Olá! Seja bem-vindo à aula 12 da disciplina de projeto de software. Esse vídeo é a parte do número um desta aula.
O objetivo desse vídeo é: apresentar o protocolo http, falando um pouco sobre suas características, evolução e como ele funciona. Bom, mas o que que significa http? Http significa hypertext transfer protocol ou em português protocolo de transferência de hipertexto.
Ele é um protocolo extensível e por isso permite a obtenção de outros recursos além de documentos de hipertexto ,como por exemplo, obter imagens, sons, além de publicar conteúdo em servidores O objetivo inicial do HTTP era distribuir conteúdo hipertexto, ou seja, documentos com links que levam a outros documentos com links. Usamos o http diariamente para acessar páginas na internet. O HTTP usa o modelo arquitetural cliente-servidor e o seu funcionamento é baseado no modelo requisição-resposta.
Para solicitar um recurso como uma página da web ou enviar alguns dados para um servidor, um cliente http, como por exemplo, um navegador web, envia uma requisição http para o servidor. O servidor recebe a requisição e envia uma resposta http que contém o conteúdo dessa página, o conteúdo deste recurso que foi solicitado pelo cliente. Bom, já que falamos em requisições, vamos dar uma olhadinha então como é uma requisição http.
o conteúdo uma requisição http tem basicamente três partes westline os riders ou cabeçalhos e o bori ver o bode ele é opcional então aqui nesse caso não está representado dentro dessa solicitação e o verbo é o método da solicitação que aparece lá na rua e quest line é ele que indica para o servidor tipo de solicitação que o cliente está fazendo veja também pode chamar o método http de verbos http. Outra coisa importante é o recurso que nós estamos solicitando do servidor, que no caso nós estamos pedindo é o recurso raiz, a página inicial, por exemplo, de um site. Alguns cabeçalhos.
Qual é o significado dos cabeçalhos, por exemplo? o ACCEPT, ele tá informando para o servidor os tipos de conteúdo que o cliente é capaz de entender. Então, como é asterisco barra asterisco, então quer dizer o cliente pode aceitar qualquer tipo de conteúdo.
O accept-encoding indica qual a codificação do conteúdo, pode, normalmente ele vai representar algum algoritmo de compressão que o cliente consegue entender. Já em conexão, está informando como é que o cliente tá pedindo para conexão ser usada, ok? Definido, por exemplo, um tempo limite ou uma quantidade máxima de requisições a serem feitas.
Host identifica o nome do domínio do servidor, então aquela barra que eu mostrei para vocês lá no início, ele é aplicado dentro desse HOST, então porque que é o raiz, porque é o HOST wikipedia e o recurso é o barra. E por fim, o USER-AGENT permite que os servidores ou alguns pares dentro da rede vão identificar aplicativos, sistema operacional, o fornecedor ou a versão do agente que está solicitando esse recurso. Agora vamos dar uma olhadinha então como é a resposta.
As respostas http são semelhantes as requisições. Elas têm aqui no início, o cabeçalho. Aqui dentro desse cabeçalho a gente tem um código do status e a gente tem e o cabeçalho da resposta.
Os cabeçalhos da resposta, melhor dizendo. Além disso, eles podem ter um corpo, mas para facilitar, aqui nesse caso, eu não coloquei. Então o código de status, esse aqui no cantinho, ele é um código de três dígitos que informa ao cliente se sua solicitação foi bem-sucedida ou falhou e como que ele vai prosseguir.
Então os códigos de status são agrupados por meio de classes. Então por exemplo, classe 200 tem êxito. Então 200 201 202 203.
Os códigos da classe 300 eles vão fazer o direcionamento para uma outra página. 400 e 500 são classes dedicadas à solicitações que falharam. A diferença que o 400 são falhas ou erros ocasionados pelo cliente e 500 são falhas no servidor.
Alguma coisa aqui sobre alguns desses cabeçalhos, né? o Content-Encoding, ele é usado para indicar quais codificações foram aplicados ao corpo, né a body, a resposta, ele vai permitir que o cliente decodifique o body depois né o corpo a resposta e o Content-Type, aqui ó, ele é utilizado para indicar o tipo de arquivo, o tipo do formato do recurso que o servidor está enviando para o cliente então quer dizer se eu juntar o content-encoding e o content-type, significa que eu vou tá enviando um arquivo do tipo html e ele vai estar compactado. Então quando ele chegar no cliente, o cliente vai descompactar esse arquivo.
Outra coisa importante sobre o http, é dizer que ele é Stateless. Então o protocolo sem estado. Isso significa que não há nenhuma relação entre duas solicitações sendo executadas sucessivamente na mesma conexão.
Porém, mecanismos como por exemplo, os cookies, permitem a criação de seções e essa exceções permitem o compartilhamento do mesmo contexto ou do mesmo estado. Atualmente, o http está sendo usado na versão dois, mas já existem trabalhos no sentido de preparar a versão três esse protocolo e vejam, é como eu disse, o http ele é extensível e essa afirmação é comprovada pois ao longo dos anos, todas as revisões que o http sofreu e vejam que foram apenas quatro desde 1991, incluíram melhorias que tornaram esse protocolo apto a continuar atendendo a demandas. Então, a primeira versão do protocolo, chamada de http 0.
9, ela foi proposta pelo Tim Berners-lee, o pessoal diz que Tim Berners-lee é o pai da internet e ele tinha simplicidade como ponto principal. Ele era tão simples que ele focava-se apenas em transferir dados do formato texto, ok? E ele só tinha um método disponível para requisição que era o método GET.
Depois, em 1996, surgiu a versão http 1. 0. Ele veio como uma resposta a ineficiência da primeira versão já que havia um rápido crescimento da web além do GET né alguns métodos que passaram a ser suportados foram o HEAD e o POST.
A resposta do servidor para o cliente ele já não ficava limitado só ao hipertexto. Então o content-type, que nós falamos agora há pouco, ele surgiu nesse momento. Então, além de html você podia também mandar para o cliente scripts, podia mandar folha de estilos, podia mandar imagens, podia mandar som.
Quanto ao http 1. 1, além de algumas melhorias de performance em relação ao 1. 0, ele marcou o início da padronização da internet e acrescentou outros métodos ao aqueles que já haviam sido definidos.
Então ele acrescentou PUT, DELETE, TRACE e Optinos. E por fim a chegamos ao http 2 que foi lançado em 2015. Ele surgiu tendo em vista a chamada internet das coisas, em que a quantidade dispositivos conectados está aumentando cada vez mais.
Então, as principais melhorias que ele trouxe foram na performance de transporte das informações na diminuição da latência e isso faz com que, por exemplo, você consiga atender melhor dispositivos móveis e conteúdos multimídia. Bom, nós temos uma versão também que o HTTPS, que seria o http seguro. O https ele ajuda, ou ele protege, melhor dizendo, a integridade e a confidencialidade dos dados entre o cliente e o servidor.
Então os dados enviados com o https eles estão protegidos por pelo protocolo de segurança de camada de transporte, a sigla em inglês é TLS, e veja que o TLS ele é uma versão mais nova é uma versão atualizada de um outro protocolo que já existia que é o SSL. Muitas vezes nós vemos o nome SSL ou às vezes vê SSL/TLS. Na verdade, o que a gente usa é TLS e ninguém usa SSL mais, até porque, a versão do SSL 3.
0, quando ela foi lançada, ela foi usada como base para o TLS 1. 0 isso lá no final da segunda metade dos anos noventa do século passado, ok? então a gente pode dizer que o tls ele é uma atualização do SSL.
Outra coisa, mais uma informação sobre o http é que ele é um protocolo de camada de aplicação. Então ele é executado sobre outros protocolos como o tcp, por exemplo. Bom e por que a gente fala tanto de http?
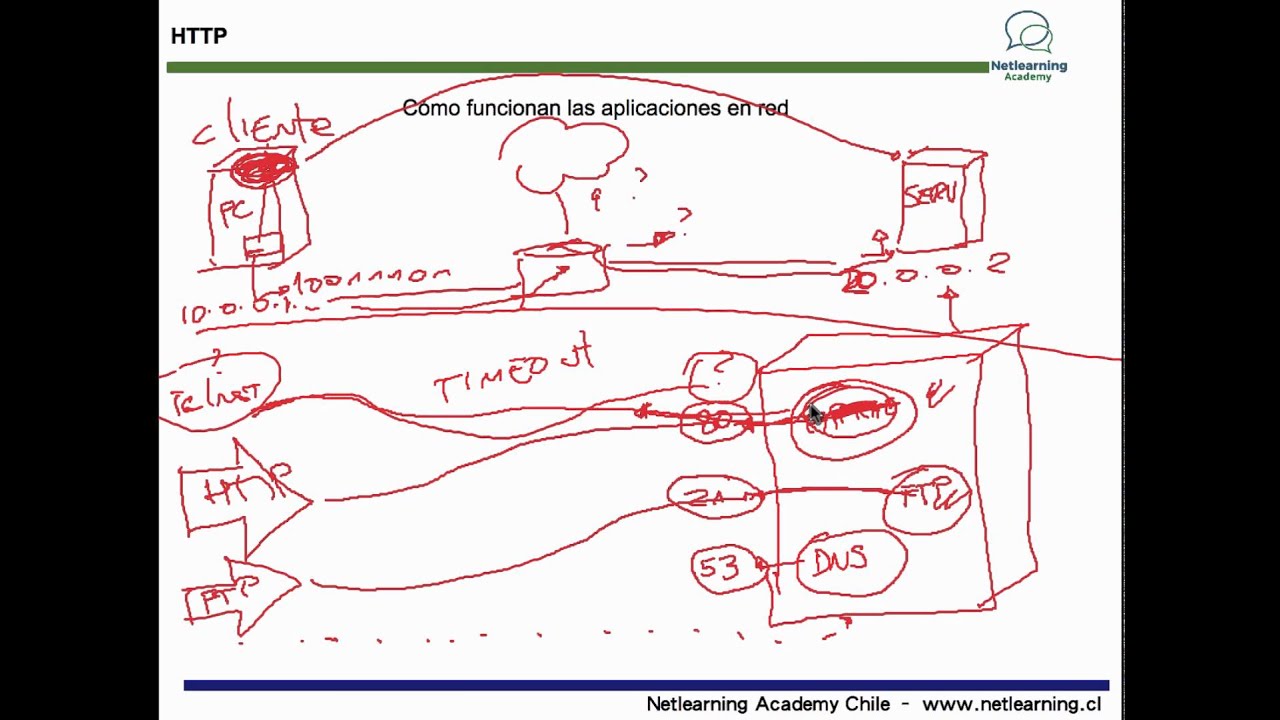
Por um motivo simples: não haveria a web se não houvesse protocolo http e sempre que a gente visita uma página da web, o nosso computador vai usar http para baixar essa página do servidor, né, que tá em algum lugar da internet, perfeito? Mas como que esse protocolo funciona? a primeira coisa que a gente tem que ter em mente o seguinte e aí e a gente sempre vai digitar um endereço de um site, por exemplo, usando um nome amigável, tá certo?
Por exemplo, www. wikipedia. org, ok?
Mas a gente não sabe aonde que está hospedado esse site. Então, a gente não tem essa ideia, não sabe exatamente onde que fica isso e para que a gente possa fazer isso, a gente possa buscar esse recurso, buscar esse site é é preciso fazer uma relação então entre esse nome de domínio, esse nome amigável, e o endereço ip, de quem que contém a localização desse servidor. Então, o mapeamento do nome de domínio para o endereço IP ocorre através de um outro protocolo que é chamado DNS.
Sem entrar em detalhes como DNS funciona, à grosso modo podemos dizer que o navegador do cliente usa um resolvedor DNS para mapear o domínio que agente digitou em um endereço ip Depois que navegador identificou o endereço ip do computador que hospeda a URI solicitada, URL já que URL é um tipo de URI, ele vai enviar uma solicitação http para esse servidor. Bom, mas antes de ir poder ver na prática o conteúdo das requisições das respostas e como usamos os métodos http eu queria mostrar a ferramenta que eu vou utilizar nas demonstrações eu vou usar o httpie, que é um cliente http que roda no shell. Ele é uma ferramenta usada para testar e verificar o http e a bastante utilizada por ser uma maneira fácil para testar servidores e APIs.
Uma das coisas que eu mais gosto, é que ele usa um highlight que facilita bastante a leitura dos resultados. caso você queira instalar ele está disponível no endereço https://httpie. org.
O httpie é uma ferramenta bastante útil, mas eu quero deixar aqui uma observação o httpie ele possui uma limitação, ele não trabalha com a versão 2 do http então todos os exemplos que foram mostrados nos vídeos seguintes vão usar a versão 1. 1 http, certo? Sugiro que você instale o HTTPIE se possível para você também fazer alguns testes aí na sua casa.
No próximo vídeo vamos usar o httpie para conhecer um pouco mais sobre as requisições respostas do protocolo http. Até lá!