[Música] agora agora a gente vai falar um pouco aqui da da das tpus que foram utilizadas né todo mundo já já conhece né o sistema aí imagino do do CNJ que mantém as tpus então a gente tá falando das tpus relacionadas aos assuntos certo e como é que funciona né Mais ou menos o vamos dizer assim a estrutura né desses dessas tpus né Elas TM essa estrutura que se caracteriza por uma hierarquia né então a gente tem uma uma estrutura hierárquica e aqui a gente usou A nomenclatura né que é comum a gente chamou esses
assuntos que são os assuntos que estão na no nível mais genérico né vamos dizer assim tipo Direito Administrativo Direito Civil né esses assuntos a gente a gente chamou ao longo do nosso do do projeto de assuntos raiz certo e a gente viu que tem alguns que é os são os assuntos mais específicos né que são os assuntos do tipo folha certo então a gente tem esses tipos principais existem assuntos intermediários aqui que não são nem raiz nem folha né então a gente tem basicamente essa essa estrutura que que define os os assuntos jurídicos dos processos
certo acontece que no dado que a gente recebe a gente recebeu né a gente verificou que tem eh petições em diferentes níveis hierárquicos né existem petições em onde foram colocados o assunto mais específico e petições onde foram colocados assuntos eh intermediários aqui ou até mesmo assunto raiz certo então a gente fez uma uma análise da ocorrência de cada tipo cada nível desse dentro das petições certo uma outra coisa importante de de falar que a a essa aqui na verdade não é as tpus que a gente utilizou a gente utilizou a TPU que que veio junto
ao aos dados né No No início do projeto uma tabela chamada assuntos né que veio junto no início do projeto que a gente recebeu e que lá tinha essa mais ou menos essa estrutura dizendo Quem era o pai de cada assunto né e a partir daí a gente construiu a TPU Eh vamos dizer assim que é utilizada pelo CNJ pelo sistema mesmo né então qual foi o processo pra gente construir na verdade né definir os assuntos que a gente utilizar pro classificador né porque no fundo o que a gente quer é classificar em um desses
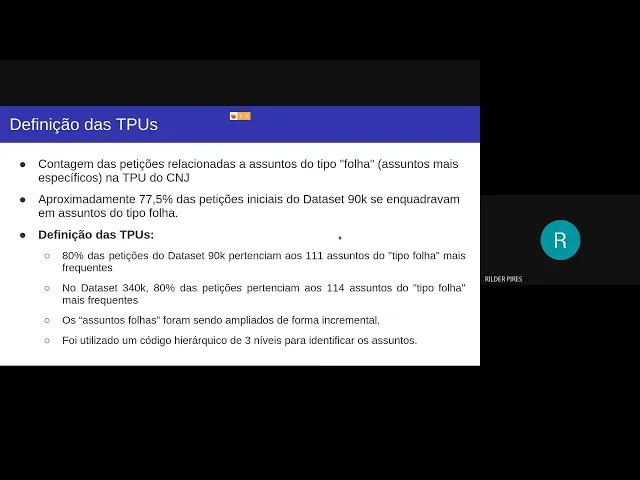
assuntos né mas eh em conversa né com com o pessoal do CNJ a gente chegou à conclusão que esses aqui não seriam interessantes né assuntos do tipo galho por exemplo raiz a gente então tinha que que ir atrás dos assuntos do tipo folha certo e aí para isso a primeira coisa que a gente fez foi uma contagem das petições relacionadas a assuntos do tipo folha né os assuntos mais específicos da TPU e a gente verificou que aproximadamente 77 isso no data 7 90 Car certo 77,5 das petições se enquadravam em assuntos do tipo folha uma
coisa que a Raquel mencionou aqui que é importante a gente ter em mente é que eh o dado ele não foi passado todo uma vez Então a gente foi recebendo esse eh datasets e incorporando datasets na nossa análise então a gente meio que fez também uma construção desses assuntos de forma incremental né a gente foi ampliando os assuntos que a gente ia eh colocando no classificador certo então a a primeira análise que a gente fez foi essa certo então a gente já filtrou aqui pra gente utilizar apenas para o classificador a passar apenas petições que
tinha aunto do tipo folha Ok já que era o alvo da nossa classificação Então qual foi o processo para construir a vamos dizer assim a nossa TPU né a a TPU que a gente vai utilizar para classificar a gente sempre eh fez uma uma análise das dos 80% de petições que a apareciam né os mais frequentes né os tipos mais frequentes então a gente por exemplo no dat 7 90k que foi o primeiro que a gente recebeu a gente viu que 80% das petições pertenciam aos 111 assuntos do tipo folha mais frequentes né Eh esses
assuntos eles não não tem uma frequência uniforme né você tem vários assuntos que são pouco frequentes e assuntos que nem nem apareceram né Depois do dos nossos filtros eles desapareceram certo e outros que nem existiam né no D sets entendeu então assim dos 4000 assuntos lá só 111 deles concentravam 80% das petições E aí a gente guardou essas esses assuntos do tipo folha e aí a cada à medida que a gente aparecia um outro dat set a gente refazia essa análise para descobrir quem eram os assuntos mais frequentes novamente né então a gente por exemplo
já no no dataset 340k que seria o o final né que a gente já tava a gente viu que 80 por das petições pertenciam a 114 assuntos do tipo Folha e que esses assuntos não necessariamente eram os mesmos daqui né tinha assuntos que tinha aqui que não tinha aqui tinha assunto que tinha aqui que não tinha aqui certo então o que a gente foi fazendo foi os assuntos foros foram sendo ampliados de forma incremental Então sempre que a gente colocava um dataset o o nosso conjunto de assuntos ele englobava tudo que já existia antes todos
os assuntos que já assuntos fol que já existiam antes certo então a gente foi fazendo isso de forma incremental isso é interessante para por exemplo caso seja necessário né um dia vocês quiserem por exemplo eh adicionar um outro dataset né para treinar então você pode fazer esse mesmo mecanismo né você observa os 80% né quantos assuntos correspondem a 80% das petições E aí você incorpora você nunca remove assuntos certo então uma outra coisa que a gente utilizou foi um código hierárquico de três níveis para identificar os assuntos certo a gente fez algumas versões do classificador
e a gente viu que pra gente compatibilizar entre os tipos de classificador e e e também utilizar essa informação que está na estrutura né da TPU eh seria interessante a gente usar um um código hierárquico né e a gente viu que três níveis era era uma quantidade boa de níveis que contemplava muita grande parte dos assuntos da TPU né então como como foi construída essa estrutura né primeiro a gente a gente pegou as folhas né que a gente selecionou e saiu organizando ela dentro dos níveis da TPU original Então os assuntos do nível um da
nossa hierarquia são os assuntos raiz da TPU CNJ o TPU que a gente recebeu Ok então eh são os os os mais genéricos Ok então direito do consumidor por exemplo Ok E aí a gente Manteve também os assuntos do nível dois que são os assuntos cujo pai né ou seja o diretamente superior a ele era um assunto raiz da TPU do 100j e a gente Manteve as folhas e chamou essa de nível três então a gente meio que deu uma uma organizada na TPU de modo a manter apenas folhas que eram frequentes não teria sentido
manter no classificador assuntos onde a gente não tem eh frequência para treinar Então a nossa nossa TPU vamos dizer assim ela ela é construída dessa forma você mantém aqui as folhas você mantém os os dois primeiros níveis da TPU original certo uma outra coisa que a gente adicionou foi um assunto genérico outros dentro de cada nível dois certo dentro de cada nível dois a gente colocou um assunto outros que ele serve para contemplar esses outros assuntos que são pouco frequentes certo a ponto de cair nos 80% mas que tão lá no nosso dado certo então
a gente coloca aqui dentro desse assunto outro então foi dessa forma que a gente construiu a nossa TPU vamos dizer assim né E para meio que não ter confusão e às vezes eh assim a gente percebeu que por questão de algumas tarefas que a gente fazia era interessante um código também hierárquico então a gente tem código códigos hierárquicos para eh definir cada um dos assuntos da TPU que causam menos confusão por exemplo quando você tem coisas assim né Você não sabe quem é o pai desse cara e aqui a gente consegue guardar essa estrutura Ok
então foi mais ou menos essa a ideia que a gente utilizou paraa construção da TPU que a gente vai utilizar na a gente utilizou no caso SK [Música]





![I Replaced ALL my ADOBE APPS with these [free or cheaper] Alternatives!](https://img.youtube.com/vi/5EfqHg49kMk/maxresdefault.jpg)














