[Música] Olá meu nome é nton Correia da Silva Eu Sou coordenador científico do projeto de precedentes qualificados uma parceria entre o CNJ e a Universidade de Brasília e eu estou aqui para falar um pouco sobre eh a arquitetura da solução que nós desenvolvemos do ponto de vista de Inteligência Artificial né temos aí outros materiais de outros professores apresentando outras outras visões do projeto meu objetivo aqui com vocês é detalhar um aí o Framework da solução que nós entregamos aí pro CNJ do ponto de vista das estruturas de modelos de Inteligência Artificial que estão embutidas embarcadas
nessa solução né mas primeiro falar um pouquinho do do objetivo desse projeto né o objetivo desse projeto que é resultado dessa parceria aí entre CNJ penude e Universidade de Brasília eh desenvolver uma solução de a né de Inteligência Artificial que seja capaz de realizar identificação de similaridade entre demandas e precedentes qualificados né então esse projeto ele focou estritamente em em precedentes qualificados do do STF repercussão geral e repetitivos do STJ Então eu vou passar aqui aqui com vocês durante esse tempo que vamos ter esse essa esse conteúdo aqui eu vou passar com vocês sobre a
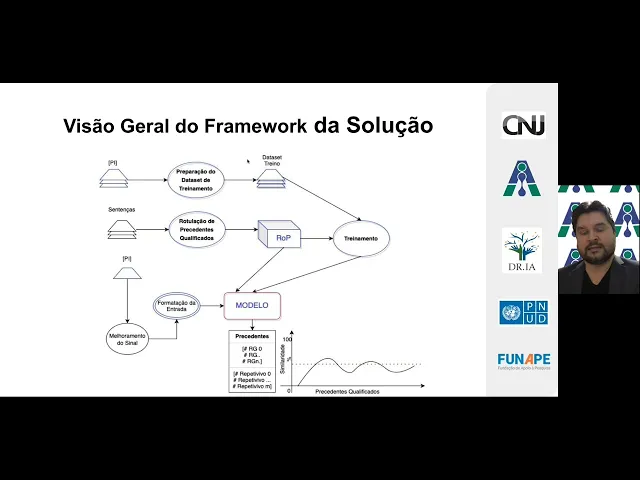
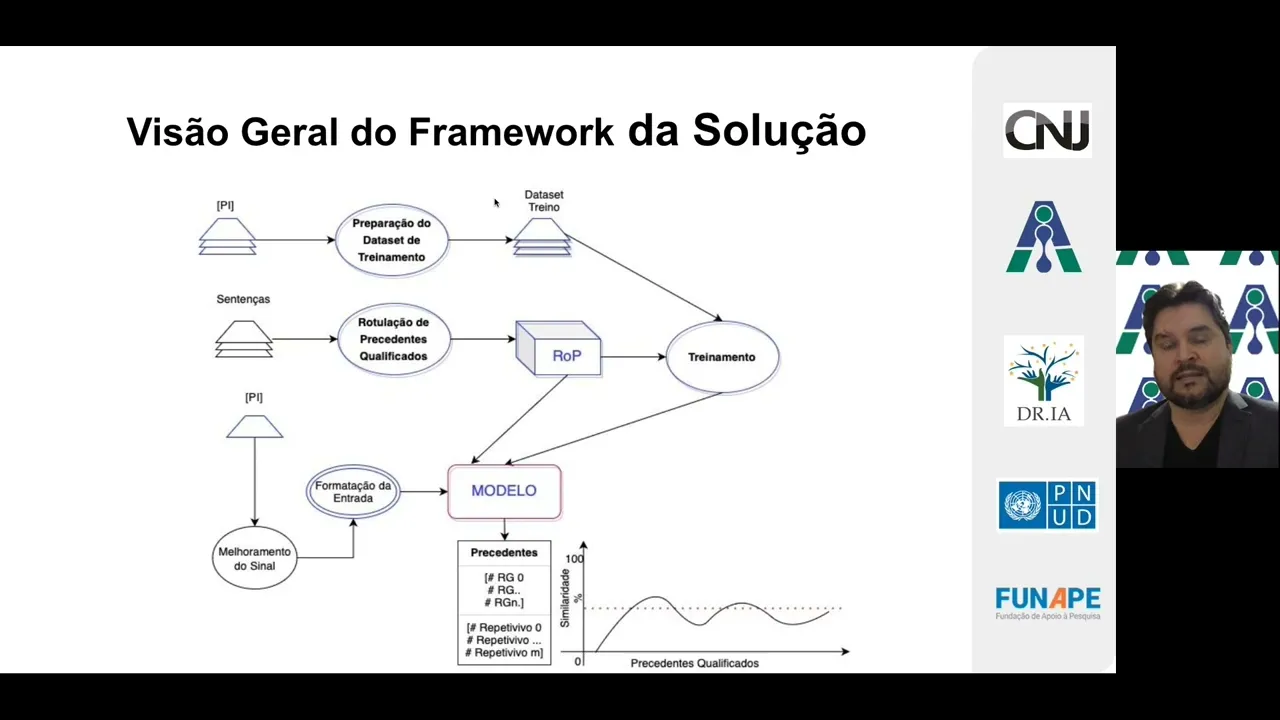
visão geral do da solução como um todo né então o que tá na tela aí que vocês podem ver é uma um desenho né da arquitetura da solução que nós aqui depois das etapas de pesquisa investigação de hipóteses nós chegamos né então é uma solução eh que ela contempla alguns módulos e eu vou est detalhando cada um desses módulos aqui com vocês hoje então o meu objetivo é explicar para vocês como que nós eh chegamos nessa solução e explicar cada estrutura dessa solução né como o objetivo demandado aqui pra gente era desenvolver uma ferramenta em
que ela pudesse dentro de um processo jurídico ler peças e inferir precedentes qualificados né nós optamos aqui depois de de algumas discussões tanto dentro da do nosso laboratório quanto também com o CNJ a entregar uma solução que ela fosse que ela tivesse uma abordagem que demandasse o mínimo de rotulação uma vez que tarefa de rotulação eh muitas vezes morosa e muitas vezes um pouco onerosa também né então nós nos baseamos numa solução fortemente não supervisionada que é uma abordagem da inteligência artificial em que eh os modelos não carecem de rotulação de curadoria de dados né
Eh pelo menos a gente tentou Minimizar essa etapa nós vamos ver que acabou que a gente precisou de rotular alguns dados de fazer algum um tipo de curadoria mas a solução como um todo ela ela se baseia numa estrutura não supervisionada né O que vocês estão vendo na tela aí é o Framework geral da solução uma vez ela implantada né então aqui a gente consegue ver a fase de preparação de datasets que eu vou detalhar aí com vocês eh rotulação de do de precedentes qualificados tendo como peça principal aqui de entrada as sentenças eh tem
essa parte importante aqui que é o rotulador de processos eh e também a a a parte de inferência né uma vez que a ferramenta já esteja eh eh treinada eu vou detalhar com vocês também como que é o funcionamento dessa ferramenta Né desde a entrada da petição inicial o pré-processamento desse texto dessa peça a entrada pro modelo e o de saída que o modelo vai fornecer pro usuário final [Música]