All right so the main event today is we're going to discuss cash coherence but before we get into uh cash coherence let's finish up our discussion of spark uh you notice that uh you know instead of me teaching uh on Thursday Kavon did and that's because originally we thought that uh based on when the programming assignment would be out that you would need to to know about optimizing DNN code on the uh GPU but Given that we've delayed the uh program assignment three and and so four is delayed uh turned out that we didn't quite
need uh the uh order of lectures and so things are a little uh not as uh smooth as we might like but nonetheless uh you guys can contact Swit right all right so back to spark right so where we left off we were talking about uh how to design a system for doing distributed computing on a cluster and remember the characteristics of a cluster of course Is you've got separate nodes or or servers uh that are connected by a network and each of the servers is running its own operating system and has its own independent
memory system right so and the way that we communicate is by using message passing as opposed to Shared memory okay so the idea of you know inmemory fault tolerant distributed computing the goals of spark us you what if you have an application that makes lots of use of intermediate data right So we know that we can make it fault tolerant by using the uh map reduce uh system so what were the characteristics how did we keep full tolerance in in the map reduce system where do we put the intermediate data yeah on the hardrive right
on the uh distributed fast system the hdfs system which we know is Fault tolerant because it's replicated but the problem as we saw from the by looking at the system It's slow especially compared to the memory it's a 100x uh uh slower than than uh than than the memory and so the question is can we if we want an application that that makes lots of use of intermediate data such as uh a iterative algorithm or a query uh the where where you've got the data in uh that you want to continuously make ad adhoc queries
to then you know the map reduce system is actually pretty inefficient right so how can we make Something that's much more efficient but still keep uh you know qual quality that we want in the distribut system is something that is still uh fault tolerant right and so the key abstraction we said was was the resilient distributed data set which was this readonly ordered collection of Records right so essentially this the sequence uh and uh the way that we get uh rdds is we start with some data on uh in in on the disk on the
hgfs and then We apply transformations to it right so we can extract uh the lines from the uh text file and get an rdd called lines we can filter which is another transformation to get mobile views and we can filter again to get Safari views and then finally we can uh uh create a count from that which is not a transformation and so of course so the result is a single scaler instead of an rdd all right and so uh we were looking at sort of how we Implement rdds and we Said that you know
the problem was is if you didn't do things efficiently you could end up with huge amounts of memory for the intermediate data and uh so of course this course is all about improving power par performance and we said the parallel performance comes from you know you've got to have lots of parallelism lots of things to do at the same time but you also have to optimize for locality right we've talked to talked about a couple of of of uh Mechanisms for optimizing locality and you just saw uh these used in in the uh last lecture
uh uh one was the idea of of fusion Loop Fusion right and here of course we're trying to minimize the need for a external uh uh memory access and and we're try trying to improve or increase arithmetic intensity and this an example uh we saw that here in this example and you saw it in uh uh doing uh attention right so so Kon talked About Flash attention and that's essentially a combination of fusion and tiling right and so tiling was the other locality optimization uh mechanism that we we talked about and we said that essentially
in order to get these sorts of Transformations you have to uh understand uh the the the application because you potentially have to globally restructure things and so the nice thing about the uh spark uh implementation is that you have the uh Ability to do fusion with rdds since uh you've got a set of bulk operations these Transformations and rdds and the runtime system the spark runtime system can look at what uh uh is happening and optimize these things so in in this example we've got these Transformations uh to create lines lower mobile views and then
finally uh an action to create how many and what you like to do of course is implement it in a fused manner such Uh as this in which you just fetch one line from the file system and then everything else is kept in memory a and and you only do it a line at a time right and so so this is uh ideally what you'd want to create and the spark runtime system will do this for you and it does it when it can analyze the Transformations and determine that you have narrow depend depes right
and in narrow dependencies uh one uh rdd only depend the partition Of of one uh rdd only depends on a single previous partition right for in instance uh uh the lower partition zero only depends on the Lin's partition zero and the mobile views partition zero only depends on the lower partition zero right so you can imagine then that the uh runtime system can fuse all of these Transformations such that you don't have uh any uh uh you extra memory accesses or external memory Memory AIS so so there's no Communications between nodes of the cluster and
uh so everything can be fully optimized and run uh very uh efficiently so the problem is is that that you can have uh Transformations that have wide dependencies right and which would require communication between the different uh nodes in the system so an example would be group by key right where in order to uh determine the group by uh uh uh uh uh partition Zero for rdb you would have to communicate with all the other nodes in the system to uh get the data from the different partitions from partition one partition two and partition three
for example right so in this case of course you can't do the fusion right uh within a single node and uh so you know this is something that would have a lot of communication right so the question is in what cases can you optimize uh operations like group by key Uh so look at this example in which we are trying to do a join right so you're going to join by key and uh depending on uh how uh the uh the rdda and rdb which you're trying to join to create uh RDC uh you know
if if you didn't know anything about uh the RDA and rdb then clearly you you would have to communicate uh across uh all the nodes in the cluster in order to to uh compute ODC okay so in what cases might you be able to get away without Communicating if you're trying to do a join for example so as shown here you have to communicate but could you imag imagine a situation where you didn't have to communicate yeah like a specific key would be uh like only in predition zero of rdda and only inition zero of
rdb and not in like the other exactly so that's the this situation in which you if you had if you Partitioned if you uh AA and a b such that the keys uh only uh the common Keys only existed in a single po ition then you would have narrow dependencies okay so that's is shown in in the second uh example here so you know essentially RDA and rdb have the same hash partition right and so that's shown in this example uh or this code here so you have an explicit uh hash partitioner right and you've
named it partitioner and you Use it to uh partition uh uh mobile views and you use it to partition client info right right so so when you do the join then the runtime system says hey these two rdds are being uh partitioned using the same hash partition partitioner right so it can detect that these are equal and it will determine there are only narrow uh dependencies and then it will make sure That the uh uh that you can do Fusion all right everybody follow that any questions yeah there might still be an imbalance of keys
right like one Rd has be a few keys and the other one has a lot a lot of entries with the same key right right so so there is this question of L balance uh but uh you know to A first order probably low balance is is less of a problem compared to communication so that's a good Point all right so so so now we have a way of sort of scheduling uh the uh computation for locality to improve uh performance and reduce the amount of memory required now let's talk about fault tolerance right so
we said you know the whole goal of uh the the spark system was to give you high performance IM memory computation with fault tolerance right so then the question is sort of how do you maintain the fa tolerance so remember this idea Of lineage right so you've got these Transformations which are these bulk uh deterministic trans uh uh uh operations on rdds right and so uh the lineage then or the set of Transformations that you apply uh starting with uh the uh data load from the uh uh distributed uh file system is the set of
uh transformation you know gives you a log of of the operations you need to perform to get to any particular rdd right so you know that if you want to get to uh timestamps You first uh you know load from the uh hdfs do the filter uh do another filter and then the map and so this list of of Transformations then is known as the lineage right so you've got a lineage is essentially a log of of Transformations that that can be uh used to recreate any Rd right and we know what what property did
we say that RDS had right they read only and Transformations are functional right which means they do not mutate their inputs right so we know That it's always possible given an rdd uh to you know recreate it from uh from the from from the hard disk from the uh the the persistent data that we know what will never go away in the system because it's replicated across uh all the nodes in the system question so if we're always we're not storing the intermediates we're just storing the log right so when do we actually I guess
materialize all this data is it just we just do all the Computation and then at the end we store whatever checkpoint so so why do you want to materialize data because at some point we need it right yeah yeah so so some some some point in in this case what does the user want time St probably right does the user uh necessarily care about the intermediate data no so you just try to fuse as much as you can right you'll going to fuse as much as you can and you know not not keep intermediate data
that The user hasn't ask for if the user ask for it yes see you got to you got to provide it to them but if the user didn't ask for it it's intermediate and and it could potentially uh go away the only issue is you know what happens if you lose that intermediate Data before you create the final result that the user wanted right okay so what happens in this situation where oh we're not done with the computation but there's a node that Crashes right so this is the example here so we've got a set
of Transformations that that give us a lineage that allows us to recreate any of the rdds that we have in our computation and you know in the middle of Computing uh the timestamps you know node uh one crashes right so it crashes and we lose uh the partition two and partition three of timestamps and mobile views okay so now what do we do yeah just kind of like lfs like just Reun the log We Run The Log so so we run We Run The Log we assume that the data exists somewhere else because it's replicated
in the hdfs right and we have a log of operations which is fairly Co grained right so it's not a huge number of of of uh of things that we have to remember and we uh reapply uh the uh the log uh in order to create the partitions uh two and three of timestamps right And so uh we uh we recreate that from uh the partitions of um of mobile views and uh well we start with lines we get get to Mobile views Chrome views and then we recreate time stamps okay so that's the way
that we recover from a crash question sort of the master node yeah the master node is keeping track of the the Lage we assume that you know that's one of the nodes and then it's not likely to fail Or it may be replicated one more question is um like if you kind of like the stand like the music B yeah it's just the LA of the Transformations so is it like like if you wanted to like like you know functions on your own kind of data like if you want to like you know do completely
custom functions how do you do that well remember you you've got to live Within the spark World which means is you have to do Transformations on rdds which are functional right so if you do things that are nonfunctional you start mutating your input then you've broken the spark abstraction and things won't work right but so if I have let's say like just a function that takes the input you output does not the you you've got a set your your data type is rdds the set of things you can do at Transformations if you go outside
Inside that uh abstraction you've you've broken things and you come and Spark it says hey you're on your own right other questions all right so you know so we have a way of recovering from from crashes and we get the you know the nice thing about spark of course is that you you get to use memory and you get the performance benefits of memory but you don't lose fault tolerance which is critical if you're doing data processing So how much performance Improvement do you get well this is uh you know the spark uh paper when
it came out uh you know 201 12 or something like that you know they compare toop and Hadoop is always a good Whipping Boy because it's so slow right and so uh in Hadoop this is the case they're doing logistic regression right which is a very simple ml uh uh operation and and K means which you're very familiar with because of course You've played with that uh and so we see the Hadoop uh the first iteration is 80 Seconds and subsequent iterations don't get much faster and of course each iteration requires an hdfs read and
an hdfs write uh the Hadoop um uh binary memory basically keeps a binary memory uh copy instead of a text copy and so it's slightly faster on the second iteration but still has to access the dis uh and Then spark only has to do the hdfs read doesn't do the right just wres State uh straight to memory and so subsequent iterations are much faster so you know spark is you know is significantly faster orders of magnitude at least one maybe two uh compared to using the dis which is consistent with the performance uh you know
Delta we saw in the bandwidths between uh s uh the um the uh the the storage system uh and and and memory Dam and uh Sdfs okay so uh we also see K means give you the same sort of performance benefit uh but you know as I said Hadoop is easy to beat because it it's kind of you know using the the file system so intensively uh but you know spark has uh gotten a huge amount of uh of traction for in the data processing uh world right so it enables uh you to compose a
bunch of different domain specific Frameworks uh together with this underlying rdd spark implementation which is uh it it works Pretty well and so you can uh combine uh the the Transformations with SQL so you can do uh database processing uh there's a spark ml lib uh which uh has a bunch of uh machine learning uh uh operations or library to do machine learning based on the spark exraction so of course you can use distributed uh uh uh distributed clusters and get the all the benefits of the spark system while doing machine learning and there's also
spark graphx uh which adds graph Operations to uh the spark uh ecosystem right and uh in in you know previous uh versions of this class uh you did uh graph uh analytics uh uh bre first search right made you do uh do you make you you don't do it this this for there's no breakfast search right right yeah in previous iterations you had to do graph analytics operations and so you might have been more familiar uh with the sorts of things that are in graphx all right so in summary then you Know spark introduces this
idea of the ID as its key abstraction and uh you know the observation is that you know using HFS as a place to put intermediate data when you're trying to do these iterative kinds of comp computations or when you're trying to continuously uh modify or query or sorry should query a particular set of data to do uh data analytics sorts of operations you know the htfs does not work as a good place to store intermediate data and so odds Are a much better uh idea and uh they can uh be used as a mechanism for
creating uh fault tolerance because you know you've got these Transformations which are these bulk deterministic functional operations on rdds and they can give you a log that you can replay whenever there's a failure and you can make sure that you can both get high performance and fault tolerance okay and as as we saw you know spark can be extended beyond the the set Of things that we showed uh in terms of Transformations and actions to do all sorts of things like graph andal analysis and and uh and database operations so one thing to be aware
of is that scale out is not the whole story so scale out was invented because people wanted to be able to uh analyze data that would not fit in the memory of a single uh uh server right so how much memory can you put on a single server today somebody give you somebody give me A number typically what what might you see in a law server how much memory gigabytes gigabytes terabytes right so maybe one half to two terabytes of of main memory on a big server right so there are a lot of studies showing
how spark could be used but the data sizes weren't really big enough right 5.7 gigabytes for this Twitter graph and 14.7 to uh gigabytes for this uh you Know synthetic graph and so if you can fit your data in memory then you don't want to use the distributed uh system to operate on it because you're going to have a lot of overheads and so that's what this uh table is showing it's showing that for 20 iterations of page rank on these GRS which fit in memory you can run uh Spock on 128 cores and you're
still you know two times uh slower than running on a single Thread okay so clearly if the size of your data you know uh does not demand using a distributed system then clearly you don't want to use it right and so uh there's a researcher called uh Frank mcer who kind of really uh took this this uh took aim at the distributed systems people he has this quote right he says you know published work on Big Data Systems has fetishized scalability over everything else and basically he says you you know They've been creating all these
overheads and then you know uh coming up with with with mechanisms to to uh reduce the overheads which they have created right so so and and you know he's arguing for let's look at performance uh uh As the metric instead of just scalability so it's an important point but the point is that you don't want to use these distributed systems if the size of your data doesn't call for It right so if you've got hundreds of terabytes of data then you know the only way that you're going to be able to process it is by
using a distributed system but if you just have you know less than a terabyte of data then you know a single system is going to be much more efficient so keep that in mind any questions yeah's the of scale out scale out is is as we've been describing where You've got individual servers connected by a network right so there sort of two uh Dimensions to scale uh people say scale out is when you are connecting nodes together by a network and scale up is when you are connecting multicores together in a shared memory system so
until now you've we've been F well until the discussion of spark we've been basically talking about scale up right where we are you know thinking about how to program multiple cores that are Sharing a memory so if you share a memory it scale up if you're not sharing memory it scale out all right um so now let's change our uh uh topic to to you know main topic of the day which is Cash coherence which is uh a very important topic because it both has performance ramif ramifications and it has correctness uh ramifications and it's
important from the point of view of of software Developers because you know they need to you need to think about how you write your programs in the face of cash coherence so how many people here have have heard of cash coherence oh good how many people here know about cash coherence protocols okay good all right well then you can help me teach the class all right so uh cash coherence uh so you know if you look at at a modern processor like the ones in Your myth machine you'll see that you know a large fraction
of the chip is is Cash 30% or more is cash and we've talked about the importance of Cashes in and locality in getting performance because of course if you have to go outside the chip to uh access the data that you need it's going to take you hundreds or maybe uh you know on very very M chips yeah several hundred cycles and uh you know if if the CPU is stalled uh while uh this is happening then of Course there's a a lot of time uh that you waste and your performance is not going to
be that good all right so let's return to uh I think kon's first or second Le lecture which is on this cache example right and so we're looking at an array of 16 values in memory and uh we said that we we're going to divide the memory addresses into cach lines okay so cach lines are multiple bytes or multiple words that are uh contiguous or consecutive Addresses in memory okay and uh lots of reasons that you want to have cach lines uh but uh one of them uh we said what was one of the reasons
that you wanted cash lines yeah spatial local to exploit stal locality that's one of the reasons you want want cash lines okay the other reason you want cash lines is it helps you uh do the implementation of cache coherency more more efficiently and it makes use of the data pods within the Memory system because you move whole cach lines and moving things in bulk is more efficient than moving things one at a time all right so we talked about uh we defined what was a cold Miss cold miss somebody back yeah when it's for the
first time you haven't loaded anything the first time that you have you access an address it cannot be in the cash right so the cash is said to be cold as far as that address is is concerned so it's a cold M all right so Then we get to and we get uh access for and we get another cash mess we talked about spatial locality uh so what was on the on the topic of spatial locality you know Architects think about Hardware mechanisms to exploit program Behavior so what kind of program Behavior leads to spatial
locality yeah sequential access sequential access where exactly so so so that qual where's the other place that you see spatial Locality yeah the instruction in the instruction access stream so both in data and instruction you're going to see spatial locality and uh and it's exploited by uh by the by having a cach line okay so we said cold Miss uh then temporal locality is the other ma uh uh type of locality where might this exhibit itself in program Behavior temporal locality yeah the counter variable how we access yeah counter variable you keep accessing Maybe stack
accesses when you're doing a recursive uh uh uh uh function right so repeated access to the same address is temporal locality okay so we said that we had cold misses and then at some point in this uh cache we uh needed to replace something because we had run out of uh places in our cash and I think this was mislabeled a conflict Miss but it was actually called a capacity Miss right if we had a bigger cash we could Contain three or four uh uh cach lines but we can only have two cach lines and
so uh we have to replace one and we have a capacity Miss right so we have two types of Misses cold misses and capacity misses okay and now let's talk about a third type of Miss there's a miss model that was created by uh uh a researcher named Mark Hill and it's called the three C's model right so you've heard about cold youve heard about capacity now let's talk about the L which is Conflict okay so uh in order to talk about conflict let me you know introduce roughly the design of the uh Intel Skylake
chip which is uh the chip in the myth machines okay so it's got three levels of cache L1 data cache uh which is 32 kilobytes in size uh an L2 cache which is uh per core so four cores uh the data cache is private per cor the L2 cache is private peror and then there's a ring interconnect Which is as you might expect is a ring right is that connects all of the different uh uh L2 caches together and they connect to a shared L3 cach which which is uh 8 megabytes in size uh okay
so uh what do we mean by a conflict Miss well it turns out that uh in order to simplify how you uh find things in caches you limit the number of places that any line could go this is called associativity so the L1 cache here in the data C in in in the uh skyl chip is Eight-way set associative and that basically says that I only need to look in eight places uh for any particular uh uh uh line okay so uh in this case uh our line size is 64 bytes so if I have
a 64 byte line size uh you know a f thing to do is sort of uh uh cache arithmetic right which says okay if I've got 64 bytes in my cach line how many lines do I have in my 32 kilobyte cache 512 right 512 lines okay so if if I have 512 lines in in in my uh cash then a fully General way of finding lines in my cache I would have to look in 512 places at the same time okay this is expensive okay and so to make it less expensive I'm going to
limit it to eight places however the difference between having a cash where I can look in 512 Places versus eight places is going to lead to more misses these misses are called conflict misses right so conflict misses are the extra misses you get because your cash is not what is called fully set associative which means you know a line could go anywhere in the cash right and this eight-way s of cash can only can only go into one of eight places okay so now you know about cold capacity and conflict okay yeah is that you're
only going Toore deep lines cash no no it's just saying that there's only eight places any particular address could go right so I don't have to look all over the cach I only have to look in eight places turns out it's cheaper to look in eight places than 512 places okay that's the intuition we could go into details but that's the intuition yeah yeah so if you have like this eight-way set Associated does that mean like like eight buckets yeah eight buckets that's good way to Think about it yeah do that mean that like would
it be rare for it to get to like 100% that's you you mean some some of those Pockets could be underutilized yeah potentially yeah yeah but usually not yeah yeah one question is the so you're saying the cash itself is like kind of like you're kind of branching on and you have things ins bucket you know they only there eight buckets and basically you look at the address you say which bucket you're Going to go in right got it so so when you have larger and larger caches do you have like multiple levels of these
buckets uh no no you don't need them uh no no you're still going to do it um you're still going to look look in have a way of usually you just have one level of set associativity right you don't have multiple levels right unless you've got another level of cash yeah this is kind of weird weird Actually because what you'd expect is as you get bigger the set of sociality should get should increase but you know starts with eight goes to four and then goes to 16 it's kind of strange don't know why the designers
did it that way but that's not what you would typically teach you say hey as you get bigger you get uh uh more set associative right because you're trying to cuz remember higher set of set ofof High set associativity means lower conflict Mis Rate right because as you increase the set ass associativity you're going to decrease the Mis rate all right so let's talk about cash design uh so you've got an uh a line in the cache they're two pieces to the line one is the data right that is is going to be contained in
the cache and the rest is the metadata right which basically tells you about the context of the cach line right So a key pass part of the the the metadata is the tag which is essentially the address of the data right so you you got this data from memory and you need to know which address is which cache line Sorry which memory line is in the cache right so the tag is going to tell you that right and then uh there's a Dirty Bit which tells you about the whether the data in the uh cache
has been modified or Not and so in this example we are going to write uh one to integer X which exists at the address shown uh there uh hex 1 2 3 4 5604 and uh the four indicates that you know it's the the fourth element uh in uh that's the address of the bite in the line okay right so reading from caches is fairly straightforward writing is a little more complicated because writing is always a little more complicated all right so There's uh two types of writing uh can anybody tell me the difference between
a right back cach and a right through cach yeah exactly so right through Pro says when we do the right to the cash we also write to the main memory and right back says we only write to the cache and later the data is actually written to main memory because after all you want a write to main memory that's the whole goal right the cash is just this Intermediate storage buffer what about right allocate versus no right allocate does anybody know what that is yeah right so the question is what happens when I write to
the cash and the the the the line that I want is not there do I allocate do I actually fetch the rest of the line and write into the cache or do I just write directly to main memory okay so with that in mind let's look at Uh an example where right allocate right back cash on a right Miss and I'm going to write to uh one to the address X so what happens so the processor performs a right but it misses in the cache the cache selects the location uh if there's a dirty line
currently in the location then of course what what does the Dirty Bit indicate about this the the the data in the cach line yeah it's different than What's in memory it's different than what's in memory it may be the only place that this data exists in the memory system should we lose it no we should not lose it and to make to make sure we don't lose it we indicate that it's dirty and then when we replace the line we know that we can't just drop it on the floor that we need to write that
data back to main memory and so that's what we do and then uh since since this is right allocate we need to you Know allocate the line we need to go get the data from the main memory but we know that the M the data in the main memory is not up to dat so of course once we bring that data into the cache we then write the uh the the data uh in this case one and then we set the Dirty Bit to one any questions yeah could you just explain Again to the right
back versus right through yes right back versus right through so right back is this example right where we had a a Miss in the cache and we uh so right back versus right through uh I should I was thinking allocate so right back vers versus right through so right back says I'm going to write into the cache and set the Dirty Bit right and then later That data is going to be written to memory when the line is replaced that's right back right through says when I write into the cache I also write to memory
and so that means I don't need a dirty bit right because I know memory is up to date at that point all right so um so the shared memory abstraction right we said that essentially what we're going to do is we're going to share we're going to communicate and Yeah question yeah you previously I had two questions just what was step for again cash espe yeah so remember it's it's allocate so allocate means that we want to alloc on a Miss we are going to allocate a line in the cash so of course we only
have 32 bits of data that we're writing from the processor so what about the other uh words or bites in the cach line those have to be updated those have to be valid right so we have to go and Get the data from Main memory essentially you you perform the read right as if you you were doing a a read Miss so you you get the full context of the cach line and then you update the particular word that's being written by uh the store um so is for the update and just the load into
the cach yeah Oh loads lying for me yeah it seems uh a little redundant yeah so loads live for memory yeah okay so so maybe we do this to make make it right is that better what was the tag again sorry I just missed what was this tag yes so tag essentially is the address of X goes in here address right so remember how do you Know what's in the cash right it's not you it can't have all the contents of memory right so you need to tag the cach lines and and tell to to
to tell the the system what data is in the cache right yeah is there yeah we'll get to that that's the that's the topic of the rest of the lecture yeah yeah is the time address address ofh ta what do you no it's the address of the memory right The the address of the cash is kind of unimportant right it's an array but what's you the way the way to really think about caches is that content addressable arrays right and the contents that you're off is the tag right you're saying given an address that gets
generated from the processor does the cash contain it right so I need essentially the the action that's going to happen is I'm going to take the address that was generated from the Processor and I'm going to compare it across all of the tags in my cache right and if any of them match or typically one not not more than one then I'm going to say hey I've got a hit right so do I really care about the the particular address of the of of the of the the location in the cache not really right I
only care that it has uh a tag for for the data that I'm offing yeah if you address like memory that's right adjacent to the one in the tag that Might still be in The Cash Line right because it's a continuous bit of memory yeah yeah yeah so I'm I so I've I've I've kind of glossed over a bit in that this is not the address of X it's the address of the cach line right because if it were the address of X then then then then how would I be able to exploit spatial locality
so every every every address that falls into this Cach line is going to be represented by the tag right and you B basically you just drop off bits from the address in order to get the the the address actually goes in there yeah so like is it that so just going back to like particular like particular section of tags are supposed to go particular I said we could go into details here but believe me uh they're Not necessary we can talk about it later yes there's this whole set of things that you have to do
to actually get the data right and actually do a cash lookup and that has to do with set associativity but you know as I've explained it here you know we won't go into the into the details uh but the thing to remember is that higher set set associativity will give you lower Miss rates and that the the higher the set of Associativity the more difficult it is to do the lookup all right good so we we said essentially that shared memory uh programming thread-based programming is we're going to share addresses we're going to uh make
sure that we uh uh access the data uh when we want to properly using synchronization and uh now we want to talk about sort of you know how we expect the shared memory multiprocessor To behave right so you're we're going to read and write to Shared variables by the processor is going to issue loads and stores right and so if I said hey here A bunch of processes they communicate over some interconnect uh to memory you know how do you expect these processes to behave right and and you know your intuitive answer would be something
like well if I store a value to a variable x uh and uh I then on One processor and I load that value uh from another processor I should get you know the L value that was stored uh to that variable okay and so that's kind of intuitively what you'd expect uh a multipro a shared memory multiprocessor the way you'd expect it to behave Okay so the problem is that once you introduce caches into the into the system now you have more than one place that the data or or or the addresses in the Memory
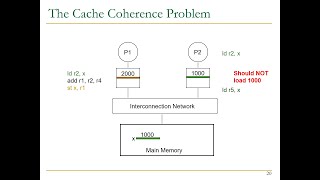
system uh uh can be all right so uh and you know if you have any particular memory uh location uh you can uh now get into trouble right so in this example we've got uh these processes with with their individual private caches and they're connected via an interconnect to the main memory and we have a variable Fu which is stored uh at address X right and so let's track uh how the processes access uh this variable or the variable Fu at address X So process a one loads X and it gets a cash mix and
so it goes to memory and gets the value and so now there's zero in processor one's cach right so abbreviation of cash is of course dollar sign okay and then processor two does the same thing also gets a cache Miss and gets the value zero okay now processor one act does a store to X says hey cash hit I'm going to update is the right back cash I'm going to update my uh Value of x to one okay then processor three does a load of X and it gets a cache Miss goes to memory it
also has uh a value of zero okay now processor three does a store of X and it update it says Hey cash hit and now the value is two and processor two does a load of X and then gets the value of zero because it's got it in its cache uh and it's it's a cach hit and then Processor one does a load of Y let's suppose we only have a single uh entry in our cach so we have a capacity Miss and so it uh gets uh yeah oh yeah so it gets replaced right
and so the value that it had goes back to memory okay so now we have in our memory system the value of x in memory is one the value of x in processor 3's cache is two The value of x in processor 2 cache is zero and processor one does not have uh the Val address X in the cache this looks like a disaster right okay so this is not a memory system that we could uh use and so the question is now could we fix this problem by using locks no no we we can't
fix it by using locks because fundamentally uh the problem is inherent to the fact that we've got multiple Places in the system that have addresses uh that that correspond to memory and we have multiple places in the system that are changing those addresses okay we have multiple processors changing their private copies of the uh the addresses in the memory system okay so how do we fix this problem so we have uh you know a memory coherence problem uh as I said you know what you Want intuitively is reading the value and address X should return
the last value written by x uh but because we've got the main memory being replicated by local storage and process of caches and then we have update dates to these local copies uh sh you know sharing the same address space we get incoherence okay so uh you know you can get incoherence even on a single CPU System whenever you have places uh that have a situation where you have multiple places that you can uh read or write from so for example um in in the Pro in a case of I an IO uh card uh
if uh you the io network card delivers data into a message buffer using direct memory access it could happen that the addresses in the message buffer are also in the cache they could be stale In the cach right so stale because they've been updated in memory and those uh uh updates have not been reflected in the cache so this happens rarely enough that you could probably fix it using software mechanisms right so you the software could flush all of the entries in the in the cache uh uh corresponding to the addresses in the message buffer
for example okay so you could solve it with software and this might be a reasonably uh uh performance solution Given the uh frequency of occurrence of of IO but if I'm actively sharing uh memory uh with with modable processors doing things with software is not really a solution so uh so the question then is you know we talked about this intuitive notion that I should get the last value of any address that was written by some other processor in the system the problem is what exactly does lost mean right so what if two processes you
know Right at the same time you know what who uh should should should should uh be the the which processor should be the last you know what if a right from processor one is closely followed by a read of processor two such that it doesn't have time to get that value how do we make sure that this situation works correctly so in a sequential program L is determined by program order right and so this is also the way that we want to think about the ordering in a thread of A parallel program okay and now
we need to think about how these threads uh values uh these thread updates are going to be be interleaved right so the way to think about coherence is coherence remember is just talking about a single memory location or maybe a single cach line so for any single memory location we want to serialize accesses to that location such that uh you know for any uh write in this case uh P0 writing value Five you know if in the serialization the P1 reading comes off to the right then it should get the value five and P2 comes
off to that right so it should get the value five and so on all subsequent read should get the value five until P1 does a right of 25 and then all subsequent read should get the value uh 25 so you have to be able to serialize access to particular address such that you uh can uh you know Uh a a and the notion is that the reads and writs should for for any particular thread should occur in the order issued by the processor okay and then the the value that you read is given by the
lost right in the serial order is that that all make sense okay so that's kind of what Behavior Uh that that we'd like to see and the question then is you know how do we get the serial order and how do we Make sure that that you get the right values from reads to wrs right so uh one way to uh provide uh you know coherence is to think about it in terms of invariance so what invariance do I want my system to hold right and so uh there two invariants that are important so for
any address X or any cach line address X we want to have a single writer multiple reader invariant so this means at any point in time uh you are in a read write EP epic where there's only one processor That can change the state of that cach line okay so read write epic only one processor can can change the state of the the cach line or you're in a readon epic where any number of processes can read that cach line okay so single writer multiple reader okay that's the first invariant the second invariant is called
the data value invariant and this just make sure that the value that was written in the last read right epic is what every Subsequent uh uh reader will see okay so in this example uh address x uh we have a read write epic P0 writes to address X and then the following read only eput the value that was written by uh p 0 uh is the value that uh is seen in the readon Epic right and then uh we have a read write epic where only P1 can write and then the value that is written
by P1 or the Lost value written by P1 is the one that is seen in the readon Epic uh following uh The uh read right epic yeah do that mean we have to like some sort of like flush between read yeah well we will switch we want that we we could flush but there may be slightly more efficient ways of doing things but there has to be a mechanism of switching between read write epics and read only epic so that part of the U intuition is exactly right yeah the you made about mocks and um
and And uh the cach coherency right it feels like if you have multiple processors uh accessing the same or writing to the same uh point the same address of memory you should anyways be like having some kind of locking mechanism right yeah I I guess I'm having trouble visualizing why this is still a problem if if when you're doing this parall rights well it it is possible for me to say you can write and he can write and you can write and you can Can't all do it at the same time but you could still
have an incoherent system in that he could write to his own cash and you could write to your own cash and she could write it to their own cash and you still have an inco incoherent system even though it was uh uh synchronized right yeah so the two two issues are are independent right one is a function of the fact that you've got two multiple places that the data can exist and that and that is kind of inherent in a cache Based multiprocessor system in which you are caching shared data right so you can imagine
a system that did not cash shared data and you wouldn't have a cache coherence problem what problem would you have yeah every memory access a performance problem right you'd have a performance problem but you wouldn't have a cache coherence problem but yeah so every every reference would have to go to Every shared memory reference would have to go to have to go to to memory right and maybe say oh I would design a very uh careful uh system uh to minimize the amount of shared data but you know you're kind of you know this is
not not a useful system right okay um all right so how can you implement coherence well there's some software based Solutions you could try and do things on the granularity of virtual Memory pages and make use of the operating system but it would be slow right it'd be slow and you'd also have a problem that uh we're going to talk about later which is called false sharing so what you want is a fine grained Hardware based solution uh based on cach lines and so we're going to talk about two different ways of doing cash coherence
or fixing the cash coherence problem or implementing cash coherence one is called snooping which is a Classic way of implementing cache coherence uh and then the uh one that you know is used most often today in most systems uh uh uh is a directory based system okay but uh we're going to start with snooping since uh I think it's slightly more interesting and easier to understand okay all right so we have a you know one way of of of dealing with cash coherence is kind of Back to not having separate caches having a single shared
cach okay and uh so what would be the problem of the single Shar cash yeah performance performance right so you have a bandwidth bottleneck because all of these processes are trying to hit uh the same cache and you've got a limited number of amount of bandwidth you can gather cash and so you might be able to do it for a couple Processes but if you wanted to scale a number of processes you would quickly run out of bandwidth or that that that cash would be extremely expensive the other issue is that what if the cash
contains data for that is not being shared uh then you can imagine uh One processor you know conflicting or having capacity uh uh misses uh caused by another processor okay so this is called uh interference or destructive Interference uh but you can also have constructive interference so imagine you had a for all uh loop like this in which you were had uh the uh iterations inter Leed across the processes right so in this code you can imagine that uh you know iteration I would fetch the the data associated with with the following iterations assume that
you know you didn't have uh uh you you had cach lines that were was was small say one one one word just for the sake of uh Of argument so you can have constructive interference as a in addition to destructive interference okay so shared caches don't really work that well for level one caches but you can use them for for level two caches so this is a processor I designed many years ago uh called the sun niagar 2 and it had a shared cach a shared second level cache and uh the way that you provided
enough bandwidth to that shared cash was by having a crossbar and a crossbar is kind Of an all to--all Network that provides you a lot of bandwidth but it takes up a fair amount of the area on the chip and uh it doesn't scale right you could get in this case you get to eight cores but if you wanted to go to more cores then you'd have have to come up with a different mechanism because crossbars are quadratic in the amount of of uh of wires you need right because it's all to all all right
so let's talk about snooping cash coherence schemes uh in The you know in the time uh that we have left and uh we will course not finish it today but we'll we'll uh uh come back to it uh on Thursday so the idea is that you've got a prod processor with its individual cache H with and uh the C the cash uh caches of the of all the processes are connected by an interconnect which is just this you know set of wires or way of communicating uh between the the processes and the processes and memory
okay so the Processor issues loads and stores to the cache right and then uh the cash receives coherence uh messages from the interconnect right associated with other actions that other processes are making okay so uh a very simple coherence mechanism would be a write through mechanism right where uh upon a right the cash controller broadcasts and inval validation message right which says hey I'm Writing address X if you have address X in your cash get rid of it invalidate it right so then we're sure that nobody else in the system no other cash in the
system has that address okay so what is the problem of the write through cache mechanism yeah all the other process do they have to keep kind of like pulling the inter yeah so assume that the cash is responsible for that right so the cash kind of decouples the processor from the Interconnect so the pro the cash is always looking at the interconnect saying hey you know is there an invalidation message on on on the interconnect if so let me check my cash do I have that address yes invalidate it no ignore it yeah what's the
problem if two processors broadcast the invalidation for the same address at the same time well somebody has to win right right so assume assume that this Interconnect only allows one message at a time and there's a winner right okay so so the problem with this right is is the right through cash right it says every right that the processor makes has to appear on the interconnect again we're going to run out of bandwidth so this is a low performance solution so what we want then is how do we do coherence with right back caches okay
so first of all we're going to change this interconnect to a bus okay So a bus has two very nice properties does anybody know what they are yeah they're really wide they're wide because I have lots of bandwidth but from point of view of coherence what what what properties do buses have that's not that's not a lot right so there there's only one transaction at a time so somebody asked about that right so Boss by definition one transaction at a time not true for a ring not true for an arbitary network But true for a
bus one transaction at a time so what does that mean when somebody says one at a time what's the first thing that comes to your mind seral serialization right so the buses act as a serialization point okay what's the other benefit of a bus kind of like the air in this room it's a broadcast medium Right One Processor says something and everybody else hears it all right so two properties of a bus we uh we have uh broadcast and serialization Okay so what we want then uh in our right back cache is we want to
make sure that whenever a processor is writing a value that is the only processor in the system that is actually uh allowed to write Okay and uh so so one way of doing that is by indicating exclusive ownership of The Cash Line and let's assume the exclusive ownersh ship is is indicated by having the dirty bits set right so what we need to ensure though is that only one cache in the system can ever have its Dirty Bit set at any time right otherwise we get you know going to violate that uh invariant that says
hey there's only one processor in the read write Epic so we only have one okay so we need a way of enforcing only one right and the way of enforcing only one processor at a time is in the read WR epic is called a cash coherence protocol so it maintains the cash coherent in variance it uh uh assumes that uh there's some Hardware logic that's going to uh look at loads and stores made by the the local processor and messages from other caches on the bus Okay so in an invalidation based right back protocol which
is what we're going to describe uh there's a set of key ideas somebody asked about what other state is in the in the metadata For The Cash Line well you need some cash coherency state right and uh the idea is that you're going to have some cash coherency State and you're going to be able to uh allow only one processor to be in a certain State at any one time and you Need to to be able to tell the other processes to uh to not be in that state okay so let me see I think
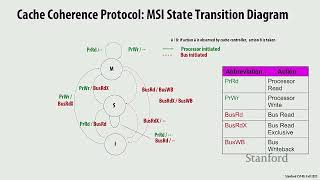
we have time to just introduce the idea all right so we talked about Dirty Bit and we talked about the fact that we need some cash coherency line state let's talk about a protocol cash coherency protocol for a right back invalidate based uh cash right so key toss of the protocol ensuring that one Processor can get exclusive access for a right and locating the most recent copy of a cash line uh you know based on uh the uh cash lines on a cach Miss okay so in the MSI protocol there are three states modified shared
and invalid hence the name and in invalid is the same as you know The Cash Line is is not there shared is this state where multiple processes can only read the line so read only and modify the line is valid it only one Cach or it's in what we've been calling the dirty or exclusive State okay so invalid The Cash Line is not there shared read only modified valid in exactly one cache all right so we have uh two processor operations processor read and processor write free coherence bus transactions right so these come from the
bus so these come from the processor processor read and processor right and then bus read bus read Exclusive bus right back come from the bus and these are caused by actions of other processes so bus read means hey give me a copy of The Cash Line because I want to read it bus read exclusives says give me a copy of The Cash Line because I want to write it so first of all before I can write it I need the whole cash line but I'm going to write it and then bus right back says hey
this is a cash line that was dirty in my cash that I'm riding Back to memory okay so keep this in mind we're going to continue with the story uh on Thursday and talk about how exactly we maintain coherence using uh these three states and these actions