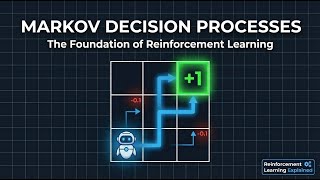
All right, let's dive right in. You're going to see this term pop up a lot. Finite Marov decision processes. I know it sounds incredibly intimidating, right? It's the kind of thing you'd expect to find buried in dense AI papers, graduate level textbooks, or some heavy research discussion. It really sounds like something only PhD students should have to deal with. But here's the thing. It's The mathematical foundation underneath every single major AI breakthrough you've ever heard of. Think about Alph Go or the reinforcement learning that helps power chat GPT or even the logic inside autonomous vehicles.
Deep down, they all rely on this exact same core framework. And here's the great news. We're going to build a rock solid intuition for it. And we're going to do it using nothing more than a simple 2x two grid and some basic math. It's not Magic. It's a system. And we're going to tear that system down to its absolute bare essentials. It all starts right here with this. Look at this little grid on the screen. It's tiny, right? Just four squares. A start, a pit, and a goal. This simple little maze is the key to
everything. By the end of this series, you'll have used this exact grid to build an unshakable intuition for the single most important equation in all of AI, the Bellman equation. But we're not Just going to learn the theory. That's boring. No, you are going to learn to think like an agent. You'll build the intuition to look at a problem and see the future just like an A does. But before our agent can see the future, before it can learn or win or even move, it first needs a universe to exist in a universe with rules.
So, let's build one. Let's define the four fundamental rules of any AI's universe. All right, we have our universe. Look at the screen. It's this tiny 2x two grid. Before an AI can learn to win this game, or any game for that matter, it has to know the rules. And I'm not talking about the rules of chess or go. I'm talking about the fundamental rules of reality itself, the physics of its digital world. And here's the secret. There are only four. Every single reinforcement learning problem, from this tiny little Maze to a self-driving car navigating
a city, is defined by just these four things. This isn't just theory. This is the operating system for intelligence. First up, rule number one, know where you are. We call these states. First, the agent needs to know its situation, its current context. We call this the state. It sounds complicated, but I promise it's not. For our little agent in the maze, the state is just its location. Are you on square A? That's a State. Are you on square B? That's another state. Check it out on the slide. The set of all possible places you can
be is the state space. For us, that's just A, B, C, and D. A state is just a concrete answer to the question, where am I right now? Of course, for a self-driving car, the state is way more complex. It's all the camera feeds, the LAR data, your current speed, the GPS location. It's a huge snapshot of everything it needs to know About the world at one single instant. But the principle is exactly the same. Okay. Rule number two, know what you can do. We call these actions. So, you're in a state. Now, what? You
have to be able to do something. You need a set of possible moves. In our maze, the actions are pretty obvious. You can try to go north, south, east, or west. The set of all possible moves you can make is the action space. This is the answer to the agent's second Big question. What can I do here? For a chess AI, the actions are every legal move for every piece. For a stock trading bot, the actions might be super simple. Buy, sell, or hold. It doesn't matter how complex the world is. The agent always has
a limited menu of options. Now, for the most important one, rule number three, know if it's good or bad. We call this the reward. This is where the learning really comes from. How does An agent know if it did something smart or something stupid? It gets feedback from the universe, a signal. A reward is just a number. A big positive number, that was good. Do more of that. A big negative number, that was bad. Never do that again. So, let's define the rewards for our universe. Look at the slide. Reaching the goal on square D
gives us a reward of + 10. Jackpot. But falling in the pit on square C, that's minus 10. Game over. You lose. But wait, what about the other moves? The ones that just take you from A to B. If those have a reward of zero, the agent has no reason to hurry. It could just wander back and forth forever and be perfectly happy. So, we add a little rule. The universe is impatient. It punishes you for wasting time. For every single move that doesn't end the game, we give a penalty of minus1. This small penalty
encourages the agent To find the goal as fast as possible. It's like a cost of living. Every second that ticks by, you pay a small price. The reward answers that third critical question. Was that good or bad? And finally, rule number four, know what happens next. We call these transitions. You're in a state, you take an action, you get a reward. But then what? The world has to change. You end up in a new state. This rule, the physics of our universe Is called the transition probability. It tells us exactly what happens when we do
something. For our simple maze, the physics are predictable. We call this deterministic. If you're in state A and you take the action to go east, the transition rule says you will end up in state B with 100% certainty. It's basically a lookup table for how the world works. But what if the floor was slippery? What if when you tried to go east from A, there was only a 90% chance You'd make it to B and a 10% chance you'd slip and stay right where you are? That would be a stochastic environment. And the real world
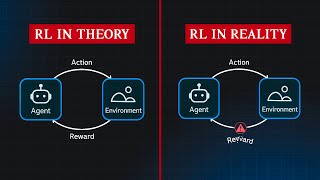
is almost always stochastic. The transition answers that final question. After I move, where do I end up? That's it. Seriously, that's the entire game. Where am I? That's the state. What can I do? Those are the actions. Okay, I'll try this action. And then what happened? The universe gives back a new state and A reward. And then you just repeat this loop. This interaction you see on the screen between the learner, which we call the agent, and its world, the environment. This is the heartbeat of all reinforcement learning. As the agent moves, it leaves a
trail behind it, a story, a sequence of states, actions, and rewards. We call this a trajectory. Let's look at a good trajectory, a winning story. The agent starts in state A. It decides to take the action east. The universe gives it a reward of minus1 and puts it in the new state B. From state B, it takes the action south. The universe responds with a reward of + 10 and it lands in state D. Game over. So, what's the total score for this story? -1 + 10 equals + 9. A solid win. But what about
a bad trajectory? A catastrophic failure. The agent starts in state A again. This time it decides to go south. The universe immediately gives it a reward of minus 10 and drops It into state C, the pit. Game over. The total score, a painful minus 10. The agent's entire goal, its whole purpose for existing is to figure out a strategy, what we call a policy, that generates these stories, these trajectories with the highest possible score. But there's a problem. a huge simplifying assumption we're making here, a cheat code. [Music] To decide the best move from state
B, Does our agent need to remember that it just came from state A? Does it need to remember its entire history, every single move it's ever made, just to make its next decision? If it did, the problem would be completely impossible to solve. But it doesn't. And the reason why is the single most important concept that makes all of this work. It's a hack. It's the memoryless hack that makes AI possible. And that is what we're Breaking down next. Okay, let's face the big problem head on. We have our agent. It's moving through its world,
creating a history, a trajectory. As you see on the screen, it could be something like start at A, go east, get minus one reward, land at B, then go west, get another minus1, and a back at A, then go south, get minus 10, and fall into the pit at C. Now, imagine our agent is back in state A to make its Next move. Does it need to remember all of that? Does it need to remember that it tried to go east, then came back? Does it have to recall every single step it's ever taken in
its entire existence? If the answer is yes, we're screwed. The problem just explodes. The number of possible histories is literally infinite. Trying to learn a rule for every conceivable life story isn't just hard. It's computationally impossible. It's a dead end. So, we cheat. We make an audacious bet. We use a hack so fundamental that it underpins almost all of modern reinforcement learning. We bet that the past doesn't matter. Let me explain with an analogy. Imagine a chess grandmaster deep in a match. The board is this complex battlefield, pieces locked in a delicate dance. to decide
her next move. Does she need to remember the exact sequence of the last 30 moves that led to this specific position? Does she need to recall that the knight moved from G1 to F3 on move five? No, of course not. She just needs to look at the board. The current positions of the pieces, the state contain all the information she needs to play optimally from this point forward. The history of how the pieces got there is completely irrelevant. This is the hack. This is the big idea. The future is independent Of the past given the
present. Think about that for a second. The present state is a sufficient statistic of the future. It screens off the past. >> So, back in our silly little maze, if our agent is on square A, that's all it needs to know. It doesn't matter if it got there by moving from B or by hitting the north wall five times in a row. The state I am at A is all the information required to make the next best move. This simplifying assumption has a name. It's called the Markoff property. And it's not just an idea. It's
a mathematical razor that cuts the problem down from impossibly complex to solvable. Now, here's what it looks like formally. And don't be scared by the symbols you see on the screen. All this equation is saying is that the probability of landing in the next state depends only on your current state and your current action. All of this the entire history of the universe just gets Thrown away. Gone. This one assumption is so powerful so central that any problem that obeys this rule it's a special name. It's the official blueprint for almost every reinforcement learning problem
you will ever see. It's called a Markoff decision process or MDP for short. So when you hear someone in a meeting or a lecture talk about MDPs, don't let the jargon fool you. All they're really saying is, "Hey, we are dealing with a problem where the Markoff Property holds. We're using the memoryless hack." That's it. You're now in on the secret. So, let's do a quick recap of our universe's blueprint. This MDP, we've got a finite set of states like our squares A, B, C, and D. We've got a finite set of actions like north,
south, east, and west. We have the transition probability, which is just the physics of the world. And we have the reward function, the feedback we get. And the golden rule tying it all Together, the markoff property. The past doesn't matter. This is the framework. This is the game board for intelligence. By throwing away the past, we've made the problem tractable. We no longer need to learn a policy for an infinite number of histories. We just need to learn the best action for a finite number of states. This is the key that unlocks everything that comes
next. It's the foundational assumption that lets us build something called the Bellman Equation, which is the master formula for seeing the future. But before we can look into the future, we need to define what we're looking for. The agent's goal is to get the highest score possible. But what does that actually mean? Do we just add up the rewards? -1 + 10 equals + 9. That works for a short game, but what if the game never ends? What if you're a robot balancing a pole or a program managing a power grid and the task goes
on forever? If you get a plus one reward every second, your total score will just keep growing towards infinity and you can't optimize for infinity. So, how do we define winning when the game itself might be endless? That's the next puzzle we have to solve. All right, we've built the universe. We have our states, actions, rewards, and that brilliant memoryless hack, the Marov property, that makes this whole thing possible. The agent's goal seems Obvious, right? Get the highest score. For a short game, what we call an episode, it's easy. Look at our little maze. The
game ends when you hit the goal or the pit. So, you just add up the rewards. A path from A to B to D gives you a score of -1 + 10 which equals + 9. Simple. But we have a problem. A huge logical paradox. What if the game never ends? Think about a robot whose only job is to balance a pole. For every single second It keeps the pole upright, it gets a reward of + one. The reward stream is just plus one plus one plus one forever. If it succeeds for an hour, its
score is 3600. If it succeeds for a day, its score is over 86,000. And if it's a perfect robot and succeeds forever, its total score is infinity. And that's where the logic completely breaks. How can an agent learn if its goal is infinity? If one strategy gives It an infinite score and another slightly better strategy also gives it an infinite score, how does it know which one is better? You can't. You can't compare two different infinities. An infinite score is a useless score. It's a paradox. We need a way for the agent to have a
goal, a concrete number to maximize even when the timeline is endless. And the solution is a clever trick, a beautiful piece of financial logic that you use every single day Without even thinking about it. Let me ask you a question. Would you rather have $100 today or $100 a year from now? The answer is obvious. You want it today. A dollar today is worth more than a dollar tomorrow. Why? Because you can use it. You can invest it. There's certainty. The future is hazy. This isn't just finance. This is the fundamental key to AI foresight.
We are going to apply this exact same idea to our agents rewards. A reward received Now is better than a reward received later. We're going to make future rewards worth less. We will discount them. How? We introduce a new rule for our universe, a new piece of physics. We call it the discount rate. and we represent it with the Greek letter you see here, gamma. Gamma is just a number between zero and one. Think of it as the AI's patience knob. If gamma is zero, the agent is completely myopic. It has zero patience. It only
cares about the immediate reward right in front of its face. The future is worthless. But if gamma is close to one, like 0.99, the agent is extremely far-sighted. It cares deeply about rewards far into the future. It's willing to suffer now for a big payoff later. So, here's how this discounting works. A reward you get one step from now is worth its full value. A reward you get two steps from now, it's only worth gamma times its value. And a Reward ks into the future is only worth gamma to the power of k minus one
* its value. Each step into the future chips away at the reward's value. This brings us to the one number to rule them all. The agent's goal is no longer to maximize the simple sum of rewards. It's to maximize the discounted return. We call this GT. And if you check out the formula, here's what it looks like. The return starting from now is the immediate reward plus the next reward Slightly discounted plus the next one discounted even more and so on forever. It can be written more elegantly with this summation formula here. Now don't let
the symbols scare you. This is the magic trick. Because gamma is less than one, this infinite sum is now guaranteed to be a finite number. It will never explode to infinity. Let's go back to our pole balancing robot. It gets a plus one reward forever. If we set our discount rate gamma to 0.9, its total Discounted score isn't infinity anymore. This infinite series sums up to exactly 10. Suddenly, we've tamed infinity. What was an endless useless number is now a concrete finite score the agent can actually try to maximize. It's elegant. So now we can
formally define the agents one true goal. It is to select actions that maximize its expected discounted return. We say expected just because the world Might be random. The agent can't know the future for sure. So, it plays the odds. It tries to get the best possible average score over all the different ways the future might unfold. This is it. This is the objective function for almost all of modern AI. GT. The agent now has a north star. It knows exactly what winning means. But how does it do it? How does it choose which actions, which
moves will lead to the highest value of GT? It needs a strategy, a Rulebook, a brain. And that's what we're building next. We're giving our AI a brain, the policy. Okay, so we have our north star. Our agent knows its one true purpose in life. Get the biggest possible discounted return. That number GT we just defined. It knows what it wants, but it has absolutely no idea how to get it. Look at our agent here standing on square A. It has four options: north, south, east, west. Which one of these Paths leads to the highest
long-term score? How does it even begin to decide? Right now, our agent is just a puppet. It has a body but no mind. It needs a strategy, a rulebook for action. It needs a brain. And here's the secret. The thing that makes AI so different from us. An AI's brain isn't made of silicon and neurons. It's made of rules. We call this set of rules the policy. The policy, and you'll see it on the slide here, denoted by the Greek letter pi, is basically the soul of the machine. It's the agent's behavior, its character, its
code of conduct. It answers the one question that matters at every single moment. What do I do now? And look, a policy isn't some mystical black box. It's just a plan. You have policies in your own life. If the traffic light is red, I will stop. If my alarm rings, I will hit snooze. Probably three times. An AI's policy is exactly The same. It's just a mapping from a situation to an action, from a state to a move. And here's the fun part. You get to decide its personality. Is your agent a meticulous planner who
never makes a mistake? or is it a chaotic gambler who lives on the edge? Let's give our agent a few different brains and see what happens in our maze. First up, personality number one, the cautious explorer. This agent is a genius. It's calculated every move. It Has a perfect plan and it follows it without deviation. Look at its rule book. If it's in state A, it always goes east 100% of the time. If it's in state B, it always goes south. This is what we call a deterministic policy. There's no randomness, no chance. If you're
in A, you go east. Period. And this policy is perfect. It guarantees the agent reaches the goal safely every single time. But what if the world isn't so predictable? A perfect rigid plan can shatter the Moment something unexpected happens. So, let's try a different brain. Personality number two, the lost tourist. This agent has no idea what it's doing. It is pure chaos. It arrives in a new state and just picks a direction at random. Its policy is super simple. For any state, choose north, south, east, or west with a 25% chance for each. This is
a stochastic policy. It's all based on probabilities. Now, will this agent ever find the goal? Maybe it might stumble From A to B and then from B to D by pure luck, but it's just as likely to stumble from A straight into the pit at C. This policy is terrible, but it's still a policy. It's a valid, though very stupid brain. Most of the time, the best policies lie somewhere in between perfect planning and total chaos. So you can have good policies and you can have bad policies. Smart brains and dumb brains. Formally we write
a policy like you see here. Now don't let the notation Intimidate you. All this says is the policy is the probability of taking action A given that you are in state S. That's it. So for our cautious explorer, the probability of going east from state A was 1.0. For our lost tourist, it was just 0.25. 25. It's just the math version of the agents rule book. And this brings us to the single most important sentence in this entire series. The entire goal of reinforcement Learning, the whole point of everything we are doing can be summed
up right here. To find the optimal policy, PI star that gets the highest possible long-term score. That's it. That's the holy grail. We are on a quest to find the perfect brain. The set of rules that on average produces the best outcomes. But this raises a critical question. We have our cautious explorer policy. We have our lost tourist policy. Intuitively, we know one is brilliant and the other is a disaster. But how does the AI know? How do we measure the score of a policy? How do we look at a brain and say this one
is a 9 out of 10 but this one is a two out of 10? To improve our policy, we first have to evaluate it. We need a way to look at any state in our maze and ask if I follow this policy from here, what's my final score going to be? We need a crystal ball. And that is Exactly what we are building next. The AI's crystal ball value functions. Okay, we've hit a critical point. We have our agent's brain, its policy. It could be a genius like our cautious explorer, or it could be a
complete disaster like the lost tourist. Intuitively, we know one is brilliant and the other is a catastrophe. But how does the AI know? How do we actually measure the quality of a policy? How do we look at the agents brain and assign It a score, a grade? We can't just say, "This feels good." We need numbers. We need proof. So, to improve our policy, we first have to evaluate it. We need a way to look at any square in our maze and ask, "If I follow this set of rules from here on out, what's my
final score going to be?" We need a crystal ball, a way to see the future. And we measure a policy with something called a value function. It's exactly What it sounds like. It's a crystal ball that tells you the future score you can expect to get from any given square. It's like putting a price tag on every position on the board, telling you exactly what it's worth in the long run. Let's forget the math for a second. Let's just use our intuition. Look at the maze here on the screen and let's use that perfect cautious
explorer policy. Remember the rules. From A, always go east. From B, always go south. Now ask yourself a simple question. Following that perfect policy, which square is more valuable to be on, A or B? Of course, it's B. Why? Because from B, you are just one single step away from that plus 10 jackpot. The future looks incredibly bright from square B. Square A is pretty good, too, but it's one step further away. its value is a little lower because you have to pay that minus1 cost of living tax to get to be First. A value
function just puts a number on that intuition. It formalizes that gut feeling. This is the entire game. If an agent can figure out the true value of every state, it can learn to win. [Music] Now, there are two kinds of crystal balls. Our agent needs two types of value functions. and you need to understand the difference between them because it's the key to everything that Comes next. First up, we have the state value function. This one answers a simple question. How good is this square? We call this the state value function. And if you look
at the slide, you'll see we write it as V pis. That little pi symbol is crucial. It means the value of state S. Assuming you follow policy pi, you see the value of a square depends entirely on the brain you're using. Let's look at our two personalities. For the cautious explorer, the value of B or VB is very high. You're guaranteed to get to the goal. And VA is a little bit lower, but still very positive. But what about for the lost tourist policy where we move randomly? Well, VB is now much lower because you
have a chance of going the wrong way back to A, wasting time and money. And VA is probably negative. Why? Because from A, you have a 25% Chance of immediately stepping south and falling straight into that minus 10 pit. The future looks bleak. The state itself didn't change. The policy changed and so the value of the state changed with it. Now, here's the formal definition. Don't worry about reading the formula. In plain English, it just means on average, what will my final score be given that I am starting in the state and sticking to my
rule book forever? This is great. It tells us which parts of the map are valuable territory, but it doesn't quite tell us how to act. To do that, we need a different kind of crystal ball. This brings us to the action value function. This one is more specific. It asks a slightly different question. How good is this move? Not how good the square is in general, but how good is the specific action of going east from this square or south? We call this the action value function And we write it as Q pisa. Most people
just call it the Q value pronounced like the letter Q. Let's go back to state A and pretend we're that stupid lost tourist. Even with a random policy, some moves are clearly better than others. Check out the diagram. The action to go east from A seems pretty good. It takes you to B, which is closer to the goal. So the Q value for A, east should be decent. But the action to go south from A, that's a disaster. It drops you right into the pit. The Q value for A, south should be massively negative. And
what about going north or west from A? You just hit a wall, pay the minus one tax, and end up right back where you started. So those Q values should be slightly negative. See the difference? The state value gives you the average score of just being at A. The action values, the Q values, break it down, giving you the Specific score for each possible choice you can make. And here's its formal definition. Again, don't read the math, just get the idea. It's the expected score you'll get after you take a specific action from a state
and then follow your policy forever after. This is the agent's secret weapon. [Music] If the agent can learn the Q values for every move, Learning becomes simple. To pick the best action in any state, you just look at your list of Q values and you pick the action with the highest number. That's it. That's the path to victory. So, let's recap. We have our two crystal balls. As you can see on the slide, the state value tells you how good is this square. It's like knowing the average home price in a neighborhood. The action value
asks how good is this move. That's like knowing the exact price of the Specific house you want to buy. Much more useful for making a decision. So there's the things. These two functions are the heart of almost every modern reinforcement learning algorithm. The agent's entire learning process is just a loop. One, start with a random brain. Two, figure out the value function for that brain. You evaluate it. Three, use those values to build a slightly smarter brain. You improve it. Four, repeat. But this leaves us with a huge gaping Question. A computational nightmare. Okay, these
value functions exist. These numbers are real, but how in the world do we calculate them? How do you find the exact value of being in state A? Do you have to simulate every possible future from that state for all of eternity and then average the results? That's impossible. It would take an infinite amount of time. There has to be a better way, a shortcut, a Mathematical hack that lets us find the long-term value of a state by just looking one step ahead. And there is. It's the single most important equation in this entire field. a
beautiful recursive idea that connects the present to the future. It's called the Bellman equation and that is the one equation that sees the future. All right, let's get this straight. Our agent has a brain, the policy. And to know if that brain is any good, it needs A crystal ball, the value function. This tells it the true long-term score from every single square on the board. But as we just discussed, this leaves us with a computational nightmare. To find the value of starting at square A, do we really have to simulate every possible future path?
Every random turn the lost tourist might take for all of eternity and then average all those scores. That's impossible. It's a dead end. We need a shortcut. A mathematical cheat code. We need something that lets an AI see into the infinite future by looking only one step ahead. [Music] We have set the stage. We've built the universe and the agent's mind. Now for the secret sauce, the one equation that connects everything. The Bellman equation. Now, this isn't about complex math. It's about one beautifully simple recursive Idea. Forget the maze for a second. Let's think about
your own life. What is the value of your current situation right now? Well, it's whatever good or bad stuff is happening to you immediately plus the discounted value of the situation you'll find yourself in next. That's it. That's the entire insight. The Bellman equation defines the present in terms of the future. It creates a relationship, a rule of self-consistency That links the value of every state to the value of its neighbors. Here's the idea in one sentence. The value of where I am now is the reward I get right now plus the discounted value of
where I'll end up. It's an echo. The value of the future echoes back to inform the value of the present. And by applying this one simple rule everywhere, the true long-term values of every state start to reveal themselves. Okay, let's stop talking philosophy. Let's see it in action. Let's actually calculate the future. Time to get our hands dirty. We're going to build the Bellman equation for our little maze for a single state. State A. Look at the setup on the screen. Our world is the 2x two grid. Our agent's brain is the lost tourist. It's
completely random, picking any direction with a 25% chance. The rules of physics are simple. Plus 10 for the goal, minus 10 for the pit, and a minus1 tax for every other move. And if You land in the pit or the goal, the game's over, so their own value is zero. Finally, our patience knob, the discount factor is set to 0.9. Future rewards are only 90% as valuable. Our mission, find the true value of being in state A, which we call V of A. The Bellman logic says that the value of V of A is simply
the average of the outcomes of the four possible actions our random agent might take. So, let's calculate the value of each of those Four possible outcomes. Remember the rule, it's the immediate reward plus the discounted value of whatever state you land in next. First up, what happens if we go north from A? You hit a wall. So, you stay in state A. The immediate reward for moving is minus1. And the discounted value of your next state is.9 * the value of A. So as you can see on the slide the outcome value is -1 +.9
* v of a. Okay. What about going west from a same thing You hit a wall you stay in a. So the outcome value is exactly the same -1 +.9 * v of a. Now for the interesting one. What happens if we go east from a? Success. You move to state B. The immediate reward is still minus one, but the discounted value of your next state is now.9* V of B. And finally, what if we go south? Disaster. You fall into the pit state C. The immediate reward is a painful minus 10. And since the
game ends, the value of this terminal state is zero. So the future part of the equation is just zero. The total outcome value is simply minus 10. We have the four pieces. Now let's assemble them. We just plug those four outcomes back into our average. And what we get is this equation you see on the screen. This right here is the Bellman equation for V of A under our random policy. It's beautiful. It's elegant and It's completely useless right now. Do you see the problem? Look at the equation. To find the value of VA, we
need to already know the value of VA. And even worse, we also need to know the value of VB. Okay, no problem. Let's just go find VB first. So, we do the exact same calculation for state B. Check it out on the slide. We calculate the outcomes for going north, east, west, and south. And when we put that puzzle together, The trap snaps shut. To calculate VA, we need VB. But to calculate VV, we need VA. Look at the diagram. It's a circular dependency, a paradox. It's a chicken and egg problem written in the language
of mathematics. Each state's value depends on its neighbor and its neighbors value depends right back on it. We have this perfect elegant system of equations that defines the true value of The universe, but we can't solve it. It's a system where every variable is lying about its true value. And we need a way to force them all to tell the truth at the same time. This isn't just a puzzle. It's the central problem we have to overcome. This is the Bellman deadlock. and breaking it is the subject of our next chapter. [Music] All right, we
did it. We derived the single most important equation in Reinforcement learning, the Bellman equation. We found a way to connect the present to the future. We discovered this beautiful recursive relationship that links the value of any state to the values of its neighbors. Now, for our little maze, we ended up with these two perfect equations that you can see on the screen. one for state A and one for state B. But it left us in a paradox, a deadlock. To calculate the value of A, we need the Value of B. And to calculate the value
of B, well, we need the value of A. Look at this diagram. It's a perfect circle, a circular dependency. Each state's value is defined by its neighbors, who are in turn defined by it. It's like a system where every number is pointing to another number with no ground truth to stand on. But wait, if you've taken high school algebra, you know what this is. It's just a system of two linear equations with two unknowns. We can Simplify it down like you see here, and we can just solve it, right? Plug it into a calculator, use
matrix inversion, whatever you want, and we get the answer. The value of a is about -5.57 and the value of b is about -2.14. There, the true values. Problem solved. The crystal ball works. Video over. Right? Wrong. You've just walked into a trap. And this is the lie that academic papers And textbooks don't tell you. They show you these tidy little examples and pretend the solution is clean. It's not. Solving this system directly is a lie. Think about the scale of this. Our little maze has two unknown states, A and B. So, we have two
equations. Simple. Now, let's leave our tour world and step into reality. A game of tic-tac-toe has a few thousand unique states. That means a system of a few Thousand equations. Hard, but maybe doable for a powerful computer. A game of chess has an estimated 10 to the power of 47 states. A game of Go has over 10 the^ of 170 states. That is more possible board positions than there are atoms in the observable universe. Now imagine trying to solve a system of equations with more variables than atoms in the universe. You can't. It's not just
hard. It is physically cosmically fundamentally impossible. The computer Required to even store the equations would be larger than the galaxy. The elegant solution, the one that works so perfectly for our little grid, is a complete and utter dead end for any problem we actually care about. It's a beautiful theory that shatters the second it touches reality. So, we're back at square one. We have the perfect equation that describes the physics of value, but it leads to a calculation that is literally Impossible. So, how does any AI actually do this? How did Alph Go find the
value of a goboard? The answer is simple. They don't solve it. They cheat. They use a back door. A trick that sidesteps the impossible math of solving everything all at once. This cheat has a name. It's the first pillar of modern reinforcement learning. It's an idea called dynamic programming. And here's how it works. Instead of demanding that the entire universe tell you the truth at the same Time, you let it lie. You start with a wild guess. Check out this slide. You just say, "Let's pretend the value of every state is zero." It's a total
lie, but it's a starting point. Then you go to just one state. Let's say state A, and you apply the Bellman equation. But you use the lies your neighbors are telling you, their current value of zero. You update its value. It's still a lie, but it's a slightly better lie. It has absorbed one tiny echo of the truth From its neighbors. Then you move to the next state and the next. One by one, you sweep through the entire system, nudging each value, updating each state's little lie to be a slightly more accurate one based on
the current lies of its neighbors. You don't solve the system, you relax it. You inch your way towards the truth one tiny iterative step at a time. This process of starting with a guess and slowly forcing the values to agree with each other until they Converge on the one true answer. That is our first real AI algorithm. It's the key that breaks the Bellman deadlock. It's called iterative policy evaluation and that is what we are building step by step in the very next chapter. All right, we hit a wall. A computational brick wall. The Bellman
equation gave us this perfect elegant system for defining the true value of our universe. But as we saw, trying to solve it directly for any real problem Is well, it's impossible. It's a beautiful theory that shatters on contact with reality. So, how does any AI actually do it? How does it figure out the value of a chessboard or a go board? The answer is simple. They don't solve it. They cheat. They start with a complete lie and then they slowly, patiently nudge that lie closer and closer to the truth. This isn't just some trick. This
is it. Your first practical realworld reinforcement Learning algorithm. It's called iterative policy evaluation. Let's break the deadlock. So, here's the plan. It's so simple it feels like it shouldn't work. We're going to take our Bellman equation and we're going to rebrand it. Look at the slide here. It is no longer an equation that we have to solve all at once. It is now an update rule, a dynamic process. We use the old values on the right side to calculate a new better value on the Left. The method is dead simple. First, we start with a
complete lie. We'll just initialize the value of every single state to zero. It's totally wrong, of course, but it's a starting point. Second, we sweep and update. We'll go through every state one by one and apply that Bellman update rule using the old values of its neighbors to calculate a new value for the current state. And third, we just repeat. We just keep sweeping through all the states over and Over and over again. With each sweep, the values will get a little less wrong. Each update, a tiny echo of the truth from the real rewards
will ripple through the system. Let's watch it happen. Let's force the lies to become the truth. Okay, here are our update rules from the last chapter. You can see them on the slide. These are the specific formulas for our little two-state universe. Now, for the initialization, the big lie. As You can see in the table, we just start by assuming everything is worthless. The value of A is zero. The value of B is zero. These are our initial guesses, our VDEV. Now, let's do our first sweep. We plug our starting values, all zeros, into the
right side of our update rules to get our new values. So for the new value of a, we plug in zeros for the old A and B. And the math works out to minus 3.25. And for the new value of B, we do the same, and it comes out to plus 1.75. Look at that. Check out the updated table. After just one pass, the numbers have already started to make sense. Our crystal ball is no longer blank. The value of a is negative because it has that 25% chance of falling into the pit. The value
of b is positive because it has a chance of hitting the jackpot. The logic of our universe is starting to emerge from the math. Now these values are still wrong but they are less wrong. So what do we do? We do it again. Time for the second sweep. This time our VU up six values are the ones we just calculated. So we plug minus3.25 in for A and 1.75 in for B. Let's calculate the new value of A. We run the numbers and get -4.32 and the new value of B. We run those numbers and
get plus 1.81. Let's update our table again. Do you see what's happening here? The values are still changing, sure, but they changed less this time. The first update for A was over three points. The second was only about one point. The updates are getting smaller. The numbers are starting to settle down. They are converging. And that's the punchline. If we kept doing this for 10 sweeps, 100 sweeps, a thousand sweeps, the updates would get smaller and smaller until eventually the Numbers would barely change at all. They would converge to the one true solution that satisfies
the Bellman equation. As you can see on the slide, the true values are about -5.53 for state A and about plus 0.92 for state B. This is the magic. We never had to solve that impossible system of equations. We just treated it as an update rule and let the values relax until they found the truth on their own. Think about what we're really doing. We are literally Sweeping our knowledge of the rewards across the grid. The immediate plus 10 and minus 10 rewards are the ground truth. And on every sweep, their influence propagates one step
further out like ripples in a pond until the entire value landscape is stable and correct. And here's the most important part. This process is guaranteed to work for any finite problem like this. Iterative policy evaluation will always converge to the true value function for Whatever policy you're testing. We broke the deadlock. We have our crystal ball. We can now take any policy, any AI brain, and with this algorithm, we can find out exactly what it's worth. We can calculate its value function. But this brings us to the big so what? We just went through all
this work to find the exact value of our stupid random lost tourist policy. We now know with mathematical certainty just how bad it is. Okay, great. Knowing your strategy Is terrible isn't enough. How do you use that knowledge to actually build a better one? How do you go from knowing to doing? That's the next step. It's time for policy improvement. All right, we did it. We broke the bell and deadlock using our first real AI algorithm iterative policy evaluation. We forced the lies to become the truth. We started with a guess and after sweeping through
the maze again and Again, we found the true value of our stupid lost tourist policy. We now know with mathematical certainty that for a random agent, well, you can see the numbers on the slide. The value of starting at A is about -5 1/2. And the value of starting at B is almost + one. We have the crystal ball. We have the answer. We know exactly how bad our agent's brain is. So what? Seriously, what's the point? Knowing Your strategy is a disaster doesn't automatically make it better. All we've done is prove our agent is
an idiot. How do we use this knowledge? How do we take these numbers, this crystal ball, and actually forge a smarter brain? How do we go from knowing to doing? The answer is almost insultingly simple. we get greedy. That's it. That's the entire strategy. Think about it. We have this perfect map of value. This VS function tells us the Long-term score we can expect from any square on the board if we follow our current dumb policy. But what if we just ignored our policy for one second? What if standing on square A, instead of picking
a random direction, we used our new value map to look just one step ahead. What if we ask a simple question for each of our four possible moves? If I make this one move and then things go on as they were, what's my immediate score? Let's do it. Let's stand at state A and be greedy. The value of any one move is still what you see here. the reward for that move plus the discounted value of where you land. And our crystal ball gives us those values. So, let's calculate the score for each action from
state A. First, what if we try going north? Well, we hit a wall and land back on A. So, the score is a minus1 reward plus our discounted value of A. Let's see. minus1 + 0.9 * -5.53 Gives us about -5.98. Not great. Going west is the same story. You hit a wall. So the score is also -5.98. Okay. What about south? That's a disaster. We fall in the pit. That's an immediate minus 10 reward. And since it's a terminal state, that's it. The score is just -10. Ouch. Finally, what if we try going east?
We move to state B. So that's a minus1 reward plus the discounted value of B. Let's run the numbers. -1 + 0.9 * 0.92. That comes out to just0.17. Now let's look at the results in this table. The choice is obvious, isn't it? Even though our old policy told us to pick randomly, our new value function is screaming at us. It's saying, "Whatever you do, go east." It's the only move that isn't a total disaster. So, we create a new rule for our new smarter brain. New rule for state A. Always go east. That's policy
Improvement. We just did it. We took a dumb rule and by acting greedily with respect to its value function, we found a better one. Let's do the same thing for state B. Okay, standing at B, if we go north or east, we hit a wall and land back on B. The score for that is about0.17. If we go west, we move to A. That's a minus one reward plus the discounted value of A, which gives us a score of about -5.98. Definitely don't want to do that. But what if we go south? We move to
the goal state D. That's a + 10 reward right away. The score is a beautiful, clean plus 10. Looking at the table for B, the choice is crystal clear. Go south. So, we make our new rule for state B. Always go south. Look at what we've built. Our new policy, let's call it pi, is no longer random. It's deterministic. It's smart. From A, it goes east. From B, it goes South. Wait a second. This is the cautious explorer policy. We started with a brain that was pure chaos. And by following this simple two-step process, we
have transformed it into a brain that is nearly perfect. First, we did policy evaluation to figure out how much our current brain is worth. Then, we did policy improvement by acting greedily based on those values to create a new better brain. And here's the magic. Here is the punchline that makes this entire System work. This isn't a lucky guess. It isn't a coincidence that our policy got better. It's a mathematical law. It's called the policy improvement theorem. And it makes one simple earthshattering promise. Check this out. Any policy that is greedy with respect to the
value function of another policy must be better than or equal to that original policy. Read that again. This new greedy policy Is guaranteed to be an improvement. It's impossible for it to be worse. We have found a one-way ratchet. a guaranteed path uphill. We have a process that only leads to progress and that changes everything because we don't have to stop here. We have one piece of the puzzle, a way to evaluate any policy. And now we have the second, a way to improve it. So what happens when you put them together? What happens when
you create a loop? Evaluation. Improvement. Evaluation. Improvement over and over again. You get a ladder. A ladder that lets your agent climb step by step out of the darkness of random chaos and towards the light of perfect strategy. You get the two paths to god mode. We have the crystal ball. We have the hammer. We've built a ladder that lets an AI climb right out of chaos and into a state of perfection. So, we're done, right? We have the keys to the kingdom. We can solve any problem Now. Not even close. What you've just been
shown is the perfect idealized theory. The kind of thing you find in chapter 3 of a textbook right before all the asterisks and exceptions start showing up. Because these beautiful perfect algorithms, they have some fine print. They come with two catches. two impossibly demanding requirements that hold true for our tiny little 2x two grid, but they completely Shatter the moment you try to use them on any problem that actually matters in the real world. It's time to read the fine print. It's time to understand why everything we've built so far is still just a toy.
First up, catch number one. You need the universe's source code. This first catch, it's probably the biggest lie of all. Both of the methods we just learned, policy iteration and value iteration, they belong to a family of methods called dynamic programming. And this entire family has one non-negotiable requirement. To use them, you must have a perfect model of the environment. What does that even mean? It means you have to know all the rules of the universe in advance. You need the complete instruction manual for reality. You need to know the exact probability of every possible
outcome for every possible action from every possible state. You see this formula here on the screen? That's what it represents. You need to know with godlike certainty that if you're in state A and you decide to go east, you will land in state B with a 100% chance and get a reward of minus1. Just think about how insane this is. This is like trying to play a video game, but before you're even allowed to press start, the game demands that you handed a perfect detailed map of every level, every enemy's attack pattern, and The exact
contents of every single treasure chest. It's impossible for our little maze. Sure, we could do that. We invented the rules. We were the gods of that tiny universe. For the real world, a robot learning to walk doesn't know the exact physics of fiction on some new carpet it's never seen before. A self-driving car has no idea what the exact probability is that the person in front of it is about to slam on their brakes. And a stock trading bot, it Definitely doesn't have a perfect model of the stock market. I mean, if it did, we'd
all be retired on a beach somewhere. Demanding a perfect model is like demanding the universe hands you its source code. It's just impossible for any problem we actually care about solving. We just don't have the instruction manual. But all right, let's pretend for a second. Let's say some oracle came down From the heavens and gave us the perfect model for a complex game. Even then, we're still not out of the woods because that's when we hit the second catch. the one that breaks computers. Catch number two, the curse of dimensionality. Let's look back at our
algorithms. What did they have in common? They both required us to sweep through every single state in the environment and apply an update. For our maze, that was Easy. We had two states that mattered, A and B. A sweep was trivial. Took no time at all. But now, let's scale up. Think about tic-tac-toe. It has a few thousand unique board positions. A modern computer can handle that. It's manageable. Now, let's look at chess. It has an estimated 10 to the 47th power possible board positions. And then there's the game of go. It has over 10^
the 170th power possible board positions. Let me try to put that number In perspective for you. 10 to the 170th That is more possible states on a goboard than there are atoms in the known universe. Now imagine trying to run value iteration on that. Imagine a computer trying to do just one single sweep through every one of those states. Even if that computer was the size of a galaxy and it could update a trillion states every nancond, it would not complete a single sweep before the heat Death of the universe. It's not just hard. It
is physically cosmically impossible. This is what we call the curse of dimensionality. As you add more pieces to the puzzle, more squares on the board, more variables that define the situation, the total number of states just grows exponentially. It explodes into numbers so vast they lose all physical meaning. And our perfect algorithms, which rely on visiting every single one of them, are rendered Completely and utterly useless. So, let's face the sobering truth. Let's put it all together. The algorithms we've just spent all this time mastering. One, they require a perfect map of a universe that
you can't possibly have. And two, they require a sweep through a number of states that you can't possibly count. This is why they are toy algorithms. They provide the theoretical bedrock for everything that comes next. But on their own, they Only work in a fantasy land, a land of tiny, fully known worlds. And this leaves us with a giant gaping question, a paradox. If these methods are so fundamentally useless in the real world, then how did they do it? How did Deep Mind build Alph Go? They didn't have the universe's source code for the game
of Go. And they sure as hell didn't iterate through 10 to the 170th states. They did something else. They used methods that don't need a map. Methods that can learn From pure experience, from trial and error. They left the world of dynamic programming and they entered the world of reinforcement learning. This right here, this is where our real journey begins. The limitations we just discovered aren't a failure. They are a signpost. They are the entire reason the rest of this field even exists. They point the way forward into the unknown. So before we take that
leap, let's take one last look back. Let's assemble the Big picture and prepare for your next mission. So let's be honest, that last section was a gut punch. We spent all this time mastering these beautiful, perfect algorithms only to discover they're built on a lie. They require a perfect map of a universe we can't possibly have. And they demand we visit more states than there are atoms in existence. It really feels like we've built this flawless race car that only works on a Tiny imaginary track. Now, this is the point where most people get discouraged.
They see the perfect theory. They see the impossible reality. And they quit. But this isn't a dead end. This is the key. The limitations we just discovered, they aren't a failure. They are a signpost. They are the very reason the most exciting parts of AI even exist. And everything we've learned so far, policy evaluation, policy improvement, they Aren't separate ideas. They are two halves of a single beautiful underlying engine. Let's zoom out for a second. Forget the specific algorithms. What have we really been doing this whole time? We've been running a process with two competing
yet cooperating forces. First, there's the evaluation force. This force looks at our AI's brain, the policy, and it tries to make our crystal ball, the value function, tell the truth about it. It Pulls the values to accurately reflect the current strategy. Then there's the improvement force. This force looks at that crystal ball and tries to make the brain smarter based on what it sees. It pulls the policy to be greedy, to take the best actions according to those values. These two forces are locked in an endless dance. Making the policy better makes the value function
a lie. But making the value function true reveals That the policy could be even better. So, let's take a second to appreciate how far you've come. You started with a simple 2x two grid, a toy. But on that simple grid, you have built an unshakable intuition for the most foundational concepts in all of AI. You've learned the formal language for any AI's universe, the Marov decision process. You've mastered the single most important equation for seeing the future, the Bellman equation. And you Now understand the core engine of all this learning, the dance of generalized policy
iteration. You haven't just memorized algorithms. You have learned to think like an agent. You understand the foundational logic that powers an AI as it evaluates its world and seeks to improve itself. This is the bedrock. But as we discovered, this entire bedrock rests on one fragile assumption. having the map. Which brings us to your next mission. Policy iteration and value iteration are like having a perfect GPS that can instantly calculate the best route from anywhere. But it only works if you've already uploaded a perfect complete map of the entire planet. In the real world, you
don't get the map. You get dropped into a city you've never seen before with no GPS. And you have to figure out how to get to the tallest building on the horizon. How do you do it? You Explore. You try a street. You see if it gets you closer. You hit a dead end. You turn back. You learn from pure messy trial and error experience. And that is your next mission. In the next video, we throw the map away. We are leaving the clean, predictable world of dynamic programming and entering the chaotic, exciting world of
model free reinforcement learning. You are going to learn how an AI can explore a world it has never seen before and learn the Optimal strategy through nothing but its own experience. We're going to build the algorithms that powered the first true breakthroughs in modern AI. We're going to learn about Monte Carlo methods, temporal difference learning, and the legendary algorithm that started a revolution, Q-learning. This is where the real journey begins. Click here to learn how to win the game without ever reading the rule book.









![How AI Taught Itself to See [DINOv3]](https://img.youtube.com/vi/oGTasd3cliM/mqdefault.jpg)


