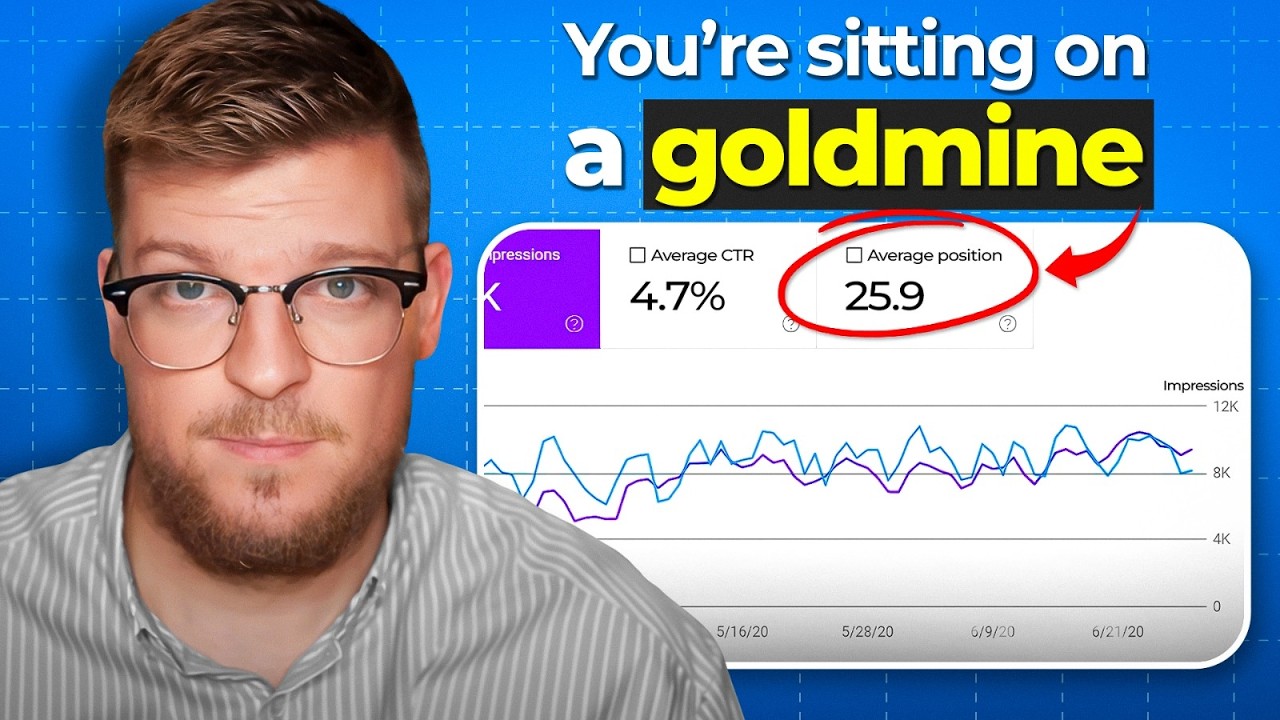
A few months ago, thousands of leaked documents surfaced from Google's fault, revealing secrets to their search engine algorithm they never wanted us to see. Buried within were four discoveries that, if true, changed everything. For over a decade, Google has denied that these things exist.
And while lone wolves have called out Google for spreading misinformation, they were often ignored and neglected. After pulling people on Twitter, 72% believe Google is actively deceiving us. I had to uncover the truth.
Why would Google lie? What could they gain by misleading millions of us who rely on their guidelines to optimize our websites? Is it just a misunderstanding or could something more sinister be at play?
Because if Google, the company that once vowed "don't be evil", is manipulating us, then who can we trust? The first piece of this puzzle takes us back to two 2012, centered around a product you're probably using right now. "Google Chrome.
They're moving toward taking over every part of our computing life. " At a search engine marketing conference, Matt Cutts, former engineer and head of web spam at Google, was asked if Chrome browser data is used in their search ranking algorithm, to which he denied. Cuts eventually left Google and with him, the rumors about Chrome data faded away.
But a decade later, John Mueller, a senior analyst at Google, faces similar question. What data does Google Chrome collect from user for ranking? I don't think we use anything from Google Chrome for ranking.
These denials planted the seeds for what would become the first of Google's four lies exposed in the leak. The documents revealed a module called Chrome in Total. According to the source of the leak, Google wanted the full click stream of billions of internet users.
Click stream data is basically like a map of everything you do online. It tracks the websites you visit, the links you click, where you pause, and how long you stay. And it's a gold mine of data for businesses because it helps them understand how users interact with their apps and websites so they can improve user experience and ultimately boost conversions.
And Chrome handed it to them on a silver platter. Thing is, click stream data is usually limited to sites and apps you own. And since Google owns Chrome, the app where sixty three percent of Internet users do their browsing, Chrome data can be used to understand how over half the planet interacts not just with search, but with the entire web.
But why would Google lie about using Chrome data? "My strong suspicion is it started because when Google started, they were competing for market share in the search world with Dogpile and Alta Vista, Lycosk and HotBot and MSN search and Ask Jeeves. And they they rose to the top of that pile fairly quickly, but I think internally at Google, they believed for decades after they had to keep all this stuff secret.
I also would strongly suspect Google is using their monopoly power in search to dominate video, to dominate maps, to dominate flight search, to dominate finance search, to dominate news search. Leveraging your monopoly power in one sector to unfairly compete in other sectors, that is what specifically called out in US antitrust law. " "I mean, look, the the most basic takeaway is if somebody has data to make a product better, they're probably gonna use it.
" And the motivation? Money. "Google's a public company.
They have to make more money every single quarter. The data that's in Chrome, it allows them to profile users. It gives them all kinds of competitive intelligence data that just no one else has and kinda they can use that to keep other competitors out of the market.
" Contrary to popular belief, advertising isn't Google's main product. Search is. And for a company that sells ads within search, they need their search engine to deliver the best results every time.
Chrome data may have been the secret weapon that's kept them miles ahead of the competition, making them nearly impossible to catch. And arguably, the most valuable data point that comes from Chrome is click data. Clicks are the bridge between searchers and search results, and they're a key part to understanding intent at scale.
So, I just Googled "running shoes," and I'm trying to decide which result to click on. So, you can see that the majority of results are ecommerce category pages, but I'm actually interested in reading a comparison guide. This one happens to be the only one, so I'll click it.
It's pretty good. I read it, and I didn't return to the search results because I got what I was looking for. But this is just my experience.
What if seventy percent of searchers that enter this query each month click on the same page and behave in a similar way? That's a clear signal to Google that most searchers prefer a comparison guide. So logically, Google should rank that page higher and probably feature more comparison guides in the top 10 results, right?
All of that insight comes from a single click, the very thing Google has spent billions trying to master. Yet despite common sense and even a 2006 patent where Google explicitly states "results on which users often click will receive a higher ranking. " Google denies using clicks in their ranking algorithm.
In fact, in a 2015 AMA, Gary Illyes, an analyst at Google, said that using clicks directly in ranking would be a mistake. Four years later, he was asked if user experience signals like click through rates are used in RankBrain, a deep learning system in Google's algorithm. His response?
"Dwell time, CTR, whatever Fishkin's new theory is, those are generally made up crap. " "So I did that test, like, sixteen times between 2011 and 2013. Whatever event I was at.
And I'd be like, hey, let's all do it, t's really fun. Right? Like, let's go search for wedding dresses.
We're all we're all gonna click on the sixth result. Everybody disconnect from Wi Fi. And sure enough, you know, you could get it from number six to number three or number five to number two or or at MozCon, I think what the famous one was, like, page two to position one in the forty five minutes I was on stage.
" The leaked document also supports that click through rate is used in the system called Navboost, which helps Google learn and understand patterns leading to successful searches, just as Rand had theorized and tested. Now, Google isn't just using CTR and Navboost, but they also look at different types of clicks to understand user experience. The document shows different attributes like good clicks, bad clicks, and last longest clicks, among others.
And to put this discussion to rest, Google's VP of search, Pandu Nayak, confirmed in his DOJ testimony the existence of Navboost and how it helps find and rank the stuff that ultimately shows up in the SERP. But here's what doesn't add up. Google doesn't deny the importance of CTR for YouTube videos.
They even give us CTR data for keywords in Google Search Console, which is telling of its importance. So why lie about using clicks in search rankings? My best guess is to stop people from manipulating their search rankings and data.
"Back in the day when I had 400,000 Twitter followers who were active there, you know, I could put up a link to a Google search, get a click. Google shut that down, which I think is smart. You don't want people like me or anybody else being able to manipulate the rankings even for a short period of time.
" If Google publicly acknowledged clicks as a ranking factor, click farms and bots would flood the system, trying to manipulate the algorithms, just as Fishkin and others had tested. But many of these tactics became less effective and for some stopped working. And that's where Chrome data may have come to the rescue yet again.
"Essentially, they are using click data, which is a very elegant solution. Right? Because they know which Chrome browsers are real.
They know which ones have history. You can see in the docs. Right?
They've got stuff around, like, did this Chrome browser visit YouTube and watch YouTube videos? How much history does it have? Does it have a normal click pattern?
" As I pieced together this puzzle, a pattern began to emerge. Everything was connected to two key elements, Chrome and Rand Fishkin. In fact, Rand Fishkin pioneered a metric called Domain Authority that became a cornerstone for SEO professionals and ignited widespread debate.
This controversy only fueled the lie revealed in the leaked documents. Google doesn't use site authority in their rankings. Both Gary and John have stated on multiple occasions that Google doesn't use Domain Authority.
But the leak reveals a metric literally called site authority. But it's not as straightforward as it might seem. As Mike King pointed out in his analysis, Google could be playing with semantics.
They might specifically deny using Moz's Domain Authority metric or claim they don't measure authority based on a website's expertise in a particular subject area. This confusion by wordplay allows them to dodge the question of whether they calculate or use sitewide authority metrics. While these metrics may not be exactly what Google uses internally, the bottom line is this, site authority, whatever it means to Google, does exist.
So why deny it? "The site authority metric they had was in a section about quality. It wasn't in a section about links.
So I don't think it's site authority as SEO see it. " In the context of search engine optimization, site authority often boils down to backlinks. If you have plenty of quality links from authoritative sites, your authority score rises.
But what about for new sites that don't have authority? Well, according to some SEO tinfoil, it might be worse than you think. Thanks to something called the Sandbox.
The Google sandbox was a theorized place where new and young websites lacking trust signals, like backlinks, were placed and they were forced to wait it out. It was like SEO purgatory. The idea was that Google needed time to evaluate the quality of these sites, preventing spam from infiltrating search results.
For instance, if someone bought 10,000 new domains and flooded them with spammy content and purchased a ton of links, the Sandbox would spare Google from having to crawl those pages and potentially pollute their search results. But this also made it unfair for legitimate new businesses trying to gain visibility, which is probably why every Googler in this story has denied its existence. Cuts in 2005, Gary in 2016, and John Mueller in 2019.
In fact, the tweet you're looking at right now is from the Wayback Machine because Mueller deleted it. But the leak changed everything. In the per doc module of the Google algorithm leak, the documentation reveals an attribute called host stage used specifically to Sandbox fresh spam and serving time.
As I continued piecing this puzzle together, I became convinced that Google was intentionally lying to us. But the deeper I dug, the more I realized that I was solving the wrong puzzle. There was a key piece missing, context.
"These weren't ranking factors. We don't know what anything on that document is actually used for. Could be used for quality testing or evaluation.
We just don't know. " People like Matt Cutts, John Mueller, and Gary Illyes have devoted much of their careers to helping the SEO community better understand and optimize for Google search. And there's no logical reason to believe that they had ill intent.
Maybe they weren't even aware of the full picture. As Mike King put it, Google's public statements probably aren't intentional efforts to lie, but rather to deceive potential spammers to throw us off the scent of how to impact search results. So how should we, as content creators, webmasters, and SEO professionals move forward knowing that we can't take Google's every word at face value?
"We've got a test thing. And, you know, there's this fear right now that we're not gonna hear as much from the Google spokespeople because of what has happened here. And I think that's fine.
I think it's better if we spend more time using the power of our community to be doing this, sharing what we've learned, and continuing to refine our understanding. Because anything that they're gonna tell us is always gonna be aiming for the middle anyway, because they can't be specific about everybody's use case. " Test, verify, and share with the community, which is what we're trying to do here.
But with Google contradicting themselves time and time again, can we really trust them? Watch this video here to see how one of their core updates crushed a small business overnight.