Hello there today we're looking at hallucination free assessing the reliability of leading AI legal research tools this is by a set of researchers out of Stanford and Yale as you can see here now I know on this channel we usually look at more kind of core machine learning stuff and so on but this particular thing it happens to be a thing that I know something about because maybe many of you don't know That but in my day life I am CTO of a company called Deep judge we make legal Tech products specifically we make search
engines for internal document collections of like large law firms and adjacent uh fields and so on so while what we do is not super directly exactly what this paper tackles the sort of broader industry of legal Tech is very familiar to me and so this caught my my interest and maybe today I can bring that interest to some of you uh and what I do find interesting is that the techniques that are developed you know by researchers and us doing all kinds of stuff these techniques are right now being exported into the broader world into
the mainstream and they are being applied and real companies are trying to build real products for real people who are not machine Learners out there and that's so research like this like looking at how this impacts the real world will actually help you in order to Just sort of a develop better things but B also have a mind for you know how later what people actually would like to do with this kind of Technologies so that being said what is this about this is about so-called legal research tools a legal research tool is a tool
that you would use to answer legal questions based on publicly available data so if I say well can I I don't know turn right on a red light to you Europeans you don't know this but in the US even if a Red light is red but you need to make a right turn sometimes in some states you're actually allowed to do that so if be a legal question hey in Delaware am I like am I allowed to turn right on a red light um the legal research tool would need to go to publicly available documents
to answer that question so um usually if we disregard AI usually these tools allow you to do that search yourself they have big databases of laws of case law right what have judges said And so on um what has I don't know country treaties what do they say what is you commentaries of professors and so on curated content like these companies sell these big corpora of very good content including public sources including proprietary commentaries and so on and you're then able to go and drill down and find your answer now all of these companies are
starting to add AI into the mix and by AI they mostly mean generative AI like Chat gbt like AI in order to assist you so you can just enter your question hey in Delaware am I allowed to take and the thing is supposed to go by itself and collect together the facts and and and collect together the necessary relevant previous cases and so on and then reason through that and give you finally an answer with references this paper here tests the accuracy of those systems speciic specifically with respect to what are called hallucinations so the
Tendency of large language models to make up stuff and they're going to reach the conclusion that even though these systems sort of advertise themselves as being hallucination free uh they are not they still make quite some mistakes and they do say that may be problematic for the legal field and so now I have opinions about this paper um notably a I think everyone involved here is kind of shady like their researchers have done and are doing kind of shady stuff The companies are definitely doing Shady stuff especially in terms of how they advertise these things
the legal field as a whole is Shady in terms of what they're afraid of and what they expect out of these systems and like just everyone is kind of shady for just talking about the wrong thing like the fact that people the fact that people expect you can apply llm based systems in order to endtoend solve tasks like this for you is just the fundamentally Wrong approach to use these Technologies like it's just if you ask any competent machine learning person you just get like a just don't don't do that like this is not a
place where you want to apply these things in the way that people expect in any case we'll go through the paper um the paper and as an abstract they do give an overview over the current landscape of sort of legal Tech especially with respect to generative AI in these legal research Tools um then they make a data set the data set has some of these legal questions one that I just presented before but obviously much more complex much more in depth then they evaluate that data set on these systems and you know lastly they they
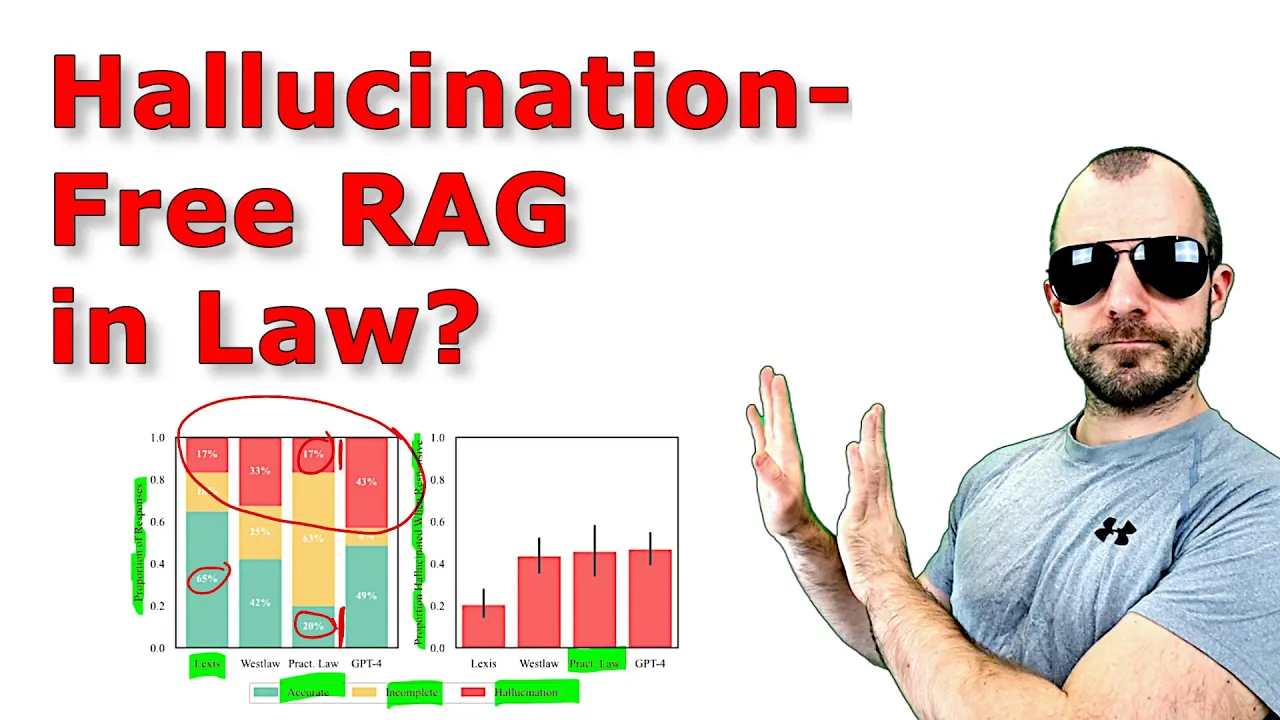
present the results and the results are going to be as you can see right here that these tools still between you know a fair bit of of time um on the positive side the hallucination rate is much lower than or Much is lower than when you just plain use a straight up llm like GPT for and so that's good and that is mostly due to their use of retrieval augmented generation uh so the the technique of retrieval augmented generation also called rag now I cringe every time someone says Rag and I've also started saying it
like it's retrieval augmented generation whenever stuff goes mainstream it needs to be like shortened and and made catchy The biggest offender in this is the word gen AI like but in any case um so you'll probably also hear me using these terms but um feel free to comment one cringe Emoji Emoji for every time you hear me saying this so retrieval augmented generation where the an llm works with a search engine to actively grab relevant resources pulls them in puts them into the prompt and then answers your Question for you s drives down hallucinations but
doesn't fully alleviate them and we'll go into some of the reasons and I do think the reasons for this are very informative to people who just work with these things in on you know kind of like test dat you oh here's my 200 personal documents and I use llama index on them and so on like the real world is much more complicated than that and a lot of you know that's the culprit for a lot of these cases Right here all right now um to what I said at the beginning uh our company how is
that related to this one right here so we make search engines but we make search engines for internal document collections of companies not public documents so whereas here you mostly care about you know legal precedents and laws and rules and uh contracts between countries in the internal document Universe you mostly care about the question have we done something before Or like I have a new case do we have we done something like this before can I go look up can I find a good example has my colleague already given advice on this particular topic and
so on so kind of different uh worlds different use cases and different different requirements to these systems and the thing that people want out of these public research tools I do strongly believe that in the current state uh applying llm like they Do is just just the fundamentally wrong thing to do and expecting llm systems to perform these tasks these public legal research tasks is just a fundamentally wrong expectation like it's just that's just not what they're for and you're trying to apply the things to something they're not made for and then you get garbage
then that I'm sorry that's the situation all right yeah as I said these systems promise to perform complex legal Tasks however their tendency to generate incorrect or misleading information a phenomen phenomenon generally known as hallucination that's what's holding them back hallucination what is a hallucination this paper is going to Define it as incorrect or misleading like making up stuff um to the machine learning world we would have bit more of a nuanced idea of a hallucination so essentially essentially large language models are Statistical statistical description of language right it's a model um meaning a statistical
model of a language as seen through a training Corpus a training Data Corpus now llms are nowadays they are relatively surface level statistical descriptions of language so and then I don't mean to I don't mean to sound like a Gary Marcus or so like oh this why it's just a bit of and so on no it's very powerful but still it is a statistical description on on kind of a Linguistic grammatical level uh they're very good at predicting the next token in a statistical sense so they just see the world in terms of likelihood of
the linguistic patterns of language they don't see the world in terms of reasoning or something like this and and certainly they do not see they do not have some sort of internal World model they do not um have a a grounding in reality all they see is text and the statistics above it so what is a Hallucination a huc hallucination happens because the real world is does not follow a smooth likelihood distribution that the llms learn from the training data so the llms from the training data they learn a relatively smooth probability distribution across language
so stuff is more likely and less likely right and then what they produce will be exactly proportional to How likely they think a given piece of text is just from a linguistic Perspective however the real world doesn't follow that in the real world you have things that are true that are quite unlikely from a linguistic perspective and you have things that are untrue that are um quite likely so the real world is much more like much more like so I I guess or or skewed or something like like the real world is not a smooth
probability distribution where the like what's statistically likely is also Exactly proportional to that true and therefore these gaps here the gaps between what's likely and what's real like here on the negative side and here in the positive side um these gaps are where hallucinations happen namely you can see at this particular point I am at a I don't know imagine this is a a particular sentence that just sounds very plausible but is just not true right that's where language models Hallucinate they will produce the sentence even though in the real world even though it's quite
likely but it it's just not the case right we all you all know such situations where something is quite likely it's quite plausible and so on but just isn't on the other hand right over here we see something that's true but that is just very unlikely and coincidentally so the the world the world has unlikely stuff that is nevertheless true in in Fact it would be very unlikely if there were no unlikely true things right that as a meta statistic would quite would be a quite unlikely World however language models the way they learn language
isn't over smoothed over narrow Pro um representation of language we might get to a place in the future where they learn from the training Corpus such a deep representation that they accurately can assess the the likelihood of stuff um then there's still the debate of how Much of the information that you need is actually contained in all of the world's text and is there information that is never written down in text that you would need to know in in order to um update in order to have the accurate likelihood I think that's of now more
of a philosophical question but I hope you can see here some stuff is likely but not true some stuff is true but not likely and that's where hallucinations happen in this paper right here they Take a more kind of basic approach of just saying well a Hallucination is kind of stuff that's wrong and they're going to Define it later these are going to be the results after after they uh round run their data set through so they test different products right here they test first of all gp4 gp4 without any grounding whatsoever they just ask
gp4 these questions and they just see what happens and you as you can see gp4 does get it Wrong quite a bit of of times and um uh yeah so the the goal is obviously hey this is what people know as hallucination uh can we do better than that right by doing retrieval augmented generation we'll get to what that is actually we'll get to what that is right now so let's go to that what is retrieval augmented generation it's a way to enhance a language large language model Generation by augmenting that generation with retrieved data
retrieval Augmented generation so uh you have the the user inputs a query which in this case is a a question kind of a natural language question hey in the state of Delaware can I do this now what usually would happen if you just were to go to I don't know chat GPT or something um or or a plain large language model you would just give that to the language model and that language model will give you a will give you an answer just and the way it does that Again from its training data is learned
a statistical distribution over language and therefore it's going to give you the output that's that's likely to follow given your input so likely to follow according to the training data now for a lot of questions the likely output is actually also true if you ask it hey uh can you make me a day trip in Rome like suggests some things to me there are a million blogs on the internet that have oh my itinerary for my Rome day trip and So on it's going to do just fine right however um it's going to do not
so fine on some of these legal questions first of all because again they're this very detailed knowledge and so on second of all and that's what we'll get to later uh legal legal question answering in in the sense of oh I need to retrieve stuff from these public sources requires reasoning Requires um explicit sort of construction of relevant context and that's also not easy requires knowing which stuff even to apply which stuff is out of date which stuff has been overruled and so on so a lot of stuff that's not actually just o what's likely
and what isn't given the training data because well the training data is just the Big Blob of text completely unordered complet completely um you know no particular date ordering and cut off After some point so with retrieval augmentation we can overcome some of that so what you would do is you would use a search engine and that's what you see down here you would use a search engine in order to retrieve data from what they call here a knowledge base so the knowledge base that would be these these vendors of these products that they test
in this paper they would have knowledge bases that they maintain and they curate so They take all the case law that is produced day by day added to the knowledge based they would take I don't know articles that their experts right added to the knowledge base and so on just accumulate that so use a search engine across that and you retrieve relevant documents to your uh to the query that the user has then you give the documents to the llm along with the question so the way that works is usually you would this query it
would Come somewhere here and you just ask the you maybe have some pre- prompt you know you are a very competent Legal Assistant yada yada yada the user asks the following question and then here you would put that question from the user you know please answer the user and so so this would be your prompt and then the the llm would output some sort of answer what you're going to do with retrieval augmented generation is you're going to Take the documents that you get from here and you're going to stick them in the prompt as
well so rather than saying rather than just plainly saying hey the user asked the question you're going to maybe also have a pre- prompt you know you are a blah blah blah but then you're going to say here are some sorry for the handwriting some relevant search results and then you're going to list these search results you know Here you're going to list the results you get from the search engine and then down here in the prompt you say something like okay the user ask this question please answer based on the above references references yeah
and now this all of this here would be what you typically say is the prompt so you would stick all of that Into the llm and then get out so the llm no longer just gets oh hey the user asked this fallowing question and it has to answer from from memory basically of the training data but but now you also provided you say hey look here the user asked question and here are some references please base your answer on those references if possible or something like this right so you immediately see how that makes stuff
better if these references are actually Useful to answering the question then an llm you know being able to access all this information explicitly in the prompt is can be much more capable than one without so even if something has never been mentioned in the training data um it can you know it can it can know quote unquote about it because you're just giving the information to the llm explicitly even if it was in the training data llms don't remember the training data explicitly they just sort Of have a statistical abstraction of it in their head
so giving them the information explicitly during run time helps in fact if you ever want to try retrieval augmented generation you can just do that yourself by mimicking this so just have your question grab a few relevant references that would be necessary to answer the question and just copy paste all of them into the prompt of an llm and then put your question below and tell it to you know Use the references above it's literally there's nothing else this is literally it when you talk about retrieval augmented generation now there are various prompting tricks and
so on and you can have a second prompt that checks and be like oo criticize yourself and blah BL blah things step by step and so on like all of these things the usual prompting tricks apply but in essence this is the core you just copy paste some references into the context of the Llm and then you ask it to use those references when it gives the answer so that just demystifying rag here this is what happens and you can immediately see how it helps but you can also immediately see how it cannot help namely
hi this is Yanik from the future a short Interruption of something that I think I failed to properly explain right here so the llm on the right hand side is really completely disconnected from the whole system on the left so the all The llm sees is this prompt it doesn't know that there more data it doesn't know about your case other than what you describe in the prompt right the The Prompt is the whole world to the llm and that explains a lot of you know what's going wrong right here it has no clue that
you have chosen these search results based on specific criteria and so on and you can try to bring that into the prompt but it will not help by much so if you if you just think what the Thing of on the right hand side here this this prompt um the few search results completely out of context and the user query and your instructions that's all the llm ever sees and is ever aware of existing the whole system on the left and all the circumstances and and all the knowledge about that it's it doesn't know any
of that right so once you start thinking like this um you can see where it goes wrong very often often all right back to Yanik in the past Who's making a few more in-depth explanations around this topic if these things here aren't relevant you're actually making stuff worse by telling the llm please please base your answer on the on their search engine results from above right please base your answer based on on them um it's going to be like okay I'll I'll do that but if they're not relevant yeah so you may change the prompt
to oh please only do so if they are relevant to you that's Going to help sometimes however if you know from I don't know if you have search engines they sometimes Miss so they sometimes give you something that looks relevant just because the text passage kind of deals with the same topic but isn't like completely different context or it's been overruled or it's you know it's confused by by something you're actually making stuff worse if you do that so one of the one of the lessons here is that retrieval Augmented generation can certainly help and
does help in a lot of cases but it brings its own set of problems with it especially when there is reasoning involved right um retrieval augmented generation is really good really good if you just wonder okay I know there's something somewhere I need to find it so if you treat it essentially like a good search engine that also reads a lot of stuff and points you to the things that are Relevant it's a lot better at that than end to endend solve a task for you where reasoning is involved at the retrieval step like what
do you even search for that's already a challenge and then how do you make sense out of the answers that's the second Challenge and if those things involve complex multi-step reason in and abstraction and certainly these legal questions do then that's really not the right place for llms to be involved also yeah you can See this lexical and semantics so there is this modern This Modern idea that you can either do keyword search or a vector search and that's it right like the last 50 years of information retrieval it just don't exist anymore and yeah
so so people go with oh yeah keyword search that's that's the old way and now the vector search and everyone's just so hyped by being able to chunk documents and then just embed them and throw them into a vector database and I Think that's just going to solve all of their problems because it's neural networks and it's cool and it's modern um there is there is there is way way not enough focus on what it means to build good search uh and you know how how that's being done uh just because people in front of
their gloomy eyes have this oh neural networks apis and Vector databases nevertheless yeah so you see the retrieval of relevant documents is Quite important I would say apart from apart from the fundamental mistake of using generative AI for reasoning BAS task like just that that's just don't do it apart from that what influences the quality of these systems the most is how relevant the reference data you can ship into the prompt over here is and therefore the retrieval aspect is is crucial again that again has multiple things like what do you even put into the
retrieval and I do think uh in this Case right here like the legal AI research uh tools that's a giant component second component what's even relevant and the relevance in again in these public research tools the relevance is often determined by stuff that's not contained in the document the relevance is often determined by stuff that the humans know because they've gone through extensive education as lawyers and it's not something that you want to just be like uh whatever Whatever the search engine outputs I'll just take all of that and base my answer upon that that's
just crazy um yeah so this is retrieval augmented generation with its good things and its flaws and so on um and yeah we're going to look at what ultimately comes out so they test four products back to this gp4 without retrieval augmented generation just plain up language model actually doesn't do too well when you consider that it just needs to remember Everything that it says is from kind of like memory of the training data then uh Lexus um Lexus Nexus is a company they have Lexus AI Plus or so their product is called it's for
doing this type of legal research it does the best out of the ones tested right here um but as you can see its hallucination rate is still considerable so one in five times it still tells you something that that's not true or uh grounded in something That that's referencing something that's not to be referenced for that case um Westlaw is by a company called Thompson Reuters it is slightly worse or well I guess double worse than the Lex's AI plus uh however keep in mind that the benchmarks that these academics use is also targeted to
elicit some of these hallucinations so in pra this is in practice it might look totally different an interesting story is around this practical law entry that they have right Here so practical law is another product by Thomson Reuters so the same as West law now you may ask yourself it's a bit odd here it seems to do okay well on the hallucination front but then the incompleteness of it is quite high right so what's what's kind of going on here what's going on is that practical law is a different product um it's a much more
restricted set of just Cur very curated content uh so what people would go there for is for example I need a really good Um template for a for a contract right and then practical love would have their lawyers write a bunch of these you know these are the gold standard templates for the industry or something like this they would also write very uh like legal opinions and so on I believe so very expert made content um so you can see the difference these two products right here they'll have much more extensive they'll have the case
law they'll have stuff like that practical law doesn't And so the thing is this is the wrong product to evaluate right and the clue is the first iteration of this paper didn't have West law it just had practical law so they picked the wrong thing to evaluate and so this is I don't know academics this is where they get a bit shady I do find um so they pick the wrong thing to evaluate from Thompson Reuters and I've seen articles and I'm not sure what the exact order of events here right is but they keep
complaining In this paper that oh these these tools are not openly accessible which makes them really hard to evaluate specifically with respect to picking the wrong product to evaluate they said well we asked Thompson Reuters three times and they wouldn't grant us access to evaluate um it now what I didn't what I wasn't able to fully deduce from these answers was did did they ask Thompson Reuters for Westlaw and they didn't get access to that and that that's why they Chose to use practical law or did that somehow happen differently but the way I can
deduce it they said well we asked for access to Westlaw they didn't give it to us so we evaluated practical law that's if that's the case or if any of the other variants is the case right if if you already had practical law and also wanted West law and didn't get access to or if you got access to neither from Thompson Reuters but then somehow otherwise got access to Practical law all of these are uh a bit a bit shady I find like just evaluate the wrong thing just because you don't have access to the
correct thing isn't you know that that's not that's not good science and then they the interview said something like oh you know once we did publish our findings then Thompson Reuters gave us access to westla well you evaluated the wrong thing and you essentially blackmailed them into giving you access which you Don't you have no right right uh so in whatever order that happened um I do find it highly Shady of of these academics to do something like this and yeah also what is funny though in the tomson reuter's case you can see in their
metric now obviously their metrics are made in a particular but in their metric then the correct product actually scored a lot worse than the uh the incorrect product right here Uh it also scored a lot worse than this Lexus product here so this difference here I would say is notable but this difference over here just shows you that there is something wrong with this Benchmark right if the fundamentally wrong product for a thing gets about equal good in terms of um in terms of hallucination and let's be clear this is the thing that they're going
to report in the Press the fact that this here is different and The fact that that indicates that you probably shouldn't use this metric you know or you probably should be very careful how to interpret this metric that completely goes lost and I do believe just also from the rest of the paper that's not that unwanted by the academics right here because every academic they really profit if their paper goes you know gets wide um widespread attention so on so more they can make it seem like oh these things Still hallucinate um yeah but I
do I do feel the inclusion of this and the fact that uh this is kind of as good if you will as this here which is explicitly made for that should give you a hint that maybe the the metric here is I mean just be careful how you interpret any of that stuff in and what it exactly means rather than jumping to the be like oh it hallucinates the whole legal field is kind of annoying me right now because they're they're just running around like Chickens and just saying oh it hallucinates and uh like I
don't know the fact that you think that is a problem just means there's a fundamental misunderstanding of what these tools should be used for right yes they hallucinate and so on yes that's a problem yes you can bring that down but so bit Shady um yeah I mean these people are from Stanford and Stanford is kind of known to uh let's say put a high Emphasis on how how they Market their research rather than just scientific um Pursuits of knowledge good so looking into these products a little bit more what I do find interesting is
um yeah they they say here yada yada that these legal technology providers have claimed to mitigate if not entirely solve hallucination risk they say their use of sophisticated techniques such as retrieval augmented generation largely Prevents hallucination in legal research tasks now I would concur with that so it certainly and even according to this paper right here the use of retrieval augmented generation does seriously reduce this problem of hallucinations right where the models just make up stuff um and not in only in legal research tasks in pretty much any task where you where the outcome should
be based on knowledge that's somewhere in a repository however look at what these Look at what these providers advertise and here is where I'm where I'm I'm uh on the side of the academics like the fact that these these companies advertise their products like this gives these academics every right to tear them to shreds uh so like the Nuance between yes retrieval augmented generation does reduce hallucinations seriously right uh you can give references which helps people to even more make sure that what the llm says is correct and so on the Difference between that and
this unlike other vendors however Lexus AI plus delivers 100% hallucination free linked legal citations Connected To Source documents grounding those responses in authoritative resources that can be relied upon with confidence what what is this 100% hallucination free uh relied on with confidence and so on now this is ridiculous but the the astute the focused among you might have realized The following they're not saying that the that the outputs are 100% hallucination free they're saying the linked legal citations are 100% hallucination free so as long as they you know only link stuff that they actually retrieve
from their database then their claim is technically correct right now well first of all interestingly um the llm can still hallucinate uh citations but I guess in the UI they can only they they can Restrict the UI to only show actual stuff from their database so Tech this this is this is a state M that is technically correct however you know it it's like you know that the people who made it were extremely aware of what they were doing and so I have no I like every piece of you know study of this paper or
other papers that come out and trash these products for still you know making a lot of mistakes is deserved Uh because they knew what they were doing right a person who reads this doesn't doesn't read oh oh only the citations are hallucination free this statement says nothing about the accuracy of the response no no no no no no no they know that what people read when they read this what they understand is that the outputs are hallucination free the sentence doesn't even make sense unlike other vendors like say a delivers 100 % hallucination free linked
Legal citations Connected To Source documents grounding those responses grounding those responses in authoritative resources that can be relied upon with confidence again what can be relied upon not the responses the authoritative resources can be relied upon with confidence so this statement says not this statement essentially just says we have a database of real stuff that's what it says it says nothing about the llm those Responses just maybe it refers to a sentence prior to this that we don't see right here and that's obviously a case here the paper Cherry picks the most egregious um marketing
things of these companies but still the sentence in itself doesn't make sense grounding those responses in authoritative resources well you just told us something about the linked legal citations not about the responses so yeah unless there is a Prior sentence um that says something about the responses of the system this is crafted to transmit something that not the case while being made such that at any point you can say oh no only the citations we we meant we clearly meant only the citations are hallucination free so yeah I I have no no uh sympathy for
uh any of these companies then whining case text unlike the even the most advanced llms counil does not make Up facts or hallucinate because we've implemented controls reliable data sources as I mean yes they have implemented controls however does not make makeup facts are hallucinate like ask one of your engineers and I'm I'm pretty sure they have protested when this when these kind of statements uh are being made these companies need to make money right and sure like I get it some you selling you put your best foot forward and so on You advertise something
uh that's maybe even a bit aspirational right all of that is fine like every single company in the world does this and we all understand that and even better it's kind of a a you're striving and and you know like I think we can sympathize with that but this is is just a plain wrong statement right even with the best references even if you have all the correct references in your context which is extremely unlikely uh so but even if You have the correct ones you know the the correct even this and then this has
been overruled by that and so on and even if your llm is actually capable of doing reasoning across those which isn't the case even then it's going to hallucinate some of the time so no this is an incorrect statement and I'm sure I'm sure again these are kind of cherry-picked things yeah Thompson Reuters we avoid hallucinations by relying on The Trusted content yada Building in checks and balances to ensure that our answers are grounded in good law um yeah based on the and so on so this is probably the most kind of timid the most
accurate it just says we avoid hallucinations uh which could still mean they they happen but just kind of they are reduced so this this gets a slight pass I would say in in in the world of marketing that's fine so but this here This I don't know this is Shady all right um there's a lot of Pros in here about giving you kind of the background of the legal industry and so on um however I want to dive into what they you know how they how they see retrieval augmented generation in terms of the legal
industry how they make their data set and evaluate it and a bit more on the results don't want to make this video too long um Yeah so retrieval augmented generation the idea behind it I guess we've had this all but it's the idea is essentially you're letting the model go open book instead of closed book however uh it's not as easy and that's mostly because open book is good but which book do you look at and if the fact that which book you want to even look at and what do you want to look up
already requires a fouryear law degree or serious experience in Industry um Then it's probably currently not the right time to just do llm based retrieval augmented generation and let the thing do it for you limitations of retrieval augmented generation rag I'm just going to say rag um legal queries do do often do not admit a single clearcut answer case law is created over over time by judges writing opinions so they write opinions they overrule each other they make them Dependent on context and so on uh legal opinions are not Atomic facts and deciding what to
retrieve can be challenging in a legal setting additionally document relevance in the legal context is not based on text alone retrieval of documents that only seem text textually relevant and are ultimately irrelevant or distracting negatively affects the performance on general question answering tasks and that is known not just in the legal Field but generally in the retrieval augmented generation field if you retrieve documents if you retrieve grounding information and that's wrong um it could even deteriorate the final output uh because now you're telling essentially you have to view it from the training data of the
llm so the llm is is kind of trained in the setting where it gets a whole lot of data collected from a whole bunch of places but most of the time when it sees the situation in Training that someone you know posts a bunch of reference information and then draws some conclusion from that most of the time that reference information is actually the relevant reference information to what the person's saying so the LM in its training data is very trimmed on these situations wherever there's reference data available to base an answer on on these situations
having the correct reference data and therefore it's probably overly assumes that Whenever you do that in the prompt that it's in one of those situations where it can quite rely on the reference data and should adhere to it quite a bit um so when you now retrieve the wrong thing or when you don't tell the llm something's been overruled and so on uh you are causing a problem because it trusts you you right now the the problem with these systems is all of that is hidden from the human right if you include the human In
the loop you can get a lot better result like you include the human while deciding what to search for you include the human in selecting the relevant references ordering them and so on deciding whether they make sense in your contact or not context or not and then you include the human while reasoning over the final references in arriving at a final conclusion that would make for a fantastic system but that would mean it's not super magic llm you just have One text box and it does everything for you right no no no that would actually
it would actually it would not be that it would actually be a productive system except it's not AI it's not magic it's just oh you just pair like you pair good UI with a good search engine with you know good human in the loop interaction with an LA M but that's that that's that's not AI That's not uh it's not a chat bot so uh that doesn't sell as well so that's the kind of the biggest Problem I have with this kind of thing people are just too their eyes are too sparkly uh from the
whole llm promises uh so that they forget what they're good at what they're not good at and that um you know soft principles of good software haven't changed all right in different jurisdictions in even different time periods the applicable rule relevant Juris Prudence May differ even similar sounding text in the correct time and Place may not apply they have an example right here um what are some notable opinions written by this judge now apparently this judge here even has never existed so this is kind of a false premise question and still via retrieval that there's
some references come up where the embedding similarity is quite close or something and then uh the a the llm response saying oh you know there are these these things um and then they they take it apart you can see how that Goes so the retriev citation is a real case in case in case in hallucination free in the narrow sense however it was not written by this judge uh the second sentence contradicts the premise and the decision is not notable as it was an unpublished opinion right so and this is a very simple case um
the whether something is relevant and whether the legal reasoning is correct and so on these get much more complicated so to think that an llm would ever be at least At this point in time would be able to do this for you is uh let's say unlikely it's an bit of bit bit of an outsized expectation right there um yeah so this sentence astonished me these challenges and the challenges of the problems of retrieval augmented generation are familiar to lawyers using natural language searches as opposed to more deterministic Boolean searches on legal research platforms and
I have a particular problem with this sentence because it kind of shows how different things are just all lumped together currently nobody can get their terminology straight so a natural language search just means that you search with natural language Google nowadays and I don't mean like the very recent Google AI answers and so on just plain Google search is a natural language search you just more or less type in what you're looking for and it Will give you relevant stuff and you don't exactly have to hit the keywords or anything like this right it's just
understands you is good at giving you what you want that's a natural language search natural language search doesn't mean retrieval augmented generation it doesn't mean that the output has be to be produced by an llm or something like it it just means that um you don't have to do these kind of Boolean searches anymore so a natural language search can Absolutely be deterministic in fact Google apart from some personalization and AD features is quite deterministic even though it's a natural language search I think what they mean is sort of an uh llm output output search
right rather than a search that just gives you back search results so not even the academics who are supposed to be very systematic about this stuff can get their terminy ology Straight right here nowadays as soon as you talk about Ai and search everyone is just like oh um it's like chat GPT with browsing right like no no you can make good search engines and you obviously see where I'm coming from you can make great search engines that give you search relevant search results that just understand what you want so that it's not all or
nothing that you there are very good very good ways of making in between Stuff and the in between stuff is where you get productive right like the biggest drawback of these systems is they're trying to do everything End by end whereas if you were to mix technology and humans like technology is very good at like reading a lot of stuff very quickly right a search engine reads a lot of stuff enormously quickly and gives you back relevant stuff and llm can also not as much stuff llm can also read a lot of stuff very quickly
point You to the relevant things but then include the human the human who's very good at reasoning who's very good at deciding which ones are actually relevant given their context and their legal knowledge and so on like that's that's a good system not the endtoend solve my problem for me system that's just not feasible right now and it's kind of stupid of the companies and the legal field who expects that uh to currently Focus so Much on that and of course they're going to run around like chickens be like oh hallucinations hallucinations the problem isn't
hallucinations the problem is you're trying to use a tool for something that is not not for it's not for that all right good hallucinate ations what are they in this paper they divide hallucinations in two categories so they have a category Of correctness refers to the factual accuracy of a Tool's response and groundedness the relationship between the model of response and its cited sources uh correctness a response is correct if both factually correct and relevant to the query and is incorrect if it contains factually inaccurate information it can also be incomplete uh or so for
example if it if just refuses to answer right so they categorize that As a refusal um and groundedness do we have groundedness here a response is grounded if the key factual propositions in its response make valid references to relevant legal documents and ungrounded if the key factual propositions are not cited and misg grounded if the key factual propositions are cited misinterpret The Source or reference an inapplicable source so if the grounding is wrong not just missing but wrong they call that a Hallucination misg grounded and if the response the output independent of grounding is incorrect
like makes false statements that's also a hallucination just refusing to answer is not a hallucination and neither is the ungrounded so if if it just doesn't site anything then um they also don't say hey this is a hallucination now yeah so you can see there is a big difference between um correct correct and grounded Helpful right that's a different thing entirely what's helpful to the people who use it um whether it's sourced in something real right like all of these things are very different so when you look at these results remember what they call a
Hallucination is just it's either this or it's this now the interesting bit and that's what I was missing is they don't divide the results between these two right they don't tell me how many of Them were incorrect versus how many were misg grounded it could even be both right it could be both and those would give very good uh insights into how to make these things better but they don't do that they have yet different metrics which they call Accurate maybe yeah accurate responses which are those that are both correct and grounded okay so um
and incomplete responses which those that are either refusals or [Music] ungrounded so accurate is when it's the these with an and and incomplete it's when it's either this or this so for example it could be ungrounded and correct or it could be grounded but refusing to give an answer so those would be incomplete responses or it could be ungrounded and refuse right which is probably most refusals are going to be ungrounded in any Case yeah they don't distinguish between these two main pieces of hallucinations and given that the paper is about hallucinations I would expect
that to be a major part of it but unless I've overlooked something they never make that distinction and that distinction would actually be the helpful distinction because that would give you an indication of how to improve uh this so I I don't know I I feel that that's kind of a mishap on the on the part of The the paper writers right here but maybe I am misunderstanding something all right so the um yeah their data set they construct a data set it contains sort of General legal research question uh for here is an example
and here yeah you see how complicated these get has a habus petitioner's claim been educated on the merits for purposes of this this where The state court denied relief in an explained decision but did not expressly acknowledge a federal law basis for the claim this is real question that real lawyers care about that they would have either in University or in their real daily practice um and you can if you know anything about llms you can see that even if you give them their best search engine on the planet about across these public documents there
is no way there's no way There's no way it can this abstract you know um where the state court denied relief in an explained decision it has to know what an explained decision is where to find that what you know denied relief what that means like what do you even search for when you have something like this denied relief could either be an explicit term or it could be a completely abstract concept that would require you to search for H and legal professionals will know but These LL it's very very hard for them to you
know grasp all of this complexity and do it all by themselves right and then even if they let's say they get all of the relevant references and so on then it's like ooh you know a legal professional would actually look has this been overruled since you know is are there other opinions and so on are there other things to consider right just from a legal practitioner's point of view is there I don't know I I for Example I know if there's some some kind of this treaty with a country it always overrules the kind of
um I don't know the the more general rule I don't I'm not I'm not a lawyer right but yeah it's it's giving tasks like this to an llm is Highly Questionable um yet jurisdiction or time specific right um where questions about circuit splits overturned cases or new developments um false premise questions those are Those are a bit Shady to make because the tools are are geared towards professionals and not towards you know sort of normal people who would be very often very mistaken about the premises or could or would be um like if if you
use these tools and you will know that you're not you're supposed to ask your questions in a way that don't make don't give a premise but uh or like open inquiries because these models they're very agreable so if you give them a False premise they will like to fulfill that premise even though it's wrong and only very few times say actually that's wrong yeah so I don't want to go too much into this um the the questions are made are specifically tailored to rag based open-ended legal research tools so they do aim to test the
kind of systems that they're interacting with right here and y y yada so you can see the um The results right here here split up in a bit different way so note how different this this graphic is from the graphics before just in sort of order you can see the way you measure and the way you present the results and what the Baseline is and so on makes a huge difference uh in terms of that so Lexus um in terms of proportion of responses falling into accurate incomplete and Hallucination is ahead here with 65% practical
law uh very few accurate Responses however also very few hallucinations so the graph you saw at the beginning is kind of the uh flipped version of the red bars up here but when you only look at the proportion of hallucinated responses while responsive meaning not not refusing um you can see that the proportion of of practical law is high because this bar here is almost as big as this bar right here again depending on how exactly you display the results how you measure what You categorize how you will get you can you can get various
effects right here um they also split it up down here in terms of in terms of oh yeah this I find also interesting we also note that it is the system and by it we mean Westlaw so the system that's technically like bad um this is a system which tends to generate the longest answers meaning Westlaw contains more falsifiable propositions and therefore has a greater chance of Containing at least one hallucinations aha so now they they try to make a system that gives more comprehensive answers and so on the way these people measure hallucinations is
well if in the answer something's wrong it's a hallucination right right uh so maybe the users actually like that maybe the users know that it sometimes uh doesn't say something that's correct but maybe the users appreciate the more extensive Answers and um actually prefer that to a system that just gives them very short answers uh with a higher reliability who knows but again the way you measure the way you assess has strong strong influence on ultimately the outcome right here uh so keep keep this in mind that this here is maybe maybe one of the
heavy contributors to the score rather than the system just being worse by default hello this is Yanik from the Future editing this video so this video is already super duper long and you can see I'm skipping over quite a number of results here now the paper does a good job uh presenting lots of examples of the different stuff and I do recommend that you look into this because it just gives you a idea of just how far away real world retrieval and reasoning use cases are from your simple oh here is our 50 you know
clean documents that I want to ask questions about uh so yeah Highly recommend that I will not do this in the video um but the paper is linked in the description back to past yanic they split it up yeah um what I found cool in this category false premise uh gp4 actually does pretty well and that's a property again of retrieval augmented generation where if you provide references but your premise is wrong then you're just loading wrong stuff into the context so the more you do that the more you convince the llm That actually you're
right and it should just adhere to what you're saying after all it's your assistant it's supposed to please you right so gp4 without and that's not the fact of gp4 that's just this is a assist where you don't do retrieval augmented generation is going to perform quite well of course however practical law also very good just kind of refusing um refusing the hell out of this because it's just like well I can't answer that or no sorry not refuse yeah Incomplete answers yes I also be like well don't have anything about that yes of course
you tested the wrong thing all right they have a bit of a taxonomy of errors but as I said uh they don't have anywhere don't have anywhere they split up between in Incorrect and misg grounded which I would really loved to see however I think it's obvious that a lot of the errors here happen because of poor retrieval so many failures in the three systems stem from poor Retrieval the retrieval itself often requires legal reasoning that's exactly why we make search engines that humans can use and then you know have the humans work with it
because the humans are aware have the context and have the education to assess what's relevant and when you let humans and machines work together is better than when you just let the machine do everything end to end and no agents aren't going to solve that layering in more prompts and more Prompts and more prompts at this particular point with the current llms is not going to solve that I'm very very sorry about that yes um yeah don't want to go too much into that I do love their conclusion right here the conclusion is this AI
tools for legal research have not eliminated hallucinations users of those tools must continue to verify that the key propositions are accurately supported by the Citations no I this this is this comes as a complete surprise nobody in the machine Learning Community could have told you from the very beginning that this was going to be the conclusion of all of this this is a shocker I'm I'm glad we went through all of this to arrive at this astonishing conclusion right here look at the end of the day this is software like software is is a tool
is technology that can help you but you Need to know what it does you need to know what it's good at you need to apply the correct tool to the correct problem and then you need to be aware of how you need to treat the output it's this has nothing to do with AI this is just a property of software and so many people just seem to forget that because it's sparkly and it's fancy and it's chat GPT and it's woo and it's just a text box and it can do anything and that's dumb all
right this was what I thought about The paper um and yes I'm sorry academics I'm sorry uh no systematic these are products they don't owe it to you to give you access no much how no matter how much you stomp your feets these are products I don't like open AI not giving access to stuff because they at the beginning their whole premise was they're for everyone and they rug pulled the entire Community that's the problem but these things here they're products For professionals and they're under no obligation to give you access and bullying them into
giving you access by just reporting numbers on something that's not meant to be uh used for this task is not the way to go and no matter how much you complain it's not it it's completely fine they're commercial products they're allowed to do to keep stuff you know for themselves and just sell it and their customers need to evaluate how to use them that's it thank You so much for listening watching and uh yeah let me know in the comments I know this was a bit of a longer paper and a bit more rant but
yeah that's that thank you you bye-bye



![[ML News] Elon sues OpenAI | Mistral Large | More Gemini Drama](https://img.youtube.com/vi/YOyr9Bhhaq0/maxresdefault.jpg)


![The moment we stopped understanding AI [AlexNet]](https://img.youtube.com/vi/UZDiGooFs54/maxresdefault.jpg)




![How write a research paper in a weekend [My AI Sprint Framework]](https://img.youtube.com/vi/dPRNzPtgOeI/maxresdefault.jpg)
![[ML News] Chips, Robots, and Models](https://img.youtube.com/vi/tRavLU8Ih4A/maxresdefault.jpg)