Olá ess é integration developer Camp estamos na etapa de boas práticas de desenvolvimento nesse vídeo faremos a finalização da etapa de boas práticas a etapa de boas práticas e desenvolvimento abordou pontos essenciais para construção de um fluxo performático focado na melhora e na velocidade de manutenção todos os pontos citados à direita foram utilizados na prática na construção do Ron temos um sumário direita demonstrando o que foi apresentado nesse módulo vimos alguns conectores e como são configurados seus parâmetros foi apresentado o conceito de Loops eflux utilizando um process e um Exception para processamento e tratamento de
erros utilizamos o block execution para evitar redundâncias e apresentamos os Loops da plataforma como Loops streams for podemos fazer processamentos individuais e repetidos elementos de um Array também vimos sobre controle de erro e controle de execução sendo controle de erro a utilização de validações chamadas externas e o One inception para centralização do tratamento quanto o resume da execução demonstra diretamente na aba de monitoramento Quais foram os problemas que ocorreram ou não ocorreram naquela execução passando por cada um dos Tópicos que estão destacados vamos começar pelos ch logs nós entendemos que sempre deveremos utilizar o conector
log após o conector Joice e também Vimos que utilizar o o nome do do conector log como uma cópia exata do nome da condição está exatamente anterior então aqui se Estamos numa condição de successful request o nome do log será justamente log e successful request assim como no caso de erro também isso acontece porque colocando o mesmo nome da monição nós conseguimos rastrear eh a mensagem rastrear o que está acontecendo imediatamente na plataforma por fim vemos também que devemos manter os logs descritivos Para que sejam fáceis de encontrar na aba de monitoramento então nas configurações
do conector log nos seus parâmetros temos log level e temos uma mensagem log level ele pode ser info warn ou error e é esse log level que aparecerá diretamente na aba de monitoramento então devemos manter logs descritivos no no sentido de nos casos de sucesso devemos colocar por exemplo um log level info e nos casos de erro colocamos o warn ou erro para que ao bater o olho na plataforma nós Já conseguimos identificar aonde no fluxo Ocorreu algum tipo de erro prosseguindo nos tópicos que foram abordados vimos sobre validação de chamadas externas abordamos dois tipos
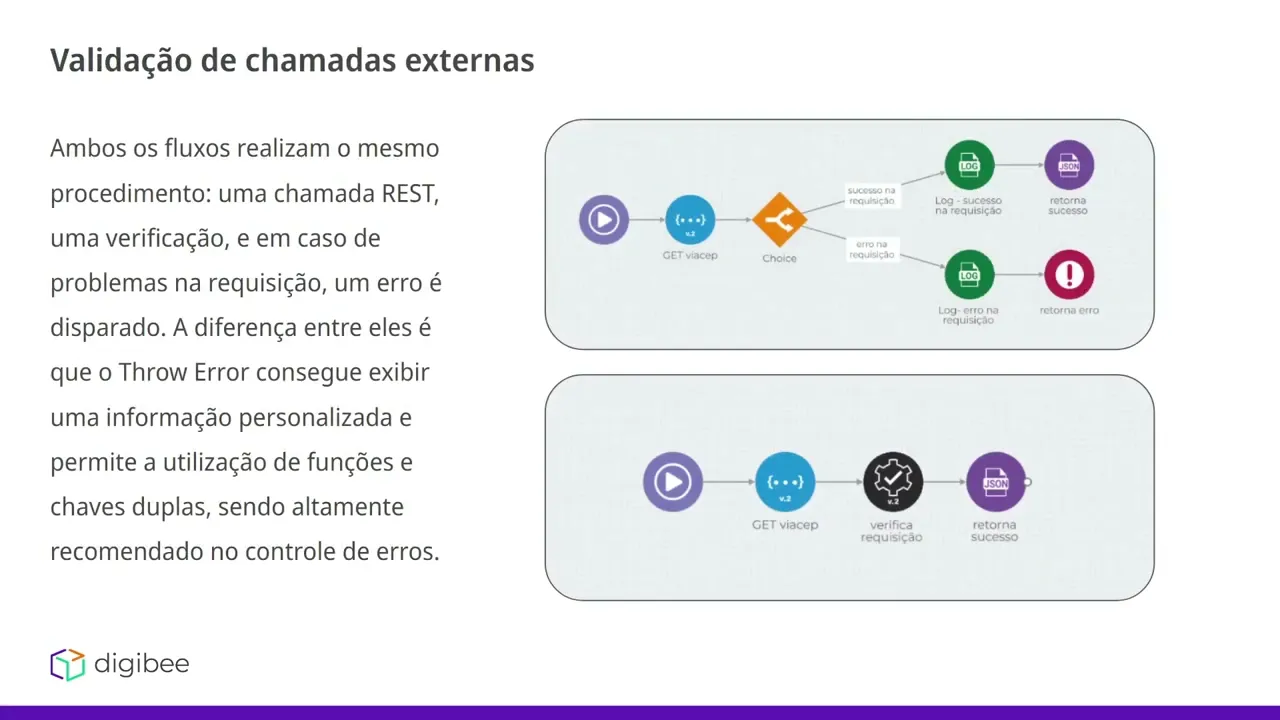
de fazer validações utilizando o componente Choice juntamente com os logs ou o conector assert os dois fluxos fazem exatamente a mesma coisa temos uma chamada hash uma verificação se essa chamada hash deu sucesso no caso de sucesso ele vai retornar um dião de sucesso e no caso de falha ele vai interromper o fluxo informando algum erro mesma coisa acontece pro fluxo de baixo temos aqui um rest uma verificação se essa chamada deu sucesso do falha no caso de sucesso ele retorna Deão de sucesso no caso de falha ele interrompe o fluxo como uma mensagem a
diferença entre os dois é que utilizando o TR erro nós conseguimos fazer um erro customizado criando um Jon eh e demonstrando alguns padrões de atributos para para identificar Qual foi o erro e informar qual foi o erro já utilizando o Search por mais que ele seja mais enxuto para a construção do nosso fluxo ele não permite a criação de um erro customizado limitando a mensagem que será entregue apenas com no formato de texto e não de json vimos sobre a centralização de tratamento de erros com o One Exception E aí um dos seus exemplos é
por exemplo esse componente de e-mail ele era utilizado em cada uma das condições desse componente Choice aqui então a cada condição desse conector nós tínhamos um componente de meio se repetindo aqui e aí na hora de fazer algum tipo de manutenção nesse conector de meio deveríamos fazer a manutenção em todos esses conectores e aqui para evitar esse trabalho repetitivo nós centralizamos o tratamento de erros utilizando o Exception todos esses conectores que estavam repetidos passam a ficar dentro do meu One Exception e aqui no momento de alteração de manutenção faremos só uma única tração em um
único conector mas que funcionará dinamicamente para todas essas saídas aqui um outro exemplo um pouco mais real é por exemplo um fluxo que após cada chamada externa eu tenho uma opção de envio de uma opção de caminho de erro e nas opções de caminho de erro como é o caso dessa direção e o caso dessa direção nós deveremos criar todo um padrão para envio de e-mail como a criação do B do e-mail transformar em string e depois fazer o envio isso se repete para todos os caminhos de erro E caso o fluxo continuasse se repetiria
também E aí para evitar essa repetição de componentes e facilitar na manutenção futura nós pegamos todo esse fluxo e colocamos dentro de um Block chamado processamento no one process nós colocamos esse fluxo tirando apenas o que estava entre os conectores log e os conectores de Troll e aí esse valor que estava aqui dentro ele passa aí pro One Exception e aqui a gente tem de forma centralizada unicamente no one exception esses valores que eram repetidos em todas as saídas de erro então comparando o fluxo de cima com de baixo aqui e aqui ficou mais enxuto
ficou mais fácil de fazer a leitura e aqui a gente sabe que no tratamento de erro por ter um troll aqui iríamos para um Exception e poderíamos fazer esse tratamento diretamente num Exception por fim a gente viu sobre resumo da execução E aí como uma visão geral nós temos aqui uma base de dados e vai retornar diversos e registros de uma vez só temos aqui o forit para lidar com todos esses registros individualmente e lá dentro cada registro pode acontecer algum tipo de erro caso aconteça a gente quer que diretamente na aba de monitoramento consigamos
entender Qual foi o erro o motivo quem que estava envolvido e assim por diante para fazer isso a gente cria o resume da execução então aqui dentro para cada erro vai ser redirecionado para um Exception um Exception vai salvar em uma base de dados temporária que no exemplo é cando esse erro e quando acabar todo esse processamento do forit nós vamos vir aqui recuperar esses resultados recuperar os erros que foram salvos deletar esses erros que foram salvos D base de dados temporária mas já estão salvos na sessão e enfim recuperar todos esses valores e fazer
o resumo da execução em si mostrando já direto na aba de monitoramento no di on saída do pipeline qu quantos registos Foram processados quantos deram sucesso quantos deram falha e nos casos de falha Quais foram as falhas e por aconteceram aqui temos um pouco mais da Visão explicada do que cada componente Faria nesses execução por exemplo salvar o resultado do forit buscar a pilha de erros que foi salva dentro do Exception deletar essa base de dados temporário uma vez que já está salvo na sessão e assim por diante aqui todos esses tópicos que apresentamos anteriormente
foram utilizados diretamente no R Zone e aqui a gente tinha que fazer nesse R Zone uma migra ação di área entre dois sistemas esse sistema que está consultando os registros e outro sistema que está publicando cada registro individualmente dentro do forid imediatamente já Conseguimos ver duas boas práticas sendo aplicadas que é validação de chamada externa e utilização de Choice e logs e juntamente né juntos temos também aqui uma centralização de erro com o forit todo erro que acontece no process é direcionado para um Exception e é feito tratamento E além disso no Exception Nós salvamos
Qual foi o erro dentro de uma base de dados temporária que é o Cassandra e quando saímos desse componente nós fazemos o resumo da execução aplicando todas as boas práticas que vimos anteriormente Esse foi o módulo de boas práticas nós nos vemos nos próximos módulos e até lá