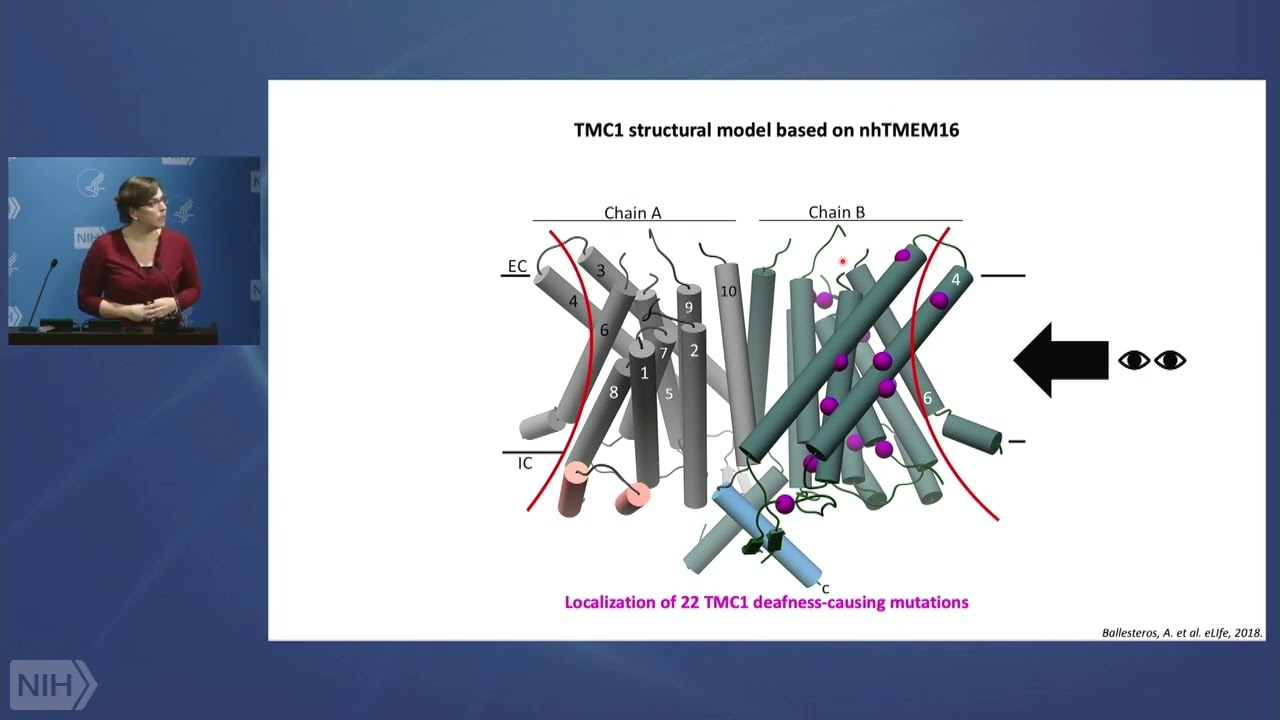
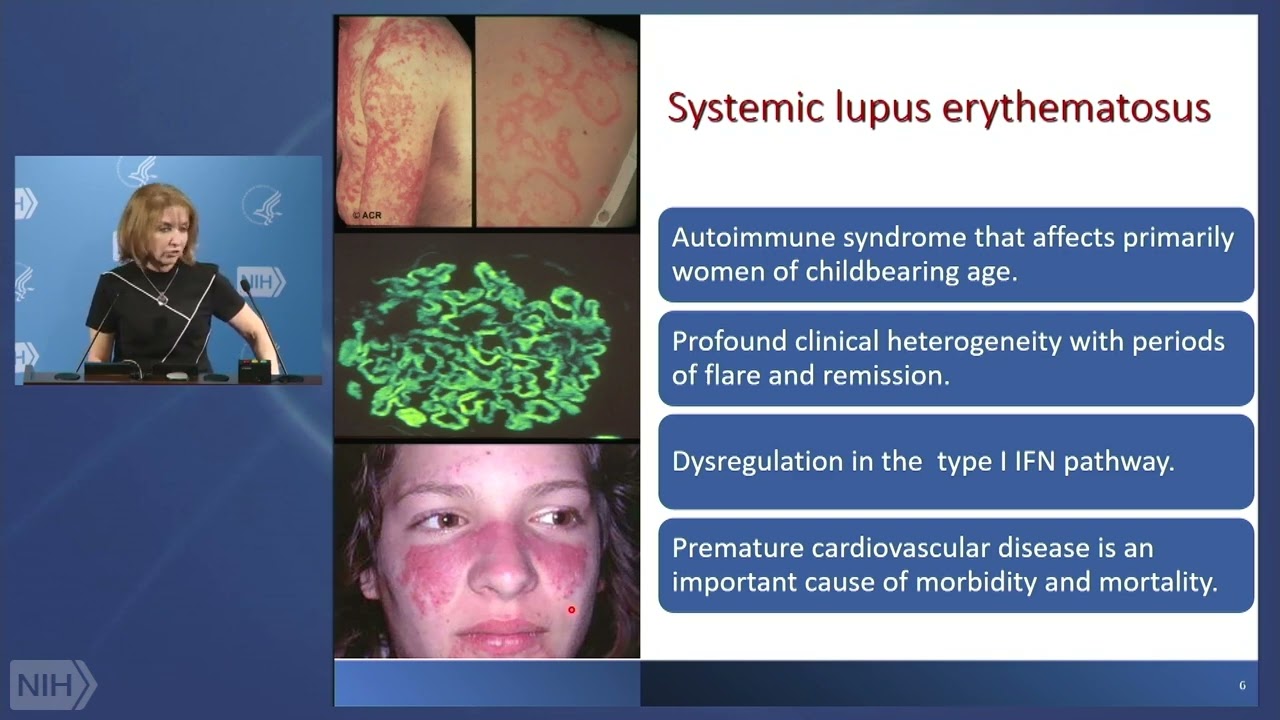
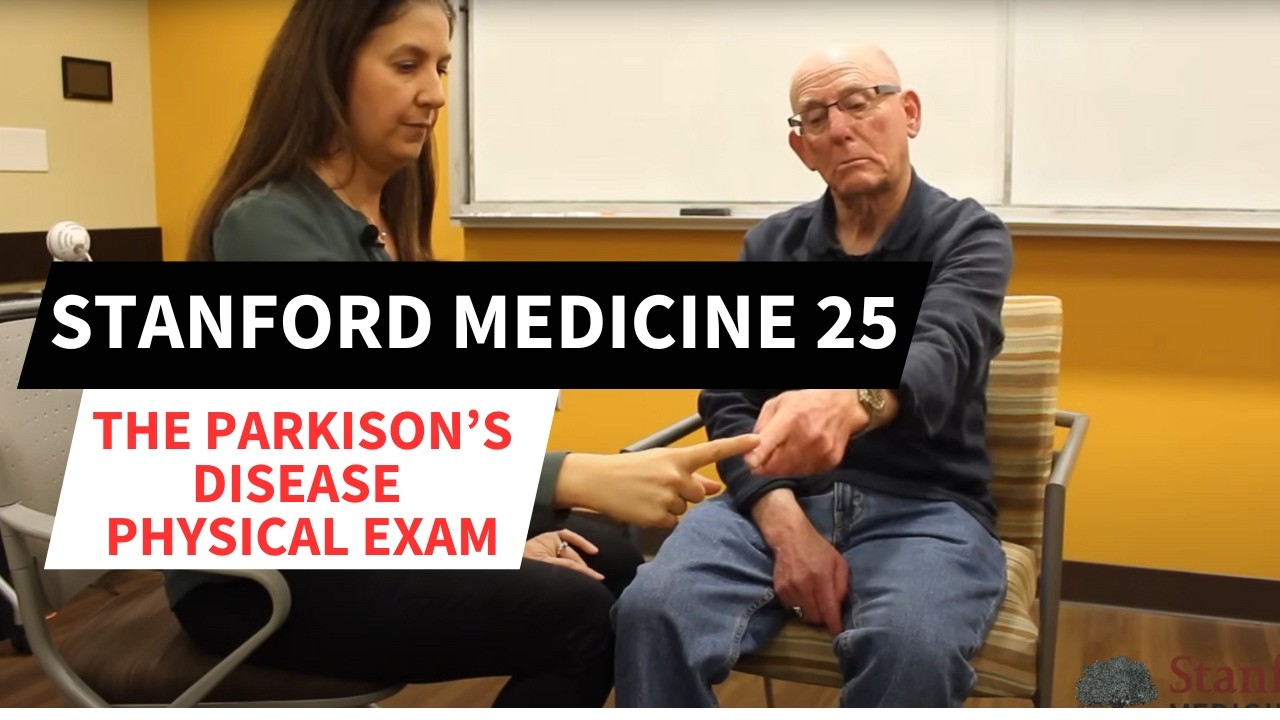
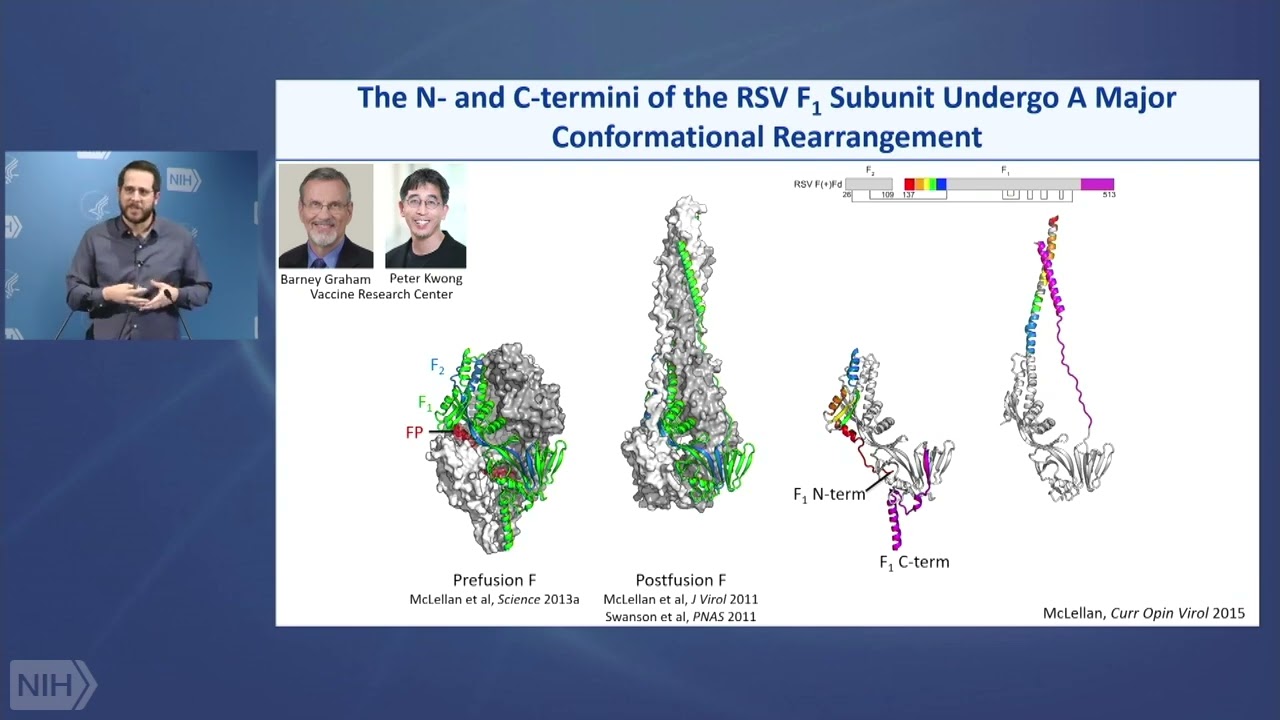
So, a few more things about study designs. Your number one question is how good is your primary research question? At the end of the day, when your research is done, and your data analyzed, will the answer -- regardless of what the answer is to the primary research question, advance scientific knowledge or clinical practice?
If it does not advance scientific knowledge or clinical practice, if it does not at least lay the necessary foundation that's missing to advance it, you have failed, and you don't have a good primary research question. I'm not saying that you answered the question the way you hoped it would be answered. But you know, does a failed -- like, if you get the exact opposite answer, does that still advance science?
It's an important thing. If you get a negative result, not that positive result you're hoping for, that's still important. The second most important element is a good primary outcome measure that's clinically meaningful and simple.
I now have to write and turn these endpoints for studies into labels that the American public can read and that the prescribers can understand. It is really hard to interpret some of these endpoints. It makes sense when you're trying to cover all your ground to combine all this stuff together, but as you get into the discussions of measures and endpoints in this course, you'll realize it can be very hard to actually express it and explain it to somebody.
But I want to give a little bit more information about how you want to start designing one of these lovely studies we're just talking about. You've got study aims, your background, your rational, then you're going to talk about the endpoints, the outcome variables, any assessment you're going to take on the people in your clinical trial, or the animals in your trial, whatever's in the trial. What are your assessments?
Be specific. Don't tell me you're measuring sleep, folks. Tell me exactly how you are measuring it.
Talk about -- think about the specific elements. Is it sensitive to change? Do not take a wooden ruler and try to measure my waistline.
That is not a good way to take that measurement. You want something that's reliable. You want something that's valid.
You need to know all this information about those measures you're going to use because the measures are what you're going to use in some combination to get that actual final endpoint. Think about your inclusion/exclusion criteria. Can you measure all of these things on the people in your study?
We'll talk a lot about this, and Wendy Weber will talk a little bit more about it when she talks about protocols, too. So you have to make sure people are legal to be in your study. But sometimes I see so many exclusion criteria, I'm like there's nobody left in this world that can be in your study.
So you've got to balance and think about safety. Like, you know, can they not ethically be in your trial? And after that, you might want to let everybody else in.
How do you start designing? Think about that accrual plan. Think about the preparatory test.
What's the timeline for your overall study and for the individual participants? Do they have to come between 9:00 a. m.
and 4:00 p. m. on days that they are likely to work?
That is going to make a big problem. Yeah, someone's like raising their head and I'm like, yeah, that's right, it's a problem. Treatments.
What are the participant implications? So I was in a trial, and I couldn't take certain antibiotics. So then, of course, I get sick and I need an antibiotic.
So there was this back and forth about what drug I could actually take. But you have to think about the implications on your participants. What is the exact product?
What is the exact dose? What about the quality? How is it administered?
Can you reproduce the intervention? Whether it is a drug or whether it is yoga, can you actually reproduce that intervention? So if I say yoga, exactly what type of yoga is it?
Am I doing it once a week? Six times a week? What's going on?
Does it interfere with patient management? Again, kind of my being in that trial interfered with my doctor trying to give me a medication. Generalizability is often lost in this quest for specificity.
So you have to decide and balance. And at different parts of your scientific knowledge, you may decide to have more or less generalizability. Specify the criteria for withdrawal from studies or a deviation from the protocol definitions.
If they do not show up at exactly day 72, does it matter? Or is it day 72 plus or minus seven days. Like, what are the windows for every assessment?
Sometimes you have to be super precise and sometimes you can be a little bit looser. Sometimes someone may need to go off intervention, but they do not need to leave your study. You can still follow them and take the assessments.
You want to have a list of all the concurrent medications, procedures, et cetera, that are prohibited, permitted, and how you're going to record them. Do remember, it's not just medicine, folks. These people are drinking teas, they are taking supplements, they are taking over-the-counter medications.
Do you want them to still do Tai chi or go to spinning class if you are studying yoga? You need to think about all the different things they could be doing that might interfere with what you're studying. But also, you have to think about, you know what, sometimes people are going to get headaches and what are they going to take?
Like, don't tell them to disavow or not do anything because you'll get nobody in your study, or they'll do it anyway and just not tell you. So what is the dose? It might be the number of sessions, or pills, or treatments.
It could be social media attempts. So if some of these studies are in fact trying to actually tell you, like, all right, we want to give you information about your cigarette smoking. Well, do I give you one text message a day?
So I send you six text messages a day to try to keep you so that you are still -- you have not started smoking again? What is the amount? Frequency.
Do I go to the chiropractor once a week? Seven days a week? How frequently do I go?
And for how many weeks? And for how much time? There was one good massage study that they looked at 30-minute, 60 minute, or 90-minute massage.
Once, twice, or three times a week. Now they did take out something because they're like, well, you're not going to study three times a week, 90-minute massage. People will not go to that.
But there've been these very interesting dosing studies, not just of drugs, but a lot of other interventions. Same thing if you're talking about a lot of psychological interventions. How much practice?
What do people need to do outside of a classroom? Who is the leader? Who is the surgeon?
Who is that person? How much contact is there and how well trained are they? There're a lot of combinations.
You're only going to be able to test some of these possible doses, but it's important to look at it. As I mentioned at the very end, you've got to think about your practitioner impact. There could be a lot of false/negatives and false/positives that come up here because we have some people that are just -- they're enigmatic.
People like them and good things happen. But sometimes you say, listen, I'm doing a proof of principle study. If the best massage therapist, who's really well-trained, and trains others, if that person cannot give a massage that improves low back pain, probably nobody can do it.
If my best surgeon cannot fix this, maybe nobody can be trained to do that. So sometimes we actually go for really well-trained folks in a proof of concept model and then broaden that out. But again, you probably want to choose techniques that can be generalized if you're going to do that.
But other times, such as the Perlman studies that were looking at massage actually for osteoarthritis of the knee, he chose Swedish massage because he said that's what everybody is trained in in most of the countries he was looking at. He was like, that's the foundation that they have, we want to build on that. So the study analysis population.
You have this mechanistic proof of concept. That's your throw in the best at it. We sometimes call these also the protocol analyses that we do because we only use the patients that behave, the study subjects who do everything we tell them, we'll analyze them here.
That's along the idea of, like, in the perfect world what might we expect? But general use is like these intent-to-treat analyses. That's everybody.
You tell a patient to take a drug, they don't necessarily take it. You randomize a patient to a study arm; they don't necessarily comply with your intervention. So intent to treat versus kind of these different completers analyses, this gets down to what is your data analyses population.
So we could say ITT, or intent to treat, once randomized, always analyzed. And then observational trial, we're like, once you're in the trial, we follow you in the trial. You assume that all study participants are adhering to your study regiment and that they complete the study.
So they -- you assume they behaved perfectly, regardless of what they actually do. Most of your regulatory agencies are going to say, "We expect you to do an intent-to-treat analysis. " Most high-quality research regulated or not, we assume you should be doing intent-to-treat analysis.
But then people kind of want to skirt the edges. They do something called a modified or MITT analysis. Modified intent to treat.
They may only include patients who start the intervention they're assigned to. So they include the study subjects who start the intervention. Well, if I randomized you to go to psychotherapy versus not, you decide you don't like what your randomized to, and you don't start, you know, that's still telling me something.
So should I really throw those people out of my analyses? It depends on the question you're trying to answer. Sometimes people say if they don't make it to like the first or the second post-baseline assessment, then I don't count them.
I'm like, well, again, you can't really compare both groups of patients then. You know, your study subjects may no longer be comparable. You have undermined the randomization.
So that's the problem with modified intent to treat analyses. You've got to be very careful with those. But sometimes we do these completers or adheres analyses that, again, you're only dealing with your well-behaved and that's a problem.
So as John described last night, we have this kind of superiority in equivalence. So I wanted to put this in a picture for you. Equivalence or no difference, the confidence in a role that we'll talk about in a hypothesis testing lecture, everything's inside this little, tiny, round, kind of in the middle.
It's like where there is no difference. So this is a normal distribution curve. And this line in the middle is kind of the zero.
It's the middle of the bell curve or the Gaussian curve. So if you're in a little tight area here, there's no difference between your study arms. If you're in these orange areas in either end, you have superiority.
So when I test two arms, I can come up with a value along this curve. And if I'm far enough out, that's saying that basically these two groups are statistically different, And it's probably not just a random error that I'm saying that that noninferiority is when I say, well, they may be a little bit inferior or they could and it's probably not just a random error that I'm [unintelligible]. Non-inferiority is when I say, well, they may be a little bit inferior, or they could even be superior, so it kind of gives me this huge area to be in.
So what are the comparison groups I might use to try to get there? Well, I've got experimental interventions versus control. Sometimes I'm in my epidemiology land.
be superior. So kind of gives me this huge area to be So what are the comparison groups I might use to try to get there? Well, I've got experimental interventions versus control sometimes I'm in my epidemiology land.
I also have cases versus control. Just because it's a controlled group doesn't mean you actually have a randomized control arm. Sometimes I'm comparing the exposed to the unexposed.
So at the World Trade Center sites, they actually took people who were doing cleanup there who had been exposed to that work and compared them to a group of people not doing cleanup, who did not have that exposure. So that is a study that the Center for Disease Control and Prevention has been running. We may have various levels of exposure that we want to compare.
Men versus women. Common comparison you see. The old versus the young.
Maybe BMI that's over 25 to 25 and under. You have the usual or standard of care or practice. Standard of care, not always that standardized, by the way, though.
And sometimes we're doing this history. Sometimes I do pre-post. I take somebody's baseline measures, I intervene on them, and I look at them afterwards.
Or maybe it's even just natural history. I look at them when I diagnose them, and I see how they've changed over the next 12 months or two years. When you talk about placebos, standard of care, attention controls, you might have some type of experimental treatment that you might offer, say, supportive care or some other current treatment.
So supportive care is not no care. It's not a true placebo. But if you have a yoga intervention, what should your control group be?
Maybe it's exercise or stretching. Maybe it's cooking class because you kind of want people in a group but not really interacting with each other. Maybe it's a book club because you want them to actually go someplace and be someplace for 90 minutes.
Maybe you do nothing. Maybe you say, in fact, again, proof of concept trial. Does anything change if they go to yoga?
Sometimes we'll do something called a weightless control where we say, "We want you to do nothing new for the next 12 weeks. " And then you can do the yoga. The controls cost money.
You will see in the sample size lecture, you have much higher sample sizes when we have control arms. You want to control everything except the smallest element of the intervention you want to test. Be careful, however, it's not too small of a difference.
So I have this one meditation study, and they really wanted to test the mindfulness aspect of meditation, and control for everything else about the meditation. This is a very small difference and very hard to do. Like, why don't you just test like the meditation as a whole versus something.
But they're consequences when you have more control imposed. You can have larger sample sizes. You may miss a difference.
And if you have a less sensitive outcome measure, you may not pick that difference up. So plan accordingly. What are the differences?
Again, you've got to think about every single difference between your study arms is basically defining your intervention. If somebody is spending one hour a week with your study participants versus three hours a week, that is something that is different. If you tell people to spend 15 minutes at home working on that meditation versus 60 minutes a day at home working on it, again, this is defining your intervention.
And so when you say to me, if you just have two study arms against each other, well I need to figure out if it's the participant contact time or the time they spend at home, and say, well, one had one hour of contact and 15 minutes at home and the other one had three hours of contact and 60 minutes at home. I can't tease it apart, folks. You have to plan all of our interventions to figure out if you can tease that out.
So your control group might be placebo, most widely accepted treatments, standard treatments. Always make sure that these two bullets are well-defined. You're going to have to record it during your study.
Most accepted prevention intervention. Are you going to do an HIV prevention intervention and not talk about condoms? What is it that you're going to do?
Again, usual care, not all that usual across sites. You've got to record what it is. What are the accepted means of detection?
What is that diagnostic test? If I did that pap smear for cervical cancer, am I going to get the same results as if I swipe with vinegar and then do the test? Non-diseased population.
Sometimes we compare disease to a non-disease population, especially to try to figure out special differences. All control groups, especially when you're doing interventional studies, need to be ethical. If you're going to assign anybody to a group, anyone meeting the study criterion has to be able to be in any study group.
If that's not the case, you need to make sure that your randomization can figure that out, and they know not to randomize people to study arms that will easily be known to kill them. I set up an algorithm, folks. I only know as much medicine as you have imparted to me in setting that up.
Your inclusion/exclusion criteria should keep people from being in study arms that you know are wrong for them. If you have questions about that, Chuck Natanson actually has a whole lecture that he talks about mistakes that have been made in randomization. In standard of care.
Is it really standard? Good controls cannot always be masked. Somebody asks me this every year, it is now on the slide.
Try but you may not be able to do it. People do tend to be better after receiving any type of therapy placebo or not. Care matters.
Do not underestimate that when you are planning your trials. Comparing population incidence rates to the beginning of programs does not take into account a lot of factors. So, I had someone, they're like, oh, well just do pre-post.
Well, if you had taken into account the control group, in fact, while they're pre-post, the post looked worse than baseline. Everybody else looked a lot worse than that. So, if you hadn't had that control arm, you wouldn't have known that they actually basically salvaged the slides.
So, everybody else is kind of going like this. They're all going downhill. And they kind of -- they went down but not by as much.
It's important to understand this. No control group. You've got a lot of problems.
Researchers and participants tend to interpret findings in favor of new treatments. There's investigator and participant bias when you don't have randomization. You cannot distinguish effect and time.
If I wait 10-14 days, we will all get over our colds. So what's the right control group? There is no right control group.
You just have to choose one. Also again, remember control groups may happen in nonrandomized studies. We'll talk more about this next week.
But you have to consider all your effects. Positive, negative. Are your effects going to plateau?
When do I measure things? Are you looking at long-term differences? Is it going to be that, you know, you're going to see a change and then it's going to kind of trickle away?
Delayed response. Do I have to wait six months before I actually see a change? You got to consider all this stuff when you're planning a trial.
So time is my favorite confounder in uncontrolled studies. You've got differential dropout between the study arms. Different seasons.
So if you are trying to test and see different histamine levels, that is going to vary depending on the season that you are measuring people. Bone density changes throughout the year. You've got to make sure you measure them on the 12-month mark, not nine months.
Social support has an issue. Just empathy and talking to people, really matters. Exercise we know controls stress, cardiovascular risk factors, a lot of other issues.
You see immune responses with all of these. So what's your study about? What do you need to control and not control?
Masking can help, especially masking outcome assessors. When in doubt, when you can mask nobody else, mask the people collecting your data. Mask them to the hypotheses of the study.
But you need to specify in your protocols who is masked, why, how, and to what. If I break my ankle, and I'm in a medical products study, actually the PI of the study may not need to know what study arm I'm in. The safety officer might need to know.
The person doing my surgery might need to know to see if they have to adjust my anesthesia. But realistically, I don't need to know. A lot of people don't need to know.
Everything about blinding is this idea -- it's like playing like secret spy. It's need to know information. All studies should be reproducible, regardless of your study design, regardless of your study.
You need a well-defined study population. Well-defined inclusion/exclusion criteria. If I had seven people in this room, you should all decide the same thing if subject A should be in or out of the study.
It needs to be well understood. The study conduct -- well, someone's having fun out back. Study conduct needs to be well-described.
How are you going to do your study? And if somebody is injured and has to leave quickly, someone else's got to walk in, are they going to walk in and do it the same way? And that's everyone, from your nurse coordinators to your statisticians to your data managers.
You have to know that the labs are going to be processed the same way, that you're going to go and try to get people from the same place, and then every little step of that study is going to follow the same way. Can I reproduce the outcome measures? How are you collecting those?
How are you doing it? We'll talk more about that later and also that data and analyses. There're a lot of potential biases in clinical trials, and there are a lot of potential remedies.
So think about these if somebody says, "Oh, here's a problem. " Well, try to find your solution. And you also have to think we all have the bias of who's actually in the study, anyway.
You are trying to generalize to this big, lighter box over here. But realistically, you've got those that are interested in participating, meet the criteria, consent, and then get randomized. It's a much smaller group and it may not be as representative as you'd like it to be.
But that's part of why it's really hard work to be a trialist. All of our studies aren't gold, but we can sure try for it. So some conclusions in the next minute-and-a-half.
What is the question? You've got population or disease, P. So some people call it PICO.
Some call it PICO(T). The intervention or variable of interest, the comparison group, your outcome, and time. And you want to write this sentence.
This is an example, like, in this population, how does this intervention or variable of interest compare to this control influence the outcome during this time period. Phrase every single study question like this. This is your study summary.
When I ask you for a one sentence summary of your study, write it like this. And if you cannot fill in those letters, you have a problem. The other part of your study question is who cares about your study question, other than you?
Your question is always going to come first, but you've got to consider the questions you want to ask, those hypotheses that you're trying to test, because I've got to turn your question into something testable. What are the key factors you've got to control? Those ethical issues and constraints?
What can be said? Maybe you need multiple control groups in order to actually answer your questions of interest.