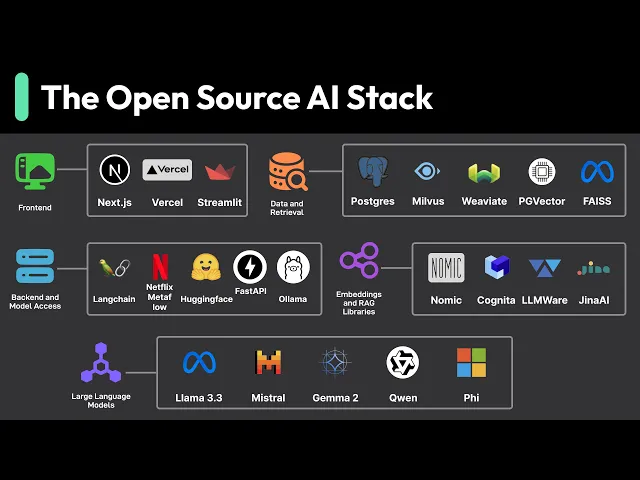
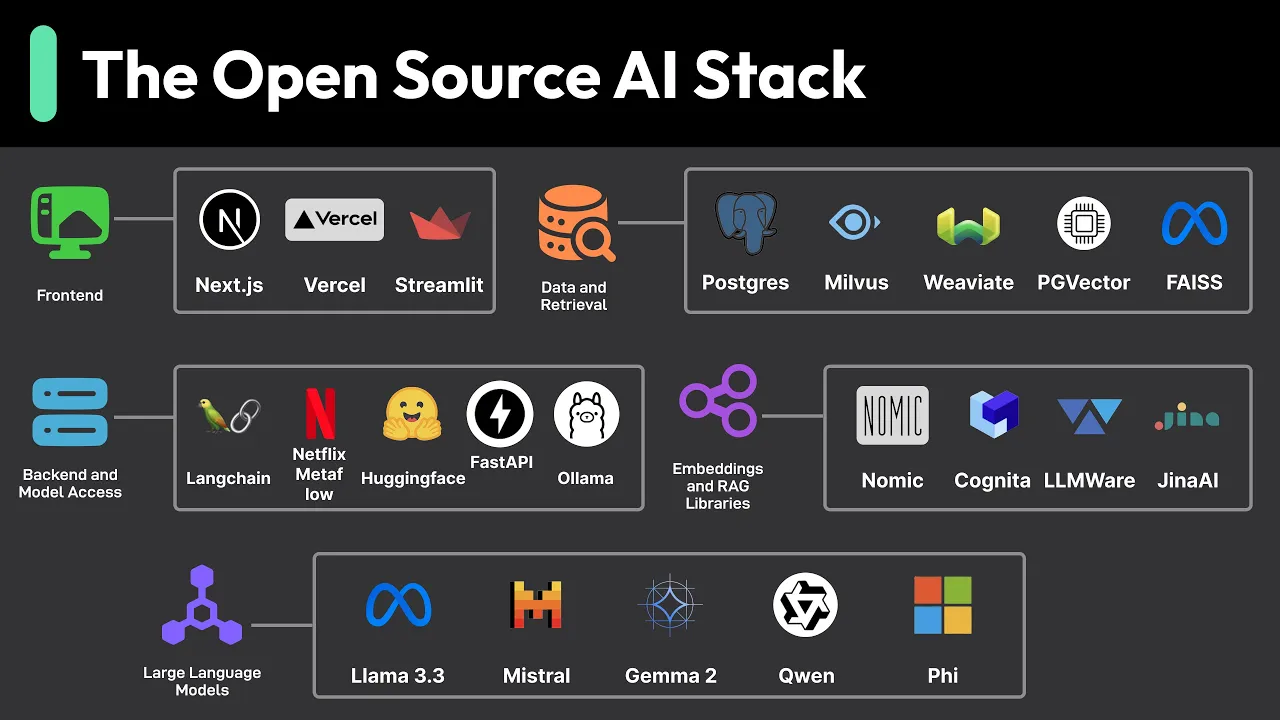
the world open source AI has exploded giving us freedom and control over our AI projects gone on the days when AI developments was locked behind proprietary walls open source breaks down these barriers and that is experiment without huge uping costs so what does this open source AI stack look like in practice let's break it down starting with the front end the gateway to our AI applications for scalable apps Frameworks like nextjs and spell kits shine with their streaming capabilities is crucial for showing AI responses as they are generated for rapid prototyping tools like stream lit
and gradio let us build interactive interfaces in pure python though we might need something more robust that our apps grow more complex let's talk about the data layer where we connect our AI models with our specific data whether there documents product cataloges or customer records a key concept here is rag retrieval augmented generation instead of fine-tuning models on a data rag dynamically pulls relevant contexts during inference with first convert our documents into vectors using embedding models store them in a vector database and then at query time we retrieve the most similar chunks and inject them
into the model's context window this give us upto-date responses and precise control over our ai's knowledge base for making sense of our Vector spaces nomic Atlas helps us visualize and debug our embeddings when we need to handle documents Lami index helps us build robust processing pipelines from splitting text into meaningful chunks to generating embeddings for handling diverse file formats from PDFs to Excel files Apache Tikka handles the heavy lifting of content extraction and metadata parsing for multimodal search Gina AI letters work with text images and other data types in a uni IFI Vector space with
building support for cross model querying now for the back end fast API give us that solid API Foundation we need with websocket support build right in great for streaming our AI responses in real time when we need to connect multiple AI operations L chain help us build those complex workflows while keeping everything in clean maintainable python then there's metaflow which let us write ml pipelines that straightforward p python code while handling the complex Parts like data versioning and orchestration automatically and we can scale from our laptop to the cloud with minimal changes for working with
models we've got some great option olama makes local development on smaller models easy almost like we're working with Docker before AI then there's the hucking face ecosystem opening up a world of community models we can access programmatically for storage we've got options that fit different scales if we're already using postgress PG Vector give us Vector search capabilities right in our existing database when we need to go bigger muas and wva are purpose built for this with wva standing out for its hybrid search combining vector and keyword approaches the llm landscape is especially Dynamic right now
models like mistra and deep seek a pushing was possible with openway models with two syam CPP with ggf format and quantization are making these models run efficiently on consumer Hardware that's really the beauty of the open-source AI stack it puts us in control though it comes with its own challenges around maintenance and expertise what we cover here is just a snapshot of the current landscape and is far from exhaustive New tools and approaches are emerging all the time the key is to start simple with proven tools scale what matters and stay flexible as the ecosystem
evolves if you like our videos you may like our system design newsletter as well it covers topics and Trends in large scale system design trusted by 1 million readers subscrib at blog. byb go.com