okay good afternoon everyone thanks for coming to the breakout session on responsible AI in the generative era uh my name is Michael Kars and I'm an Amazon scholar which means I divide my time between AWS IML and the computer science faculty at the University of Pennsylvania at AWS along with my good friend and colleague Peter henin over here to my right I'm very involved in all of our responsible AI efforts within AWS from both the technical end enforcing various responsible AI diens that we care about as well as thinking about things from the policy legal
and Regulatory perspectives and everything in between and so the the plan of record today is that I'm going to take a little bit of time at the beginning um to first of all just talk about some of the science behind responsible ey ey these days and especially the challenges to that science that are emerging in the generative AI era and then Peter will take over after a little while and talk about how we kind of turn that underlying science into the practice of responsible AI in AWS AI ml products and services and hopefully we will
leave a healthy amount of time for Q&A towards the end um so I don't think I need to say too much about generative AI to any audience these days um I've been in this field for a very long time and I sort of missed the days when my non-work friends didn't care about what I did instead of having to talk about generative AI at every dinner party um but you know this is just a little demo um sort of showing you the type of thing that goes on behind the scenes in something like a large
language model where there's some initial prompt or context as we might call it and then the underlying model is Computing what the probability distribution over the next word is given the context so far and then of course the sequence is one longer and so you can apply the same process to the next token or word Etc and it's and because and there's great power in this first of all it's kind of scientifically incredible that just by solving this apparently myopic problem of next word distribution prediction you get so many things for free like syntax tax
semantics compelling coherent texts in a style of your own choosing um and also because of the randomization involved just because you're not always picking the most likely next word but you're actually drawing from the underlying distribution you get variation in the output so of course the same prompt will generate completely different output the next time and so this is an incredibly powerful technology that's you know become part of popular culture and Society at large these days and there are already a very very large large number of existing and rapidly emerging use cases for generative AI
it includes things like writing tools or Aids to check your grammar your spelling your style or the like or to suggest alternative phrasings of a particular sentence productivity tools like using a large language model to summarize the the transcript of a meeting and extract the action items from it using it as an aid in Creative content um of course many people know that generative AI can be used for actual code gener ation and so the all you know the universe of people that might be able to participate in software development in similar processes is greatly
increased by this and so the the excitement around generative AI is obviously understandable and well Justified and it brings great promise in new innovation and new products and productivity for us more generally as a Workforce but it also present some new risks and challenges and this is the kind of thing that Peter and I think about at AWS and try to um address to the extent that we can um using a mixture of the underlying science and other sorts of procedures and policies around just the general AIML workflow that we engage in if I had
to sort of say what is the one thing that distinguishes generative AI from all of the AI and ml that came before it up up until a few years ago it's the open-endedness of the output it's the open-endedness both of the input or the prompt or the context and the fact that instead of making Point predictions about you know a particular input like you know here is a digital image is there a cat in this image yes or no you're just making some binary classification or prediction here you're actually generating free form open-ended content and
of course that generality is part of the great power compared to traditional AI models but as we'll see it's also the source of some of the challenges that come up in curving behaviors that are undesirable in certain contexts and so what I want to do is spend a few minutes talking about the science of responsible AI in the pregenerative era or what I like to sometimes call the before times um and the the running example I'm going to use is say from Consumer Finance you know you have historical loan applications that you actually granted loans
to so you know the outcome of that loan and so you know whether it was repaid or defaulted and a natural thing to want to do with such data is to build a predictive model on that data that when you know you train on that data and then you hope that it generalizes as well out of sample so given a new loan application that you've never seen before you'll make an accurate classification and this is what I would call a very very targeted problem you know what problem you want to solve you want to give
loans to creditworthy individuals and not to the ones who might default um and you're making these very very narrow predictions you're just outputting yes or no um you know zero or one okay and so you know what are the kinds of things you might be concerned about in training a model for Consumer lending from a responsible AI perspective so of course you have to think about how you're going to train the model and the source of the data that you came that that you gathered for this process and so in particular if you have historical
data generated by human lending officers and they have some demographic bias in the decisions that they make you shouldn't expect training a model on that same data to eradicate that bias rather than perpetuate it and then of course if you're worried about these types of fairness or Equity issues you have to you know these are computers and models and data after all you have to figure out a way of basically defining fairness in a way that's satisfying to you and then enforcing it in the trained model and so a typical definition for instance In fairness
in a consumer lending application might be um equalizing the false rejection rates across different population so if you think about the two types of the the only the two types of mistakes that you can make in such an application either you deny a loan to a creditworthy person or you give a loan to somebody who's going to default we might argue and it's definitely debatable and there's many many different definitions of fairness you could adopt but a reasonable one would be across different demographic groups perhaps racial groups gender groups combinations of them that you don't
want the false rejection rate the rate at which you are denying creditworthy applicants to be wildly different between different racial groups different gender groups or the like and we know quite a bit these days about how to train models to enforce those kinds of constraints so instead of solving the normal optimization problem which is just minimize the error on the data in front of you period you instead you know solve the problem minimize the error on the data in front of you subject to the constraint that the false rejection rate not vary considerably across different
groups okay um and and there's a lot to say about this and there's a lot that's been written about it in the last 10 or so years um and and and so the the fact that we have this very very targeted use case and a model that's really only making one kind of prediction and has very prescribed outputs rather than open-ended outputs basically gives us a handle some leverage on solving this problem from an underlying scientific and Technical perspective so now I want you to engage in the thought experiment of like what would the analogous
thing be for a large language model what would it mean for instance concretely for a large language model to be fair or give approximately equal treatment across different demographic groups in a large language model and I want to try to convin Vince you that this is a much much more difficult problem and it's a much more difficult problem that we wish was a technical problem at this point but it's even more of a definitional problem than anything else and so I might give the example of um gender bias let's say in the completion or selection
of pronouns in the continuation of a prompt so imagine that I go to a large language model and I type in some prompt like Dr Hansen studied the patients chart carefully and then and you might expect the continuation in referring to Dr Hansen to assign let's say either male or female pronouns to a do Hansen um if you tried this on U large language models that were available a few years ago you would invariably get male pronoun completions from a prompt that involved a reference to Dr Hansen and so one thing I might ask for
in a large language model is that it not do that kind of thing if some kind of occupation is mentioned that the you know frequency of continuations should approximately equally respond with male and female and perhaps other pronouns as well but it's much more nuanced than that because there might have been things in the prompt that would change the distribution that I want over the selection of pronouns for instance and and of course this isn't just applicable to doctors but we might want to enforce the same kind of equity across many many different you know
every occupation you can imagine like firefighters nurses accountants lawyers what have you but then if I say for instance that Dr Hansen has a beard then you know do we still want to complete with male and female pronouns with equal frequency perhaps not um what if instead of mentioning a Dr Hansen The Prompt mentions a WNBA player the Women's National Basketball Association do we want that to complete 50% of the time or with some frequency of male pronouns and I'm kind of going I'm belaboring this for a minute just to point out how like this
even just figuring out what we mean by fairness for this particular problem of pronoun selection in the completion of a prompt where some occupation is mentioned is very very difficult to articulate and there's too many you know conditions that could change what we want the distribution to be and there's too many occupations and so this is very much a work in progress and people are thinking about sort of more General ways of measuring and then enforcing fairness the same way that we have a good handle on the science of for things like you know consumer
lending or more generally very um prescribed pointwise predictions and so the overall message here is that you can see that even just defining what fairness might mean forget about how you would enforce it technically in the context of large language models requires new approaches and solutions the science that we had on these topics up until recently will not suffice and doesn't obviously generalize to cases like this where the the output is much more open-ended and similarly things like privacy concerns have morphed in the generative era so what might what might privacy concerns be in the
case of traditional AI or machine learning like consumer lending well I might want the property that the train model doesn't let a third party exfiltrate or reverse engineer financial information so if your if your loan application was part of the training data you don't want somebody who can play with the you know input output behavior of the train model to actually be able to figure out what your loan application looked like unless you think that this is kind of an abstract unlikely concern you know it's quite often that any predictive model that's making a binary
prediction like the example I'm giving Will accompany that prediction with a confidence value it'll say like well I think this person will repay the loan and I am 70% confidence if by playing with the input outp behavior of the model you can find an input in which the model expresses 100% confidence that's almost certainly because that record was in the training data already and the model already knew what the outcome of the the loan was okay um and and so again these problems persist in the generative era but they become much more nuanced including in
ways I'll mention in a few minutes but one of them is just you know the the literal regurgitation of training data right you know you type in something like Michael kerns's address is and you don't want the llm even if my you know home address happened to be in the training data you don't want the model to regurgitate the output verbatim but now because the output is so open-ended you have the additional concern that like well it didn't output my home address verbatim but it had output some variant of it that's sufficiently close that with
a little bit of work anybody could figure out what it actually was and so the high level Point here is that the generative AI era has not only made traditional responsible AI dimensions and concerns exacerbated but it's introduced entirely new ones as well and I'm going to spend a little bit of time talking about each of these but they include things that you've probably all read about in the mainstream Media or elsewhere things like concerns around veracity like hallucinations you know the the output of the llm just making up apparently factual information which is in
fact verifi verifiably false there's concerns of course around toxicity of output you know if my out my model is outputting zero or one I might not like the prediction it's making but I it's unlikely that I'm going to call it toxic or offensive or disturbing um there are concerns privacy concerns that are starting to bleed into intellectual property concerns and this is a topic I'll mention a little bit later but that also of course um touches on the fact that our legal policy and Regulatory framework for thinking about things like privacy or copyright even didn't
anticipate the training of these models on you know um art artistic data or creative writing or the like and stylistic appropriation for example um and the same goes for for things like more traditional forms of data privacy so let me talk about hallucinations for a second I'm I'm betting that all of you um are familiar with the concept and may have in fact experienced hallucinations in your playing around with various llms um I don't know how well you can read this but basically the prompt here to the llm um asks it to tell to tell
us about some papers by me Michael Kars and um let me get here to where I can read it you know it starts off by saying Michael Kerns is a prominent computer scientist thank you very much it then correctly names several areas in which um I am a researcher and then and then it lists a bunch of papers um interestingly it seems to mainly have picked up on my Alter Ego in Game Theory rather than machine learning but that's probably because once it started generating tokens from the Lexicon of Game Theory then it continues to
do so because that's you know sort of reinforced what the context is but what I could say about these papers if we went through each one of them is that um two of them are entirely fictitious papers that I never wrote with co-authors that I never wrote and the papers don't even exist but they're all plausible right and the co-authors actually exist as real people that whose names I recognized um two of them none of them are actually entirely correct two of them have true titles but with co-authors with different co-authors than the papers I
actually wrote with one of them mentions Ken Arrow as a co-author he's a uh the the late Nobel prize winning Economist I wish I wrote a paper with can Arrow but I didn't but this is what we mean by hallucination and if you understand how an llm works it's not hard to see why this happens because you're you're not actually going out and looking up citations you are just generating words from the Lexicon associated with whatever my footprint in the training data was at the time of the training of the model okay um let's go
on to talk about toxicity and safety for a second and again you know what might what I'm trying to do with my time here is just not point out to you sort of what the solutions are which people like me are actively thinking about but just what some of the nuances are in even asking figure out what you want to to enforce so for instance you know toxicity and safety so you know there are many passages that are quotations from famous writings and novels if an llm outputs a quotation that might be considered offensive by
some or even many but it clearly identifies it as a quote from a well-known you know text do we want to suppress that I mean it depends on the context probably it depends on who's reading it we wouldn't want to put it in front of children but we wouldn't want a blanket suppression of it because that might amount to a form of censorship okay um what about in a similar vein what about people's opinions that others might find distasteful but are clearly marked as the opinions of that individual and so one of the thing I
think one of the things that Peter and I have realized over time in the generative era is that you know we need to find some Middle Ground between the generality of things like large language models and enough specificity in use cases that we can start to imagine what the constraints might look like so what do I mean by that well what I mean by that is if I'm using a large language model as a creative writing Aid and I'm writing you know novels or short stories for adults then I might have a certain tolerance for
certain amounts of content that people might call toxic for instance you know you know vulgar language for instance if I'm using an llm as a writing aid for children's book you have zero tolerance for that obviously and so once you start to say even within a broader use case like content generation exactly what the use case is what the audience is then you can start to come closer to articulating the constraints that you want to enforce and ideally you would like to be able to write them down in a in almost a mathematical formal language
so that you can constrain the training process to obey those constraints and so you know many of you are probably familiar with the fact that a lot of the large language models that we have around today are are sort of trying to approach some of these problem with so-called guard rail models so things like toxicity detectors that are applied both to the prompt and to the output and they perhaps even have a knob on them that can set your tolerance for how much toxicity you want what types of toxicity you want because of course you
know if you look at the literature on toxicity classification and detection it's not just toxic or not toxics it's what type of toxicity what type of content is it vulgar language is it images is it other disturbing content Etc and what is the severity of it um intellectual property is another area that now is front and center in the generative era because now of course we have concerns like this example where we've gone to a image generation model with the text prompt that says um you know create a painting of a cat in the style
of Picasso and you know this is in some strange Gray Zone between privacy um and things like copyright because you know um the Picasso estate or the Andy Warhol estate like these images the original images they're not private data they're not like your loan application or my home address they're in the public domain and perhaps the artists or writers want them to be in the public domain but they didn't anticipate them being used to train a model that then is engaged in some kind of perhaps stylistic appropriation and so again it's hard to say exactly
what we want you know in one context you might call it um a hallucination and in another you might call it a generalization in one case you might call it stylistic appropriation in another case you might call it sort of you know appropriate creativity um and this is I think an area that won't have purely technical or scientific Solutions but it will have to involve um our legal system adapting to the unforeseen training of these models and the use of this kind of data and so let me just conclude by saying you know I've I've
told you about a lot of problems and I've told you about a lot of problems that have gotten harder not just to solve but even to conceptualize and and sort of Define what we want in the generative era but there is quite a bit of science going on I mean I know many people in my field that more or less I would describe as they've stopped doing whatever they've been doing for their entire career to work on responsible Ai and so you have a lot of very very smart people that are thinking hard about these
issues some of these things I think will have Technical Solutions kind of like the fairness constraints I Des described in consumer lending others are going to require a strong public policy legal and Regulatory framework but you know to just to mention not all of these but um things like um um red teaming or water marking sort of water marking in order to identify content that was generated by an llm so that people aren't getting fooled by AI generated content in inappropriate ways um the somewhat distasteful phrase model discouragement and machine unlearning refers to sort of
an emerging science around how do you take a model that's been trained and sort of remove the effects of particular pieces or subsets of the training data on the output of that model ideally in a way that doesn't require retraining the model from scratch which if you know about the size and expense of training these models is completely infeasible to be doing like on an ongoing basis every time somebody wants you know their their data to be removed from the training process and so there's a lot going on scientifically and I want to now turn
it over to Peter to talk about um you know how we take all of this science and the challenges that generative AI presents and sort of operationalize it within the context of AWS products and services Peter take it away all right thank you Michael so let's all right so for a little bit of context I lead a central team at AWS that advances the science and practice of responsible Ai and that means that we live these ambiguities that Michael has been discussing over the past 20 minutes um every day of our life so let me
just start with a little bit of level setting okay to make sure that everybody's on the same page um I want to observe that ml software is not smart traditional software okay there's a couple of fundamental differences from which a lot of stuff flows um first one is that with ML Solutions right um we spec with data as opposed to traditional software where we're specking with human language okay that causes problems right up front if you're an ml team and you go out and you ask a data team to build you a nice data set
one of the first things they are likely to do is try and deliver very high quality data which means they give you an extremely detailed uh uh sort of set of guidelines for the people building the data set what that really means is that they tried to write down in English you know what the manifold is that they're asking uh the data team to label which is completely contradicts the point of going to data in the first place because you couldn't write down in English if you could you would have done that the sort of
uh historical feature engineering so that's actually a big difference right off the bat the second one is that with traditional software right customers do not expect to test it should just work right out of the box with ML Solutions customers must test this is completely different all right as soon as you introduce privacy that means that it's possible that someone submits data into the system that is has assumptions that differ from the assumptions on which it was trained and only the person submitting the data can know that so there's a testing expectation with that testing
expectation comes the expectation that you know how to build data sets you know how to judge the results etc etc so another big difference third one um with traditional ml software right I sorry with traditional software um when you release version n+1 you expect it to work as well as or better as version n on every single input not so with ML Solutions on ML Solutions new releases are going to work better with respect to some Metric for example the average which means you can have things stop working for a particular person or a particular
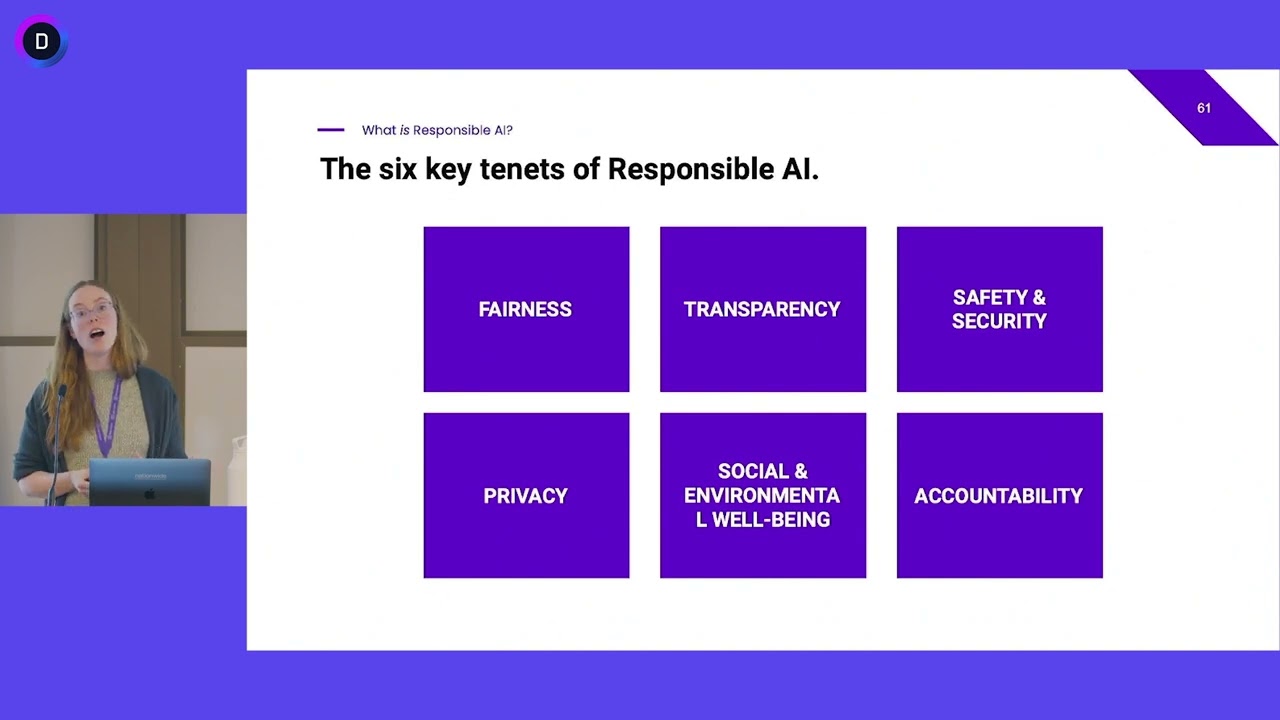
input that worked before and again you have to have um you know processes in place to handle that so this doesn't change with geni all right so that's that's kind of the base level of stuff that we we have to worry about and all of that means all of that means you have sort of the shared responsibility between providers of models and deployers of models okay so that's that's a fundamental point now on top of that we layer what we consider sort of considerations or dimens of responsible Ai and Michael has talked about a number
of these but there are more still um we have in the age of geni we have the issue of controllability right which is about making sure that you can steer and monitor uh your model to achieve its uh desired system behaviors I can't I think in the worst case people are wondering or worrying about some people may be worrying about Skynet and something running a muck well you know do you have control lever right that you can employ to steer this thing and do you have monitoring mechanisms to make sure that in fact it's doing
what you expect and we have privacy and security which Michael talked about and safety um and fairness and then veracity and robustness those are there um we also have explainability transparency governance all of these are issues that you have to juggle when you're deploying um ml Solutions and you need to juggle these kind of properties of your of your application of your model of your supply chain on top of those issues about the shared responsibility model all right let me just pause I hope this isn't just raising a lot of concern it's a lot to
juggle um but there is a way forward we have a framework that we use to think about how we make our investments in this obviously leading it is our investments in science um then we have a lot of work that we put into translating the science into practice um and then thirdly we spend time thinking about how we bake all of this into the entire ml devop cycle um and then finally we also think about you know the people how do we who do what stakeholders do we engage how do we educate people Etc so
I'm going to cover uh since Michael covered the first box to some extent I'm going to cover the second third and fourth and uh try and leave everybody optimistic that in fact we can make progress in building and operating responsibly okay so second box Theory to practice let's talk about uh sort of some secrets to success and I think Michael was highlighting uh this one in a number of cases defining application use cases narrowly and I'm going to dig into each of these to make sure that they're clear second one matching the process your development
process your operating processes to the level of risk third treating data sets as product specs fourth distinguishing application performance by a data set um and five you know operationalizing the shared responsibility model okay so these are just five things to consider let's dig into each of these so what does it mean to have a narrow application case all right A lot of people think okay face recognition that's a use case it's not here are just three flavors uh retrieving an image from a gallery could be for uh you have a found child and you want
to look up the child in a in a gallery of missing children or it you know could be some other Gallery retrieval um celebrity recognition looking up a celebrity in a database of uh production video it could be a virtual proctoring application right but each of these although they employee face recognition have different kinds of variation that you have to worry about different kinds of biases different consequences for an error and different ways in which you tune the system so that you you know don't you have sort of fewer of the errors that are more
costly so for example with when you're retrieving you know images let's say in the the missing child case right you really want to return as many matches as you possibly can but in the context of looking up a celebrity to find a clip in a video right you're going to get lots of hits so there you're not going to tune it for you know Recall now in the Gen case you have the same kind of sets of issues suppose that you want to catalog a product uh versus persuading to buy these are you would write
different things if you're a human right then you would uh you know if someone just says well in general Des you know write write some words about a product so when you're cataloging excuse me Catal cataloging a product you are probably intending there to be sort of a broad demographic anybody can read the catalog you want to worry about veracity you have uh the consequences brand damage lost sales returns you're going to when tuning it you're going to favor neutrality of the language Clarity completeness um but when you try and persuade someone to buy you're
probably going to Target a narrow demographic you're going to have additional issues with unwanted bias like how are you you know how is the llm thinking about this demographic you have greater consequences if it shows unwanted bias in terms of Representative harm for example um and when you tune it you're probably going to try and tune it to sort of zero in not on a complete description of the product but on the sort of the the particular problem that this demographic is most interested in and the benefit uh to that demographic so it's the same
thing traditional AI generative AI zoom zoom in on a narrow use case and I I just can't emphasize this enough because if you go broad you're going to get into trouble you're not going to be able to Define what bias really means you're going to end up doing worst case risk you know risk analyses which tell you not to do it um so so this is absolutely critical as a first step um second thing risk-based approach okay if your application is recommending music versus say identifying a tumor it's very clearly like different consequences for getting
this wrong all right so you need to have a systematic approach to assessing risk within the organization first piece of advice is to align with the NIS uh framework um second thing is to realize that uh you know in some contexts uh risk you know people worry about risk to their own organization but in this situation we're worrying about risk to the stakeholders okay it's not about saving your bacon it's about saving their bacon all right so you want to identify all the stakeholders both in the development process imagine the people who are labeling suffer
tox it um and on the usage side um and people who you know might not be included uh in the process of building it as you know many llms just focus uh on English right and there's reasons for that but nonetheless that means that there are groups which are not being served as well as those things so go through identify the stakeholders identify potential events negative or positive estimate likelihood and impact of each event aggregate the risks and then choose development and operating processes that are appropriate to the level of risk okay this is really
not easy to do like you can get in you know very extended arguments with people uh on what the actual likelihood and impact of a particular event is right it takes sort of a social process of uh sort of you know forming storming norming performing before you get everybody able to consistently uh assess risk um but it's it's critical then treating data sets as specs okay we said before data sets data sets are particularly key here so take a look at what's actually in the input um anticipate Global diversity so for example to pull on
the traditional AI example of doing face recognition right you may be familiar with people talking about skin tone in terms of having you know five maybe 10 variations but the actual curve if you go and look at it is this sort of banana shaped curve in RGB space it's much more complicated and you want to sort of accommodate the full diversity that's out there you have to think about the difference between intrinsic and confounding variation make sure your data sets have it and use lots of different data sets um gen it's going to turn out
to be the same thing your data set is encoding your design policies all right um distinguishing application performance by data set um this is also absolutely critical to internalize uh performance is a function of an application and a data set not just the application and I know this goes against everything people want they want to say this model is good or this model is bad or this model works this model doesn't work um and that's really just not the way to to think about it the issue is how well does a model or application perform
on a particular data set so you know what we might imagine right is that over time model performance um increases as you rev the model and get better right against a particular test data set a right but there might be some other test data set B on which it does even better over time or there might be some test data set C on which it gets progressively worse over time all right all of these are possibilities but what this really means is that when you're developing okay both in the Trad space and in gen okay
you've got to worry about two development trajectories the trajectory of the model and the trajectory of the data set because very often people are evolving the data set it's not constant and every time you evolve the data set you're jumping the data set from a to c or a to b or something like that okay so another critical point in terms of doing this practically now in terms of sharing responsibility upstream and downstream if you want to operationalize that okay lots of things to do you have to think ahead all right if you're a model
provider as for example Amazon is with uh its Titan family right you need to anticipate Downstream use cases if you're Downstream you need to Define your application use cases narrowly but Upstream it's a little it's even harder right when you anticipate diverse Downstream use cases you still have to sort of treat them narrowly and say these are going to be some things that you really shouldn't do and these are going to be some things that you really are you know that we're really designing for um you've got to both on both sides assess risk and
select the process on both sides You're Building data sets Upstream You're Building data sets to train and evaluate Downstream you may not be building but you still need to evaluate so you still have to build data sets testing the component on the component on anticipated data Downstream testing end to end just because a particular llm or Foundation model has been tested you know out the wazo by lots of folks doesn't mean that you can assume therefore that you can just drop it into an application and you're okay you should test your application end to end
and make sure this whole thing is really working as you expect okay sending feedback you know if for example we're using a vendor to help us build a data set okay and we learn something we're going to give them feedback similarly if someone you know Downstream deploys an Amazon service and has an issue they got to let us know uh the communication has to go you know Upstream and downstream um and then you also have to act on what you've learned right that's absolutely critical so think about if you're going to be deploying you know
gen within your organization either internally or you're Building Products based upon it think about having processes in place to deal with each of these issues so one example of the way in which we do this is that we've introduced last year these things we call AWS service cards they describe services from the point of view of not a scientist or an engineer we have model cards and data sheets for things like that these are trying to educate sort of a more non-technical audience about appropriate usage of a um of a particular service so anyway just
one example all right so let's move to the third box where we talked about um you know first we talked about Theory to practice then we talk about okay well we know what good practices are we have a set of good practices how do we kind of embed those throughout the entire ml devop cycle right so here's a cartoon of the devop cycle everyone has probably a different favorite cartoon this is just one of them um and the question is is like where do we where do we think about these issues and the answer is
going to be as you probably can expect absolutely everywhere right every single stage you got to sit down and think about how does controllability fairness privacy security robustness how do all of those issues play out in this particular you know block of the of the cycle um let me just pick one example which is uh at the very beginning if I can go back here right we had a ml problem formulation box over on the left hand side there um okay so you know a fundamental question is just asking whether or not ml is appropriate
all right so how well do humans perform on the same tasks what task are humans really solving right might your system be repurposed you just like kind of ask the big questions give yourself space and time to do this um let me give you some a few examples we have had people ask you know can you build a loitering detector for example loitering is a you know say in the context of uh you have video sort of security video of your store and you want to know if someone is loitering so you can your security
team can take some action okay well loitering is a value judgment uh you don't want the system making value judgments how is it going to do that you cannot that's not a good system to be thinking about building all right can you do sort of a number of human standing in some location for you know a certain time period yes all right that's that's much more practical um all right stylish clothing two years out could you predict that well what are your input signals going to be I would say this is kind of a question
mark try it but uh good luck um this one write ad copy for a group for red and blue 64 inch diameter golf umbrella all right so in general can you write persuasive ad copy well maybe you can if you use demographic groups that are defined by the task that a particular person cares about but maybe you're going to get into a lot of trouble with LMS if you try and use kind of standard definitions of demographic groups that represent intersections of gender age and ethnicity or something like that because maybe the llm hasn't really
you know and how could it like code what the biases of those folks might be so anyway ask those questions um and here I think you know if you if you reflect upon this I think it's also good to appreciate that that you have a very powerful tool in deciding what your system will do and what it won't do you do not have to build a system for example that handles the full diversity of the planet in every possible situation um if you had to do that every time you would probably never get off the
ground how would you get all the data that you needed etc etc be enormously expensive and you might build something that eventually people didn't even want and you have to learn that so you have this lever which is transparency you can elect to say to folks okay these are the circumstances in which it's intended to be used and this is how it works um and everything else is kind of you know either unknown or or at risk and please don't do it or do it with full knowledge that you're going to have to do extra
testing okay so you know you have this lever that you can you can choose uh to to operate all right so across the ml life cycle um we have a number of things that we deploy I think the primary thing to make everyone aware of is people we have a partner Network we have a geni Innovation Center we have solution Architects um there's a lot of complexity as as Michael was pointing out and as I have sort of taken you through a bit uh up to this point and so th those folks can be extremely
helpful um we also have tools on Sage maker we have data Wrangler we have ground truth we have clarify we have model monitor we have ml governance tools for example model cards um and we have the internal team um that that uh focuses on helping all of our service Advance the science and practice of responsible AI so we have a lot of investment on this um and the outputs you can see in services like Amazon code whisper Amazon on Titan right on the code Whisperer side we have data that's private and secure we have content
filtering we have built-in security scanning we have attribution uh for you know sourcing um we have indemnification we have on the on the Titan side we have again privacy security content filtering we have human Enlightenment through you know reinforcement learning and through supervis fine-tuning we have knowledge enhancement via rag uh orchestration customization so there's lots of investment going into these all using the principles that we've uh talked about uh previously all right so let me finally switch to the uh the the bucket around people um I have sort of walked through a lot of challenges
and if you're in an organization which is either trying to deploy a geni application internally or build one for its own customers right there's going to be some process that you go through of building awareness sort of establishing foundational skills seeing capabilities emerge you know and then sort of finally baking it into your operations and you have to just sort of set upon this journey explicitly okay and as you go down this journey you can't just expect it to happen without you know thinking it through I think one of the things I want to call
out is that uh responsible AI is not something purely for your technical teams for your scientists and for your engineers it's absolutely crucial that your product managers uh be in the center of this okay so you know at Amazon we have this kind of tier where you know foundational principles around human rights and sustainability are things that you know we um we pursue across the company and then we have on top to of that the set of normal stuff that any product manager is worrying about use case accuracy feature set latency cost uptime um and
then on top of that you have all the raai things that we were we were worrying about right and so you're going to inevitably find yourself you know in some situation where you know the things on the bottom are things you cannot trade off the things in the middle are things that people are trading off today in the normal course of business you know do I want this many features that's going to come at a higher cost if I lower the features lower cost that kind of thing and then the the raai properties are also
going to have potential tradeoffs all right um and those need to be made explicit and again if you happen to have gone down the path of having narrow use cases it's much easier to understand what those tradeoffs are and to communicate them so that people and have a good experience using it and then the last thing I know it may sound a little much but participate in other words you know you're in your org you're trying to develop your capabilities within your org but you you know there's a lot of uh there's a lot of
activity on the policy side on the legislative side on the regulatory side and you need to participate as much as you can in those processes ISO 4201 is going to be a Lynch pin of the EU AI act right but there's 30 other standards roughly that are also in development okay and the folks developing these standards are trying to do the best that they can but the more input they have from people who are actually building and deploying applications the more likely these standards will actually be effective all right so that's for example why we
participated in the White House voluntary commitments we participate on lots of standard bodies but we would encourage everyone else to do the same so let me okay if you want further information all right we have a couple of uh actually we have three not two not two um pointers for you uh one you can hear more from Michael at the first uh at the first link the second one you can uh learn more about the White House commitments and the third one um gives you more information on getting started with Gen with our services um
all right so I want to thank you at this point we've got about 11 minutes left um