[Music] hello everyone welcome to this lecture in the build large language models from scratch Series in the last lecture we looked at the intuition behind the attention mechanism and we saw the limitations in the recurrent neural networks which prompted The Invention which is at the heart of the attention mechanism in today's lecture we are going to look at The the mathematical foundations behind attention and we are also going to code out a very simplified version of the attention mechanism from scratch in Python so I'm calling this simplified U simplified self attention mechanism without trainable weights
before we proceed to the content of the today's lecture here are the lecture notes which we covered previously in our introductory lecture on attention so if you have not seen This lecture I highly encourage you to go through the lecture to understand the intuition that way you will appreciate today's lecture much more in the last lecture I also showed I also told you the plan which I have to cover attention in this series of lectures I strongly believe that it is impossible to cover everything related to the attention mechanism in one video or even two
videos so I've planned a set of uh three to four different videos to cover this Entire concept the the way I'll be doing this is that first in today's lecture I'll be going through the simplified self attention mechanism without any trainable weights just to introduce the broad idea then in the next lecture we'll move to self attention with trainable weights the way it's done in modern llms including GPT then we'll move to causal attention and then finally we'll move to multi-head Attention all of these will be separate series of lectures and in each lecture we'll
I'll show you the mathematical foundations on this white board and then we'll code out the attention mechanism showed in that lecture from scratch in Python so if you have got this overall workflow let me go to the lecture notes of today's lecture and we'll get started awesome so the main goal which we have today is to implement a simple Variant of the self attention mechanism which does not have any trainable weights which is free from any trainable weights so to motivate today's lecture let's start with a simple sentence in the whole of today's lecture we'll
be dealing with this sentence which is your journey starts with one step now if this sentence is given to a large language model there are number of things which are done first we will be pre-processing this sentence we'll take this sentence We'll convert it into individual tokens GPT uses the bite pair encoder which is a subw tokenizer so it will convert these tokens and then then we'll have token IDs for each of these tokens then that token ID will be converted into a vector representation which is also called as a vector embedding so each of
these word will have a vector embedding in a higher dimensional space when we deal with llms like GPT the dimensional space can be as High as 500 700 or even more than thousand dimensional Vector space but for the sake of today's demonstration we'll be considering a three-dimensional Vector space so here's how these vectors can look like for each word in the input sentence we have a vector in the three-dimensional space these vectors are not just normal vectors they capture the semantic meaning of each word so Words which are semantically related to each other like let's
say cat and puppy Cat and kitten dog and puppy will be closer to each other um so you might be thinking that okay this is pretty cool and this can be the input to the large language model then why do we need attention the main problem here is that let's say if we look at Journey what the vector embedding does is that the high dimensional projection of this word does capture the meaning of this word itself but it does not contain any information About how this word Journey relates to other words in the sentence how
much is the relative importance between your and journey starts and journey with and journey one and journey and step with respect to Journey the embedding Vector does not contain any of this information and this information is very crucial for us to know if this sentence appears in a large body of text and we want to predict the next word we really need to know the Context we need to know that which word in this sentence is closely related to Journey let's say that will really help us predict the next word in other words we need
to know how much attention should we pay to each each of these words when we look at Journey that's where attention mechanism comes into the picture so the whole goal of the attention mechanism is to take the embedding Vector for uh take the vector embedding for Journey let's say and then Transform it into another Vector which is called as the context Vector the context Vector can be thought of as an enriched embedding Vector because it contains much more information it not only contains the semantic meaning which is the embedding Vector also contains but it also
contains information about how that given word relates to other words in the sentence and uh this contextual information really helps a lot in Predicting the next word in large language model tasks one such context Vector will be generated from each of the embedding vectors so if you look at all of the embedding vectors which I have shown here we'll have a corresponding context Vector for each of these embedding vector and that is the main purpose or that is the main goal of attention mechanism even the simplified attention mechanism Which we are going to consider today
and even the complex multi-head attention which is used in modern large language models the goal of all of these mechanisms is the same we need to convert the embedding Vector into context vectors which are then inputs to the llms so let's get started with accomplishing this aim of converting the embedding vectors into context vectors so here's the input Vector which we have Your journey starts with one step each of this each of the tokens is converted into a threedimensional vector it's called as a vector embedding and the notation which we are going to use is
we are going to denote X for the inputs so X1 will be the vector representation of the first token X2 will be the vector representation of the second token X3 will be the vector representation of the third token and these will be threedimensional tokens for the sake of Simplicity throughout this lecture when I use the word token and word I'll use tokens and words interchangeably normally one token is not equal to one word because GPT uses a subword tokenizer but for the sake of Simplicity I'm going to use tokens and words interchangeably in today's lecture
so let's say if we look at Journey the input embedding Vector is X2 two because it is the second word our main aim uh in this lecture is to Essentially create a context Vector so the context Vector for X2 will be denoted by zed2 similarly we need one such context Vector for all the input vectors and to compute the context Vector from the embedding Vector we'll need to have information about how much in importance needs to be given to X1 which is the word your how much information needs to be given to X3 and how
much information needs to be given To all the other word when we are looking at Journey For example and this is captured by this metric which is called as attention weights so we need to decide how much attention we we need to give to each input token when we are Computing the context Vector for any uh embedding vector and based on these attention weights we will finally derive the context Vector which is denoted by Zed so we'll see mathematically how to Uh manipulate the attention weights the input vector VOR we'll also see what are attention
scores and how to get the context Vector for each of the given embedding vectors but I hope until now you have understood the task or the aim which we have in today's lecture and as I mentioned the representation or the notation which will be which we will be following is that for the inputs we'll be using X so X of one will be the token embedding one which is the vector representation of the first token X of two will be the token embedding two which is the vector representation of of the second token Journey Etc
so these are three dimensional embeddings in the example which we are considering in today's lecture now uh I have just written down the goal which I was talking about the goal of today's lecture or the goal of any attention Mechanism is to basically calculate a context Vector for each element in the input and as I mentioned before the context Vector can be thought of as an enriched embedding Vector which also contains information about how that particular word relates to other words in the sentence okay so let us get started and we'll dive into code right
now so here's the Jupiter notebook file and I'll be sharing this file with you and uh we'll Get started implementing a simplified attention mechanism in Python so let's start taking a deep dive into this code so uh we are going to consider threedimensional embedding vectors and the the reason we are choosing this small Dimension is just for illustration purposes to ensure that uh we do not consider an very complex example and confuse everyone but the learnings which we are going to have today can easily be Extended to a higher dimensional Vector space also so we
have the inputs tensor which is inputs equal to torch do tensor and for every input token we have a embedding Vector which is a three-dimensional vector Vector so for the token or the word y we have this three-dimensional Vector for the word Journey we have this three-dimensional Vector for the word starts we have this threedimensional Vector right up to step We have this three-dimensional Vector so there are six threedimensional vectors which we are considering over here and uh I have just plotted these vectors here in in the threedimensional vector space for you to have a
look these Vector embeddings capture the semantic meaning so journey and starts will be bit more closer to each other because they are semantically more related than let's say journey and other words so this is how the vectors look like in 3D Space uh there is no reason to plot this graph you can do this entire exercise without these visuals but the reason I wanted to show you this is because when I learned about Vector embeddings for the first time I was really fascinated by the concept that words can be represented as vectors uh it seemed
very surprising to me that how can words be represented mathematically as vectors but when I saw this I really was I really liked the concept so visual Understanding helps and that's why I'm showing you this plot so if someone is not familiar with natural language processing and your intuition is not developed in this space such plots can really help you visualize things which you will never forget so Vector embedding becomes much more easier if you have visuals like these okay now let's move to the next step uh first let's look at this tensor and let's
try to understand what each row and each Column of this tensor actually represents so each row of this tensor represents each token so the first row is the first token or the first word Etc and each column represents that particular Vector Dimension there are three dimensions and hence there are three columns okay now uh we'll be moving to the next aspect which is discussing a bit about query and what exactly are query Um so now what we'll be doing is that we'll be finding a context Vector for each element so if you look at um
this sentence right here we'll be finding a context Vector for each of the embedding vectors but for the sake of demonstration we are going to start with journey so we are going to exclusively look at Journey right now and we are going to find the context Vector for Journey and then we are going to to apply the same analysis to all the other Words in this sentence uh so now as I mentioned we'll be focusing on the second element which is X of two why two because it's the second element of X so X1 is
the first element X2 is the second element so we are looking at X2 because we are looking at the word Journey the element or the token which we are looking at right now it's also called as the query and since we are looking looking at the token Journey that becomes the Query this uh terminology will also show up later when you look when we look at multi-head attention mechanism but for now uh just keep in mind that we are looking at this uh token journey and that becomes our query and the corresponding context Vector for
this query which is X2 will be Z of two and that is essentially an embedding which contains information about X2 and all the other input elements so this context Vector not only Contains information about that particular word which is Journey but it also contains information about all the other input elements again I would like to emphasize here that in this lecture we are not looking at trainable weights later we are going to add trainable weights which is how it's actually done in llms because this helps the llms to understand the context text much better and
learn in a better Way uh okay now we have this task that we we have a query which is the word journey and the task is to convert this the embedding Vector for journey into a context Vector the first task the first step of implementing this task is to compute the intermediate values W which are also referred to as the attention scores so the first task is to basically do the following we have a query which is the word journey and we have all these other input words Right now what we have to quantify basically
is that how much importance should be paid to each of these other words or how much attention should be paid to each of the input word for the query journey and this is Quantified by a mathematical metric which is called as the attention score so the attention score exist exists between the query and every input Vector so there will be an attention score between the query and The first input Vector there will be an attention score between the query and the second input Vector there will be an attention score between the query and the third
input vector and finally there will be an attention score between the query and the final input Vector the first step of getting to the context Vector is to find these attention scores which will help us understand how much importance should be given to each of the tokens in the Input okay for a moment assume that you do not know anything about large language models you do not know anything about machine learning or natural language processing just assume that you are a student who is Guided by intuition and Mathematics and try to think of this question
you have this input query X2 and you have these other embedding input embedding vectors how would you find the importance of every input Vector With respect to the query that's the question so you have the query vector and you have each of these embedding vectors X1 X2 dot dot dot right up till the final input Vector how would you find a Score which quantifies the importance between the embedding between the query vector and the input embedding Vector can you try to think about this intuitively forget about everything else forget about ml forget about attention just
try to think From the basics what is that is that mathematical operation which you will consider to find the importance between two vectors let me ask you this question in another way as a hint take a look at this Vector embedding you know that vectors are embedded in like this in a three-dimensional space now let me ask you we have the query Vector which is and we have all these other input Vectors for step your with one and starts how would you find the importance of all the other vectors with respect to the query Vector
which is Journey you can pause the video here for a while while you think about it let me give you a hint if I rephrase this question in another manner I'm sure many of you will be able to answer what is that mathematical operation which gives you the alignment between the two Vectors which mathematical operation lets you find whether two vectors are aligned with each other or whether they are not aligned with each other keep that thought in your mind now let me nudge you more towards the answer now we know that uh the embedding
vectors encode meaning right so if two vectors are align to each other which means that they are parallel to each other or if their angles are closer to each other like journey and start it Implies that they have some sort of similarity in their meaning so it makes sense that more importance should be paid to start Vector because it seems to be more aligned with the journey Vector whereas if you take the vector corresponding to one this purple Vector at the bottom you'll see that it's almost perpendicular to the journey Vector right the vector one
is like this the vector journey is like this so it's almost perpendicular which means that They do not have that much similarity in meaning so when we assign importance probably the vector corresponding to one should have less importance than the vector corresponding to starts for the query Journey because starts is more aligned to Journey now can you think which mathematical operation would quantify this alignment let me reveal the answer it's the dot product between the vectors this This is an awesome idea because Let Me Now go to Google and type dot product formula if you
see the dot product formula it basically the if you take the dot product of the two vectors it's the product of the magnitude of the vectors multiplied by the cosine of the angle between them so if the two vectors are aligned with each other that means the angle between them is zero and if the angle between them is zero cost of 0 will be one so the dot product will be Maximum whereas if the two vectors are not all aligned with each other that means they are perpendicular to each other the angle between the two
vectors is now equal to 90° and COS of 90 is equal to 0 so there is no similarity between these vectors and the dot product is zero so higher the dot product more aligned the vectors are lower the dot product the vectors are not aligned so the dot product actually encodes the Information about how aligned or how not aligned the vectors are and that's exactly that's exactly what we need so the dot product between journey and starts might be more so it's because they are aligned so what if I use the dot product to find
the attention scores that's the first key Insight which I want to deliver from this lecture what if I use the dot product to find the attention score between my query vector and the input Vector this is a key step in understanding the attention mechanism the dot product is that fundamental operation because it encodes the the meaning of how aligned or not how not or how far apart the vectors are and this is exactly what we are going to do next so the intermediate attention scores are essentially calculated between the query token and each of the
input token and the way the attention scores Are calculated is that we take a DOT product between the query token and every other input token why do we take a DOT product because the dot product essentially quantifies how much two vectors are aligned if two vectors are aligned their dot product is higher so more attention should be paid to this pair of vectors so their attention score will be higher so in the context of self attention Mechanisms dot product determines the extent to which elements of a sequence attend to one another this is just a
fancy way of saying how different elements of the sequence are more Alik with each other so higher the dot product higher the dot product higher is the similarity and the attention scores between the two elements this is very important higher the dot product higher is the similarity between the two Elements or the two vectors and higher is the attention score a fancy way of describing two vectors which are aligned to each other is saying that these two tokens attend more to each other whereas if the two vectors are not not aligned we can say that
these two attend less to each other for example just visually we can see that journey and starts are aligned right so these two vectors attend more to each other so more attention should be paid to starts when The query is Journey and if you look at the vector one and the vector for Journey you'll see that they are not aligned they have a 90° angle between them so they do not attend to one another this is the key idea behind calculation of the attention scores and this is exactly what we are going to implement in
the code right now so to compute the attention score between the query vector and the input Vector we simply have to take the dot product Between these two vectors so let's say the query is inputs of one why inputs of one because python has a zero based indexing system and since our query is the second input token uh the second input token remember is for a journey it will be indexed with one because python has a zero indexing system so inputs of one will be the vector for Journey so let's say the query is the
inputs of one and then the attention scores need to be calculated So first we initialize the attention scores as an empty tensor then what we'll do is that we Loop over the inputs we'll Loop over the inputs and we'll take the dot product between every input vector and the query Vector that's it and then we'll populate the attention scores tensor so the first element of the attention scores tensor is the dot product between the first input embedding vector and the query Vector the second element of the attention Scores tensor is the dot product between the
second input vector and the embedding Vector similarly the Sixth Element in the attention score tensor is the dot product between the sixth input vector and the query Vector so each of these element each of the elements of the attention score is a DOT product between the input vector and the query Vector now let us actually look at these attention scores a bit and try to uh look at their magnitudes right so which Which of these have the largest magnitude so we can see that this second second value the third value and the sixth value have
the largest attention scores so second third and six so let's see the which which words they correspond to so second is the word journey Third is the word starts and sixth is the word step so of course Journey has the high attention score right because the query itself is Journey so if the query itself is Journey it will be aligned with the vector for Journey and so it will have the highest dot product but the second and the third highest dot products are for starts and step and let's see whether that follows our intuition so
as we had earlier seen starts is also very closely aligned with journey so it makes sense that the dot product between journey and starts is higher so the attention score for starts is higher similarly when you see step You'll see that step also seems to be closely aligned with journey their angles seem to be similar and so the attention score between step and journey will also be higher now let's look at the elements with the lowest attention score so it seems to be the fifth element and the fifth element is the word one and let's
see whether that makes sense with our intuition so you can see the vector for the word one and the vector for Journey Almost have a 90° angle between them they are not at all aligned with each other and that is exactly captured in the attention score that seems to be the least between journey and one so every time you deal with attention scores try to have a mental map of why exactly is the attention score higher or why exactly is the attention score lower now we'll move to the third step or the next step rather
before we comp compute the context vector and that Step is normalization why do we really need normalization the most important reason why we need normalization is because of interpretability what does that mean well what it means is that when I look at the attention scores I want to be able to make statements like okay give 50% attention to starts give uh 20% attention to step and give only 5% ATT attention to the vector one so when the query is Journey I want to make these Kind of interpretable statements in terms of let's say percentages that
if the query is Journey of course Journey will receive 20% attention 30% attention but starts will also receive higher attention maybe 30% maybe step receives 20% attention and the rest of the vectors remain receive less percent if I'm conveying this to someone they will get a much better idea right if I convey in terms of these percentages so I want my attention scores to be interpretable And they are not right now because if you sum up the attention scores they are more than one so we cannot express these in terms of percentages and that's why
we are now going to normalize the attention scores uh now first okay so the main goal behind the normalization is to obtain attention weights that sum up to one that's the main goal and why do we do this as I mentioned it's useful for interpretability um and for making Statements like in terms of percentages how much attention should be given Etc but the second reason why we do normalization is because generally it's good if things are between zero and one so if the summation of the attention weights is between zero and one it helps in
the training we are going to do back propagation later so we need stability during the training procedure and that's why normalization is integrated in many machine learning framework It generally Helps a lot when you are back propagating and including gradient descent for example so uh what is the simplest way to implement normalization can you try to think about it remember we want all of these weights to sum up to one so what is the best way you can normalize this you can pause the video for a while if you want okay so the simplest way
to normalize this is to just sum up these Weights and then divide every single element by the sum so what that will do is that will make sure that the summation of all the attention scores will be equal to one and this is exactly what we are going to implement as the simplest way to normalize so what we'll do is that we'll maintain another tensor which is attention weights to that will just be the attention scores divided by the summation so what will happen is that Every element of the attention score tensor will be divided
by the toal total summation and so the final tensor which we have which are also called as the attention weights will be this it will be 0455 2278 2249 Etc and you'll see that they sum up to one here I would like to mention one terminology and that is the difference between attention scores and attention weights both attention scores and attention weights represent the same Thing intuitively they mean the same the only difference is that all the attention weights sum up to one whereas that's not the case for attention scores so if you take the
summation of these attention weights you'll see that it is equal to one um okay this is great so you might think awesome what's the next step well it's not that great because uh there are better ways to do normalization many of you might have heard about soft Max Right if you have not it's fine I'm going to explain right now but when we consider normalization especially in the machine learning context it's actually more common and advisable to use the softmax function for normalization and why is this the case um I think I need to write
this down on the Whiteboard to explain um why soft Max is preferred compared to let's say the normal summation especially when you consider Extreme values so let me take a simple example right now and I'm going to switch the color to Black so that you can see what I'm writing on the screen so let's say the element which we have are 1 2 3 and nine uh or let's say 400 let's say these are the elements 400 now if you do the normal summation uh and normalize it that way what will what will happen is
that 1 will be Divided by all the entire summation right so the first element will be 1 divided by 1 + 2 + 3 + 400 which is 406 uh so the denominator here will be 4 0 6 then the last element similarly would be the highest element which is the extreme value which we are considering here this highest element will be 400 divided by 406 so I'm just writing the denominator Right now yeah so the last element which is the extreme value will be 400 divided 46 and this element will be 2 divided by
406 and this element will be 3 divided 46 so you might think that okay what is the problem here the problem here is that when we look at the inputs 400 is extremely high right so the normalization should convey this information that you should completely neglect these other values so ideally when such a situation occurs we want the Normalized values to be zero for these smaller values and we want the normalized value to be one for this extremely high value and that's not the case when you use the summation operation when you do the summation
this normalized will be around let's say uh I not I'm not calculating this exactly but let's say it's 0 point uh 0 0 25 and let's say this this calculation For the extreme value is let's say around uh Point uh 9 let me write this again so this will be let's say around 0.9 9 just as an example so you might think that okay this is almost close to one right but it should not be almost close to one it should almost be exactly equal to one the reason why this is a problem is that
when you get values like this They are not exactly equal to zero so when you are doing back propagation and gradient descent it confuses the optimizer and the optimizer still gives enough or weight some weightage to these values although we should not give any weightage to these values so ideally the normalization scheme should be such that when we normalize the small values should be close to zero in such a case and the extremely large values should be close to one and that is not achieved Through this summation based normalization however this exact same thing is
achieved if we do a softmax based normalization so let me explain what actually happens in the softmax based normalization so we currently have the attention scores like these right we have X1 X2 dot dot dot up till X6 in the softmax what happens is that we take the exponent of every element and then we divide by the summation of the exponents So the denominator the summation is e to X1 plus e to X2 plus e to X3 plus e to X4 plus e to X5 plus e to X6 so the first element will be e
to X1 divided by the summation the second element will be e to X2 divided by the summation and similarly the last element will be e to X6 divided by the summation now if you add add all of these elements together you'll see that they definitely sum up to one that's fine but the more important thing is when you look at These extreme cases if you in if you use soft Max 400 now when you do e to 400 that will almost be like Infinity so this value when normalized will be very close to one and
the smaller values when normalized using softmax will be very close to zero so it's much better to use softmax when dealing with such extreme values which may occur when we do large scale uh models like llms that's why it's much more preferable to be using soft Max now we can easily code such Kind of a soft Max in Python ourself but it's much more recommended to use the implementation provided by py torch so what py torch does is that instead of doing e to x divided by the summation it actually subtracts the maximum value from
each of the values before doing the exponential operation so the first element will be e to X1 minus the maximum value among X1 X2 X3 X4 X5 X6 divided by the summation and the summation will be e to X1 - Max Plus e To X2 - Max Etc so the only difference between pytorch implementation and the naive normal implementation we saw before is that pytorch includes this minus maximum so it subtracts all the values by the maximum value uh before doing the exponent IAL operation now mathematically you'll see that when you expand this e to
X1 minus the maximum it can also be written as e to X1 divided e to maximum so the E to maximum in the numerator and denominator Actually cancels out and the final thing what we get is actually the same thing as what we had written previously so you might be thinking then why is this even implemented this subtracting by the maximum the reason it's implemented is to avoid void numerical instability when dealing with very large values or very small values if you have very large values as in the input or very small values It generally
leads to numerical instability and leads to errors which Are called overflow errors this is a computational problem so theoretically we can get away with this implementation which is on the screen right now but when you implement computation in Python it's much better to subtract with the maximum to prevent overflow problems I have seen some companies in which this is also asked as an interview question so it's better to be aware of how pytorch Implement softmax and we'll be doing both of these implementations In the code right now so let me jump to the coding interface
as I said the first thing which we'll be implementing is naive soft Max without dealing with the Overflow issues without subtracting the maximum value um so what we'll be doing is simply taking the exponent of each attention score and dividing by the summation of the exponent the dimension equal to Z is used because we are taking the summation for a full row so we are Essentially summing all the entries in a row and that's why we have the dimension equal to zero why are we summing the entries in a row because if you look at
these Matrix over here um yeah this X1 X2 X3 X4 X5 and X6 this is one row right and when we calculate the summation we are going to do e to X1 plus e to X 2 Etc so we are essentially summing all the entries in a row and that's why we have to give Dimension equal to zero as an exercise you can try out Dimension Equal to one and see the error which you get so this is how we'll implement the knive soft Max and uh which will basically take the exponent of each attention
score and divide by the summation so we'll print out the attention weights obtained using this method and you'll see that it's 1385 dot dot do1 1581 of course these scores are different than the summation because here we are using the exponent operation but if you sum up these scores you'll See that they also sum to one that's awesome and now what we'll be doing is we'll be using the P torch implementation of soft Max one more key point to mention is that the soft Max attention weights which are obtained are always positive because we always
deal with the exponent operation and that's positive the positivity is important to us because it makes the output interpret so if we want to say that give 50% attention to this Token give 20% attention to this token we need all the outputs to be positive right if it's not positive well uh it's it becomes very difficult to interpret in that case uh now um so note that knife softmax implementation May encounter numerical instability problems which I mentioned to you such as overflow for very large values and underflow for very small values therefore in practice it's
always advisable to use the pytorch Implementation of soft Max so it just one line of command torch. softmax and we pass in the attention score tensor and what this one line of command torge do softmax actually does is that it implements um what I'm what I've shown on the screen right now it implements this e to X1 minus maximum Etc this it converts the input into this normalized format so this is tor. softmax and you can quickly go to the documentation to See tor. softmax and you'll see the py torge documentation for for softmax I'll
be sharing this link also with you uh in the information section of the YouTube video okay so this is basically pytorch softmax and we have got these attention weights and we'll see that the attention weight up to one one thing I want to show is that our knife soft Max results in this attention weight tensor and the pytorch softmax also results in the exact same attention weight tensor since We don't have any large values or any small values we don't have any overflow or underflow issues here and so both our knife implementation and the pytorch
implementation give the same results but the reason it always advisable to use py torch is that later we'll be dealing with very large parameters and some of those might be huge so it's better to um have numerical or better to deal with numerical instability awesome so remember the one Reason why we calculated the attention weights is for interpretability right now let's try to interpret so the attention weight for the first Vector is around .13 the attention weight for the second is 2379 attention for the third is 233 Etc this means that we should pay about
13% attention to the word your about 23% attention to Journey about 23% attention to starts 12% attention to with uh with one 10% Attention to one and 15% attention to step so high attention is being paid to journey and starts so as you can see here High attention is paid to journey and starts and if someone asks how high we can can say that well about 20% and low attention is paid to one and if someone asks how low we can say that well only 10% we are able to make this interpretable statements only because
we converted the attention scores into Attention weights and remember that's the difference between attention scores and attention weights attention weights sum up to one so it's much easier to make this kind of interpretable statements so we have computed the attention weights right now and we are actually ready to move to the next step which will which is actually the final step of uh Computing the context Vector so let me take you to that portion of the Whiteboard right now so After Computing the attention weights now we have actually come to the last step of finding
the context Vector so let me just show you the image of what all we have covered up till now so we had this input query we computed the attention scores by taking the dot product between the input query and each of the embedding vectors and from the attention scores we actually got the normalized attention scores which are called as attention weights and these Attention weights actually sum up to one awesome so we have reached this stage right now and now we are ready to get the context Vector I just want to intuitively and Visually show
you how we calculate the context vector before coming to the mathematical implementation so let's say these are the embedding vectors for the different words in the sentence and here I've also mentioned the relative importance of each so Journey carries 25% importance because that's the query so it should carry the highest importance but starts carries 20% importance um then step carries 15% importance and one with and your carry less importance now how do we get these how do we use these attention weights to compute the ultimate context Vector so the way this is done is that
let's say we use starts so the starts Vector is now multiplied by the attention contribution and that Is equal to 02 right because 20% is important so it's importance is 20% so the starts Vector is multiplied by 02 which means it scaled by by the corresponding attention attention weight so the starts Vector is multiplied by 02 so it will be scaled down like this the width vect width Vector is scaled down by 15 because it carries 15% importance the step Vector carries 15% importance the journey Vector carries 25% importance so it will it will be
scaled Down by 1/4 uh and the one vector carries only 10% importance so it will be scaled down by a lot which is about 1110th now what will and similarly your carries 15% importance so it will be scaled down by multiplied by5 so what we do is that we multiply each of the input embedding vector by the corresponding attention weights and we scale them down that much so now we have uh the multiplied weights for each Of these and we take the vector summation of all of these and you add the vector summation and that
gives the final context Vector like this so this is now my cont context Vector for Journey so this is the context Vector let me write it down again okay so let me explain this again so we have calculate we have multiplied each of the input embedding Vector with the corresponding attention weight and we have got these six vectors right we Sum up all of these six vectors and that uh now describes the context vector and this I'm just writing here context this is the context Vector for the embedding Vector of Journey now look at how
this context Vector is calculated the context Vector has some contributions from all other vectors so it's an enriched embedding Vector it has 25% contribution from the embedding Vector but it has all the other contribution from other vectors And those contributions symbolize something those contributions symbolize how much importance is given to the other vectors for example we have about 20% contribution from starts because the attention weight to starts is 0.2 we have only 10% contribution from one because the attention weight for one is 0.1 and that's why context vectors are so important I wanted to show
this to you visually because the context Vector which will calculate for modern llms for Large scale models like GPT they carry the exact same meaning they are enriched embedding vectors so the context Vector for Journey looks like this and we can also see this in code so I have just written a small code to find the to plot the context Vector I'll show the mathematical derivation but for now just take a look at this context Vector for Journey which has been shown in Red so the vector embedding for Journey has been shown in green but
the context Vector is shown in red which is the summation of all the other vectors which I just showed to you and this is how it looks like in the three-dimensional space ultimately we are interested in these context vectors and it was only possible to get this context Vector because of the attention mechanism that's why the attention mechanism is so important we would have been stuck at the embedding Vector if we did not have the attention Mechanism now let us look at the mathematical representation um regarding how we actually compute the context Vector from the
attention weights and if you have understood the Whiteboard description which I just showed you understanding the this mathematical operation will actually be very easy okay so we have reached this stage now where we have computed these attention weights and after Computing The normalized attention weights what we'll do is that we'll compute the context vector and currently we're looking at the context Vector for Journey so it's Z2 and to do that we'll multiply all the embedded in input tokens with the corresponding attention weights this is very important and so that was the scaling which I showed
you in the figure and then we will sum up all of the resultant vectors when we sum up all of the Resultant vectors that will give us the final context Vector for the token journey and this has been showed in this schematic right now let me just rub rub this here so that I can explain this to you in a better manner okay so we have the attention weights for every token right so we have1 2 Etc so what we'll do is that for the first input embedding we'll multiply the attention weight with this Vector
for the second input embedding We'll multiply the attention weight for the second input embedding with the second Vector we'll multiply the third attention weight with the third input embedding and similarly we'll multiply the sixth attention weight with the sixth input embedding this is scaling down the vectors in the victorial representation and then we'll add all of them together when we add all of them together we'll ultimately get the context Vector for Journey and this is The final answer this is the context Vector for Journey and I've have plotted this context Vector over here which has
been calculated through this uh mathematical operation which I just showed you on the screen and now we'll be implementing this operation in Python to calculate the context vector and it's pretty simple it's only two to three lines of code first we have the query which is the inputs index by one because the word Which we are looking at is Journey then we initialize uh tensor context Vector two why two because we are looking at the second token journey and we are finding the context Vector for that so what we'll be doing is that we'll be
looping through all the inputs and uh what we'll be doing is that we'll scale each input with the corresponding attention weight and then we'll add all the scaled vectors together to give the final context Vector that's it so let's say we are looking at the first input Vector which is the first input embedding we'll multiply it with the first attention weight then we'll look at the second input Vector we'll multiply it with the second attention weight then we'll look at the sixth input Vector at the end and multiply it with the sixth attention weight and
we'll add all of these vectors together which ultimately leads to the final context vector and that's The one which I've showed here in the red arrow I've also shown the any context here as a ping Dot and how it's different from the other vectors awesome so we have reached this step where we have calculated the context Vector for Journey right however the task is not yet over because we have to calculate a similar context Vector for all the other tokens right we have to calculate the similar context Vector for your journey starts with one step
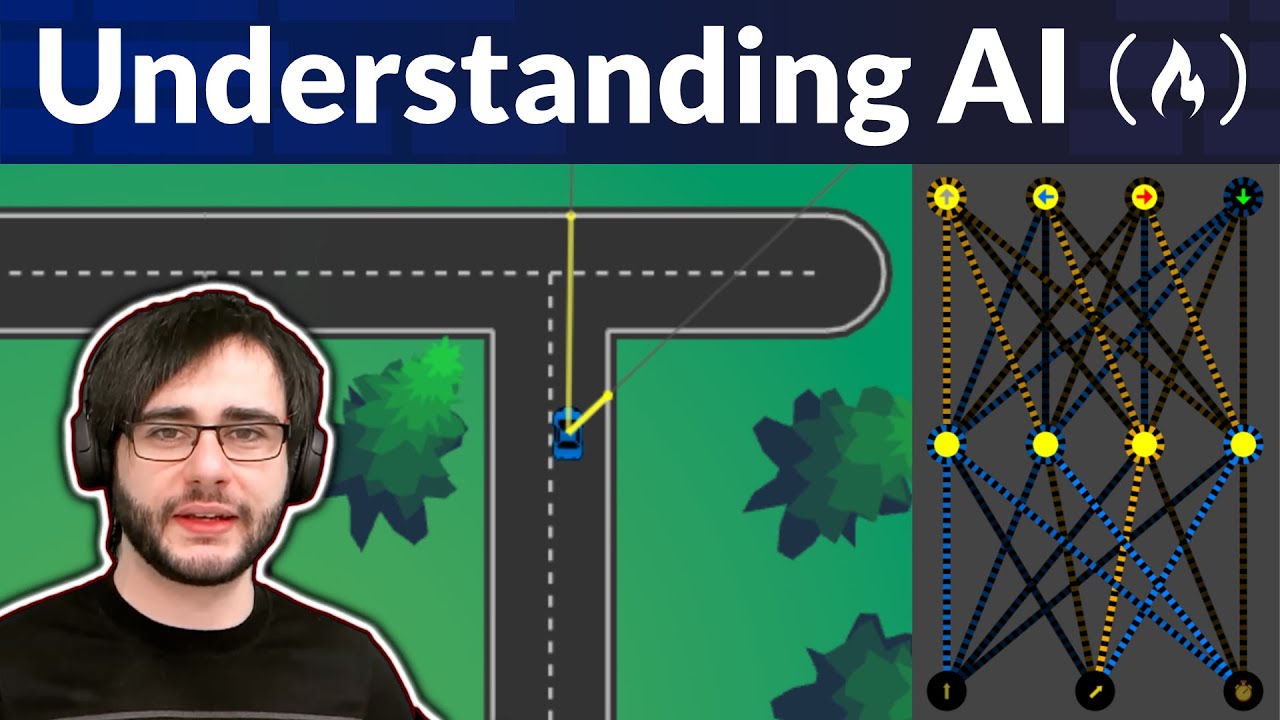
All of these six words and now if you have understood this computer comput which we did for Journey we can actually extend the exact similar computation to compute the attention weight and context Vector for all the other inputs and this is actually represented very nicely with this which is called as the attention weight Matrix so what the Matrix which you're seeing on the screen right now is called as the attention Weight Matrix and let me explain uh this Matrix in a very simple manner so if you look at the rows each row represents the attention
weights for one particular word So currently we have calculated the attention weights for Journey right so the first value here 13 is the attention score or the attention weight between journey and your the second value here 23 is the attention score or the attention weight Between journey and journey the second value here is the attention weight between journey and starts the fourth value here is the attention weight let me yeah the fourth value here is the attention weight between journey and width the fifth value here is the attention weight between journey and one and the
sixth value here is the attention weight between journey and Step so these are the sixth atten ention weights which we also computed over here so these are the six attention weights which have been computed here we have just rounded off the values so the values might not be exactly similar but these are the uh these are the six attention weights okay now um let us go next okay so similarly what we have to do is we have to find essentially similar attention weights For all the other words like let's say if we look at starts
we have to find six attention weights for starts we have to find six attention weights for width we have to find six attention uh weights for step and we have to find six attention weights for your and one so for every every query we have to find six attention weights so all of these which I'm highlighting with star right now all of these are the queries currently we only looked at the journey Query but now we have to essentially replicate the exact same computation for all the other queries as well so how will we do
this let's say if the query is Step we'll find the attention weight between step and all the other words and then we'll find the context vector by doing the summation operation like we did at the end for the query of Journey so essentially we are going to follow the exact same steps as before For all the other tokens also we are first going to compute the attention scores then we are going to compute the attention weights and then we are going to compute the context Vector remember these are the exact same steps which we followed
uh for uh the query of Journey and these are the exact same steps which we will follow for other queries as well so let me take you through code right now and let us start uh implementing the attention or let us Start calculating the these three steps for the other queries as well so as we discussed we have to follow three steps the first step is to find the attention scores and remember how do we find the attention score if we have a particular query we'll just take the do product of that with all the
other input vectors so let's say if the query is in inputs we'll take the dot product of the query with all the other vectors in the input so one way to find the attention scores Is to just Loop through the input two times and essentially find the dot product uh I'll show you what that actually means uh right so let me rub these these things over here so that I can show you this one method of finding the attention scores so let's say you Loop over the input Vector right so the first you'll encounter your
then you will find the dot product between your and all these other uh all the other Inputs so that will be uh the result of the first inner loop so what you do is that first you fix an i in the outer loop and in the Inner Loop you go through the input entirely so when we fix an i in the outer loop it means we fix this sarey then we go through the inner loop entirely and find these six dot products now change the outer loop so then the outer loop changes to journey and
then similarly find the dot product between Journey and all the Other vectors now change the outer loop once more so similarly we'll change the outer loop and in each outer loop we'll go through the inner loop so that is essentially finding the dot products which are the attention scores uh the problem with this approach is that this will take a lot of computational time so if you look at the output tensor so this is a 6x6 and each element in this tensor represents an attention score between two pairs of Inputs so for example this 6x6
Matrix which you just saw in the code is very similar to this here I'm showing the normalized attention scores but even the attention scores look like the 6x6 so if you look at the first row all of those are the dot products between the first query and all the other queries if you look at the second row all of these are the dot products between the second query and uh all the other inputs so this second this second row actually Will be exactly same to the attention uh scores which we had calculated earlier see because
the second row is 9444 1.49 ETC so if you look at the second row here that is also 9544 1.49 because the second row represents the dot product between the second query and all the other input vectors similarly the last row represents the dot product between the last query and all the other input vectors okay now here we have used two for Loops Right and that's not very computationally efficient for Loops are generally quite slow and that's the reason why matrix multiplication needs to be understood the reason I say that linear algebra is actually the
core Foundation of every machine learning concept which you want to master is this for someone who does not know about linear algebra and matrix multiplication they'll just do these two rounds of four Loops but if you actually know linear Algebra you'll see that instead of doing this you can just take the uh multiplication of inputs and the transpose of the inputs and you will actually get the exact same answer so what this does is that you take the input uh input Matrix and what the input Matrix looks like is this you take the input Matrix
and then you multiply with the transpose of the input Matrix and you'll get the exact same answer as Uh you'll take you'll get the exact same answer as doing this dot product in the for Loop format and you can verify this so if you just take the product between inputs Matrix and the inputs transpose what we'll see is the exact same thing as the previous answer why because when we multiply two matrices what it essentially does is it just computes a bunch of dot products between the rows of the first Matrix and The Columns of
the second Matrix which is exactly what We are doing here in these two for Loops it just that this matrix multiplication operation is much more efficient than using these two for Loops so Step One is completed right now we have found the attention scores I hope you have understood why this is a 6x6 Matrix here and why each what each row represents each row represents the dot product between that particular query and all the other input um input embedding vectors now we'll implement the Normalization so remember how we did normalization here we did torch. soft
Max right so similarly what we are going to do here is we are going to do torge do softmax of this attention scores Matrix and what this will do is that it will implement the soft Max operation to each row so the first row we'll do the soft Max like we learned before then the second row we do the softmax like we learned before similarly the last row will do the soft Max like We learned before so if you look at each individual row you'll see that entries of each row sum up to one so
you can look at the second row here1 385 2379 it's the same U attention weights which we have got for the journey query uh one key thing to mention here is that what is the dim parameter over here so the dim here I'm saying minus one and the reason is explained below the dim parameter in functions like like Tor. softmax specifies the dimension of the input function input tensor along which the function will be computed so by setting dim equal to minus1 here we are instructing the softmax function to apply the normalization along the last
dimension of the attention score tensor and what is the last dimension of the attention score tensor it's essentially The Columns so if the attention scores is a 2d tensor it's a 2d 6x6 tensor right and it has the shape Of rows and columns uh the last Dimension is the column so Dimension equal to minus one will normalize across the columns so what what will happen is that for the first row look at the columns so this is the first column this is the second column actually I have to show here this is the First Column
this is the second column this is the third column so we are normalizing essentially along the columns right because we are Going to take the exponent of what all is there in the First Column second column third column Etc we are going to sum these exponents that's why it's very important to uh write this dim equal to minus1 because we are normalizing across a column um and that's why the values in one row sum up to one since we are normalizing in the each column that's why the values in each row sum up to one
it's very important to note that so Dimension equal to minus1 means that we have to apply the normalization along the last Dimension and for a two dimensional t sensor like this the last Dimension is the columns so the soft Max will be applied across the columns and that's why for each row you will see that all the entries sum up to one so these are the attention weights which we have calculated and the last step which is very important is calculating the context vector and uh I Want to uh show some things to you but
before that let's verify that all the rows indeed sum up to one in this attention weights so what I'm doing here is that I'm looking at the second row here and I'm just going to sum up to one and I'm just going to sum up the entries of the second row and you will see that uh the second row sums up to one and I have also included a print statement below which prints out the summation of all the rows and you'll see that the First row the second row similarly the sixth row all of
the rows essentially sum up to one this means that the softmax operation has been employed in a correct manner for you to explore this dim further you can try with dimm equal to Z dim equal to 1 also from the errors you will learn a lot these small details are very important other students who just apply llm Lang chain and just focus on deployment will never focus on these Minor Details like what is this dim operator over here Etc but I believe the devil always lies in the details so the students who understand these Basics
will really Master large language models much more than other students now we come to the final step which is essentially Computing the context vectors right and I will take you to code but the final step is actually implemented in elegant one line of code let me take you to the final Step before what we had done in the final step remember what we simply did was uh we just uh where was that yeah in the final step what we simply did was we just multiplied the attention weights for each Vector for each input Vector with
that corresponding Vector right I can show this to you in the Whiteboard also okay so what we did for the final step of the context Vector was something Like this yeah so what we did was we we got the attention weights for each input embedding vector and we multiplied those attention weights with each with the corresponding input vector and we those up now this is exactly what we have to do for the other uh for the other tokens also but we have to do this in a matrix manner because we cannot just keep on looping
over and use for loops and there is a very elegant Matrix operation which Actually helps us calculate the context vectors it's just one line of matrix product essentially we have to multiply the uh attention scores Matrix or the attention weight Matrix with the input right and we have to do some summations can you think of the matrix multiplication operation which will directly give us this answer um it's fine if you don't know the answer but the simplified matrix multiplication is just essentially Multiplying the attention weights with the inputs that's it uh this last step of
finding the context Vector is just taking this attention weight Matrix and multiplying it with the input Matrix and the claim is that it will give us the context vectors it will give us the six context vectors which we are looking for remember we need a context Vector for every token right and there are six tokens so here are the six context Vectors now I'm going to try to explain why this matrix multiplication operation really works so let's go to the Whiteboard once more all right so this is the first Matrix which we have and that's
the attention weights right here and this is the second Matrix which we have which is the inputs uh so keep in mind here that the attention weights is a 6x6 Matrix so we have six rows and six columns and the Inputs is a 6x3 matrix now we have already looked at how to find the uh context Vector for the second uh for the second row right which which essentially corresponds to the word journey and uh so let's see what we exactly did here so the final attention Matrix will be a 6x3 matrix because so sorry
the final context Vector Matrix will be a 6x3 matrix because every row of this will be a context Vector so the first row will be the context Vector for The first word the second row will be the context Vector for the second word so let's look at the second word which is essentially the context Vector for Journey now uh if we take a product of these two Matrix so let's say if we take the product of the attention weight Matrix and the input Matrix first let's check the dimensions so this is a 6x6 Matrix and
the inputs is a 6x3 so 6X 6 can be multiplied with 6x3 so taking the product is completely possible and it Will result in a 6x3 matrix uh so let's look at the second row if you look at the second row it will be uh something like we we'll take the second row uh so the second row First Column would be the dot product between the second row of this and the First Column of this the second row second column will be the dot product of this with the second column of this and the second
row third column will be the dot product of this second row and the Third column here so that's what I've written here in the output Matrix so the first element of the second row will be the dot product between the second row and the First Column the second element of the second row will be the dot product between the uh second row and the second column and the third element of the second row will be the dot product between the third row of the first Matrix and the third column of the second Matrix right now
when you Compute these dot products uh very surprisingly you will see that the answer is actually equal to this the answer is 138 the answer is actually 138 which is 138 multiplied by the first row over here plus 237 multiplied by the second row over here plus 233 which is multiplied by the third row over here Etc uh it's just a trick of matricis but what it it turns out that this second row second row can also be represented By this formulation where you take the uh first element of this second row multiply it with
the first row of the input Matrix plus the second element of the second row multiply with the second row of the input Matrix plus the third element multiply it with the third row of the input Matrix can you see what we are essentially doing here we essentially scaling every input Vector right we take the first input Vector we take the first input Vector we Scale it by 138 we take the second input Vector we scale it by 237 we take the third input Vector we scale it by 233 isn't this the exact same scaling operation
which we saw uh when we looked at the visual representation of the uh context Vector calculations remember we have seen seen the scaling operation to calculate the context Vector here where we had taken each of the input vectors and we had scaled it by the attention weight values and then We summ them to find the final context Vector this is the exact same thing which I which we are doing over here so when we take the product of the uh when we take the product of the attention weights and the inputs another way to look
at it is that if you look at the second row it's actually scaling the first input by 138 scaling the second input by 237 dot dot dot and scaling the sixth input by 0158 so it's the exact same operation as We performed before for finding the context vector and that's why finding the context vectors is as simple as multiplying the attention weights with the inputs the first row of this answer will give you the context Vector for the first uh input embedding Vector the second row will give you the context Vector for the second token
the third row of this product will give you the context Vector for the second token for the third token and right up till the Very end the sixth row will give you the context Vector for the final token and this is how the product between the attention weights and the inputs will give give you the final context Vector Matrix which contains the context Vector for all of the tokens which you are looking for and uh with this final calculation we calculate the context Vector for all um of the input tokens and this is exactly what
I've Have tried to do here so finally uh we generate a tensor which is called as the all context vectors and we multiply the attention weight Matrix with the input Matrix and then we get this all context Vector tensor and if you look at the second row here 4419 6515 56 you'll see that this is exactly the same value of the context Vector which we had obtained over here uh when we looked at Journey so this again implies that whatever we are doing here uh with the matrix Multiplication is leading to the correct answer so
based on this result we can see that the previously calculated context Vector 2 for journey matches the second row in the in this tensor exactly so remember this operation to get the final context Vector we just multiply the attention weights with the inputs if you did not understand the matrix multiplication which I showed on the Whiteboard I encourage you to do it on a piece of paper because this last matrix Multiplication is very important to get the context Vector we just have to multiply the attention weight Matrix with the input Matrix and what all you
are learning right now will Direct L extend to the key query and value concept which we'll cover when we when we come to causal attention and multi-head attention and even in the next lecture in the next lecture we are going to look at this exact mechanism but with trainable Weights then we'll come to the concept of key query and value but these operations which we are looking at here so for example uh here we are taking the matrix product between attention weights and inputs right in the key query value this will be replaced this inputs
will be replaced by value we'll also have a key and a query but the underlying intuition and the underlying mechanism is exactly the same so if you understand what's going on Here you'll really understand key query value very easily okay one last thing which I want to cover um at the end of today's lecture is that okay so you might think that we already then find the context vectors like this right then what's the need for trainable weights we just take the dot product and we then find these context vectors the main problem with the
current approach is that think about how We found the attention weights to find the attention weights all we did was to just take the dot product right so currently uh in our world the reason why we are giving more attention to starts is that the alignment between starts and journey is maximum so the only reason why we are giving more attention to starts is because because it semantically matches with journey because we are only getting the attention scores and attention weight From the dot product however that is not correct right because two vectors might not
be semantically aligned but maybe they are more important in the context of the current sentence so for example journey and one are not semantically related to each other but what if in the current context one is the is the vector which is more important so apart from the meaning you also need to capture the information of the context right what is happening in the Current sentence and without trainable weights it's not going to happen we are not going to capture the context effectively right now we did manage to capture the context somewhat but we only
give attention to Words which are similar in meaning to the query but even if a word is not similar in meaning it still might deserve attention in the context of the current sentence so let's take a simple example Here okay so the example is the cat sat on the mat because it is warm and let's say our query is warm so in the first case let's say we do not use trainable weights like what we have done in today's lecture if we don't use trainable weight we only take the dot product between the query warm
and each words embedding and we'll find that warm is most similar to itself and maybe somewhat related to mat words like the cat and sat might have Low similarity scores because they are not semantically related to or so with with this so if we don't consider trainable weights we'll only look at Words which are more similar to this query which is warm now with trainable weights the model can learn that warm should pay more attention to mat even if mat is not semantically related to warm so what will happen without trainable weights is that mat
and warm might be vectors which are like this which have a 90° angle and they might not be related because their meaning is not related but that does not mean we should not pay attention to mat because in this context probably Matt is the most important if the query is warm because the mat is warm but the meaning of mat and warm are not not related right that's why we need trainable weights with trainable weights the model can learn that warm should pay more attention to Matt even if mat isn't semantically similar to warm in
Traditional embedding space so this is where important the trainable weight allows the model to learn that warm often follows mat in context like this one and that's how it captures long range dependencies that is the reason why we need trainable weights without trainable weights this meaning would be lost and we would only be looking at Words which are similar to The query by trainable weights we get more more of this information that okay Matt might Not be related in meaning but in the current context mat is the word which is more important because the mat
is warm this is how trainable weights allow us to capture context and in the next lecture we'll specifically devote the next lecture to uh the simplified self attention mechanism but with trainable weights so here is the lecture notes for the next lecture self attention mechanism with trainable weights we'll introduce the concept of key query value And then slowly we'll move to the concept of uh causal attention and then we'll move to the concept of multi-head attention so up till now we have covered simplified self attention I know this lecture became a bit long but it
was very important because uh I have seen no other lecture or no other material which covers this much detail visually theoretically and in code about the attention mechanism I could have directly jumped to key query and value Which will come later but then you would not have understood the meaning but this lecture allowed me to build your intuition I hope you're liking these set of lectures if you have any doubts or any questions please ask in the YouTube comment section and I'll be happy to reply thank you so much everyone and I really encourage you
to take notes while I'm making these lectures I'll also share this code file with you um thanks everyone and I look forward to seeing You in the next lecture