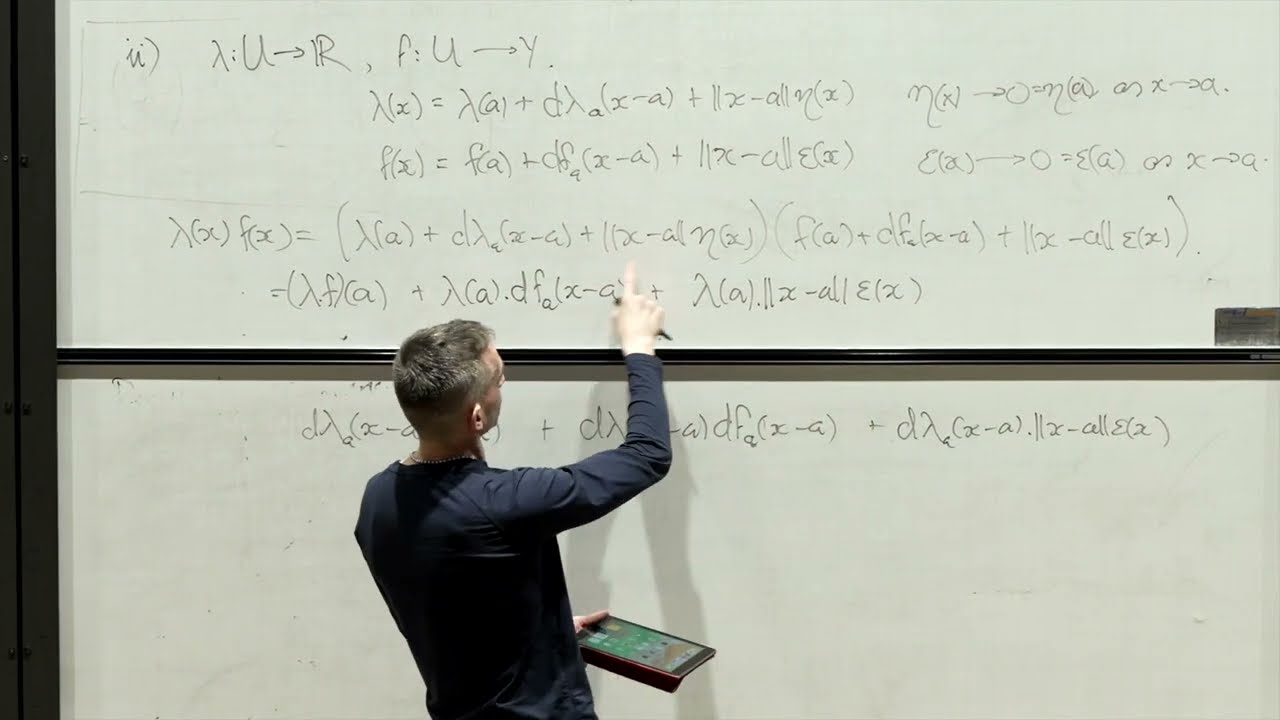[Music] I want to start just by finishing off one or rather pointing out one consequence of what we did yesterday so we saw yesterday that if x is a norm Vector space and its Dimension is finite then any linear map or all linear maps from X to any other Norm Vector space um are continuous are continuous and that's the same as being bounded in the sense that we talked about last time so a important consequence of this is that if you have X equipped with two Norms so I'll call them Norm a and Norm B
um then you get two different Norm spaces one with the vectorace Space X with this norm and the other the vector Space X with this Norm um and the identity map so the linear map that's just the identity on vectors you can think of as a map from this Norm space to this Norm space and and its inverse which is also just the identity are automatically continuous when X is finite dimensional okay so as is its inverse and that means equivalently that they're bounded and so just to cash out what that means it means that
the image of Vector so the norm sorry make that a lower case the borm of the vector X is bounded by a constant times the a norm of the vector X and that's using continuity of the identity map going this way if you use the continuity of the of the identity map going this way you get a sort of complimentary inequality you get say maybe I'll call that C1 so the a norm of X is then bounded by some constant times the borm of X and whenever you have both of these things a norm bounded
by a constant times another norm and vice versa this Norm bounded by a constant times that Norm we say the Norms are equivalent okay so in finite Dimensions all Norms on a finite dimensional Vector space are equivalent you had in in metric spaces you had examples if you look at um infinite dimensional Vector spaces like uh say sequence spaces that are square summable and absolutely convergent then um those two Notions of convergence or continuity or just the Norms are not equivalent so in infinite dimensions uh this is no longer true okay so one of the
convenient things about finite Dimensions is that whatever Norm we use every other Norm that you might use is equivalent to it in this uh explicit sense so the uh one Norm the two norm and the max Norm that you used regularly in the metric spaces course um all those three Norms are equivalent and you could show that directly but this is saying that whatever Norms you put on a on RN it's equivalent to say the ukian norm okay and that you can think of is saying well okay I don't need to care let's just always
use the ukian norm um in reality it's useful to know that every Norm is equivalent to the UK ukan norm and sometimes it's more convenient to use a different Norm like uh when we proved this statement that any linear map is continuous if the if its domain is finite dimensional it was easiest to start using RN with the one Norm okay so the main topic for today is what is differentiability okay so what we want to do is want to have a sensible definition for say a function f defined on some subset of a norm
directory space so let's say U Is An Open subset and X is nor Vector space in which U sits and F is just some map from U to Y where Y is another Norm Vector space so remember that imposing the condition that the vector spaces have Norms is just uh a condition that means it will make sense to talk about limits and to talk about continuity so the derivative is going to be defined in terms of some kind of limit so we need a norm like we most likely need a norm for that to make
sense um but I want to know what it means for f to be differentiable uh let's see definition for f uh to be differentiable at some point in its domain and and we'll take the domain to be open just so that at any point we know the function is defined sort of in every direction nearby so that's just a convenience um for this setup now the one variable definition well what did that say that said suppose um f a function on let's say an open interval taking values in the reals well then we can say
um if C is some point in the interval f is differentiable at C and has derivative frime to C if this limit exists um okay and when you move to thinking about maybe functions from the complex plane to itself this definition is fine right because you can just literally transpose it word for word take this to be a complex number you can divide it by H because you can divide complex numbers so for metrix basis in complex analysis it was fine to just to take this definition and sort of read it to say complex numbers
rather than real numbers um but if f is going from an open subset of a norm Vector Space X and landing in a norm Vector space y um this definition is not helpful um right I mean there's a number of problems I'm dividing by H so if H is a vector then I don't know in general what it means to divide by a vector um it's probably too much to hope I can make sense of that for an arbitrary Vector space and then even if I did it doesn't really solve the problem that you have
because the numerator and denominator live in different Vector spaces so dividing one by the other even if I knew how to divide by vectors wouldn't really help me because i' need to figure out how to divide by a vector in a different Vector space so this definition is sort of set up in a way that is really designed to obscure how you might generalize it to Vector spaces but let's think for a moment um can we learn anything if we assume that X and Y are onedimensional right so that seems like it is just this
situation um the only difference is I'm sort of abstracting it a little bit so I just have some one-dimensional Vector space with a norm and some other onedimensional Vector space with a norm but that's not really an issue right I just need to take coord coordinates and I can reduce both of those to uh something which is just a copy of R so one solution would be to say well okay in the one-dimensional case surely we're fine we just pick coordinates write down the function from the reals to the reals Associated to picking coordinates and
then take the derivative of of that function now so let's do that just to see what happens so um let's say um pick x0 a non-zero Vector in X and Y Z a non-zero Vector in y so those give you a bases of X and Y respectively um and I can write F of let's say t * x0 so this is an arbitrary Vector in here let's call that capital F of T * y0 right any Vector in um capital Y is just a scaler multiple of y0 so this thing has to be just a
scaler time y z so I get just by picking coordinates this function capital F uh is just a real valued function on the real line so let's say for example at zero we can ask if the derivative of capital F exists and that's just from the definition up there so does uh IE okay and if it does then we could go well maybe that's what we want to call the derivative the only issue is that we have chosen coordinates so if we want an answer that really is just intrinsic to the norm Vector space we
should check that it doesn't matter what coordinates we pick right so if we take let's say X1 sorry and y1 some other choice of vectors which are non zero then X1 is going to be some multiple of x0 and y1 is similarly going to be some multiple of y z and then we'll get a new function f maybe I'll call this one F0 and the new function F1 so the way I've defined it up here I would have F of tx1 um should be Capital F1 of T * y1 now let's just translate what that
means in terms of x0 so T * X1 is F of t or Lambda t uh x0 uh is therefore F1 of what I'm calling T and y1 is Mu y z okay um and then this is just F of Lambda of T time y z right just to take the definition up there uh using Lambda T instead of T that gives you this and so you see that uh F0 and F1 are related by you know a reasonable transformation but it's not the identity so F1 of T is Mu inverse F0 of Lambda of
T and so what that means is that the derivative when I chose the coordinates x0 and y z um sorry that will get multiplied by the corresponding thing if I use the derivative of the function F1 they're related by well just this expression here right the F1 Prime at zero will be Lambda mu inverse F0 Prime at zero okay so it does depend on the coordinates okay so what this is actually just telling you is that the derivative is not a scaler right it's not a whatever it is if it's going to map between X
and Y it's another scaler but you already knew that because if you did physics and or ever had anyone make a sort of intuitive explanation of the derivative it's supposed to be rate of change right so for example velocity has units right it's meters per second or whatever your choice of units is and this is just reflecting exactly the same thing [Music] so this just shows that the derivative is not a scalar right it it transforms I mean it is something we can calculate in coordinates like this because we know how to relate the thing
we get when we change coordinates so in that sense it's no worse than a scaler but the thing to realize what it's actually doing is that is that the derivative is actually a linear map right the scaler that you get from the ratio is just giving you a 1 by one Matrix if you like um so the uh derivative of this function f mapping from X to y when X and Y are onedimensional uh should be thought of um sorry I should say at at zero as the linear map um let's write it like this
frime to Z which sends x0 to this scalar times y z um so maybe given by okay and if you think and viewing it this way this calculation that we did the the calculation um uh to say of how it behaves when you change coordinates um is just the one by one case of if you like a goes to PA a q inverse if you change bases from if you have a a linear map from a vector Space X to a vector space y you write down its Matrix with respect to some basis in X
and some basis in y then when you change the bases you have to change that the Matrix gets altered by the change of basis matrices on the source and the Target and that's just exactly what we saw in the one by one case Okay so if you like that tells us what you should do with the fraction so th we should view um this expression that you get taught as the ratio defining the derivative I mean one thing you can always do whenever you have an expression which has a fraction in it is you can
just clear denominators and say well this divided by this um equals F0 is the same as requiring um the limit as H goes to zero of 1 / h f of H minus f of0 um minus frime of zero applied to H um I'm still dividing by H here but um we can replace that by dividing Say by the length of H or indeed what we can do in the one variable case or mimicking the one dimensional case is just take um so yes let's see this expression has the advantage that it sort of tells
you if you just look at that it's a product in the real variable case but if you're thinking f is going from one vector space to another then it's sort of obvious that this thing has to become a map from X to Y so that you can compare the vectors F of h and f of Zer which lie in y this thing is going to have to lie in y also which tells you that this thing should be some kind of function from X to Y and then we want this difference to go to zero
after we scale it by something uh which should be related to this Vector H okay so from this we get sort of I guess proposal one oops for what we might Define the derivative to be right so we could say we want a linear map um because that's what we got in one variable case um and what properties should it have well it should have something like this um uh tending to zero sorry uh so what we can do is say that if we have a vector in X um then the derivative at zero on
that Vector should be the limit of f of0 plus if I just use a scalar T to vary the length of the vector but keep it in the same direction then I can consider the difference of f of 0 plus sort of a small p pation in the direction V minus F of0 all over T and then here I'm just dividing by a scalar so this is one way to escape from the division by Vector problem and then just take the limit as T goes to zero okay so this thing gets called a directional derivative
um so it's the directional derivative at zero that's the point you're facing your measurements of the function f from uh in the direction V and we'll probably denote that as a kind of partial V of F at zero okay so this is one sort of reasonable candidate um I guess if you have F taking values in a vector space you know how to multiply and divide by scalars so you can use the direction of v um to move consider the change of the function f as you move in the direction V infinitesimally in the sense
of move just a very small amount in the direction V subtract the vector that you were originally divide by T and see if that tends to a limit so that gives you um where it exists a well- defined function um so this uh this proposal gives at okay I'm centering things at the origin just for Simplicity but you could do exactly the same thing at any fixed Vector in the norm Vector Space X if you had some Vector a you can look at a and perturb it a small amount in the direction of v and
the same definition applies so this proposal gives you a function well gives a candidate for the derivative as a point that being the derivative at zero is the function which takes the vector v to this limit which is a vector over in Y where that exists I mean assuming that exists so that's not quite good enough um so let's see drawback um in the one-dimensional case the derivative was a linear map I mean maybe that's just a quirk of one Dimensions but in a sense what the derivative does is it gives you a good infinite
decimal approximation to the behavior of the function at the point that you're interested in now an approximation well you know if it's a really good approximation that's good so long as it's useful to work with so the function itself is a very good approximation of itself but it's complicated um so really what we want to do is get a good linear approximation because linear things you're not supposed to believe are easy um or at least linear maps are a lot easier to study than arbitrary differentiable Maps so the definition but just of taking all the
different directional derivatives has the drawback that it mightn't give you something that's linear so uh proposal one um need not result in frime of zero so it's definitely it's a map from X to Y um but it need not be linear um let's see yeah let's take an example so if I have f a function on R2 and let's say it's just equal to X1 * X2 * X1 + X2 uh all divided by the norm squared in the ukian sense of X that's provided um X1 and X2 aren't zero and then let's just set
it to be zero if X1 and X2 are I mean if we're at the origin okay so we can compute so if V is V1 V2 let's see what the what happens when we take the directional derivatives so the directional derivative in the direction V of F at zero it's kind of cumbersome to say uh is just F at T * V minus F at zer which is zero over T so let's just substitute in for that and you get a factor of t for X1 X2 and X1 + X2 so this is T cubed
V1 V2 V1 + V2 divided by well T ^2 just coming from the F of T applied to V and then I divide by T again so that's T cubed and then the T cubes cancel so this is just okay so the directional derivative of F at the origin in the direction V is just F at V so this is a case this is sort of motiv motivating why I was saying the directional derivatives or collections of directional derivatives give you a really good approximation of F at zero but it's no simpler than F at
zero and then what's Happening Here of course is that this uh numerator is homogeneous um of degree 3 and the denominator is hom homogeneous of degree 2 and anytime you have a ratio of things differing by one in homogenity dividing by T will give you back the thing that you started with okay so this is saying that you can have all the directional derivatives and not get a linear map so if you like proposal two well let's just insist that you get a linear map um say f is differentiable at zero if the directional derivatives
um Define a linear map um from X to Y so that that seems better that saying well we kind of know what the infinite decimal approximation of the function should be it should be the directional derivative at least following of the intuition of the one variable case and we want a linear map so we just demand that we get a linear map um it turns out well now this thing has a name it gets called uh not fr's uh gate derivative um so this is not the definition of the derivative that we will use and
the reason we won't use it is because of things like the example I'll do a second um but it's not a completely disastrous definition there are situations in which the definition that I'll get to in a second which is sort of a more robust one um just doesn't hold for functions that you still care about enough to want to have some notion of derivative and then if you can't have what you really want you can sort of make do with what you've got so this is not completely useless but it's not good enough for the
purposes of this course so the example that I want to consider now is just let Omega be the following region in the plane so let's see if uh that's a so you're supposed to believe that this is a um y = x cubed uh and then I want to have here that's supposed to be one y = x^2 okay so and then the region that I care about is just the stuff in between okay and then so so it's just this kind of little uh slice that's bounded between the graph of y is X cubed
and Y is X2 between 0 and 1 okay so this is also one up here okay and then the function I want to consider is just the indicator function of this set so this is just equal to one if um your vector is your point Sorry is in Omega and zero If X is not in Omega okay so now let's see what happens um ah sorry I should say it's the open region so Omega is the points X1 X2 where let me see I guess uh V1 sorry X1 0 is less than X1 cubed is
less than X2 is less than X1 s okay so I have strict inequalities here so the origin is not in Omega and then the point is that you can check that for all v um in R2 the directional derivative of this function f at zero in the direction V is zero um and why is that well it's just that the tangent lines of both y = x^2 and Y X cubed at the origin are flat so um if you take X2 equals sorry yeah X2 equals 0 all those points lie outside Omega so you get
the directional derivative vanishes if you take any so this is where the the picture isn't very good if you take any line with positive slope then if you just calculate you see that okay there will be a portion of the line which lies inside Omega but because these tangents are horizontal at the origin um and this has positive slope for very very small um multiples of your vector v it will lie if you like above both the graph of x^2 and X cubed okay so all the directional derivatives of this function exist at the origin
they all vanish so they Define a linear map which is the zero linear map but well now it's a matter of taste really um this function is not even continuous at the origin right so but F of um uh t tqb + t^2 / 2 right just the the average of these guys is equal to one uh for all T in between zero and one let's say uh and the limit of this is the origin as T goes to zero so my function which is possesses all its directional derivatives at the origin and those directional
derivatives Define a linear map fails even I mean fails fairly spectacularly to be continuous at the origin so if you wanted to think of the derivative as being like sort of better an improvement on continuity then this definition isn't good enough um so you can have all the directional derivatives existing you can have them patching together to give you a linear map and your function still behaving relatively unpleasantly so the definition that we actually want uh finds a way of sort of excluding this um and if you think about what's Happening Here somehow in every
direction you eventually end up being an sort of domain where F vanishes but which direction you're in um how small you have to get before that happens um depends a lot on the choice of Direction so the way to sort of get out of this issue is to demand if you like that the uh directional derivatives sort of all approximate the function at the same kind of uniform rate okay so the uh definition that is if you like proposal three um the one that works is the following um if f is a function um so
I'll kind of try and keep this notation standard so you open in X and X and Y Norm director spaces um and a is a point in U we say f is differentiable as a if there's a linear map let's call it Alpha um from X to Y strictly speaking if we were working in infinite Dimensions I would say here continuous linear map but I you care about finite dimensions in this course and then all linear maps are automatically continuous so I have a linear map Alpha from X to Y uh such that if Epsilon
which is going to be a function from U to Y is defined by Epsilon vanishes at a and F of a plus h so if I perturb F moving in a direction H is f of a plus my linear map applied to h plus the norm of H times Epsilon of a plus h okay so all of this expression is just saying take F of a plus h subtract F of a subtract off the linear approximation that's supposed to be our derivative that gives you some Vector that Vector should go to zero sorry that's then
then I need to finish off my sentence um and Epsilon uh of a plus h TS to Epsilon of a which is zero as H goes to zero okay so this is saying that there is a linear map with the property that if you like the error between the function the actual value of the function A F of a plus h and the approximation given by F of a plus this linear map applied to H the difference between the two so the error you can write as the length of H times something and that then
when you divide everything by the length of H this still go go to zero so it's saying that um the linear map Alpha applied to H gives you an approximation to the function f of a plus h which you know is a at least as good as the length of H it's uh well actually because we know all linear maps are bounded you can see from that fact that there can be at most one linear map with this property okay so let's just rewrite that just to make it clear so thus that is Epsilon of
a plus h is equal to F of a plus h minus F of a minus Alpha of H all divided by the norm of H and then we're just saying that that error is going to zero faster than the norm of H okay if this condition holds um then if this holds Alpha is the derivative of F at a and then well if you look at textbooks you will see a whole variety of different notations um and is denoted possibly lowercase DF at a possibly uppercase DF at a and possibly both upper or lowercase with
the a as a subscript um I I think I will tend to use this or this um the reason for not writing this is because this thing is a linear map so you'll want to write the linear map applied to a vector becomes DF of a of V which just gets kind of clunky and so the usual convention is to write say something like DF of a acting on V like that um but so this is what's called uh this definition is if you want a name for it the frase derivative um and it's also
often referred to as the total derivative which is not a great name but it comes from um as we'll discuss probably next time the notion of partial derivatives where you sort of fix some directions see what the variation of the function is in some subset of those directions um and those being partial derivatives then what's the other the thing that isn't partial well it's total I guess um so total derivative is a fairly common term though it's not really a particularly good one FR derivatives is sort of the formal term um it's this uh yes
sorry what to say what this definition is doing compared um to the definition where we just ask for the directional derivatives to exist and form a linear map is that it's asking for this error to go to zero um when you divide by Norm H sort of so it's uniform in like the sphere of vectors of Any Given length um so it's uniform in a sense in the directions so the uh the difference between the fresh a derivative and the gate derivative is that the fresh a um if you like derivative demands the directional d
d directional derivatives uh to converge sort of uniformly in the direction on the sphere in X so that's the so really that's just taking the unit sphere as sort of the vectors of length one as representatives for the uh space of possible directions you can perur in okay and just to point out um if f is fras differentiable at a then all the directional derivatives exist um and in fact the directional derivatives of F at a are just the fras derivative applied to the vector and let's just check that to see that we understand what
the definition is actually saying so indeed what's the definition of this guy we want the limit as T goes to zero of f of a plus TV minus F of a minus if you like T * this all of this over t t equals z um but if you just look at what the FR derivative definition gives you the limit as T goes to zero of f of a + T * v um minus F of a minus the fras derivative at a applied to T * v um all divided by the norm of T
* V um equals zero so this is just the difference that is Epsilon of a + T * V and then if you just work out what this is this is the limit as T goes to zero of I guess uh T divided by the absolute value of T times Norm V time F of a plus TV minus F of a minus t taking the scalar out of the linear map DF of a at V uh so this is bounded so because this goes to zero this goes to zero and that means that this Vector
here satisfies the definition of the directional derivative okay so the fres derivative is the linear map you get by patching together the directional derivatives so if you like um if you have a function whose directional derivatives exist the question of whether it's faas differentiable or not is a property of the linear map you get by piecing together the directional derivatives it's saying that linear map has to be a good approximation to the function in the sense that it approximates the function sort of at least as well as the norm of the difference between a and
a plus h okay so next time we'll study sort of the basic properties of the derivative and see that you know things like the chain rule um have an analog for the fresh Ator VI