[MUSIC PLAYING] KATIE NGUYEN: What exactly is multimodal AI? In the fast-paced world of new generative AI models and topics, it can be difficult to decipher each of these capabilities and how to use them. In this video, I'll cover multimodality and how to leverage it for your use cases.
To fully grasp multimodal models, let's take a step back and start with generative AI. Gen AI identifies structures and patterns in the data in order to grasp meaning. With this knowledge, the models can generate new content, primarily from one input type.
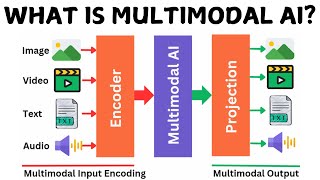
Multimodal models go a step further and have the capability to take in various inputs, such as text, images, audio, video, and code. This is an incredibly important advancement when it comes to reasoning tasks. Consider how humans learn.
From an early age, children learn about the world from hearing people talk, observing their surroundings, touching objects, and so forth. Humans need a comprehensive understanding of their environment to learn and make logical decisions. AI models are no exception.
Hence, multimodal AI refers to AI models that are trained on a wide variety of input types. And they excel at performing cross-modal reasoning, just like humans. With a basic understanding, let's dive into the application of multimodal AI with Gemini.
For this demo, I'll be running through some examples in Colab Enterprise using Gemini 1. 5 Pro and Gemini 1. 5 Flash.
Gemini 1. 5 Pro is Google's multimodal model with a long context window. Gemini 1.
5 Flash is also multimodal, while being optimized for high-frequency tasks where response time is crucial. To kick us off, let's look at a visual understanding prompt that contains an image, video, audio, and text. In this example, I'll provide a video clip showcasing the power of a Google Pixel accessibility feature.
I'll also supply an image taken from the video and a text prompt telling Gemini to look through each frame and answer some questions. Specifically, I'll ask Gemini to find the timestamp of the image within the video and summarize the moment. After running this cell, Gemini 1.
5 Pro is able to accurately provide a timestamp when the image is shown in the video. The model also mentions how the narrator is describing the story of a blind man. And the image is this man taking a selfie with his dog.
From this one prompt, you can see how powerful combining all of these modalities can be. It has been incredibly difficult for AI models to reason across various types of data at once. Now, Gemini can easily solve these "needle in the haystack" problems across multimodal inputs.
Let's consider some other use cases. In this next example, I'll show how multimodal AI can be used to reason across a code base. I'll use the Online Boutique repo, which is a microservices demo application.
To start off, I'll clone the repo and create an index where I'll extract the content of all code and text files. Now I'll use Gemini's long context window and multimodal capabilities to take in all of the repo's code, and text information. I'll also prompt Gemini 1.
5 Flash to create a developer getting started guide to help onboard new devs to the codebase. Once generated, you can see how Gemini does a great job reasoning across the code base and generating content that's useful to new users, saving time and effort for all parties involved. Finally, let's consider an e-commerce use case.
Say you have a furniture site, and you would like users to upload pictures to get specific recommendations. With Gemini's ability to reason across multiple images, this is a real possibility. Start with a photo of a customer's living room.
I'll also supply four possible pieces of art that the customer may be interested in. Now I'll use Gemini to help the customer choose the best option. To get specific product recommendations, I'll ask Gemini 1.
5 Pro to explain whether each piece of art would be appropriate for the style of the room. I'll also ask Gemini to rank each of the art pieces. I'll make sure to label each image within the prompt so Gemini has a reference when providing the final description.
When I run this cell, you can see that Gemini provides thoughtful and well-reasoned feedback, taking the customer's room into consideration. Being able to reason across modalities, understand the context of the question, and generate an accurate output is a game changer. This application of multimodal AI opens up countless possibilities in the realms of e-commerce, security, marketing, media and entertainment, and more.
This has been a brief overview of multimodality and how to utilize Gemini for some multimodal use cases. If you want to try out more code samples, check out the rest of this notebook and our generative AI GitHub repo. See the links below for more information, and let us know how you'll use Gemini's multimodal capabilities in the comments.
Thanks for watching.