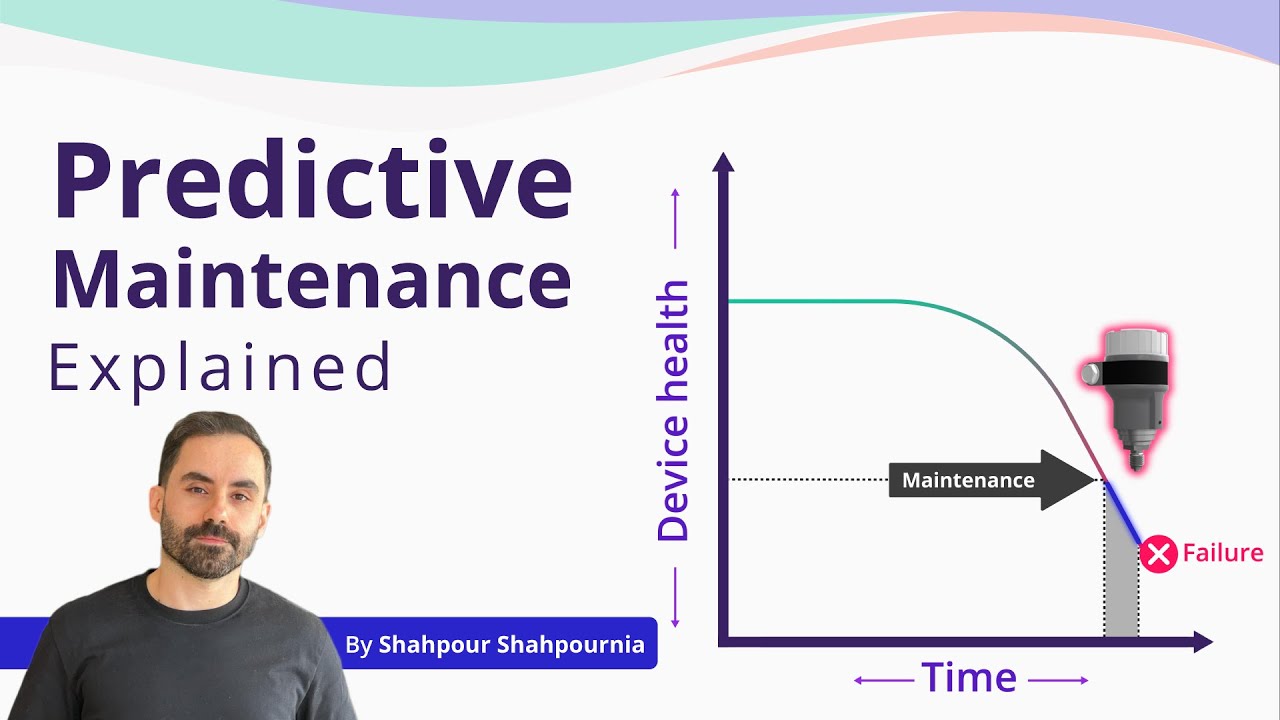
this distinguished gentleman is Conrad Hal Waddington biologist paleontologist even a philosopher and a poet not a heavy machinery guy by any means during World War II Mr Waddington was advising the Royal Air Force don't ask he looked into the way B-24 bombers operated from Northern Ireland to hunt German U-boats out of 40 aircraft at any given moment about 20 were out for maintenance because if you do maintenance often enough every 50 hours in flight for these bombers you prevent most breakdowns right well what Waddington found has changed the way we think about maintenance and reliability
so let's have a look at how we've got from checking airplanes every 50 hours to detecting failures before they happen and even predicting the time when a machine stops let's talk about predictive maintenance from Roman aqueducts regularly cleaned of lime to maintaining Victorian age steam engines just marvel at those boiler explosions a byproduct of the Industrial Revolution to state-of-the-art airliners the common assumption remained the same to increase reliability regularly take your machine apart check it and substitute some components for the new ones you do it on a schedule and if this cycle is tight enough
there's a high chance that you'll prevent a catastrophic failure before it manifests itself this is called preventive maintenance and it's based on the useful life principle but then all of a sudden World War II came it forced Humanity to make a lot of technological discoveries and unveil some cognitive biases so let's get back to Mr Waddington he ran some statistics and the results were most unexpected unplanned repairs happened right after the scheduled maintenance in those bombers and then they tended to slowly decrease before the next scheduled procedures happened rigorous maintenance did more harm than good
as each disassembly Disturbed a working system as a result the Royal Air Force dramatically extended maintenance Cycles some procedures went away while bombers flew 60 percent more good for them and not so much for German U-boats today this brutal graph is known as the Waddington effect it dented the idea that frequent preventive checks are a way to keep Machinery reliable so what's wrong with preventive maintenance unfortunately waddington's findings were classified up until the 70s but even before his notes were published two United Airlines Engineers Stan Nolan and Howard Heap started digging into the same problem
in the 50s Engineers shared a similar assumption if equipment reliability deteriorates with age you have to statistically find when that happens and schedule repair or overhaul before this curve ascends but when the failure happens here or here you start thinking of making the cycle shorter or every check more rigorous and thus more expensive for example it took 4 million man hours for a complete structural inspection of a Douglas dc-8 yet the failures kept on happening and their rates made the FAA nervous in 1960 a Joint Task Force consisting of FAA and Airline Engineers including these
two went on a quest to fix that Nolan and Heap wondered what if age is a bad predictor of failure several years of gathering statistics LED researchers to these graphs they plot the failure rates Against Time it turns out that only two percent of all aircraft components fit the useful life intuition and deteriorate with age while 68 percent rather die in their infancy but if they do survive the failure rates stabilize these two percent are simple components like tires or brake pads that suffer wear and tear as time passes but looking at patterns overall you
can see that only 11 percent of systems can benefit from age-based maintenance these findings led to perhaps the most impactful strategy in modern maintenance engineering adopted across industries from Power Systems to Walt Disney Parks it's called reliability centered maintenance RCM suggests that you use different maintenance strategies depending on the nature of the equipment and the nature of failures some components like those two percent must have a hard time maintenance schedule some are just allowed to Die the strategy is called run to failure and usually applied to non-critical Parts the aircraft won't fall out of the
sky if you can't recline your seat sorry finally you monitor the condition of some components to detect the early signs of degradation and schedule maintenance accordingly hold on but what about reliability how do you ensure the aircraft won't fall with this sort of maintenance that's the neat thing you don't RCM says that you have to Define critical systems and double or triple them so that any unexpected failure doesn't bring a machine to downtime or an aircraft well down to the ground the first aircraft to experience RCM was Boeing's 747. it took 66 000 man hours
for a complete structural inspection remember a simpler Douglas dc-8 with 4 million man-hours so RCM is the Cornerstone of modern techniques that make Machinery reliable and cheaper to maintain and most Innovation happens with condition monitoring and predictive maintenance back in 2001 a survey of 500 plants showed these techniques on average led to a 50 reduction in maintenance costs and a 55 reduction in catastrophic equipment failures let's start with condition monitoring if you look at the marketing materials of equipment vendors you may see that condition monitoring is often called predictive maintenance arguably it's totally not true
as condition monitoring can tell us that something is wrong with a machine but it can't forecast the exact time of its demise what you have to understand is that any Modern Machinery provides feedback on its operation this is Eugene of Duke formerly an engineer at Boeing and General Electric and now a project manager at all techsoft so condition monitoring is a very common given that we have enough operational history to detect that let's say an engine overheats or its vibration levels are out of acceptable limits and sensors aren't anything new the first vibration meters appeared
back in the 50s while the first thermometers appeared in 1612 but it's a matter of how we use them early vibration analyzers weighed 34 kilograms and were hardly suited to be used anywhere besides a lap setting today sensors can weigh 90 grams and be installed everywhere and stream data to a server for analysis and there's a large variety of parameters we can capture temperature and infrared thermography vibration frequency hydraulic pressure electrical current ultrasonic noise humidity oil contamination once you have sensors installed there are two ways for you to do condition monitoring setting Health thresholds or
using machine learning for anomaly detection so a standard way to do condition monitoring is to gather sensor data over time and Define a threshold of say vibration frequency that your turbine must stay Within if vibrations or temperature go beyond that threshold the system will send an alert to check this turbine this is the most common way but it has drawbacks if your threshold is too low you get a lot of false alarms that operators must check if it's too high you risk missing a sign of an upcoming failure what does the decimator say 3.6 ronking
but that's as high as the meter 3.6 not great or terrible simply put however widespread the threshold technique may be it's not very precise here's when machine learning can help anomaly detection is a common machine learning task that looks at data to find outliers in the case of condition monitoring the outliers would be those sensor readings that fall out of distribution unlike setting a straightforward threshold anomaly detection can be quite sophisticated factoring in several parameters at the same time for example it can answer the question is this vibration frequency normal given the age of the
turbine ambient temperature and the current workload the simplest approach to anomaly detection would be to use the main ml technique supervised learning we have a history of normal readings and those that preceded failures so we train the model to distinguish between the two and in the new data recognize those Troublesome signs but it's easier said than done for instance this temperature Spike may be either a malicious anomaly or a benign event that has nothing to do with the fact that this rotor will fail in two weeks if we take the temperature readings down the line
and closer to failure as sample data to train a model does that even help given that the rotor failed in a couple of hours so here's a paradox factories Machinery operators and vendors have terabytes of sensor data but very few reliable records that predict breakdowns an alternative approach is to use unsupervised learning it means that the model doesn't know how specifically the sensor readings that signal an upcoming failure may look but if they stand apart from the rest of the historic measurements it's an anomaly so let's sound the alarm and wake up the operator General
Electric a Machinery giant producing systems from aircraft engines to railway locomotives combines both supervised and unsupervised techniques to run an early warning condition monitoring system on top of that they apply semi-supervised learning to train models based on limited failure data and then scale that to the rest of the readings but why do so many companies label condition monitoring as predictive maintenance for instance the Dutch Railway maintenance company struck on rail tracks sensor data in rail switches to detect anomalies and predict failure at least seven days in advance they call it predictive maintenance you see it's
a matter of the question the model is capable of answering with condition monitoring it can answer the question is it likely that this rail switch fails in seven days this seven day Mark is enough for many companies to call their model predictive and ultimately this may be enough to close this rail section dispatch a repair team and avoid unexpected train events but you still get a yes or no answer so let's explore then how real predictive maintenance works condition monitoring can tell us that a failure is about to happen a more ambitious goal is to
know when if you know how much time is left you can extend the life of your equipment and precisely plan for downtime the primary metric here is remaining useful life or are you L as you've guessed it normally tells how many cycles a machine has left before dying given its current condition before data became the new oil and AI was wedged in everywhere to solve all problems imaginable engineers and scientists had their way of predicting remaining useful life many machines have lived through Elon Muskie in Hell a simulated reality if we know the laws of
physics materials and failure modes we can convert them into code from weather forecasting to gaming physics Engineers can make very impressive simulation models so we create a digital twin of equipment track the current parameters of the real system and simulate with high precision in its lifespan before it breaks not only do we use models to maintain equipment but also to design its prototypes doesn't prevent Engineers from throwing chickens into turbines though the problem is simulation is very expensive Elon you literally need super computers and hundreds of thousands of dollars to constantly run those models on
a handful of equipment parts let alone on the entire Factory for example a precise model simulating crack propagation of a single flat plate took 96 hours to compute on an Intel i7 processor back in 2014. modern processors aren't appreciably faster a a cheaper way is to use predictive machine learning models if you have those sensors that stream data right to the server as usual the problem is quality data for supervised learning you must have enough history of Lifetime data and run to failure events to train a model capable of forecasting the remaining useful life sometimes
you do have this history remember RCM you may want to promote some components from the run to failure strategy to predictive maintenance if you are smart enough to gather sensor readings of these components you have the data but run to failure is an approach that we normally apply to non-critical parts and you don't expect say aircraft engine manufacturers to let their turbines die mid-flight just to gather relevant data what are the options then well you can get back to simulations and digital twins generate enough synthetic failure data and then use it to train predictive models
another way is to dedicate an actual batch of your Machinery wear it to death and gather sensor readings in the process finally equipment manufacturers May provide threshold data the health characteristics screaming that something is wrong with your pump or bearing to forecast the remaining useful life your data team can take the current readings and threshold readings and train a model in drawing a curve to the point where say the pressure indicator reaches the threshold the time it takes for a pressure to reach the threshold would be remaining useful life so there you have it you
may have basic condition monitoring with a simple Health threshold or you can run anomaly detection ml systems to detect failure that's about to happen you may use supervised unsupervised and semi-supervised learning for that sometimes you would call it predictive maintenance if you can anticipate failure at some specific time in advance but if you need to estimate when exactly the failure happens you need predictive maintenance capable of forecasting the remaining useful life if you have a lot of computing resources you can run simulation models if you have the right data you can run machine learning predictions
but wouldn't it be great to combine all of that let's have a look at what Advanced hybrid predictive maintenance systems look like you may have noticed that Aviation supplied a lot of examples in this video there's a reason for that besides the fact that we love aviation aircraft have always been the drivers of engineering Innovations no other industry in the world is so dedicated to reliability and well safety aircraft engines the Marvel of engineering were among the first to benefit from the adoption of predictive maintenance and today engine manufacturers are pushing further to combine all
of the techniques for instance Rolls-Royce yeah when we hear Rolls-Royce something like that out of a crypto Bros dream comes to mind but the car manufacturer and Aero engine business have been two different companies since the 70s anyway Rolls-Royce has been tracking engine performance mid-flight for more than 20 years as the engine flies it streams data from its sensors to a satellite which in turn reroutes these readings to Rolls-Royce servers for monitoring satellite bills may be high so once on the ground an additional batch of data will be uploaded summing up about half a gigabyte
of data per engine per flight the strict flying instruction but each pilot has a slightly different style of flying and the operator craft over different Terrain in different climate condition So eventually the technical condition of each engine is unique and that's exactly what Rolls-Royce has been looking into each engine has its digital twin which receives sensor data streamed from a satellite and uploaded in batches after each flight it's also aware of the whole repair history and operating conditions to consider during the simulation besides that all digital twins are connected meaning that each engine provides its
subset of data to be analyzed with all its data Rolls-Royce runs condition monitoring to detect anomalies and check the engine on the ground if something looks wrong and finally ml-based predictive maintenance models forecast the useful life of components that go into each individual engine as the company claims it helped them extend the maintenance cycles of some engines by 50 percent while maintenance requirements are planned years in advance it all sounds cool Tech Singularity is near but General Electric Rolls-Royce and Lockheed Martin are industrial juggernauts Landing multi-billion dollar Aerospace military and National Rail contracts they seem
to dwarf other companies that operate machinery well it doesn't mean a small or mid-sized business can't afford Advanced predictive maintenance in reality General Electric predix platform Microsoft Azure iot Central IBM Maximo AWS with zamentous core and many more are cloud services already available to receive and centralize data from sensors with that infrastructure you can run condition monitoring and make remaining useful life predictions so the technology is already here thank you one thing to mention you must have someone who understands data engineering and machine learning so check out our videos on the topic to learn more