welcome back so we are talking about physics informed machine learning the process of building models from data that are either physical in nature uh or are discovering new physics or embedding physics into the machine learning process and today we're talking about stage three uh which is designing an architecture okay so this is one of uh my favorite parts of this entire machine learning uh pipeline I've been looking forward to making this video for a while actually spent a lot of time uh kind of thinking about the progression and we're going to have hours and hours
and hours of you know material and lectures on various architectures that we can look at and use to discover physics using machine learning and to embed physics into machine learning so super super interesting important uh topic today and it's one of the kind of most popular areas people think about um in physics and form machine learning so um this is the neural network Zoo this is um a figure in Nathan Kuts and my book datadriven science and engineering inspired by a figure from the Isaac azov Institute uh and this just gives a small overview of
you know some of the many many many types of neural network architectures you can choose for a particular task um in machine learning so you have things like uh autoencoder networks Gans deeper current networks uh and many many more these are just kind of cartoon sketches of the various ways you can stitch together neural network building blocks uh into an architecture and so uh today we're going to talk about what is it um what do I mean by an architecture what are the different types of architectures what are ways that these are more or less
physical or that there are implicit assumptions built in to our choice of the architecture and again this figure you know is from five years ago so this is already um you know just a a tiny corner of all of the types of architectures that people are playing around with and developing today um a lot of what we're going to talk about in this uh this series on architectures is inspired by uh architectures in the brain in Neuroscience systems so animals um including you know mammals humans um you know rodents um fish right like insects have
nervous systems and brains and the way that they interact with and process data from The Real World to make decisions and move their bodies and things like that uh you know there are a lot of rich architectures in our brains and in our nervous systems so this is a great figure um I got from Bing Brunton she pointed me towards this this is a a picture a hand sketch by uh kahal who drew these beautiful um kind of handdrawn representations of neuronal architectures as observed in uh I believe microscope Imaging this is a section of
the hippocampus and you can see that this is a pretty complicated architecture it's multiscale there's connections across different regions that are doing different types of computations uh and we're you know just scratching the surface of understanding in neuros sence what all of these architectures are but a lot of that has inspired our uh neural network and machine learning architectures in the modern era so a lot of our convolutional neural networks and uh image processing is inspired by uh things we observe in the visual CeX and increasingly we're getting more and more kind of data about
these neuronal architectures and so these two fields are definitely evolving and growing together uh both neuroscience and machine learning so just an important thing to be aware of we're probably going to have some videos entirely on kind of neural inspired Computing and architectures um so you know stay tuned for that later in this um you know part of of the class on physics and for machine learning we're going to cover a pretty broad range of different architectures there are a lot of really important methods out there in literature that researchers are using today uh applying
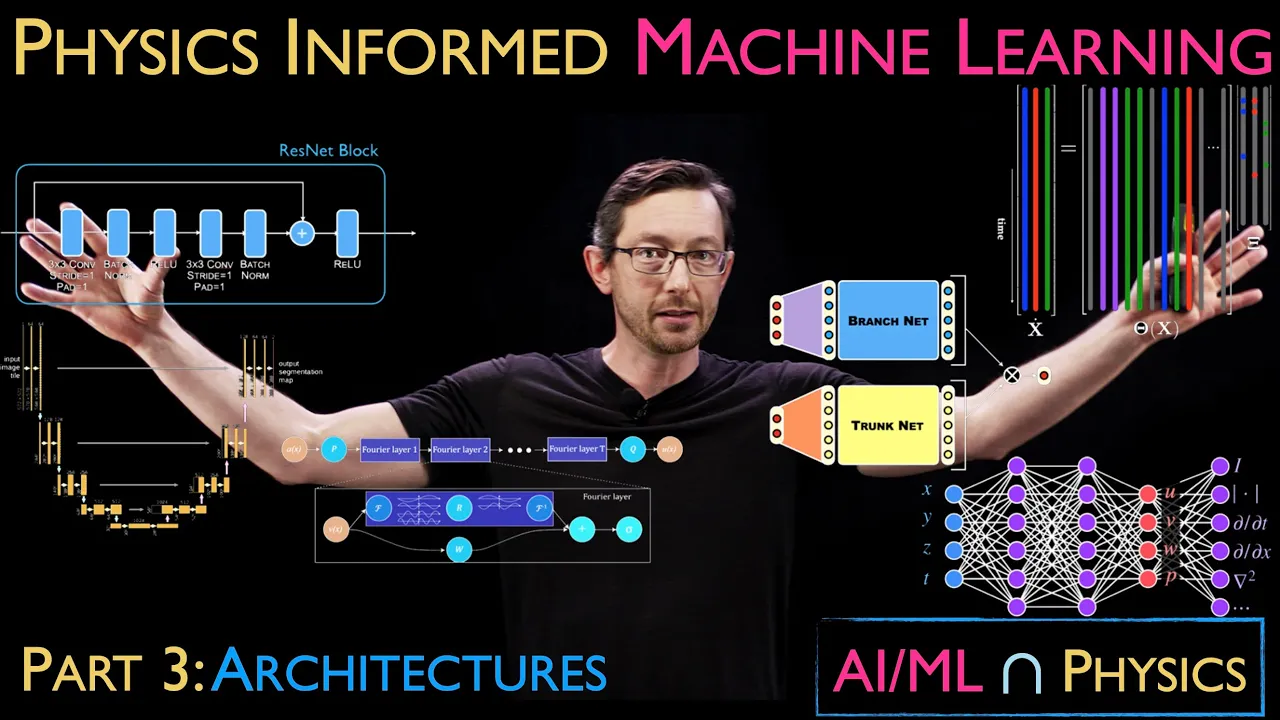
neural networks to and machine learning to physical systems both to discover physics and to make their learning algorithms better by incorporating physics uh so we're going to talk about things like um resnet uh residual networks these kind of um deep uh recurrent neural networks with jump connections we're going to talk about um things like the unet architecture this again has some implicit uh inductive bias in just the choice of this architecture kind of assumes that the world it's trying to model is multiscale in space and time for example uh we're going to talk about things
like operator networks um this is the fora neural operator very very popular uh modern architecture to analyze physical systems like partial differential equations uh things like Cindy the sparse identification of nonlinear Dynamics importantly this is not a neural network this is a generalized linear regression to learn a differential equation from data okay and this is an architecture this is a you know a this parameterizes a space of functions you could use to model your system um we're going to talk about pins physics and form neural networks again huge field of modern physics informed machine learning
research uh you know and and generally other operator methods and kind of architectures for pdes and Odes and this is you know I don't know maybe half of the topics I'm preparing and each of these we're going to have at least you know half an hour or an hour uh maybe with code and examples and case studies okay so we're going to go really into depth and a lot of these I'm pretty sure I have like 5 hours of material on Cindy alone okay so you can do a deep dive uh in equation Discovery if
that's what you're interested in but today we're talking about architectures and not just you know generic architectures but architectures that are good for physics that help us actually promote models that are more physical that help us learn with less data because we've had these implicit biases that um that add structure and physics um you know to these machine learning architectures so I'm going to you know talk about this a lot more in you know in the next hours and hours uh of this the material but I wanted now to start really getting into what do
I mean by physics so we're talking about physics and for machine learning and I didn't even describe what I meant by physics um I was at um a NPS Workshop about a month ago and I was giving a talk about you know machine learning for scientific discovery and I decided I should probably you know Wikipedia what is the definition of physics before I say that we're doing physics inform formed machine learning and you know kind of the Wikipedia definition has something to do with matter and energy and change uh and that's fine and good but
I don't like that as a working definition so I am going to tell you what I mean by physics in the context of what we want our machine learning models uh to have as kind of their capabilities so one of the first important pieces we're going to um highlight is physics historically the kinds of physics that we um you know know and love like fals ma eal mc^2 things like that these are somehow interpretable and generalizable interpretable in the sense that they're usually very very simple um out of you know all of the the complicated
things I could write down to describe the motion of a falling Apple uh FAL ma is a very simple interpretable description and it's very generalizable because the same physics that describes this apple also describes you know the physics of launching a rocket uh from the Earth to the Moon okay so generalizability is a Hallmark feature of physics and our understanding of the physical world and again I don't think that physics is just limited to matter and energy I think that there is a physics of how the brain works and there's a physics for how you
know a swarm or you know a colony of ants behave there are these generalizable interpretable kind of rules that govern complex systems and we might be able to learn those using machine learning and enforce uh some of those physics in our machine learning models okay interpretability and generalizability essential for me to be physical um parsimony and simplicity these are related um but there's this other perspective that we use to promote physicality and models so there's this great Einstein quote everything should be made as simple as possible to describe the data but not simpler so in
the machine learning era we're looking for models that are as simple as possible to describe the data and no simpler this principle of Simplicity or parsimony has been the gold standard in physics for 2,000 years from Aristotle to Einstein the models that are more beautiful more parsimonious as simple as possible and no simpler typically encapsulate the core bits of physics and they also have this KnockOn effect that they're more interpretable because they're simple and they tend to generalize because they're not overfitting so we're going to talk about this later in the context of the history
of science from um astrology to astronomy from Alchemy to chemistry every time we've made this huge kind of Leap Forward in our understanding of physics things have actually gotten simpler the descriptions have gotten simpler and more Universal okay super super important point and then the last area where um I think we have a huge opportunity to capture essential physics in machine learning and to discover essential physics with machine learning are these Notions of things that are you know symmetries invariances and conservation laws so almost all of our partial differential equations Mass conservation momentum conservation energy
conservation um you know all of our partial differential equations come typically from the conservation of some quantity okay mass is conserved momentum is conserved energy is conserved and similarly there are fundamental invariant in our universe and the way that things work um that give rise to you know symmetries in the data okay so symmetries and invariances and conservation laws are fundamental core principles in physics that we can leverage and either bake into machine learning algorithms or learn these symmetries and conservations with machine learning algorithms okay so really really essential um like we know that you
know if I have a pendulum physics the physics doesn't change if I translate it um you know in in space and in principle this fluid flow shouldn't change if I rotate it okay there are these invariances in the laws of physics good okay so that's what I mean by what is physics now we're going to go through these architectures and think how can we either enforce uh or promote these ideas and then how can we also discover you know symmetries and things like that with uh with these architectures and it's really important we're talking today
about choosing architectures to be more physical but the same basic principles apply when we add loss functions to train our algorithms or when we add you know when we do a constrained optimization to force our system to adhere to some symmetry or invariance Okay so this uh idea of physics is important for art architectures it's important for loss functions it's important for the optimization algorithm we use to train our machine learning algorithms good and I mean I guess you know the the takeaway here is yes we want all of these if we can you know
we would love for our machine learning models to be interpretable and generalizable simple and parsimonious and actually you know enforce or promote the known symmetries and variances and conservation of the physical world let's not forget you know the thousands of years of human experience we have learning physics the oldfashioned way um and you know let's make sure that we actually bake this into our machine learning models good okay so let's just do a really really simple example this is kind of what we talked about before in the overview lecture let's say I have you know
a physical system this is a pendulum in my lab this is a video so the representation the data is you know a time series of a very high dimensional Vector which was this image reshaped into you know all of its pixels so this is maybe a megapixel image evolving in time and I can represent that either as a matrix or as a really tall Vector if I just stack all the pixels on top of each other okay so it's data it's data it's high dimensional data but we know that this system has low dimensional meaning
right if I look at this as a human I don't see a million things I need to keep track of there is one pendulum and it's moving according to one angle we are experts at pulling out those key features those key patterns and going from very high dimensional data to something low dimensional like angle Theta and Theta dot so that's the kind of thing that a machine learning architecture would be chosen to do I as a human know that this high-dimensional data has low dimensional variables that matter angle and angular velocity so I might choose
an architecture that does this compression this kind of information bottleneck this autoencoder uh Network that will take this High dimensional data and try to find two variables that best represents that data this is a choice of architecture and I'm implicitly assuming that the physical thing I'm modeling is low dimensional now there will be a loss function in the next lecture that we need we need a custom loss function for this autoencoder so they go kind of hand inand but here is an example of an architecture we are using to promote low dimensionality and moreover I
might want to actually get a differential equation out I might want to learn some Dynamics in that Laten space not just you know a compression to Theta Theta dot but I might want to learn the differential equation that governs the evolution of theta and Theta dot something like this you know uh kind of fals ma for for a pendulum and so I can learn those differential equations Again by choosing a machine learning architecture that's good at learning differential equations something like this uh Cindy sparse identification of nonlinear Dynamics so again this is not even a
neural network it's just you know I build a library of things that could be on the right hand side and I use some kind of an optimization to find the fewest of those Library elements that add up to describe the Dynamics okay again so that is an architecture this is an architecture it's a space of functions that could describe my observed data and then there is some loss function and some optimization algorithm them to find the best function in that search space the best function uh in that kind of space of of uh parameterized by
this architecture so these are two architectures that get to physics okay one of them for example is this compression we're we're assuming our physics is low dimensional and here we're going to use um this Cindy Library procedure to get the differential equation that's assuming our physics is kind of sparse or simple that parsimonious idea okay so this is just one example um of you know an a set of architectures that actually promotes physics um this was codified by a really nice paper um written by Kathleen Champion when she was a PhD student um here at
University of Washington with Nathan Kuts and myself where essentially she did exactly that she comined a deep neural network autoencoder to learn a good coordinate system uh for the physics a low-dimensional coordinate system and then also a Cindy model for how uh the Dynamics evolve in that low dimensional coordinate system okay so this is a really um nice way of promoting things we know should be true in physics namely that they're parsimonious or simple low dimensional uh and sparse and this is a theme we're going to see over and over and over again even when
we choose an architecture to be physical we still often need custom loss functions to train these architectures to find the best model in this space of functions parameterized by this architecture so architectures usually have loss functions that are good uh to train those architectures okay good um so I want to take a step back what do I mean again by architecture so there's lots and lots and lots of different types of architectures there's you know hundreds or thousands of different types of neural networks there's plenty of machine learning that are not neural networks things like
you know uh generalized linear regression support Vector machines gusan mixture models K means clustering like there's a a huge variety of machine learning models at the end of the day a machine learning model typically takes inputs X and tries to build some function that predict that predicts an output of Interest Y and this function f that we're going to learn with you know for example a neural network um so in the case of a neural network you know the input here would be X the output would be Y and Theta are all of the parameters
that you can tweak for example the weights of the neural network to tune or to fit this function to best fit y as a function of X okay um in the case of this Cindy uh model procedure over here you know the the outputs that we're trying to predict are the time derivatives of some system State x dot um the you know architecture that we're parameterizing is a bunch of of Pol omals in this case that you're trying to add up to equal x dot and Theta are the weights of those terms that again add
up to approximate your Dynamics so in all of our discussion about architectures what we're really talking about is we're trying to constrain the space of functions F that we could use to describe this input output mapping because you know if I if I go to you know kind of a mathematical description function space are usually really big they're kind of infinite dimensional very very um Broad and inclusive lots of functions live in these function spaces think of a Hilbert space you know uh spanned by signs and cosiness like a fora basis um what most machine
learning architectures do is they constrain the space of possible functions that could describe this input output relationship through a choice of architecture so this is a very simple whole feed forward neural network that has a little bit of an expansion and then a contraction that's different than the autoencoder network we talked about before that had this really aggressive bottleneck and that's different than a Cindy architecture that's entirely different than a neural network but in all of these cases your architecture is parameterized by some free parameters Theta and we're going to optimize those parameters using some
loss function and some optimization algorithm to tune this function to fit data of the inputs and outputs data that we actually observed and collected okay so that's really I want you thinking in the back of your mind architectures they look cool everyone loves the pictures of you know unet and autoencoders and neural networks they look really cool but at the end of the day what these are doing is these are parameterizing functions and some parameterizations are more useful for some kinds of physics than others some of these function spaces allow me to enforce symmetries or
or enforce conservation laws or um you know promote parsimony and simplicity things like that so um I think that's everything I wanted to tell you here but I want you thinking that these are um architectures Define a space of functions we're searching over and we find the function we want by tuning these free parameters Theta good so now let's just go through some examples um I've got maybe I don't know five or 10 kind of of my favorite examp examples of just architectures that are interesting we're going to have whole videos on each of these
architectures you know you can download code and examples so this is just like the mile high thumbnail sketch um this is one of my favorites this is actually a really early example um 2016 this is right when people were starting to apply machine learning to really solve hard problems in physics and Engineering um where Julia Ling and her collaborators essentially built a deep neur Network in panel B that can predict the Reynold stresses that we need to to build turbulence closure models so when you're running like super computer simulations of fluid flow over a race
car or um you know a 787 Wing or some kind of you know really big industrial fluid flow usually we need some kind of a turbulence approximation because it's too expensive to simulate all of those fluid degrees of freedom and so often times we use something like this Reynolds average navier Stokes equation but predicting these Reynolds stresses is really hard that's been a open problem for five decades how to how to accurately um predict these actually more than five decades and this paper uh by Julia Ling and her collaborators uses a custom architecture in panel
B that has this tenser input layer and you know again we're going to have a whole video talking about how this works but essentially through the choice of this architecture through the choice of of this function space that we can use to model these Reynold stresses they are able to make it so that these models by construction just because they're in this architecture the models that are discovered have a property known as Galilean invariance meaning the physics doesn't change in any inertial reference frame so if I have a box of turbulence here or I have
a box of turbulence moving at a constant velocity the physics the the closure model terms the physics shouldn't change in any inertial frame that's what it means to be Galilean and variant and Ling at all showed that through a choice of this architecture with this custom tenser layer enforces Galilean invariance by construction all of the models represented in this function space are Galilean invariant that's super powerful and that's a way of building physics into the models presumably you can train this with less data and it will generalize better because it has that physics built into
it really important idea super cool paper um other examples um the residual Network I mean this is one of the most uh powerful architectures in modern machine learning uh this paper came out in 2015 I think by the time I made this video it's been cited at least 50,000 times people use it all the time it is a particular uh kind of deep architecture that has these jump or skip connections and this architecture is designed approximately so that the function of um this block behaves kind of like a numerical integrator like an Oiler integration scheme
again this is a choice of architecture that promotes something that we think might be physical like time stepping forward so this is really good for time series data and kind of you know data that evolves in time dynamical systems data um the unit archit Ure again this is a super powerful architecture for uh super resolution image segmentation um it's the basis of of a lot of diffusion models and it has this inductive implicit bias the structure of this um really speaks to the fact that the things that we observe in the real world are multiscale
okay they're multiscale in space so if I am looking at um you know a picture of the real world it's going to have this multiscale structure in time in space and that's kind of implicitly built into this architecture so this is good at parameterizing things like natural images um or scenes um you know of traffic or of a city or you know things like that um physics and form neural networks this is going to be one of the most important uh you know little deep Dives that we're going to do I'm going to have a
a pretty substantial lecture series on this and we're going to talk about it mostly in the context of the fourth stage of machine learning crafting a loss function but you'll notice again these are always kind of inherently mixed architectures and loss functions usually go together loss functions often rely on an architecture and architectures often have custom loss functions you use to train those models pins are really really interesting um if you're trying to estimate something like you know a fluid velocity field a spatial field something you know like it has a u a V and
a w component maybe a pressure that varies in space and in time what you can do is you can take a normal feed forward Network that you would use to kind of predict those quantities and then because of the automatic differentiability uh of these neural network uh environments like py torch and tensor flow and Jacks you can often compute these partial derivatives of these quantities without having to like hard code it and then you can add those outputs into a loss function that says that you actually have to satisfy the the physics of the partial
differential equation so again mostly this is a loss function but it is relying on an architecture where you actually are using things in the neural network to get these quantities that you need for your loss function so I think of it as kind of you know a little bit of architecture mostly loss function um L grangian neural networks and hamiltonian neural networks are a really good example again very much at this interface of architecture and loss function where if you know your system conserves energy or has this kind of mechanical structure that we know you
know lonian and hamiltonian systems have you can often bake that in both into the architecture and into a loss function to train the neural network architecture okay this is one of my favorite areas U really really cool work uh in lran neural networks um deep operator networks and operator networks in in general things like um deep oets for neural operators often use very custom architectures that accelerate the training uh with less data okay so again lots of physical implicit assumptions going into these uh structures we're going to talk about this at length um a lot
of these different operator networks um Foria neural operators is another really really popular architecture again the way I think about it it's based on the fact that every example we have of the real world of physics in the real world is multiscale and typically very compactly and efficiently represented in the forier domain so having these kind of forier layers in the forier neural operator is implicitly baking in some Physics assumption about the multiscale nature of physics uh and again we'll have a whole you know video talking about this later um graph neural networks are a
super cool example some of the neest um results in machine learning for physical systems are related to graph neural networks things like you know discovering um laws of planetary motion that generalize to multi-planet systems simulating fluid flows um gnns are you know all about baking in some Assumption of the structure of how things interact like nbody systems or molecular Dynamics or you know rigid body systems a lot of opportunities to bake physics uh into the these graph heral networks this is something I've been wanting to learn a lot more about myself so I think we're
actually going to learn about this together um I'm using this as an excuse to kind of dig into this topic and really um some very powerful demonstrations of you know efficient accurate machine learning models to really simulate some pretty complicated physics um this is a a super neat paper where they show that they can simulate lots of different types of fluids and elastics and just complicated partial differential equations using relatively simple ideas in in graph neural networks to to kind of bake in some of the physics of that system and I think roughly speaking it
relies on the idea that the physics of one little parcel is probably similar to the physics of another little parcel so instead of a huge neural network that takes in the entire you know voxal movie maybe there is a much smaller set of rules that determines locally what the physics interactions are okay so again we'll dive into this a lot more um good that was uh kind of the big overview that's uh I would say about half of the topics we're going to talk about um you know at length in detail throughout the rest of
the five or 10 or 15 hours of material in physics and for machine learning um something that I really really want to convey um and so I'm going to talk about it here is this notion that symmetries are fundamentally important to physics and they're fundamentally important to how we encode physics into machine learning and discover physics with machine learning so symmetries and invariance are one of the most useful mathematical Notions that we can use to improve machine learning for physical systems we're going to again this is going to be like a 5H hour minimum Deep
dive into what symmetries are how to enforce them with machine learning how to learn them with machine learning here I'm just going to give you the tiniest preview of what I mean by symmetries and variance um and this is a huge area of research where people are working super hard to bake these ideas into machine learning so invariance means the following things so let's say I have some machine learning architecture uh maybe it's a neural network that takes in an image of a dog or a cat and it spits out through this uh this function
f you know is my neural network and the output it tells me if it's a dog or a cat Okay so an image of a dog goes in I get a label dog or cat out super simple you know neural network you can train this easily yourself invariance means that we know that the notion of a dog shouldn't matter if that dog is translated in the image or rotated or scaled so there are some Transformations typically this is Quantified by something called a symmetry group or a Le group uh there are some Transformations G that
if I transform my data through G and then I run that through my neural network I should get the same output this is still a dog even though it's rotated by 30 Dees okay so that's what we we mean by invariance we want our model f to be invariant to these Transformations G that we think the physics is invariant to the physics of what it means to be a dog doesn't change if I rotate that dog so invariance means that my output doesn't change even if I run it through the those Transformations those rotations translations
things like that okay we understand this intuitively that's kind of what the word invariant means okay there is another notion in machine learning it's really in mathematics called equivariance and it is subtly different than invariance these are really important both are important equivariance means that if I take my data and I transform it through some symmetry like a rotation some symmetry operation and then I run both of those through my neural network then the output of my neural network is also run through uh that rotation or translation so it's a little different um here we
were talking about you know classification where the output should be identical here maybe I'm building a neural network that does image segmentation maybe it takes this picture of a dog and it segments it into you know Paws and snout and it kind of you know labels what the the bottom of the dog is and the top of the dog is that's the output Y and so equivariance means if I take my input and I rotate it or translate it if I transform it and then I run both of those copies through my my machine learning
architecture the output should be you know also have that same rotation or translation mathematically what we mean uh what we say is that the function f our kind of machine learning model and this symmetry operation G commute I can do G then F or F then G and I get the same answer that that mathematically this is called a commutative diagram and there's a ton of uh of algebra of group Theory um Le group theory that tells us when a function f and a symmetry Group G commute and how and things like that and so
this is a really big idea we know that convolutional neural network promote this idea of you know translation invariance it's now possible there are some really good research papers out there showing us how to build in general symmetry groups into things like autoencoders uh and other neural network architectures so we can start building our machine learning models to satisfy these symmetries these rotation and translation in variances by construction and the upshot here is if if I had to learn this by just augmenting my data I would need a lot more data of rotated translated copies
of my data but if I can build my architecture to have this equivariance property by construction because I know from physics that there's a symmetry I can dramatically reduce the amount of data I need to train that model and it's going to generalize way way way better so there's excellent work by um max Welling by Tess Schmidt by many others out there in the community talking about equivariance in machine learning models and so we're going to have a big section talking about how do you build these equivariant models um you know what kind of loss
functions do you use what kind of architectures how much more efficient are they how much better do they generalize but I just couldn't give this lecture on architectures without letting you know that you know equivariance is one of the most important ways we promote physicality uh through AR architectural choices okay good um so that is the kind of Mile High lecture on stage three of machine learning designing and architecture and opportunities for building in physics into that uh into that stage so next we're going to talk about loss functions and optimization again closely related these
are all kind of coupled uh and then we're going to dive into tons of cool examples and you know if there's an architecture you want to know about hopefully we are going to cover it all right thank you