welcome everybody i'm paul fletcher from the department of psychiatry and i'm i'm really pleased to introduce michael frank it's fantastic to have someone uh like michael frank speaking to us and he's currently the edgar el master professor in the department of uh cognitive linguistic and psychological science at brown university and his original phd in colorado was in psychology and neuroscience and in the interim he's also held a professorship in arizona for me michael is really a translational scientist for excellence his basic interests are in both computational and experimental approaches to reinforcement learning and decision making
and he's really applied these in incredibly innovative ways uh and neurobiologically informed ways to neuropsychiatric illnesses and has offered important findings that are truly translational and he's rightly won a number of prestigious awards for his work and today his topic is striatal dopamine computations in learning about agencies so michael over to youth well thank you so much paul and valerie and thanks for inviting me i look forward to getting some feedback and talking to you guys um okay so i'm going to start off right away with the idea that has held some prominence for a
few decades about how uh dopamine might be involved in some form of reward or rather reward prediction error and so i'm sure many of you are familiar with this given many of the early findings from wolfram schultz's labs and others where if you have in this case a monkey and you pair a stimulus like a lighter tone that then is followed by a reward a couple of seconds later if that reward is not expected you see an increase in the firing of midbrain dopamine neurons um and initially people might think okay that's consistent with dopamine
encoding some kind of reward value but then if the monkey is trained for a while in a pavlovian association such that they know that this stimulus actually predicts the reward after that training then you see that dopamine no longer cares about the reward itself when it's delivered even though the monkey is perfectly happy to get the reward and enjoys it but you see there that dopamine does show an increase in activity to the stimulus which previously was perfectly neutral but which predicts future reward and then if you play a trick on the monkey and you
give the stimulus but you then withhold the reward then you tend to see a drop in dopamine levels and so that kind of finding which has been supported in many other experiments that have manipulated all sorts of things to test the general idea and also across species has been taken to be in support of evidence that rather than coding for something like reward or directly movement or something this dopamine signal is coding for our an error in the prediction of reward so here the reward is unexpected and here it's expected so there's no prediction error
but the stimulus which was itself previously unexpected is now suddenly a prediction of future reward so there's an error in how much uh the animal expects reward as soon as the stimulus arrives and here that's even more evident because the animal didn't expect reward now it does and now it's expecting reward for a while it's expecting it to occur at a particular time and then when it doesn't occur there's a sort of disappointment and that's reflected in a negative reward prediction error signal um and one of the things that i and other people have been
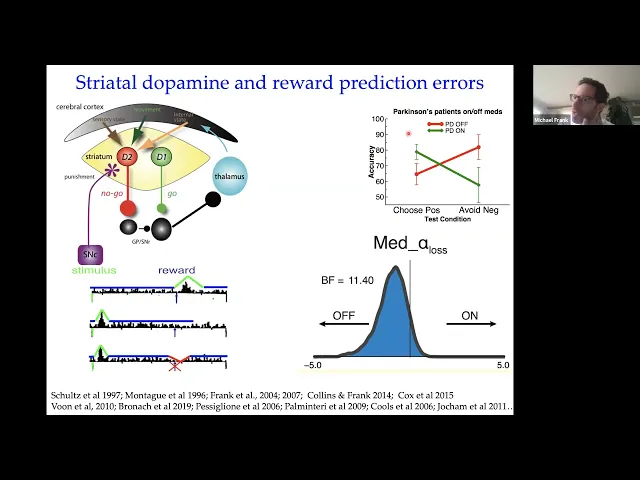
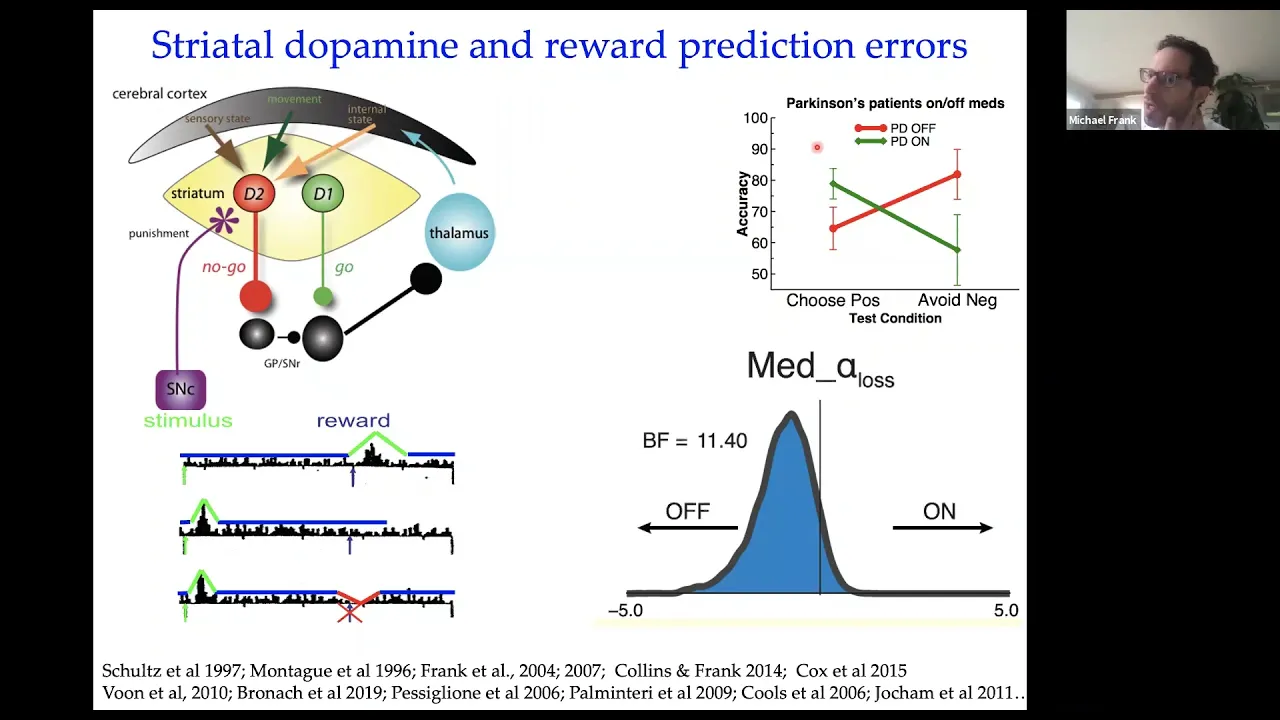
interested in is given that there are these reward prediction error signals that come from the midbrain how could that impact activity and learning and behavior in the downstream uh circuitry that responds to dopamine in the striatum so the striatum is the area of the brain that receives the most amounts of dopamine and its dopamine function in that region is very well studied and i'm not going to go into any detail on this here but the general idea is that there are these different pathways that go through the basal ganglia that have different receptors for dopamine
and that the impact of dopamine increases like reward prediction errors is different in these two pathways so one pathway is involved in sort of go activity or facilitating actions that are related to motivational value and another pathway is involved in uh suppressing those actions that are unwanted or produce negative rewards and so the general idea here was that these reward prediction errors can be married with this sort of circuit level model of the frontal striatal circuit that says when you get reward prediction errors you sort of potentiate neurons in the go pathway and you de-potentiate
neurons in the nogo pathway whereas when you get negative prediction errors it's the opposite and that essentially is an opponent model that says that you know dopamine can go up and down but it induces learning in opposite directions in these two different pathways and we think that there's some reason the brain might have come to that solution but we're also particularly interested in how that might relate to findings in behavior in this case in clinical populations so some of my very early phd work on this was looking at patients with parkinson's disease who have low
levels of dopamine they have depletions of the neurons that make dopamine in the midbrain and we gave them a task that requires them to to undergo reinforcement learning so they had to learn uh to choose certain stimuli on computers that lead to high probability of positive you know winning points or winning money whatever and then other stimuli had a high probability of losing points and what we found there is that parkinson's patients who have low dopamine and are off their medication are uh are actually just fine at learning to avoid those actions that led to
lots of negative reward prediction errors um and and that according to this sort of theoretical framework here depends on having low levels of dopamine to learn from whereas they're impaired at learning to choose those actions that lead to high levels of positive reward prediction errors and then you can ask is that really related to dopamine by just increasing their dopamine levels with their regular dopamine medications uh and then you see that those patients that used to be worse at learning from positive prediction errors are now better there but they actually are worse at learning from
negative prediction errors and that was consistent with a model that we built at this circuit because normally your brain wants these dopamine levels to go down when you get negative prediction errors but the medications continually stimulate these d2 receptors that prevent those neurons from learning from negative prediction error so that was the the general idea and just just to say that that was our original finding but that basic finding has been replicated now in more than 15 different studies in our lab and many other labs with these kinds of tasks and other tasks including some
that valerie voon did a while ago about 10 years ago this is a particular another study recently from another group showing how the effects of medication in parkinson's disease is effectively to change a parameter from a reinforcement learning model that symbolizes how much people learn from losses or negative prediction errors as opposed to positive prediction errors and showing that the medication effect is to essentially reduce learning from negative prediction errors similar to this effect here and they also showed in imaging that that was manifest by changes in the striatal response to negative prediction errors in
ways that are consistent with uh this general model and we think that that even though it's a somewhat contrived uh lab test to assess this function we think that it has some clinical relevance because we know that parkinson's parkinson's patients at least a subset of them when they're on medication can develop some uh impulsivity disorders like pathological gambling and other things something that valerie has studied a lot and you can imagine that while this might not be the only mechanism that is related to this if you have a bias in your brain to learn more
from positive the negative prediction errors then for example playing blackjack which has a 48 chance of winning now your brain interprets it as if it has a 60 chance of winning or something like that uh and on the flip side of that uh the off medication state where there's this other bias in the opposite direction um should be associated with a bias to learn to avoid those actions that lead to negative outcomes but if your brain is constantly telling you that there are negative prediction errors then you might be biased to learn to avoid selecting
actions even when they actually are good actions and we have some work in rodent models that would that uh something like that is actually happening that supports the progression of parkinson-like symptoms in animals even if you don't further exhibit any more dopamine depletion this sort of aberrant learning process can itself lead to progression of symptoms and similarly we think that antipsychotics and schizophrenia can lead to something like that in the sort of motor symptoms of schizophrenia and this is just to show that this cartoon diagram that of the basal ganglia is supplanted by another cartoon
diagram that we use to simulate this circuit in more detail with neural network models that i'm not going to go into any detail but i just wanted to mention that we try to use these sort of uh relatively detailed circuit level models to ask questions about how can you account for the basal ganglia dopamine circuitry and how differences in activity in these different populations might relate to differences in learning and behavior and that kind of model predicts this kind of pattern of data and and other things um but i want to move beyond that um
and before i go to the sort of the main topic of the talk i want to also emphasize that everything i just emphasized was on the learning side that you have these prediction errors that go up and down but it's also well studied for a long time that dopamine also directly affects performance or motivation and we think it does so via very similar similar mechanisms by modulating uh essentially the degree to which these striatal d1 and d2 receptors represent the costs and the benefits of actions and so in this paper in a collaboration with roshan
cools and postdoc andrew westbrook last year he studied how people engage in decisions uh as to whether to perform difficult cognitive tasks or not and andrew has this procedure where he asks you know would you rather do a difficult working memory task in this case it's the n-back task that is hard or an easy one and generally people like to do the easier one over the hard one it's really not fun to do a task that'd be really challenging and so you can but you can get them to prefer the hard task if you give
them enough money to do so so you can pay them in this case you know four euros versus zero or uh and then he'll give people you know different choice options for different amounts of money and then you can construct uh sort of an indifference curve of how much money somebody is willing to uh it needs to get in order to do a harder task and so what i'm showing on the right here is predictions from this model it's a sort of a more simplified version of that complex neural network model that i mentioned where
if you plot on this graph here the the dotted vertical line here is the indifference point so that would be like if you're not sure whether you should choose the easy task or the hard task there's a benefit which is how much more money would you get for doing the hard hard task and then there's the cost which is how hard it is how subjectively effortful it feels and so as you go to sorry we're missing the label here but you'll see that in a minute and the point is that as you go to the
the right of this indifference point the model predicts that you know the benefits outweigh the costs and so you should predict you should increasingly choose the hard task and as you go to the left you should increasingly choose the easy task but the more interesting prediction is that as you simulate increases in dopamine in this model which is reflected by this ratio here it predicts that the steepness of this curve goes up and up so that with more dopamine you're more likely to wait the heart the value the reward benefit of performing the hard task
and you should say okay i'm going to just choose that hard task more consistently whereas if you have lower levels of dopamine you still go up but not as strong a rate and then because this model has this opponency where there's like the benefits and the costs on opposite sides of these indifference points it predicts an asymmetry in that choice function so that the more likely you are if you have high levels of dopamine you actually don't represent that cost as strongly and so this is a shallower choice function whereas low levels of dopamine allow
you to actually discount that costs a lot so this sort of asymmetry in the slope is what is a core prediction of this dopamine model if you apply it to making decisions or and and these decisions in this case happen to be about cognitive actions but the same thing would apply for motor actions and physical effort and so forth and what andrew saw was that there's evidence from in this case uh pet if you look at dopamine levels in the striatum and the caudate people with the highest levels of dopamine exhibited the steepest choice functions
to the right of the indifference curve and the shallowest functions to the left of the indifference curve and then if you gave people a dose of methylphenidate or ritalin which has several effects but one of them is to increase striatal dopamine then you could see that its effect is equivalent to what you would predict from increasing dopamine levels in this model where people are more willing to exert more effort for the harder task as the benefit goes up and they also show shallower functions relative to placebo as you go to the left and so my
point here is just to say that um that you can use this model to account for asymmetries and cost benefit decision making and in this case applied to cognitive effort and we also think that that's potentially interesting because as you all know a lot of people take these smart drugs like methylphenidate and adderall and others uh to improve their cognitive performance and this study suggests that while it might improve performance in some cases it might be actually increasing people's willingness to engage in cognitive effort rather than their ability okay so that was a very brief
tour of a lot of uh a big literature really actually on reward prediction errors on learning and performance but the most the the biggest part of this talk i want to talk about going beyond sort of the notion that dopamine just does one thing all over the striatum or all over the brain and so we know actually now over the last couple decades that there are diverse dopamine dynamics in different target regions uh and sometimes dopamine signals when you record from them in that concentration levels don't show just transients like reward prediction errors but they
show things like ramping we know from josh burke's lab that dopamine in target regions like the striatum can sometimes even be decoupled from spiking at the midbrain cell body which suggests there might be some local regulation of dopamine at the level of the striatum uh and this third point is one that i essentially just motivated on the last slide that there's a role for dopamine directly in movement and motivation separate from learning um but from the computational level um this notion that there are reward prediction errors has been incredibly useful for understanding all sorts of
things about dopamine and behavior but if you take it at face value that there's that's all it's doing it's an impoverished signal if you want to learn in the brain how to assign credit to which circuits in your brain actually generated rewards so the idea is when you're making a decision uh let's say to get a cup of coffee and drink it and it's delicious you get a reward prediction error but should you reinforce the decision to get the coffee or should you reinforce for example the low-level motor program and the awkward uh reaching movement
that you might have taken to get it and the problem is while most models including our own uh models of dopamine and the basal ganglia suggest that the way you you sort of credit the striatal neurons that cause the um the reward is to simply uh combine dopamine levels with activity so neurons that are active are the ones that that learn but in the real situations lots of neurons are active at the same time and they may not all be contributing to behavior and you have many different corticostrial circuits for let's say reaching or higher
level decisions how do you know how does the brain know to reinforce the right ones that are like the most efficient ones to then be more likely to get rewarded in the future and i'm particularly because we're going to be studying this in a rodent model we're going to use a simplified design that will ask are is the thing that you should credit the agent's actions themselves so it's not it's not this coffee example but just whether the agent the pro or the animal the person is in control of the rewards or not and i'll
try to make that more clear in a minute to motivate that i just want to use a an example that i like because i like snow sports and so here you have these two kids going down the hill sledding and they're having lots of fun and they might be getting all sorts of reward prediction errors but they're not actually causally responsible for that other than their decision to get in the in the sled in the first place but here is a mogul skier who is going down the hill and in order to experience positive reward
prediction errors they have to tightly coordinate their action planning with particular states of the environment that then lead to the reward prediction errors and they are responsible in their choices for uh for you know good outcomes uh and if you don't like that example another example would be uh guitar playing so some people really love to listen to people playing guitar um and you might exhib uh experience a lot of reward prediction errors um but that doesn't necessarily mean that you know which actions to play yourself if you're to be given a guitar um and
so to illustrate the sort of problem uh at the circuit level here we have these um this is a cartoon of one of our hierarchical neural network models of corticosteroidal circuits i'm not going to go into much detail except to say that you know there's a lower level motor circuit here that is just about selecting low level motor motor plans and then there are higher level circuits that are in interacting between the prefrontal cortex and the basal ganglia that are involved in selecting higher level goals rules task sets in this case and this might be
like the decision to get a coffee and this might be your reaching action and the problem is that dopamine from the midbrain innervates all of these levels of the cortical striatal circuitry simultaneously and so if you made a decision that was uh that led to reward you you might actually reinforce the wrong circuit and you might lead to the conclusion that just because you experienced reward here that you'll know what to do here and if you did that it would lead to these sort of disastrous consequences if you have never skied or don't know uh
what to do here um and so a solution to that if you're building it into a computational model that has to solve problems not mobile skiing problems but you know related uh complex learning problems is you can do something like this you can say well i have some mechanism in the brain that detects whether this uh this part of the striatum changed the cortical state or changed the change the world in some way that therefore might be related to um might have caused the the reward and that if that happens if you have a way
of detecting that you can use that to amplify the dopamine signal that then goes back to that circuit and less so to the other one so that's the general idea here is that if you have some mechanism of detecting which of your circuits was uh affecting behavior you can use that to amplify the dopamine signal there and if you do that in computational models it helps it learn in a much more efficient way and we had some there there are some biophysical reasons to suspect that that might work um but i'm going to try to
that mostly it was coming from computational considerations and so we want to study that um and so the overview of this here is that we think there should be these sort of what we call actor weighted dopamine signals so dopamine signals that are weighted by the which of your underlying circuits or actors were responsible uh and i'll tell you about how we think that that in the rodent model actually is related to not exactly what i just said on the last slide it's not just that you're increasing dopamine to one circuit or another but it's
mediated by differences in the spatial temporal dynamics of that dopamine system which provides information about agency whether an animal is responsible for the outcomes or not and i'll try to tell you that this is manifest by regionally specific dopamine trans transients that are essentially like reward prediction errors uh related to agency um and then the the beef or the main part of the talk shows that um there are these waves of dopamine that propagate across the mediolateral axis of the dorsal striatum in a way that we think is particularly adapted to implement this sort of
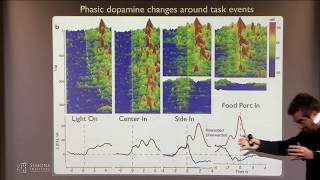
credit assignment to one circuit versus another and i'll give you a high level overview of a model that tries to tie together uh these different doping dynamics okay so all this work that i'm going to talk about from here on in was done by a really talented postdoc arif hamid who's now going to be an assistant professor in minnesota and what he's doing here is looking in mice and he's going to be imaging uh the axons of dopamine terminals in the striatum over the dorsal striatum and he's putting in a cannula so that he could
image about uh 80 of the dorsal striatum at one time so instead of imaging just a single dopamine neuron or a single level of dopamine in the striatum he's going to be able to image the activity of many axons at the same time and he's going to be doing that with g camp which allows you to look at the terminal activity of those axons uh but also d-light which is a way of measuring the concentration of dopamine release directly and so you'll be looking at plots that look like this with a top-down field of view
where uh medial striatum is to the left laterals to the right and anterior posterior that way okay so of course we didn't have mice doing mogul skiing so that i'll have to go over the task of what arief actually did he had the animals on a wheel while they're being imaged and then they experience these tones these auditory tone transitions that escalate in frequency as the animal approaches a reward which is going to be water in this case uh and in some of the experiments he also had these visual stimuli that sort of went along
with the tones so that they get some information about their progress to reward um but the trick is that there are sort of two different task designs here which have sort of hierarchical structure so in one task it's instrumental so that in order for the animal to get make these tones move in their frequency and and then to get the reward the animal has to run a certain amount for each tone transition so sometimes they have to run just a little bit and sometimes it's far the distance that they have to run to get the
reward is sampled from a uniform distribution so the animal never really knows at the beginning of the trial how much it has to run but as is experiences these tone transitions it could sort of infer okay i'm in a test that is allowing the tones to go really rapidly and i'm going to get rewards soon or they have to run a lot but then in other sessions or sometimes within the same session the task is has exactly the same structure but the rewards are unrelated to the animal's behavior so we call it pavlovian where we
sample it again from the uniform distribution but it's not about how much the animal has to run it's just how long they have to wait between each tone transition so here the animal is in control of the outcomes kind of like the mogul skier and here they're not kind of like the sledder and we have evidence behaviorally that the mice actually do use these tones transitions that they see or hear to give them evidence about how far they are to the reward and the way that we can see that is if you measure their lick
rate they start licking because they're anticipating the reward and they lick more and more and more as they get closer to the reward and they do so in a way that is informed by the tone or like how far they are in terms of the percentage towards achieving the reward and not just the raw amount of time or distance that they've run okay so that was all to set up this question of uh is there special dopamine signals that go to different parts of the striatum that allow it to reinforce certain things and so we're
going to focus on the division in the striatum and the rodent between the medial and the lateral striatum and the dorsal medial striatum is traditionally associated with goal directed uh behavior or representing action outcome contingencies which is one way of thinking about agency so if your actions are responsible for outcomes then you're agenda you're controlling the world and so uh we can ask the question is if the animal is in this instrumental task do they figure out that they actually are responsible for these tone transitions despite all the uncertainty about the uniform distributions and so
forth and if so then perhaps you should reinforce that area of the striatum that is responsible for representing these action of contingencies and using that to motivate behavior whereas if it's in the pavlovian test then perhaps that region should not get that reinforcement even though the animal expects reward okay so the main finding here is so i'm going to focus i'm going to play some videos of what happens in the dopamine signals first in just the gcamp or calcium terminals and what you're going to see is a timeline when it gets to zero seconds that's
when the animal experience the reward in the instrumental task and what you should notice is that there'll be a big sort of white blotch of activity which would signal increases in dopamine activity when the reward was achieved but you should see that it doesn't all happen at the same time in all regions within this striatum so you saw it once it's going to play it again you can see is that there is a wave of dopamine activity from the medial striatum that propagates towards the lateral striatum in the instrumental test but what happens in the
pavlovian task you do the same thing you can see there's also a wave of activity but it's going the opposite direction um and so those were just videos of certain sessions but you can also quantify this in all sorts of different ways and the reef did to use computer vision methods for quantifying the optical flow of this activity and this is basically just summarizing the vector fields showing that on average when the animal gets reward in the instrumental task the direction of travel of these waves is from medial to lateral and uh in the pavlovian
task it's the other way um and if you look at what happens in the dopamine signal in the animals uh before they've learned the task at all you do see some interesting spatial temporal dynamics during the reward but they are irregular they don't go in any clear direction and so the summary from this uh slide here is that this spatial temporal trajectory of dopamine activity is learned because it's not there initially and it's sensitive to sas structure in that when the animal is in one task the wave is going one direction and when it's in
the other task it goes in the other direction and we think that that might relate to a way in which the doping signal gets information about uh the task structure that could support credit assignment that i'll try to unpack in the next few slides um so i'm not going to have time to go through all the details of this paper was actually just published last week online in cell with uh arif amit again as the first author and collaboration with chris moore's lab at brown um so one thing we wanted to do besides just asking
whether the waves go in one direction or the other is say well what happens if you have the tasks reverse within the session so here is the velocity of the animal when they're in the instrumental task and you can see they're running at relatively high speed and then at when at zero is when we unbeknownst to the animal we reverse the the task from instrumental to the pavlovian and you can see they fairly quickly learn after a few trials to stop running as much although they're still allowed to run whereas when they're in the pavlovian
task it's uh you know they're not running as much and then when the it switches to instrumental they increase their running so they're learning the task structure they're running only when they need to to obtain rewards um and so we're going to look at the dopamine waves in these within session reversals in both d lights and and g camp sessions so they're basically just different ways of measuring dopamine activity at the terminals or release they basically show the same results but for those who are interested i'll show them both and you can see i'll show
you the videos again what happens at the reward here in dlight you can see they go in opposite directions again instrumental and pavlovian trials and in g camp in green again the opposite direction slow down for you to see so this is basically just showing again that we get waves in opposite directions but also within uh during this session when they're going back and forth between the different tasks you can quantify that significant and here you can look at the dynamics of that and so uh what this is showing actually i'll focus on the left
here it's just individual trials when the animal in pink is in the pavlovian task where we're just quantifying the the flow of the dopamine activity at the time right after the reward and you can see it's going from lateral to medial it's going to the left on average and then here is the reversal and you can see for the first couple of trials it actually was still going in that direction but then after the third trial in this particular session it starts reversing and going the other way and you can see that here quantified across
animals and sessions you can quantify the angle of the wave going one direction the other and you can see these nice reversals right at the block change that mirror what you see in their behavior and so i i think i'm going to i can come back to this if there's a question for this but we have some simulations through reinforcement learning models that could suggest why waves are particularly well suited to support this credit assignment but i realize i'm going longer than i wanted to so i'm going to skip this slide and i'll come back
to that if you're interested and i just wanted to take the last couple of minutes to motivate um uh this model that we have that tries to tie together the dopamine dynamics uh that are happening in the striatum and why uh and how they can be used to infer agency and to reinforce behavior so to do that here we built a model this is not a detailed neurobiological model it's a computational level model so let's say you're an animal in this task and what you're trying to figure out is is the task generated by an
instrumental contingency so is there sort of a distance uh to run or do i just need to wait to get the reward and so let's imagine that in your brain you have these sort of experts that focus on oh i'm in a situation which i have to run i mean it's instrumental or not and then within the instrumental task you might you know learn that there are different kinds of contingencies like sometimes you need to run three centimeters to meet to move each tone sometimes five centimeters sometimes eight centimeters you can think of that as
having different sort of motor models kind of like when you pick up a glass of coffee or water sometimes you expect it to be heavy and sometimes light um and within each of these sort of sub experts they would have different predictions essentially about if i had to run five centimeters per tone i expect that after the first five centimeters i'm going to hear this tone and then after the next one that tone and so forth um and at the end of the day what the model has to do is decide should i run and
how fast should i run and so in this model we're asking how can you assign credit to these different sort of experts and sub experts in a way that will allow it to to do the right thing and the basic idea is that you should accumulate evidence for those sort of sub experts and then the overall experts that best predict uh the outcomes or the transitions that you see in the task where agency in this case would be reflected by a congruency between your actions and the outcome so if uh well maybe i'll make that
clear in a second let's say you're running here and sometimes you're in a short trial and you have to run a little bit in order to change the tone sometimes the long trial you can ask is there a congruency between your how much you've run and when those tone transitions happen and so at the lowest level of this model uh we expect there to be these prediction errors every time a tone transition happens because even if you predict you're in the instrumental task you don't really know exactly when the transitions are going to happen so
if you're in a short trial uh the tone transitions might happen earlier than expected and if you're a particular sub expert that expected it to happen the tone transitions to to be longer you would get a reward prediction error every time the tone transition happened earlier than expected and the way this works in reinforcement learning is that those go up across time because of uh something called temporal discounting whereas uh if the trial is longer you still should see prediction errors unless you're exactly predicting when they're happening but they should be you know smaller and
spaced out as the tone transitions happen and the idea is that you could use these sort of discrepancies between your actions and your outcomes and when the prediction errors happen to make some inferences about which of these sub experts is uh is most likely explaining the data is most likely responsible for the world and so you could use these reward prediction errors for making inferences about agency uh and so the way that that happens in the model is that the sub experts will accumulate the evidence for you know one of the sub-experts or another and
if you're in a task that requires let's say running eight centimeters per tone then you see the sort of ramping of the activity of the sort of evidence for that sub expert and decreasing ramps for the other ones and finally at the highest level uh if you're saying okay across all of my little distance experts here i'm gonna you know pay attention to the one that's predicting stuff the most in this case it might be that one and how well am i predicting outcomes relative to just waiting just the time expert and so what that
does it says in the instrumental task it would predict a ramping increase because overall across all my sub experts i'm predicting the data better than a model that just says i have to wait without running whereas if you're in the pallowing task it would actually go the opposite direction in the distance expert because it's not actually responsible for the outcomes okay so after you've done those three levels you would say okay i have evidence that i'm in control here and you can use that to then decide how much to run and so that if you
have evidence that you're in control then that can give rise to something like a wave that would reinforce the dorsal medial striatum or the distance expert in this model which then in the model will produce more and more running in the instrumental session and less running in the pavlovian session okay so i know that was a lot but here are the key predictions from this model that predicts that there are these different signals that the brain needs to use to compute whether it's responsible for outcomes or whether it's agentic and uh should reinforce the behavior
at the lowest level there is these sub-expert reward prediction errors and now aligning them so that they're reflected by progress towards rewards so percentage of the trial um and then uh in the middle level there are these ramps and the highest level they're the waves that you've seen already and that you know these should all inform each other and so what a reef did is he looked in the brain uh by zooming in in the dorsal medial striatum dopamine signals to see if there are evidence for these dynamics at all the levels and so at
the lowest level here he's using two photon imaging to really zoom into individual axon segments and he found these really intriguing patterns where he saw that there are certain axon segments that show transients to the tone transitions they look a little bit different than what you see in the model here because they're sort of distributed across different axon segments but there's one axon segment that shows this prediction error when you go from the first tone to the second tone and or it shows a transient and that transient is larger when it's in a shorter trial
compared to a longer trial as expected from a prediction error and then there's another axon segment that shows a transient for the second to third transition and so forth spanning sort of tiling the whole space so that was pretty neat we thought because you see evidence in different axon segments for these different kinds of prediction errors uh along the um along the trial um and but they still look like reward prediction error like responses and they have properties of that um and this part i'm going to not really talk too much about but we also
see evidence that uh at the sort of zoomed out level across the dorsal medial to dorsolateral striatum there are these ramping signals that as the animal is approaching the reward the dopamine signal is ramping up in the instrumental task and it's ramping down in the pavlovian task and the steepness of that ramp is is greatest as you are most medial in the striatum so as the animal is most uh the the region of the stride that's thought to be most related to goal directness or agency has the most uh steep ramping up and down across
the different task directions and then and then here we can ask okay is it actually responsible for changing the wave direction and for reinforcing behavior so here i'm just showing the velocity of the animal we know that it runs more in the instrumental task and runs less in the pavlovian task and so we can ask is there evidence for this uh these waves of activity being involved in reinforcing uh agency and so what arief did is he asked if we look at the wave angle on the last trial if it's going from medial to lateral
which is supposed to reinforce running is that related to velocity on the next trial so it's not a performance effect it's the amount of dopamine that you had on the last trial it's not really the amount it's the direction of the wave and you could see that if you just look the last trial back the greater the wave is from medial to lateral the faster the animal runs and then you see that effect two trials ago and then it sort of goes away in previous trials back so this sort of pattern of looking at the
uh some neural signal on the last trial and the trial back in the trial back before that is exactly what you want to look for for a reinforcement learning effect where you know generally prediction errors have the greatest effect on the last trial and the trial before that and so forth but here it's not the standard just doping activity leads to greater learning it's the wave of dopamine leading to greater running um okay so i know that was quite a lot but the summary of what we're seeing here is uh there's various different dopamine dynamics
in the striatum i emphasize the waves but we actually saw three different kinds of transient of dynamics we saw these waves we saw ramps and we saw transients and we think that the transients are like reward prediction errors uh about but in this case about the task structure so when the tones happen when you don't expect them but also uh you know a particular region of the striatum is related to agency and other regions are not and then the ramps can sort of cumulatively uh accumulate that evidence for agency to decide you know whether the
animal should work or not should it run in that trial or not but really we think that that allows it to infer whether it's in the instrumental task or the pavlovian task which then has a way to guide these waves to reinforce the correct uh underlying circuit in a way that uh supports credited assignment um of course there's huge this opens up this finding that a reef had of waves and these dynamics is a novel finding uh and so that also opens up many questions about the mechanisms that give rise to these waves and many
other experiments that need to be done but we're excited about this and i look forward to your feedback again if you want to see much more of the details of this at all levels i refer you to the paper and with that i need to thank arif for pretty much all that work uh and my collaborator chris moore whose lab uh he sat in to uh to do the the rodent work and my other collaborators for the initial studies i told you about in my lab and funders and so forth so thank you very much