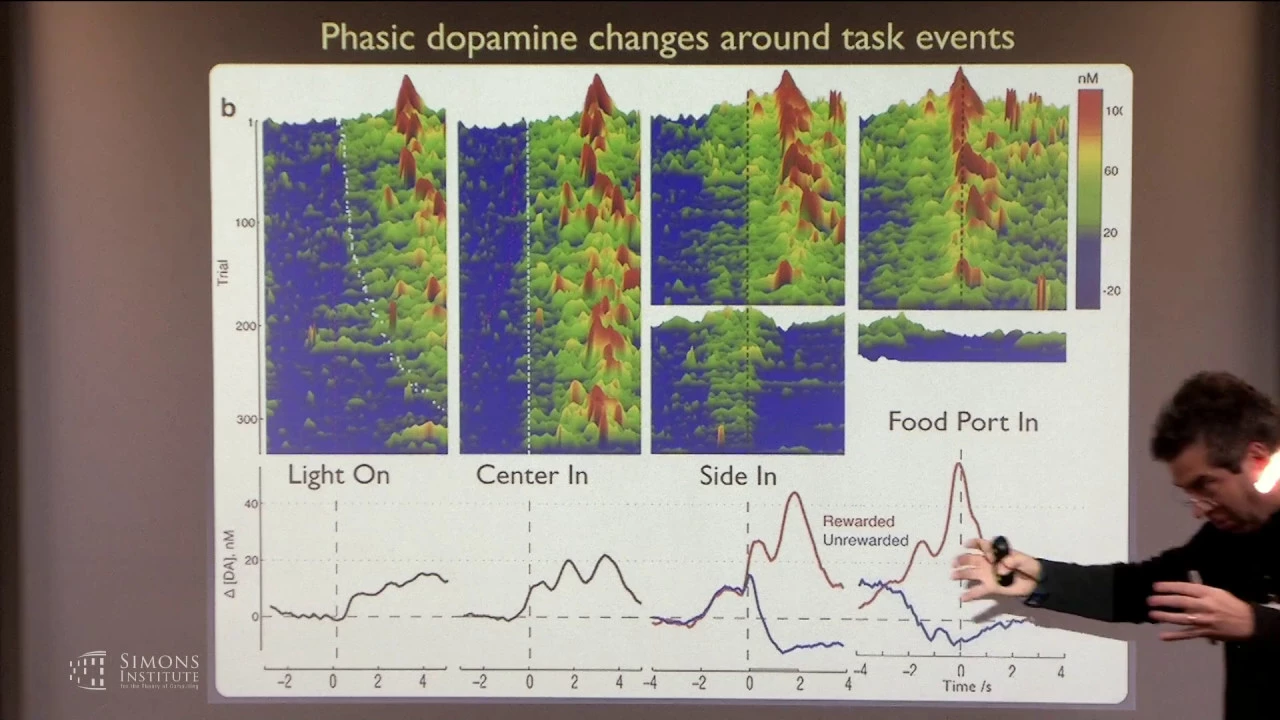
And then we can look at these fluctuations and align them on different events in the task obviously. We can say are there consistent fluctuations that correlate with light on or center in, and what you see is a fast ramping up of dopamine just as he completes his approach. Right?
And then if you break up the data by whether he got a reward or didn't, so at side in he either hears the click or he doesn't. If he does, dopamine goes up fast. If he doesn't, dopamine goes down fast.
But the highest, the peak level of dopamine within a trial in this task is as he runs over to collect his reward, dopamine is getting up, up, up, up, up, and then as he grabs it, dopamine goes down fast. And, you know, obviously you can look at whether this pattern depends upon his reward history, and indeed if he's gotten more rewards recently And then you see a smaller increase in dopamine --Sorry, wrong pointer. All right.
And if he's gotten very few rewards, then the same click of sugar pellet delivery causes a bigger increase in dopamine. So this moment of time seems somewhat consistent with reward prediction errors but other stuff happening in the trial, like as he approaches to begin the trial or as he goes to get his sugar pellet don't seem consistent with this general idea of a reward prediction error. Right?
He's done this task tens of thousands of times. Why should going over to get his now totally predicted sugar pellet have any error associated with [AUDIENCE MEMBER] It? Sorry.
Question. Yeah. So the undershoot that you see when he doesn't get a reward-- Yeah.
That's essentially because it's been ramping just before? Yes. Or does it go below baseline levels?
[JOSH BERKE] Yeah. So when we f-- first started trying to publish this data, we were very much thinking in terms of reward prediction errors, and one of the things that sort of bugged me about this is that it sort of seemed to go down and then stay down rather than bouncing back up nicely, and in fact it goes down and stays down, and I won't I wasn't --I cut out a few slides about that But maybe I'll stick 'em in at the end. But basically, it doesn't really look like a reward prediction error.
It all depends-Let me come back to that. If you're still interested in 10 slides, ask me. I'm just, I'm trying to compress an hour-long talk into All right, so even though some aspects look like a reward prediction error, o-- other aspects don't.
All right? So and this seems consistent with lots of other voluntary studies, right? So here's a ramping up, fast ramp up in dopamine as a rat gets ready to push a lever for cocaine or for food and so forth.
And here's another example Grabiel and Paul Phillips showing a rat running down a maze arm to collect a fully predicted sugar pellet and dopamine is ramping up as he runs down the maze arm. All right? So people have sort of contorted themselves trying to come up with computational counts which this thing which doesn't really look like a prediction error really could be a prediction error.
But I don't find any of those very convincing. Okay, so story so far is we have these past fluctuations of dopamine accompanying motivated approach behaviors that's have some relationship to prediction error and we have this Michael Dallas thing about slowly measured dopamine correlating with reward rate. So are these all different things or are they different aspects of the same thing?
And obviously, I wouldn't phrase it that way unless I thought they were all one thing. [AUDIENCE MEMBER] Josh, can I just ask a question? Yeah.
So this is still in the context of the probabilistic task, right? Yeah. And so what you're saying is that you know, Yeah, It's been, it, maybe this is a phase where there's been a lot of you know, sugar pellets at one of the ports.
Mm-hmm. But nevertheless, there is a probabilistic element to it. Sure.
Right? So there's still some degree of surprise or, you know-- Sure. --probabilistic.
In [JOSH BERKE] The task that we did. I mean, in some of the other tasks like this one, there really wasn't any surprise [AUDIENCE MEMBER] Associated. And so then even so.
[JOSH BERKE] Blah, blah, blah, blah, blah. Okay, and so, you know, in bri-- uh, very brief fashion, I'm gonna make the argument that this fast fluctuations in dopamine are not signaling rule of prediction errors, they're signaling reward predictions in a form of a value function. And I think even David mentioned value functions yesterday.
So what do I mean by that? This is probably obvious to some people, but imagine the sort of abstract situation where an agent has to pass through a sequence of states while remembering to use the right laser pointer. One, two, three, four, five, six in order to get-- And these are unrewarded states in order to get to a reward, right?
Well, it seems pretty obvious it's better to be in state eight than state two because state eight is closer to reward, right? So you can write the value of each state as a time discounted expected future reward. Yes, good.
All right, so the state value, the value of being in each state is how much reward do you expect to get discounted by time. And in some ways the point of a reinforcement learning algorithm is to use your ongoing experience to make estimates and adjust the estimates of how much reward you expect to get. Right?
And this is useful because you have to make decisions. Is it worth engaging in some activity? Well, if you have a higher expectation of reward, obviously it's better to engage in it.
So imagine a sequence where you're uncertain about whether you're gonna get a reward. So this is your value function on the 0. 5 curve, and then you get a cue and the cue says, "Aha, on this trial you're definitely gonna get a reward.
" Right? So your value of being in that state has just jumped up here, right? And the amount of that jump is a reward prediction error, right?
So if you have a higher expectation of reward and now you find out yes, definitely gonna get a reward, it's not very surprising you jump up a little bit. If you had a lower expectation, you get a bigger jump, right? So these are so-called temporal difference reward prediction errors.
They just are shifts in the value function, right? So if you can keep track of value fast, you also get the reward prediction errors. And looks a bit like the dopamine data, but we could, You know, the real task that we use is more complicated 'cause there are variable delays and more events happening.
So we made a model that evolves in real time and we feed in the rat's actual data behavior into the model in order to generate real-time estimates of reward prediction errors and reward predictions. And it looks something like this. The particular set of states used doesn't really matter, you can just feed him the rat behavior and you can do this.
You can generate, look at real time dopamine fluctuations and say, "Do they look like the state values of the model that are evolving in real time or do they look like the reward prediction errors? " And the bottom line is they look a lot more like the state values than they do like the reward prediction errors. Okay.
So I just made the argument to you that if you keep track of value in real time, you can also use that as a, to calculate reward prediction errors and use them for learning. But does the brain actually do that? Right?
So one way we explore this is through optogenetics. So if dopamine is being used as a learning signal, then if you mess with dopamine fast, then what should happen is right now, nothing, but next time you encounter the same situation, your behavior should be different, right? That's what we mean by learning, right?
Whereas if dopamine is about motivation and online performance, then messing with dopamine should affect behavior right now, right? And so we can look at that in the following way. So we can tickle dopamine cells and measure consequent dopamine release in the forebrain here, blah, blah.
And we can give extra pulses of dopamine at different moments within the trial and see whether if we give dopamine at the same time as you turn on this light, is he faster to engage in an approach behavior just as if we boosted his motivation, just as if we'd increased his expectation of reward, right? Or alternatively, if we give extra dopamine here as he finds out whether he's gonna get a reward, do we effectively boost a reward prediction error and reinforce his choice? So if he goes right, is he more likely to go right on the next trial?
Okay. And in fact both of these things happen. So if you look at the hazard rate of approach, so this is the latency and hazard rate.
So giving a train of laser pulses immediately within hundreds of milliseconds affects his online motivated behavior, makes him more likely to engage in an approach, right? It's not a slow learning effect in any way. Conversely, we can reinforce his choices.
So if we give a pulse of dopamine and reward feedback, then on the next trial he's more likely to make the same choice again. This doesn't happen in littermate controls. We can make it go the other way with haloperidol and so forth.
All so we most of what I showed you so far is published. I showed you that reward, so the dynamically change in dopamine signal seems to fluctuate to correspond to reward predictions much more than prediction errors. And that these dopamine signals used to make judgments, decisions about whether it's worthwhile working or not, that the fluctuations of this could be used as reward prediction errors, and we don't really believe in these different time scales of dopamine.
We think there's just dopamine which is fluctuating fast and it can be used for both motivational and learning functions. [AUDIENCE MEMBER] All right. So [JOSH BERKE] But we still have some problems, right?
We still want to account for the Short's data, all right, this kind of thing, saying that dopamine cells encode reward prediction errors even though dopamine release seems to do reward predictions, so wha-- wha-- What's up with that? All right. So a couple of things we've been thinking about.
One is that, you know, the dopamine cell recordings have almost entirely been performed in head-fixed animals performing Pavlovian tasks where they really don't have anything to do except sit there and wait for rewards, so maybe the need to work reflect, is reflected in the dopamine encoding the value of work, okay? And the other possibility is that dopamine cell firing and release are really different things, and both of these seem to be true. [AUDIENCE MEMBER] Okay.
[JOSH BERKE] So one way we've been investigating this by recording identified dopamine cells using optogenetics and here's just to sort of get consonance with the Short's data, we also record the same cells in a more Pavlovian task, and if we give unpredicted food cues, these cells look like Short's cells more or less in response to unexpected rewards. Okay. Then we can record the same cells in our bandit task and see what happens when you get reward cues or absence of cues, and the key things I want to point out are the following.
So one is that these cells together do encode a positive reward prediction error, all right, not a negative reward prediction error for some reason, which seems strange. We could talk about that. But the other thing is that the average firing rate, or the tonic firing rate, doesn't care about reward history at all, all right?
So we have a situation where the tonic firing or the firing of dopamine cells has no relationship to reward history even though dopamine release in the forebrain does. All right. So how do we explain that?
And one more example of a sort of dissociation between dopamine firing and dopamine release is seen here. So as I told you, the animals are sitting and waiting for the go cue and they wait a variable amount of time. So as the animal waits, the dopamine cells start firing less and less and less and less, and this kind of thing has been seen before and interpreted as a negative reward prediction error, all right?
So as you're waiting for the cue, your expectation that the cue's gonna happen in the next moment is going up, up, up, up, right? Surely it's gonna happen now, all right? And so when it doesn't happen, you're more and more disappointed, right?
More and more negative here. All right. I just said that.
So we can look at this either with recording individual cells or groups of cells, and in this fiber photometry experiment, we've been trying to simultaneously record dopamine cell bodies in the VTA and their terminals in the accumbens and seeing if they're the same or different using GCAMP. And using this method, we also see that the cell bodies are going down, down, down, down, down, down, down during this delay period, possibly reflecting a negative prediction error, but the terminals of the same neurons are actually increasing their activity, more like a reward prediction. So we really think this kind of thing is showing us that control of dopamine terminals and release is largely independent of dopamine cell firing and there's a whole field of biology that needs to be explored further here.
All right. So just to wrap up, I just said this dopamine forebrain dopamine release does not simply mirror midbrain dopamine cell firing. We think that local areas sculpt their own dopamine release, and we'd like to know how this happens.
We'd like to know whether striatal neurons are switching modes, sometimes using dopamine as a learning signal and sometimes using it as a motivation signal. Are there many different functions of dopamine in online behavioral control or is there one way that we can computationally bind these together? And the current working hypothesis we have is that dopamine is signaling how worthwhile it is to expend a limited internal resource which could be energy or attention or time.
[AUDIENCE MEMBER] So I'm gonna [JOSH BERKE] Stop there because I'm out of time. (applause) [MODERATOR] We have a couple minutes for questions. [AUDIENCE MEMBER] It's a beautiful talk.
Thank you. I just wondered when I think of the basal ganglia, there's body configuration, there's a gene where the little mouse learns its four key presses as a macro. So I-- I'm-- I'm just wondering if that, if the configuration of the body is a, is a compound for some of your stuff.
And also, this is a naïve question, but I always thought there's lots of flavors of dopamine in there and do, how do you know that you've got the right flavor? [JOSH BERKE] You mean a strawberry flavor? Uh maybe I'm not fully understanding what you mean by flavor.
I mean, I understand that like you mean different-- Well, there's D2, D3. Ah, sure. Sorry.
So absolutely, so there are different receptors that listen to dopamine. Yes. Absolutely.
And so I can certainly talk about how those receptors are listening to dopamine. There's been an idea that the sort of D2 receptors are listening to steady levels of dopamine. There's some evidence that's true, some that it's not.
But either way, whether you're a D1 receptor-bearing cell or a D2, you still have this problem, right, which is what does dopamine mean to you right now? Okay. So you could be trying to separate out these by one set of cells cares about it as motivation, the other learning, but you know, they both have to undergo synaptic plasticity.
In both cases, they have the same fundamental synaptic dendritic architecture. They both have similar learning rules. So I think dopamine is modulating plasticity on both of those cell populations, so yeah.
[AUDIENCE MEMBER] How are you dissociating dopamine neuron firing and dopamine release? [JOSH BERKE] How are we dissociating [AUDIENCE MEMBER] Them? How would you imagine dissociating those two things?
[JOSH BERKE] Hmm, you mean how do I imagine that cells could dis-- I mean, if you were a target cell in striatum, you have no idea what's happening with firing in the midbrain. You just know how much, what the instantaneous concentration of dopamine is, right? [AUDIENCE MEMBER] I thought when a cell fires an action Potential-- Ah.
--that action potential propagates Along-- Ah. --could you bring me up to date? Sure, so-- [JOSH BERKE] So dopamine terminals have all kinds of receptors themselves, right?
So for example, they have cholinergic receptors, nicotinic, and we know that even if you don't have a, if you take a slice of striatum with no midbrain present, then if you flash acetylcholine optogenetically, you get dopamine release, right? So there are lots of ways by which you can control dopamine release locally, and I should've been more specific about that, sorry. We also know, for example, that the basolateral amygdala input to ventral striatum can control dopamine release even if you inactivate VTA, all right, so if you shut down VTA.
So yes, there are mechanisms that have been known about for decades for local control of dopamine release. They've just never entered into the computational theories. [AUDIENCE MEMBER] Yeah.
Does that mean that if you were to block local release, let's say by blocking Mm-hmm. Then you would still get the reward prediction aspect of this-- Yeah. --without the motivation aspect?
[JOSH BERKE] Yeah, well we've been trying to find the right ways to get at that, right? So we've been trying, for example, to put, you know carbon fibers for voltammetry on optic fibers for control of cholinergic cells and things like that. There's so much fast regulation in the system, you know, that we don't even know the status of the cholinergic receptors, whether they're desensitized normally.
There's so much that's unknown about the status of these things in behaving animals that, you know, partly we're trying things, and partly we're like, "Ugh, it's too hard. " [AUDIENCE MEMBER] Yes. So I'm not quite clear.
Y-- y-- there's this association between the release and the firing. [JOSH BERKE] Yeah. [AUDIENCE MEMBER] But there must also be some relationship there.
Sure. So what does the firing contribute to the release? [JOSH BERKE] Sure.
So we, I mean, I actually think that the basic short story of a reward prediction signal is right? That you can use fast fluctuations as reward prediction signals, but I think it's only half the story. So I think sometimes the striatum listens to this as a learning signal, and sometimes it uses a motivation signal.
And I think, for example, the cholinergic interneurons are really important in switching modes, right? So for example, the cholinergics usually fire steadily and then have brief pauses, a couple hundred milliseconds, maybe June will talk about that, right? And then during those pauses, you unblock synaptic plasticities, right?
So there's evidence for switching into a learning mode very transiently and then switching back, and we think when you switch back, now you use it to gate excitability of the neuron. [MODERATOR] But then, but then what is the-- What does the firing contribute? [JOSH BERKE] What does the firing in cells?
Well, I think if you get a burst of firing of dopamine cells, you still usually get a pulse of dopamine release, right? But it's a tricky deciphering job that has to be done at the level of the forebrain, and we only have the beginning of a sense of how that might work. [AUDIENCE MEMBER] Thank you.