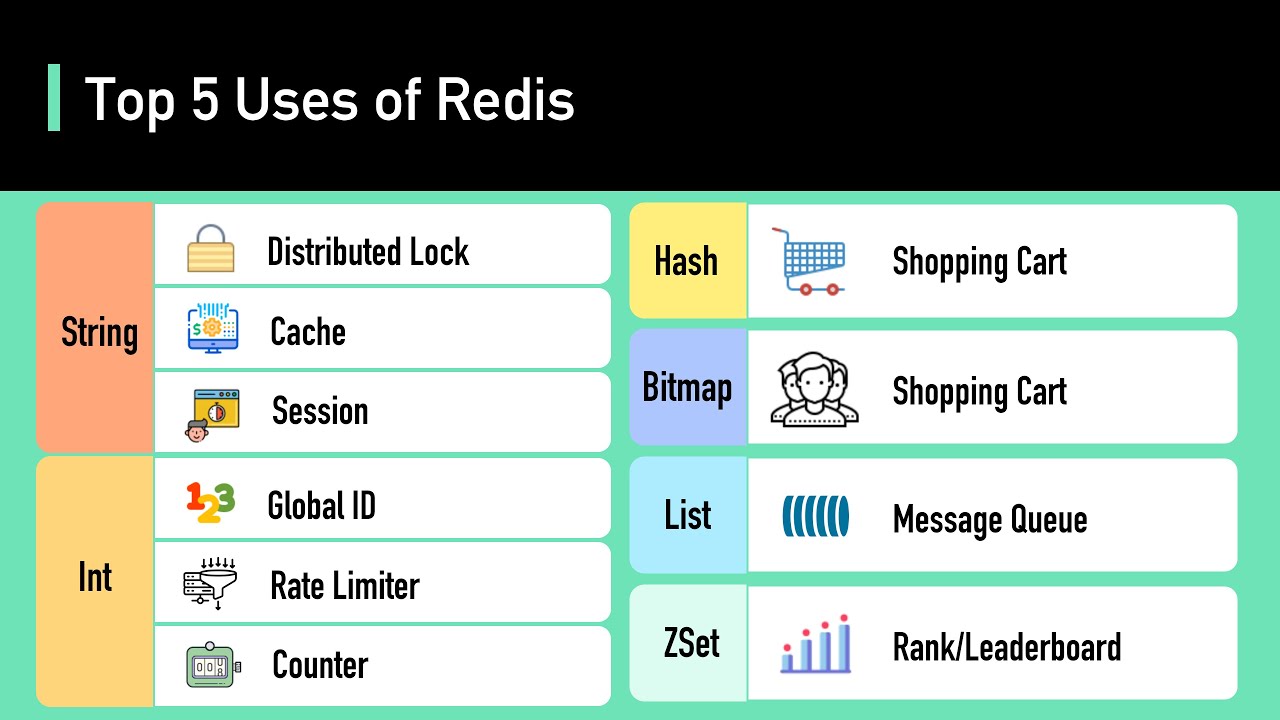
imagine a distributed system where your application runs on multiple machines or notes for example a banking system where multiple transactions might try to update the same account balance simultaneously when multiple transactions or notes try to modify the same data simultaneously the final outcome can be unpredictable and depend on the timing and order of operations this can result in data corruption inconsistencies or incorrect calculations this is known as race condition for example if one process has updated a value but another process is still working with the old value it can lead to errors and unexpected behavior
in some cases multiple processes can get stuck waiting for each other to release resources resulting in a deadlock where none of the processes can proceed so for shared resources such as a database a file or a specific piece of data you must ensure that only one node or process accesses and modifies this resource at a time that's the problem dissipated locking solves in ense a distributed log is a mechanism that allows only one node or process in a distributed system to acquire a lock on a shared resource this prevents raise condition and ensures data Integrity
when multiple nodes try to access and modify the same resource concurrently in my previous video I explained some of the real world use cases of op optimistic locking now compared to distributed locking think of optimistic locking as a polite conversation where people assume they won't be interrupted and only apologize if they accidentally talk over each other distributed locking on the other hand is like a formal meeting with a strict agenda and a designated speaker who controls the floor to prevent anyone from interrupting optimistic locking primarily operates at the application or database level whereas distributed locking
operates across multiple nodes or processes in a distributed system optimistic locking manages concurrent updates to the same data record or object within a single system or database it relies on version numbers or timestamps to detect conflicts and resolve them when multiple transactions try to modify the same data concurrently it also assumes that conflicts are rare and optimizes for performance by allowing concurrent access until a conflict is detected for example two users editing the same document in a collaborative editor which we have seen previously distributed locking coordinates access to Shared resources for example files database configuration
data across different machines or processes it employs various algorithms centralized token based Corum based Etc which is to ensure that only one node or process can hold a log on a resource at a time it also assumes that the conflicts are possible or likely due to distributed nature of the system and prioritizes preventing conflicts or performance optimization for example multiple servers accessing and updating the same inventory count in a distributed e-commerce system an ideal distributed log should guarantee that only one node can hold the lock at a time eliminating raise conditions and ensuring that operations
are performed automically you should guarantee the log should not become unavailable if a note fails the acquiring and releasing log should be effici and not introduce significant overhead the notes should have a fair chance of acquiring log without starvation now like I said before there are several algorithms and approaches for implementing distributed locks each with its own tradeoffs for example centralized locking has a single node or service that acts as a Central Lock manager all nodes here request and release logs through this node it is simple to implement and easier to understand but the central
node is a single point of failure and its performance can become a bottleneck under high load in token based locking a unique token is passed around among nodes only the node holding the token can access the shared resource and so it can be more fault tolerant than centralized locking however it is a little bit more complex to implement and potential for issues with token loss or expiration are always a problem let's talk about Corum based locking which is usually implemented using redis imagine a cluster of five redis instances notes a b b c d and
e and we want to implement a distributed log using red log which is a redis algorithm to ensure only one client can access a shared resource at a time even in the facee of node failures and here are the algorithm steps so let's say at the acquired time the client records the current time as D1 during lock acquisition phase the client attempts to acquire the lock on each radi instance using set an X command with a log key and a unique value say it's client ID each radi instance responds with okay if the lock is
acquired successfully or null if it is held by another client the client includes the log validity time or TTL with each Set n x command to ensure that logs don't become stale if the client crashes the client calculates the time elapsed since step one for example T2 minus T1 and then it does the Quorum check meaning if the client has acquired the log on a majority of instances at least three out of five in our example and the elapse time is less than the log validity time the lock is considered acquired otherwise the dock is
not Acquired and if the lock was acquired the client must release the lock on all R instances using de command for example let's say the client successfully acquires log on instances a b and c within the validated time the log is considered acquired because it has a majority if the client crashes before releasing the log the log on a b and c will eventually expire due to the TTL allowing another client to acquire the lock the Quorum requirement or the majority ensures fall tolerance even if one or two radius instances fail the lck can still
be acquired and released correctly as long as majority of instances are operational this prevents a single point of failure and increases the system resilience so basically it aims for high fall tolerance and availability however this approach is more complic and potential for issues with clock synchronization between notes and this has been a subject of debate in leader election algorithm notes elect a leader and the leader is responsible for granting locks it avoids single point of failure but again can be complex to implement and leader election can take time and resources you can check out my
video on leader election algorithm where I explain this algorithm in detail with practical examples both pros and cons now redes is a popular choice for implementing distributed logs due to its speed Simplicity and build-in commands like set an X which automatically sets the key only if it doesn't exist and expire which sets a timeout for the log to prevent it from being held indefinitely let's check out a simple Java example that demonstrate distributed locking using redis leveraging set an X expire and DL commands we use the JIS Library a popular Java client for redis so
here we Define a lck key to to represent the log and a log expiry seconds time out to prevent indefinite logs we establish a connection to the radi server using Jedis and we acquire the log using J is. set it attempts to set the lock key to the value locked only if it doesn't exist meaning NX the ex option sets the expiration time in seconds if the log is expired successfully it return returns okay otherwise it returns null and if the lock is acquired the code enters the perform critical section method which represents the protected
section of the code that only one thread or process should execute at a time in this example the critical section simulates work by sleeping for 5 seconds in the finally block we check if the lock is still held by this thread by comparing the value of lock key to locked and if so we delete the key to release the lock and then we also close The Red Connection this example demonstrates a basic distributed log with redus for more robust implementation however you make consider using redis modules or libraries like redison which provide additional features like
automatic lock renewal now zoer is also a distributed coordination service specifically designed for tasks like leader election configuration management and distributed locking it offers strong consistency guarantees and robust features for handling node failures making it a reliable choice for critical locking scenarios it can be more complex to set up and manage computer Rus hcd is a distributed key value store similar to zookeeper and often used for distributed locking and configuration management it also provides a simple API and is known for his reliability and fall tolerance it's again a popular choice for cloud native applications and
kubernetes environments now some relational databases such as post SQL MySQL and no SQL databases such as mongod Dy do offer built-in locking mechanisms that can be used for distributed logging this can be convenient option if you're already using these databases for other purposes however database based locking might not be as performant as specialized Solutions like radi or zookeeper especially under high load so the best tool for distributed locking depends on your specific requirements if low latency is critical redis might be a better choice and if strong consistency guarantees are essential zookeeper or etcd might be
more suitable and if you need a simple solution red is built-in commands might suffice and if you are already using a particular data base leveraging its built-in locking mechanisms might be more convenient ultimately there is no one size fits all answer it's crucial to evaluate the tradeoffs and choose the tool that best aligns with your application needs and your team expertise [Music]