all right so we want to write our own programming language um so we're going to write a compiler but now people might think of a compiler as this like magical Pro like special program that's separate from any other kind of application but it's actually just just a standard application just like anything else all it does is read in a text file of the source code it doesn't processing and then outputs another text file um but this time in a different language so it's pretty much just a translator it's just that um it translates to assembly
and when we translate things to assembly we have a special word for that which is a compiler so so let's like let's let's draw a little diagram as to what exactly is is going on here so because there's a few steps from taking source code from something like C and turning it into a final executable um so we have our source code so if we're creating our own programming language we have our source code um and then we have a compiler right and so most people would be familiar with this step so we have a
compiler and we have our source code and we put the source code into the compiler and the compiler gives us assembly right um but we can't just run assembly because assembly is still foreign to the CPU it doesn't understand assembly what it does understand is machine code but assembly is pretty much human readable machine code what it does is it just takes it's pretty much like a one-to-one translation you're just you're just taking the instructions like the add instruction and then just output outputting the the bytes that the CPU can understand so it's really not
that um that big of a step the compilation step is the biggest step um but what comes afterwards then so so we we have our assembly uh so then we put it into an assembler okay um and you might be like okay so it assembles it into an executable um but you would be wrong you're close but not quite there we actually get an object file so the object file um is almost there but not quite the object file does have the machine code um from the assembly um but you can't run it yet because
it might reference other libraries on your system if you're on Windows you might want to communicate with the win32 API if you're creating like a window on Linux you might communicate with the X11 Windows system and such so you have these external libraries right you have your you have your Libs and you need to link them with your object file and that's where the the Linker comes in you have your Linker and the same thing applies on Windows to pretty much all operating systems work in this same way so you have your libraries you have
your object file you put it through the Linker and what do you get you get your final X at Q x x x oh my God executable you get your final executable all right just like that so looking at this you might think boy the compiler seems like a pretty small step compared to all this but actually despite the number of steps um these steps from the assembly to the final executable the assembling and the linking is actually not that complicated it's it's relatively straightforward assembling is just almost a one-to-one translation and the linking isn't
super complicated um as well the biggest the complicated part is the compiler because you're translating this high level language into assembly and especially if you want to optimize it it gets really complicated so this is the biggest step and this is the thing we want to create just the compiler for the assembler we're going to be using something called nasm right and I'll I'll get into what that is and the Linker we're going to be writing this for Linux for now so we're just going to use the the gnu Linker which is just LD all
right and that pretty much comes installed I Believe by default if not it's like one command away um all right so this is how it works now before we get into the compiler let's just see what are we even compiling to what is the assembly what do we want our output to look like what is the simplest assembly that we can create that runs all right so we're in vs code and uh we're in Ubuntu here so despite me being on Windows I am in Linux essentially um so what is the simplest assembly we can
we can create now if we think of the simplest C program we can write most people think of something like um hello world but hello world isn't actually the simplest program that we can run the simplest program is just um would be returning zero right returning an exit code so an exit code of zero implies no errors and exit code other than one implies something went wrong but that's just convention um the operating system doesn't really care we can just return whatever we want so before we have to before we Implement like these complicated print
statements let's just return something all right so this is pretty much as simple as we can get so what would the assembly for this look like let's see let's program in straight up assembly all right so let's create just a little test dot Asm right where do you even start so in C you have a main function and most programming languages have a main function that that is the entry point of your program uh in assembly uh at least for Linux and with nasm I'm just going to stop saying that it's implied right now we're
using nasm and we're using uh Linux because assembly differs between platform and assembler so everything's going to be slightly tweaked but given our environment the our entry point is actually going to be underscore start all right that's just what it is in assembly we don't have functions we have labels so this is a label and we indent it and then we put our instructions here right but by default this label isn't exposed to the outside world um I believe we need to make it uh visible to the Linker so the way we do that uh
you know in most in other programming languages you would do something like public or something like that but in assembly here we're doing Global start so now this is saying that our start is global and then we're we're declaring our start here or defining it I guess right here so we have our start now in C um what we did was we we did like return zero right but but that that's too high level that is way too high level for assembly we need to go we need to we need to simplify this a bit
okay the CPU is a little dumb we can't just call the function call return and then pass it like what we want to return we got to be more specific so we can't just return but let's try and return so ret is short for return and so if we just return from our main function you might expect okay well there's no errors so it should just return zero right so let's actually see so we have our assembly here all right so if we go to our diagram we're at this step so now we need to
assemble it so I have nasm installed uh as you can see here nasm but we actually want to um so we want to turn this into an object file right so the way we can do that is we can do nasm and we need to give it a format and so for Linux it uses the elf format and we're going to Target 64-bit because who is 32 but it's 2023 we're all using 64-bit so we specify the format as elf 64 or uh felph 64. just that's an easier way to memorize that one and then
we're going to give it the test.asm right so we'll go ahead and do that and now we have an object file and so if I go into so this is machine code so you have to go into the hex editor here to see it but we can see we our heading here is like an elf and if we go through this we can kind of see here's our like start and it's kind of it's just empty or I don't know where our return is it's somewhere in here okay but we can't run this yet we
have to link it now even though we're not linking with anything we still have to call the Linker so in Linux or we use LD as you can see if I do a man LD I mean it's the good new Linker so let's actually link it um so we're going to give it our test.o and then we're going to specify the output as just test and now we have our executable that we can run and so this is our program so you might expect it to just run but if we run it we seg fault
that's right we have our first seg fault um trying to just return nothing because we are so low level that we cannot simply just return from our application we actually have to tell the Linux kernel that our application has done okay we can't just be done we have to tell it we're done so we need to communicate with the with the kernel the operating system so how do we do that um with assembly so we're going to use syscalls and so that's that's the lowest level way that we can communicate with our operating system so
how do we even do that so we can't just call a function in assembly what we do is we have registers and you only have a handful of registers and they just they're just uh spots they just uh locations on the CPU that you can store things into but all instructions execute from the registers so if you want to add two numbers you have to take them from uh your system memory from Ram you have to put them in the registers and then you can operate them operate on them and maybe you can keep them
in there for a little bit um if you have enough space but there's only a handful of registers there's very little especially in x86 assembly very few registers that you get to work with um so you might be able to keep them in there for a few instructions otherwise you have to put them back onto the stack which is in memory so let's just put some values in the registers and then we call a syscall all right so so what are the sys calls on Linux what exactly can we do here so if I if
I look up some uh Linux sys calls I believe there is a good chart out here um not this one um chromium I believe this is the one yes so here are our Linux syscalls for x8664 Linux this is from Linux 4 which is a bit old but the thing the great thing about Linux unlike Windows is that their sys calls are actually pretty consistent um I don't know the last time that Lexus calls broke compatibility they're pretty stable so we'll use them uh so we have things like reading and writing opening and closing blah
but let's actually um look for exit right so there is an exit sysc code here it is exit and we have our arguments here so argument zero one two three four and five and you can see that they're assigned different registers so we have the RDI which is the deregister um or RDX actually I don't I don't quite understand that naming excuse me registers there's some there's some consistency sometimes um but yeah some of the registers are shared I'll I'll explain that we'll get to it but if it starts with an R it's a 64-bit
register and we're doing 64-bit so we're exiting all right so we want to call the exit Source call it only takes one argument which is an integer and that's the error code um which is the number we want to return right so how do we actually do this so you can actually see the hex code for this but we don't actually have to do that because we're just the our assembler is going to turn it into the into the correct um bytes to do that so it's exit code 60 or not exit code 60 it's
it's geez it's um the uh syscall is this is called number 60. and in order to specify that you have to put it in the racks register which is the a register so let's actually let's actually do this so normally in C you would expect something like um if if we're doing a sys call like we would have exit and then like uh Exit 69 right you'd pass in the first argument but you can't do that okay you can't do that you can't type in exit instead what we have to do is we have to
uh tell it which syscall we want to use which is um 60 and we specify that in the a register the 64-bit a register so the way we set a register is we we don't set like Rax equal to 69. what we do is we move 69 into the a register so we say move into Rax so the destination is first and then we give the number so we're moving 69 into racks okay which is the 64-bit a register then we want to specif I'm actually wrong this is run because this is the value we
want to return racks specifies which Cisco we want to use which is 60. okay so then we have argument one which is um or argument zero because we we start counting at zero obviously um and that's an integer and that's our error code and that's going into RDI right so we're going to move into RDI the exit code we want which we'll say 69. so this is saying we want to do the exit assist call and removing the value the first argument into that and then we can call this is called and we just use
the word Cisco just like that and that's it this will tell Linux yo we're exiting this is the exit code we want all right so let's actually say this let's assemble this file 64 test.isn let's go ahead and Link that and let's go ahead and run it well we don't know if it did anything we actually need to see the exit code and on Linux you can do that by doing Echo dollar question mark this will show you the exit code of the last command we you ran which is test and there we go we
got 69 let's change something else 420 let's um let's actually combine this in one command so we'll we will assemble it and then we will do LD test um Casado uh test and then let's run it let's just combine it's all in one command um okay and then we want to exit we want to Echo and we have 164. okay RDI might be just a limited size I actually don't remember um let's let's see X x86 RDI so I there might be a limit to these um so RDI um I actually don't know it must
be it must not be 64-bit then um RDI might have a limited size if I can figure out how this works obviously I know what I'm doing here RDI I want to know how big it is um what is the size of RDI so is it is it 64-bit 8 byte register um it probably has a limited size let's actually see that let's see let's put in put in D5 okay so that works and then let's try 256. and zero okay it's wrapping around okay so it can only go from zero to 255 which is
how many bits it's just one byte so eight bits right so it can just be a maximum of one byte even though we're putting it in a 64-bit register it's only reading eight bits of that register this is where x86 gets confusing because there are um there are registers um like racks so you have like the a register boy this is terrible this is really bad so you have the a register um and the entire 64 bits is like racks wow this is great typing and then our uh drop it and then half of it
if you just take half of it that's the eax register so both of them are the a register but these two um names for them point to the same register which is different parts of it so I believe if I put an eax this might still work it does not [Applause] that's all right that's some experimenting but just just so you know if you have eax and Rax one's a 32-bit and one's a 64-bit but they actually point to the same thing so they're not two distinct registers they're just two different ways to access the
same space just one smaller and one's bigger okay I don't think I'm doing a good job explaining this oh whatever it doesn't matter okay so this is this is the simplest assembly program everywhere turns zero it won't actually return an error we got zero Perfect all right so this is the simplest assembly program that we can write now how do we actually compile this um like how how can we um create a language that compiles to this assembly let's let's do that and we're going to write our compiler in C plus I know that's a
bit sacrilegious in 2023 you should be writing in Rust um but um oh well right um the the 2023 2023 thing to do would be to write it in Rust and then compile it to webassembly and then like run it in typescript or something in the browser um something like that but we're just we're just gonna do C plus plus right but in the future hopefully maybe we can write our language in such a way that we can actually rewrite the compiler in its own language which I know sounds like At first first glance that
might be sound impossible how can you write a compiler in its own language but it actually makes a lot of sense and it's called self-hosting language because all it is is just reading a file processing and outputting a file so there's no reason why you can't do it in its own language but we can't do it in its own language if the language does not exist so let's actually go ahead and start the compiler so let's create a simple project and we're going to do this in in C in C plus plus right so we're
going to use cmake so let's go ahead and create a directory um and we're going to call it hydrogen the reason I'm calling it hydrogen is because it will be simple lightweight which is which is scientifically accurate but hydrogen is also known to be flammable so if you handle it improperly it might kill you so that's why we're calling a hydrogen okay so we're going to call it hydrogen and then inside of hydrogen we're going to create um let's actually open the folder in here for now let's go under uh slash slash Dev slash um
slash hydrogen okay so let's actually go in here and let's create a c make file so C make list if you don't know what cmake is um it's ya build system for C plus plus The Unofficial official build system kind of because um you know there I don't know they can't make their own standardized build system so cmake is as good as we can get okay um I gotta be honest I can never remember how to write cmake see make files I always copy and paste from other projects so I'm actually going to like um
go to one of my other projects and just find find um find a a project that already uses cmake and just and just uh copy it so we're gonna have we're gonna have this minimum version required uh I I never know what to make this we'll just do 3.20 um because that's a nice round number I don't know what version I'm currently using 3.22 cool 3.20 probably good enough all right we've got to specify our project we're going to call it hydrogen uh we want to give it the C plus plus standard we're working with
we're going to do nice and nice and new um uh we're gonna use C plus plus 20. so we're gonna get all the brand new features um and then we're going to create our executable this is going to be our actual compiler and we're gonna we're just gonna We're not gonna do a the whole word hydrogen because that's way too many characters of type we're just gonna call it Hydro for short um and then we will use the main uh main CPP file here um I believe that should work and then if we go ahead
and create a source and then create a main.cpp and then we include IO stream um we have our main function here I don't know why I put a zero in there and we're going to do a bit of hello world with the very strange um C plus plus printings by doing count and end line um and then we'll we'll just return we'll just return zero and let's see if this actually even works um so we'll do cmake uh we we need to make a a build directory we're not even going to use vs code I
don't even know why I'm doing this cmake um what am I doing cmake uh build I I think it's how you do this ah no I'm not no it's sources here build directory is build that would that would work okay okay we're getting there and then now we can actually compile this by doing cmake dash dash build build and now we compiled it and then we can go ahead and run it and we get a Hello World all right so we can delete that because we're not going to use vs code we're going to use
good old sea lion all right good old sea lion because vs code is for soys and if you're if your IDE is not using um 10 gigs of your RAM you're not doing it right all right so we're gonna go into not there uh I gotta find it I gotta find it where are we home uh all right so we're not using visual studio get out of here we are going to be using WSL right um yet we're going to be using WSL uh we'll do debug and release with debug info there we go okay
so we'll we'll add both of those so those are our two configurations for cmake and here's our Hello World um let's go ahead and run this as soon as it loads all right we can go ahead and run this and it should actually work we get a Hello World all right beautiful hello world exited with zero awesome so we need to read um a hydrogen file which is our own language so let's let's actually let's um we'll just create it at the root directory right so we'll just call this like um I don't know test
and what we'll do I don't know what file extension to use I think Hy is kind of a cool file extension two characters hydrogen it's first two letters it's probably taken by something else I don't really care whatever so 10.hy so what's our syntax going to be um I'm not 100 sure yet but let's just do the simplest thing which is return 69 semicolon this is going to be a semicolon based language um and it's not going to be uh using white space right so it's not going to be like python can I get out
of here with your indentation as like um white space is not going to matter all right right so it's not gonna matter so let's just do this now how do we even go about doing this right so we want to turn this into um This Global start and then start and then moving into racks UH 60 and then moving into RDI 69 and then we want to do a Cisco so so we want to convert this into this so what is the first step in a compiler right the first step is actually something called lexical
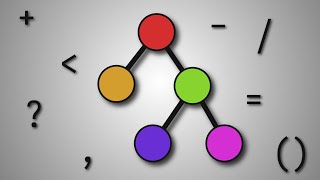
analysis ooh fancy words right what is that let's let's look it up let's let's Google it lexical analysis analysis okay um lexical analysis or lexical tokenization is the conversion of text into meaningful lexical tokens thank you Wikipedia this is totally clearing things up um okay in plain English this is basically just taking uh all the characters uh from the file because we read the file in as a string of characters and we want to turn it into bigger pieces that we can more easily um manipulate and parse right because we don't care about if you
have an r or an e or a t we just want to know that there's a return so we want to turn this into a series of tokens so the way you might do this is we might have a return token and then we might have like an integer literal right so like an integer literal which has a value of 69 and then we have a semicolon right so we're just going to have we're turning our list of characters into a list of tokens all right and then we can parse these and do whatever we
want and then turn that into assembly right all right so step one we gotta read the file um let's see if I remember how to do this I don't even know if I remember but we want to take in um the argument which is the source file right so I believe um what is it ARG ARG C is it ARG C count oh my God I don't even remember how to do this guys um into Arc C and then like ARG V no oh my this is not right it's a Char string of ardv it's
a pointer to a pointer or is it an array is it like that can I do that yeah this is how much I know C plus I I think I'm pretty decent at C plus plus but I I can't I can't remember things like this okay so args to get uh command line arguments you have the the count of how many arguments there are and then you have an array of strings and a string is a a chart pointer it's a character pointer all right so let's actually make sure that we have um an argument
but the first argument is actually always the executable itself all right so if we just print out the first argument right so if we just print out ARG V the first argument here um it's complaining blah blah I don't care if we run this we get the path of the executable right so um that's cool if we want that but we don't really want that we want to pass in something else so um let's actually start calling this manually because uh so if I call Hydro from here uh cool so you can see that we
get the path um we want to actually pass in something else like um dot dot slash test.hy right we want to pass it that file so if I if I put in a one now and if I run this and I build it first obviously but I build it first and run it now we get this dot dot slash test.hy which is the argument that I just put in cool but we need to make sure that that argument is there because if I don't do that we should get like a sec fault probably right um
or it just works for some reason okay but there is nothing there so we need to actually verify that so let's let's um we're going to do if ARG C doesn't equal to whoops I've been doing too much Java and typescript JavaScript and typescript that I'm using the strict equals um here uh so if we don't have two arguments uh then we will um we will return an error so in stand in standard error we will say um incorrect usage um something like that and we will do like the correct usage will be um uh
will be like hydro and then input .hy something like that right so so we'll do incorrect usage correct usage is this and then we'll then we'll return um we'll turn exit failure we'll use the fancy macros for this all right which exit failure is just one it's just a Divine of one but uh and then we can do exit success here because we will be all fancy here with our macros all right so cool so now if I go ahead and build this and try and run it we get incorrect usage track usages hydro and
then our input file so we can dot slash test.hy and now it works correctly cool cool cool so now let's actually read the file right so I believe in C plus plus that's an F stream which is uh which is a file stream so we'll do input and then we get a I believe it takes in a path uh but I need to include this right so include F string like that and then um we can get in a path perfect perfect perfect so we have Arc V1 and that'll be our path which it doesn't
like I obviously screwed something up already what did I do does oh you know what it might not take in a um I'll take some oh oh that's that's right I need to specify the usage of this so um I believe that's um is it iOS or something I can't remember what iOS stands for but I know this contains flags of how to use it right how we're going to use the file so we're going to use it as an input right so I think like that there we go all right so we're using it
as an input what does iOS stand for I can't remember these classes for character streams I cannot remember these but we're using it as an input only file for input open for input yes so we're only reading from it right so now we have the input and so I can't remember what we can do with this maybe we can get the can I get the string from this um or can I like read the entire file read some read stream size guys I can't really remember how this works how do you create an entire file
input dot okay read buffer read hmm I I think it's I think it's I think it's read but I can't remember how this works right um does it give me it gives me a Char pointer so maybe it's like contents and then we give it contents but it takes in another argument which is the stream size okay am I gonna have to Google this I I can never remember how to do this stuff okay C plus plus read file we have to we have to do this okay this is just how it this is how
it is um open open if I just want the entire file I want the whole thing as a string read file to string read whole ASCII file industry read buffer all right that's how you do it so we need to create a string string all right we create a string string uh string string string and this will be the contents um or uh uh uh yeah we'll do contents stream and then we will do uh we need to actually include this #include um is it is it string stream stream buffer a stream string string something
like that okay um and then we need to do content stream and then we do input dot read buffer just like that and then we can do input Dot close all right beautiful beautiful or I don't know if we actually have to do close we might be able to have this be in its own scope and it might have a disruptor right so if we do something like this this might close the file for us because as soon as this is a scope and as soon as this file stream exits the scope it should close
the file should does it have a Destructor I have no idea does it have a Destructor basic s stream does nothing the file the file is closed by file buffer object not the formatting um okay you know what I'm gonna assume it is hopefully it is um okay so we have our contents so let's actually verify that this actually works um actually we want to turn this into a string so I believe we can do we can just create a string so contents um equals content stream dot stream and now we actually have the string
right so that should do it in that case we can probably do something like this and then do this there we go so now we have contents all right so let's actually print it out and let's see if this actually works so let's print out the contents and let's see if this actually functions so let's we have a problem already I don't know if you know where that came from okay let's see if this works nothing all right I don't think anything's in this file it there is something all right you know what I don't
know where this is running from um I put it in source I want it in the root directory I just put in the wrong spot guys there we go all right we got the file contents beautiful now we need to actually start Lexing this file so we need a list of tokens so let's let's create our our enumeration so we'll do an enum class because we're doing modern C plus plus and we're gonna do uh a token right token token type yeah token type and we will do a uh we will have a return ah
but that's a keyword so we'll do underscore uh yeah writing a compiler is you're gonna have to do a lot of weird things to get out around keywords in your language right uh in the language of programming and so we're gonna have a return we're going to have um integer literal so an integer literal and then we're going to have a semicolon all right so something like that and then we'll actually have our token type which we'll just create a struct and we'll say it's a token and it will have a token type so I'll
give it a type and then it will optionally have a value right so we'll make it an optional um and the value will be I guess a string I guess I don't we'll make it a string for now value and we'll go ahead and get optional in here all right all right all right so tokens number Okay blah blah okay so let's start tokenizing things or Lexing it right so let's just create a simple uh function that returns us a list of tokens so we're going to use a return as a vector because we're in
C plus plus right we we don't use lists we use vectors so we need to uh include Vector all right and we'll we'll do um we'll do tokenize tokenize and we will get in a um we'll take in a string um stir do I call it stir yeah we'll call it stir all right so we want to tokenize a string into a series of tokens so how are we going to do this we need to iterate through um each of our each character all right and we're just assuming this is all ASCII for now so
let's go ahead and Loop through each of them so I believe we can just do a like char C in string is that a thing yeah I think we can do that let's make sure this is actually how you do that let's print it out let's print it out make sure we should get a big column of characters oh I don't know why I ran it from here because I need to run it from here we got a seg fault um why did we get a seg vault I mean this worked that is interesting we
got a seg fault because we're not using our return value I don't think I didn't think that would sight fault maybe maybe it does nowhere to oh I'm not returning anything from here okay I see I see okay we'll we'll do that okay I see I see I see I see okay so we're going through character by character so let's actually see how we're going to tokenize this so we're going character by character through our source file so we're gonna see an R and so um if we see a letter we'll start reading it into
a buffer I think is what we're going to do right and then when we get something that's um no longer a letter or a number than like a space then we can determine what that buffer contains and if it contains a keyword then we can use a keyword otherwise it will just treat it as an identifier just a standard like variable name or function name whatever um and we're not concerning ourselves with the placement of it right so if we just had a number first or a semicolon first that's I guess technically not really valid
syntax maybe and depending on your language but we're not we're not actually checking for like syntax errors here we're just we're just straight up turning whatever we get into valid tokens right so let's um let's see here um you know what hmm I actually don't want to do this because I think I want the index I think I'm going to want the index so we're actually going to do in C equals zero C is less than string dot length and then we'll do C plus plus look at that that's pretty meta um and then we'll
get the actual character actually so I'm just gonna make this I will make this I for the index and then we'll do um Char C equals string dot at I right and that should give us the character cool and so let's do a if it is Alpha I think that's a thing I don't know if we could use standard is Alpha is Alpha C right so is it an alpha alphabetic character um then we read it into a buffer so I guess we can just create a buffer here um which will just be a Char
array I guess yeah we'll just do we'll just do this we're not going to care about optimization I don't really care about how we do this um um we're gonna so this will be like a buffer we'll just default initialize that bad boy and then what we will do is we will start putting these things into a buffer and we'll keep reading um until we'll keep reading tokens until we don't get an alphanumeric character right because you you can start off you can start off an identifier with a letter and then they can contain numbers
afterwards but you can't start an identifier with numbers right so we can we start with is Alpha and then we can we can continue it with is alphanumeric so um I don't know if I'm liking how this is being structured whatever we can refactor it later we can refactor it later um we're gonna do um trying to do buff Dot pushback the first character and then we will do I plus plus and then so we're now at the next character and then if is Alpha alphanumeric actually we should do a while loop here while it's
alphanumeric um string dot at I while it's alphanumeric we will keep pushing back the character string dot at I and then we will do I plus plus and then at the end I believe will be one character ahead so then we need to go back one I think I think that'll do it Maybe and then after this is done we have to check if it's a keyword right so then we'll do if buff um it's not really a good way of checking you know what I kind of Wonder can you push back on a string
you can okay we'll just do that so if buff equals equals um return right so if it equals return character constant too long for its type what have I done um I've screwed something up ah maybe like that equals oh too much typescript you gotta do double quotes all right so if buff equals equals return then we okay we need we need to create our token array here so we need to create a token array um token and then tokens and then what we can do is we can add our token to this list so
tokens dot push dot push back um and then we need to give it a token so it's type is going to be token type return and it's not going to have a value uh we'll we'll just um default that at zero okay all right add no okay so we have that else let's just give it an error for now we'll just we'll just do um C error you messed up you met you messed up all right you you messed up um and we'll return exit failure okay I don't know what this formatting is it's horrible
um I need to create a claim format file why is this not working oh that's not how you I just want to exit here there we go all right I don't know what formatting this is I don't like it I don't like these curlies on their on separate lines I'll have to deal with that I gotta create a claim format file I'll do that later um okay so then what is the problem here redundant string initialization what is oh okay we we don't usually do that um actually I don't even you don't even have to
do this I don't know why I'm doing that okay so um now we got our return so we should get a return uh we need to deal with the space so if there's a space or we can just continue we're just going to ignore it um also after this we need to um we need to clear a buffer I realized so we need to do buffer.clear um and then we need to continue I think Maybe I don't know we'll see we'll see um so um if it's a space so we need to determine if it's
white space there might be something for this is white is um is I don't know if there's a is a white space if let's actually see is there um is white space in C is space perfect that's exactly what we want all right so if um is space C then we just um we just continue we just can we just ignore it all right so we just ignore white space um and then we need our number right so um maybe this should be an this should be an Elsa else if is why is this why
can't I do num is is there no is num is is number really it's got to be a thing it's got to be a thing is digit of course because you called it num up here or you called it num somewhere else so it's Alpha num is Alpha num and then is digit consistency beautiful our language will be very much more consistent guaranteed all right um so is digit C um and then we basically do the same thing as up here but we're just going to keep reading digits so we'll first of all push back
into our buffer see um and then we need to do what do we need to do we need to do a while while um stir dot at C and then we need to do is digit while it's a digit we need to keep pushing back and I did something stupid here I'm missing a parentheses buffed up pushback stir dot at C this is very safe code by the way very safe very safe code I plus plus we need to go back when we might have to go back to I don't know I'll figure it out
when it crashes on me and then we will do um we'll just uh add a token then so tokens Dot pushback um it'll be DOT type token type int literal and then the value will not be null this time it'll be the buffer right and then we can do a buffer dot clear right there we go Okay so that should take care of that and then the last thing we need is just to check if it's if it's a semicolon right so if C is a semicolon and then we can do tokens Dot pushback see
no that type equals um token type semi and it doesn't need a value okay and then if we go through all these and we don't get anything that means we just we also screwed up so we'll just also say you messed up like that let's see if this works um it's probably not but that's all right we will figure it out also we didn't return it okay we need to return our list of tokens here um so down here we need to do return tokens all right all right all right all right so let's build
it okay let's run it and we got a problem um yeah out of range ah why um is out of range interesting what did I screw up what did I screw up debugger help me tell me what I did around oh I can't debug it like that um let's let's just configure this so I can debug it so we'll just do program arguments um test.hy in here so I can just run it directly from here yeah okay so now I can debug it um no such file or directory do I not have GDB installed why
um huh that's interesting I can't remember maybe I reinstalled a WSL I can't remember um so let's go ahead and install this um let's see I had to mute my mic while I do that because you can determine key presses from just your microphone alone now because it's 2023 and AI can do that all right so that's actually debuck this correctly now um all right so um we have a problem somewhere over here it's at the six oh we're doing at C why am I doing at C it's at I so safe C plus plus
is a very safe language very very safe um it was successful but we don't even know our our uh a list here we don't have a way of printing it out easily um so let's just let's just uh let's just let's just let's just put a breakpoint on it I don't think I can stop there though I think I actually have to do something like I I just have to do something so that I can put a breakpoint here and then stop it and then I'll just I'll just use the debugger to see what's going
on here so thing we have three tokens that's good token type return with no value good our next token is an integer literal with the value 69. and then the last token is just a semicolon with no value first try almost that's pretty cool all right so we have a list of tokens now we need to actually create our assembly um from the tokens all right so we can tokenize our file um let's actually let's actually turn it into assembly right so so let's do um let's return a string of the output and then we
will do so we're turning tokens into assemble do we want to go from tokens so typically what you'd have is you tokenize then you parse and then you [Music] take the parse tree and then turn that into assembly we are just going to ignore that for now and just go straight from our tokens to assembly just so that we can have something that works and we'll get into parsing later so let's actually do uh tokens to ASM for now uh this is probably not going to stay like this um so we'll take in a vector
of tokens uh if I can type um tokens so a constant reference and we'll return a string so we will have a string of the output and then we want to Loop through our tokens so we will do four um const token um uh wait what am I doing const I'm forgetting how C plus plus Works token token in in tokens all right so we're doing this I might want the index in here I think I'm going to want the index let's just get that oh my gosh no okay I ain't I equals zero I
is less than tokens dot length or is it dot size it's size for for a vector and then we can do I plus plus okay now we will do if if let's actually grab a token equals tokens dot at I if token DOT type equals token type return so if the first token we get as a return and yeah so what we actually need is we need a return we need a the number the integer and then the semicolon we need to require all those things so um this is going to be kind of messy
we will do if um we need to make sure we're not out of tokens so if I plus plus is less than tokens dot size or no if I plus 1 is less than token's size so if we're not at the end and token tokens dot at I plus one DOT type equals token type uh Dot uh integer literal and then if I plus 2 is less than tokens.size and uh token tokens dot uh so basically what we're doing is we are checking if we start with a return we want to make sure that there
are at least two more tokens and that those two tokens are an integer literal and a semicolon and if all that is true then we can output what we want so then for the output we will we're going to Output actually we'll use a string string here so we can stream into it we will stream one two three four so we're going to indent it and then we're going to move um we are going to move um interacts we're going to move 60 to specify we want the we want the exit and then we're gonna
we're gonna move into RDI whatever the integer literal is so we're not even going to check it we're not going to check it we're just going to straight up move it in there um so in in RDI we're going to move uh tokens um tokens dot at I plus one so this is the integer literal which we just confirmed is an integer literal up here dot value um that value dot dot value because it's an optional okay so we move it in there and then we need to give it a new line right all right
and then we need to actually do this is called so one two three four syscall just like this so we're straight up putting the assembly into a string but we actually need to start off our strain here so we actually need to start it off with global start and then start and then new line like that we cannot start it off like that we can't initialize a string stream like that okay so I'll put we actually need to do this okay uh all right all right this should do it let's print it out then so
then we have our um we need to we need to return the string so we need to do return output when we turn our string stream into a string all right so now let's let's print it out so we'll see out um okay we we should just call this tokens tokens and we'll do tokens to ASM and then give it our tokens well we'll unline there we go so let's go ahead and run this and there we go we got our assembly and we have 69 in here but if we change this to uh 21
and we run it again we get 21 in our assembly all right so now we just need to Output this to an assembly file so we need to go ahead and do the whole um F stream again so we'll do an F stream uh we're gonna do this in its own scope so it closes um so it automatically closes the file when the scope ends and we will do output file I'll just do file because it's in its own scope and then we will do um we're just going to hard code this in for now
um not the slash out um dot Asm and we will do an STD iOS and this is an out right and then we'll do file Dot I think we can stream directly into the file so instead of doing this we're going to take this and just directly put that in there um yeah that actually should be it if I go ahead and run this we have an out.asm and look at that oh I forgot the underscore for the start that needs an underscore uh let's go ahead and delete that and let's go ahead and run
it again we have out.asm and there we go here is our assembly look at that look at our compiler It's So Sophisticated it's so safe it's so safe like why do you need rust when you can just do this stuff this is I got I will say this is pretty ugly code this is really ugly but I just want to get something working we can make it pretty later on let's just make it do something just so we can get the idea across so we have our assembly file let's actually call nasm directly from here
let's actually not wait should we let's let's do it I think we can just do system and then give it a command so we could do like dot dot slash out dot ASM no we need to do nasm uh felph 64. um out dot ASM right let's actually not do dot dot slash let's just do out.asm and then do so the system allows you to just call um just uh just shell commands directly from C plus I don't know if this is C plus plus this is no I guess this is from C okay so
you can just do this and see um and then we'll call LD Dash o and we'll call out and then we give it out Dot o and that should do it so now if we run this inside of here we get out.asm we get the object file and then we get the executable so let's actually see if we can run the executable so let's do dot slash out we need to look at the exit code we should get an exit code of 21. and we do so now what we can do is we have our
own programming language where we can type in whatever we want here as long as it's one byte right it's got to be less than 255. uh so we can put in that two we can go ahead and compile it and then we can go ahead and run it and get the exit code and it's a two look at that look at what you just look at that so this works it's ugly code we'll fix it later um but it works that's but but that's it the thing that I'm trying to show you here is that
a compiler doesn't have to be that complicated all it does it reads a file you tokenize it um you you there is a missing step here you usually create a parse tree we'll do that next time um and then you turn that parse tree into assembly uh we're just doing directly from tokens to assembly here and then you just output it to a file uh you you assemble and and Link it and you got an executable that's it that that's it um so next time we will do proper parsing and we are going to probably
create some probably create a class for tokenization and parsing and code generation um because this manual index manipulation here is super sketchy I don't like it it's not good this is not this is not good code but we I just want to get something working all right but but this is it in 126 lines we have a compiler for a language that is nowhere near turn turn complete um but can give us a an exit code so I mean just looking at this you can see how you can just expand this from here on out
all right so our compiler is not magic all right it's not Magic just feel like it all right that's pretty much it for this time um the source code for this will be on GitHub although um I'd recommend uh not taking this part too seriously until it's cleaned up but it'll be on there it'll be in the description as well as some references to whatever uh pages I was on here um for uh I'll put this these pages in the description as well if you want to reference them yourself um but that is it for
me thank you for watching and maybe see you next time bye