so in this video we will take a look into a very interesting approach that atashian took to do cash and validation and they leverage sqs and SNS combination to do that it's pretty uncommon and we'll see what they did why they did and when they changed what they changed and how they changed right it's pretty interesting it's a pretty uh interesting Deep dive that we'll do today so let's get started you would have heard this very famous quote that uh there are two hard things in Compu science the first one is naming things variables functions
and whatnot and second one is cash and validation and this entire video is all about cash and validation and how what lashan did it now consider this that um a pretty standard way for people to use a cache is they have a source of Truth kind of my SQL postgress of the world right and they have a cash your red is Dice DV etc etc etc now the whole idea of cash invalidation is whenever the data changes in the source of truth how do you invalidate the cash that's the whole thing so that you don't
serve stale data for a longer duration that's why you need to invalidate the cash and that is what the entire discussion is going to be how and why are you trying to or are you trying to invalidate the cash now this entire thing is in the context of a service at atashian called tenant context service right we'll take a long time the diagram looks scary it's not it's not it's pretty simple I'll explain it step by step so this thing is a tenant context service which has its own source of Truth which is dynamodb it
has some sort of inje we don't need to worry about the internal details of it right it has some sort of injection workers which are doing rights into this Dynamo DV right consider this TCS API the tenant contact service API that whoever wants to know about the metadata talks to this API API server goes to the database reads the data serves it right so whoever wants to consume the TCS data this is the flow right okay now the code idea or the core paino of cash and validation happens when your inje workers are doing rights
onto the Dynamo DB the source of Truth is changed and this change needs to be percolated to the client of TCS service now what are this client now this entire Blue Block blue box that you see is one client of TCS that would be multiple such clients now each client is a consumer of TCS so the client would have its own set of customers this one and some application who is using TCS data and this T TCS data is typically now consider this as a one pod or one server in which you have a side
car and your main application side car is the one that is inter interacting with the TCS API to get the data right your server directly talks to sidecar to access the data quickly so this way your app the customer the client of TCS service this one the HTTP AP the web server of it can focus on serving it's request that it's wanting to and the side car is doing the grunt work of let's say fetching the metadata from the TCS API and this and that and whatnot right so this is how they are leveraging the
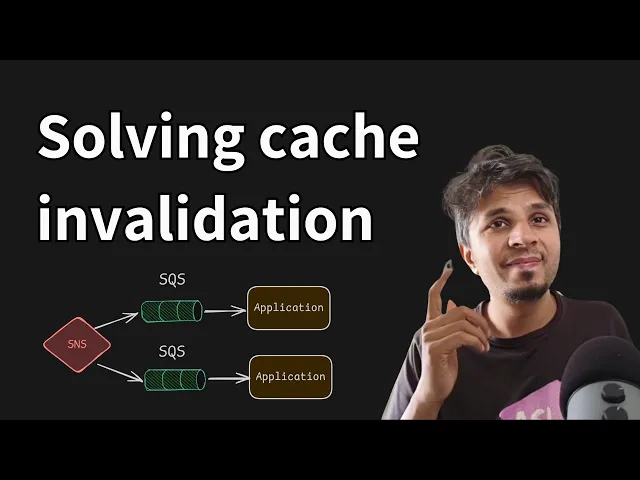
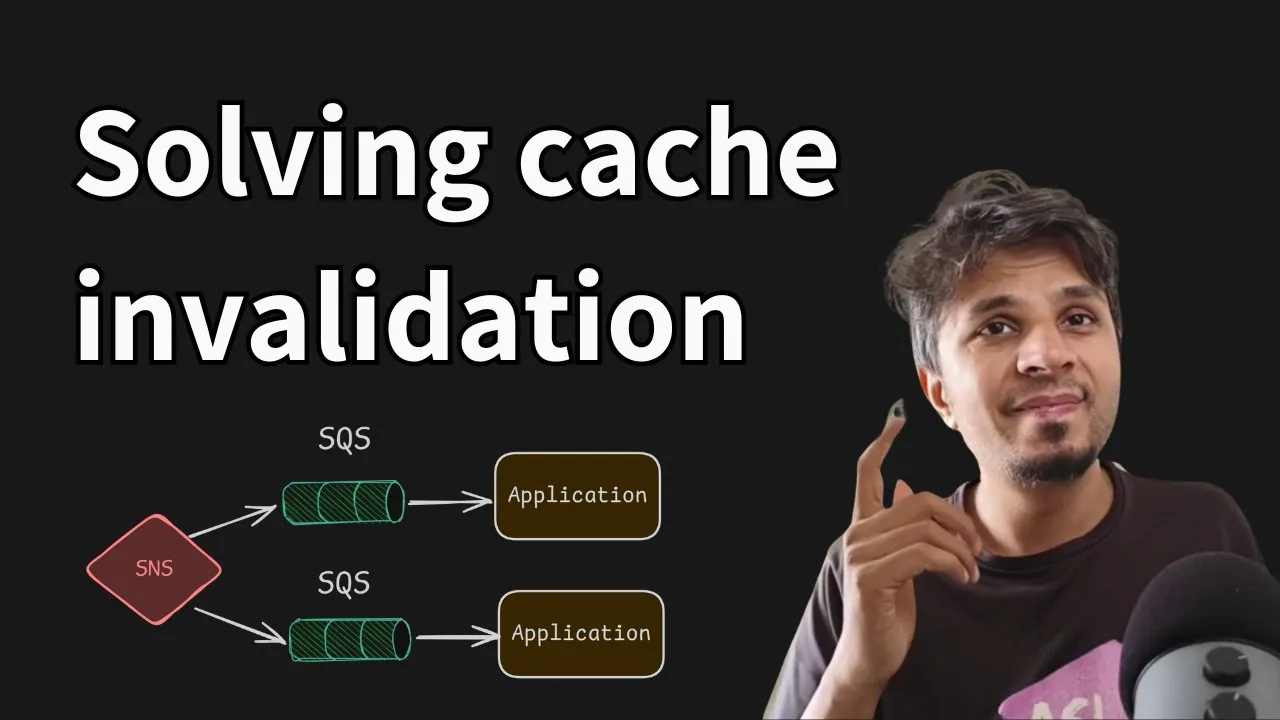
side car pattern right and the sidecar is responsible for quering the data over here and caching it over here and whatnot so the data is cashed on each side car it's not a centralized cache the data is cached on the side car this is the HTTP API server that is serving the request right now this is their flow now where does cash invalidation come in so when the right happens to the database right now the inje worker sends an invalidation request to an SNS topic right this SNS topic is subscribed by multiple sqs servers each
sqs server is consumed by one pod so one pod one sqs and SNS is taking care of broadcast and sqs is getting this invalidation event SAR is consuming the message from sqs and invalidating its local cach I'll repeat this entire flow once again when inje worker updates the database updates a source of Truth it sends an invalidation message to SNS SNS fans out to all the sqs that have subscribed to it one sqs is for one pod the side car of the Pod consumes a message from sqs it's a invalidation message and invalidates the local
copy of data this way when the subsequent request comes in for the key which is let's say it's invalided which mean it's not there in the cash or whatever has happened your side car will go to TSS API it will go to the server get the data cash it again and continue its processing this is the flow very obvious yes extremely obvious you can start seeing the problem with this that this approach is not scalable so first thing first you need one SNS topic per client of TCS so the more the number of clients of
TCS if there are n clients each client would require one SNS topic right that's one second you require one sqsq per compute node per pod per2 server that in itself sounds very weird right that why would you need to have one sqs for each ec2 server right that's that's a fun part right people start building it in first class and then they realize that at scale things don't work which is perfectly fine and that's what we all learn right from this mistake quote unquote mistakes right okay so one sqs per compute node right now imagine
when an invalidation happens right this invalidation message is also an event so some pad that you need to invalidate this thing now this message sent once to this SNS what if for this same key there would be multiple SNS topics that are interested in that so imagine there are M SNS topic to which the invalidation message is sent and each SNS topic has let's say n on an average com on an average sqs subscribed to it right so msns each one is sending n sqs messages so M into n is the total fan out that
happens which is humongous it's unnecessary cost that you are bearing because sqs builds you per message now imagine the time when there the rights are more if the rights are more the number of invalidation messages are more the number of invalidation messages are more which means the fan out the total number of messages being sent because M cross n is the fan out m is the total number of SNS topic each one having n sqs subscriptions M into n is the factor of fan out so every invalidation message is sent M cross n * and
during high right throughput or high right load the number of invalidation messages are higher so in that case your sqs starts to throttle the account level throttling that would happen that's the problem so lots of problem let's find a solution sorry okay here hey easy solution why send one message for every invalidation request let's just uh patch them so first thing first remember this thing uh whenever you see a potential uh batching like a potential to bat stuff always do that that's the lowest hanging fruit that you have and you should leverage it so you
instead of sending one invalidation message for every update try to batch the number of invalidation message and then send one message in one shot right and that reduces your fan Out imagine if you just wait for a for 1 second and let's say you get 10 messages in 1 second you literally have slashed your total number of messages by a factor of 10 which is pretty awesome so remember this whenever possible batch the request now batching helps you reduce burst traffic you reduce high F out as we discussed but what it does is it introduces
the delay in processing because now your inje worker is done a briting the database it needs to buffer the message over here for some time 1 second window and then send one message to SS so now SNS instead of getting one message for every single request every single invalidation request it's buffering it's batching and then getting one request that contains 10 invalidation messages kind of right so you are batching it's a good solution but you are still not avoiding one sqs per compute node problem so batching is slashing your number of messages all good but
having one sqsq per compute node seems criminal to be really honest so it's tedious it's complex it you will very soon hit AWS account limits and whatnot so how do we solve it now here we'll go with the framework of opposes push versus pull so up until now what we were doing is Here If You observe the data got updated you push the message to SNS SNS pushed the message from sqs this one pulled from it so you are proactively pushing the invalidation to be done as soon as possible right so instead of push can
we pull so with batching can we pull so what they did is they re architected their solution they are still doing batching because it reduces the number of invalidation messages that needs to be processed so that's a good thing right so what they do is now when they batch they put this batch on S3 and the side car periodically so earlier sidecar was listening from uh listening to sqs and then invalidating its local copy now sidecar talks to S3 reads the data message in which it gets all the invalidation messages is that needs to be
acted upon and then invalidates the local copy of data so from a push paste architecture we move to a pull based architecture trying to get a benefit out of it and this is a revamp that they did again it sounds pretty uh obscure to think about it like why on Earth would they do this in the first shot but that's how they have that's what their architecture was and then they solved it now few key takeaways that we understand and again these are uh very essential when you're are starting and your company scales how things
work so first thing first your infrastructure cost can escalate very quickly at scale because imagine this um the more the client of TC uh the more the client of tenant contact service happens your fan out of messes is increasing right so although it looks like a pretty simple system to implement but your infra cost can scale very quickly if you do not have things in control that's why second this is the most most critical one your knife solution which you employed or you deployed on your day Zero works fine all good but keep an eye
on scalability keep an eye that hey what would happen when we skill we typically think it's if it's working it's working I won't take a look at it right but is it really the case is it really the case the amount of cost that you're bearing is it worth it the amount of time you're taking in processing is it worth it so keep in mind to visit your previously deployed service running for a very long time to see if there are any potential improvements that you can do and things are under the managed SLA with
respect to cost performance durability all the buzz wordss whatever you want to think and more importantly be ready to re architect Your solution keep an eye on the cost keep an eye on the convenience keep ey on the maintainability and see if You' want to rear it does not mean you go ahead and re architect every few months that's a waste of time but if there's a need that your cost or convenience or maintainability is going for a toss you go ahead and be ready to re architecture solution so here we saw how we or
how atashian converted their push based stuff into pull Bas stuff that's a complete change of access pattern right but was it worth it yes because now the infrastructure is pretty much scalable you don't need one sqs per compute node and whatnot that makes your life super easy and yes this is all what I wanted to cover today all the important links this is taken from an atashian blog this is uh you'll find this link in the iard top or below the description is where you'll find this link I highly recommend check this out apart from
this uh check out my courses I conduct highly practical courses on system design completely no fluff it's not about drawing boxes it's about digging deeper into implementation detail production nuances and all it's a pretty fun course I've been doing it for four years I have a time of my life every Saturday Sunday I wake up to that and have a lot of brainstorming with lot of great folks so if you want to learn system design the right way hop along the links are in the description check that out and yeah like always do like share
and subscribe and spread the word on socials be curious engineering is beautiful uh dig deeper uh Implement whatever you're reading and more importantly have fun [Music]