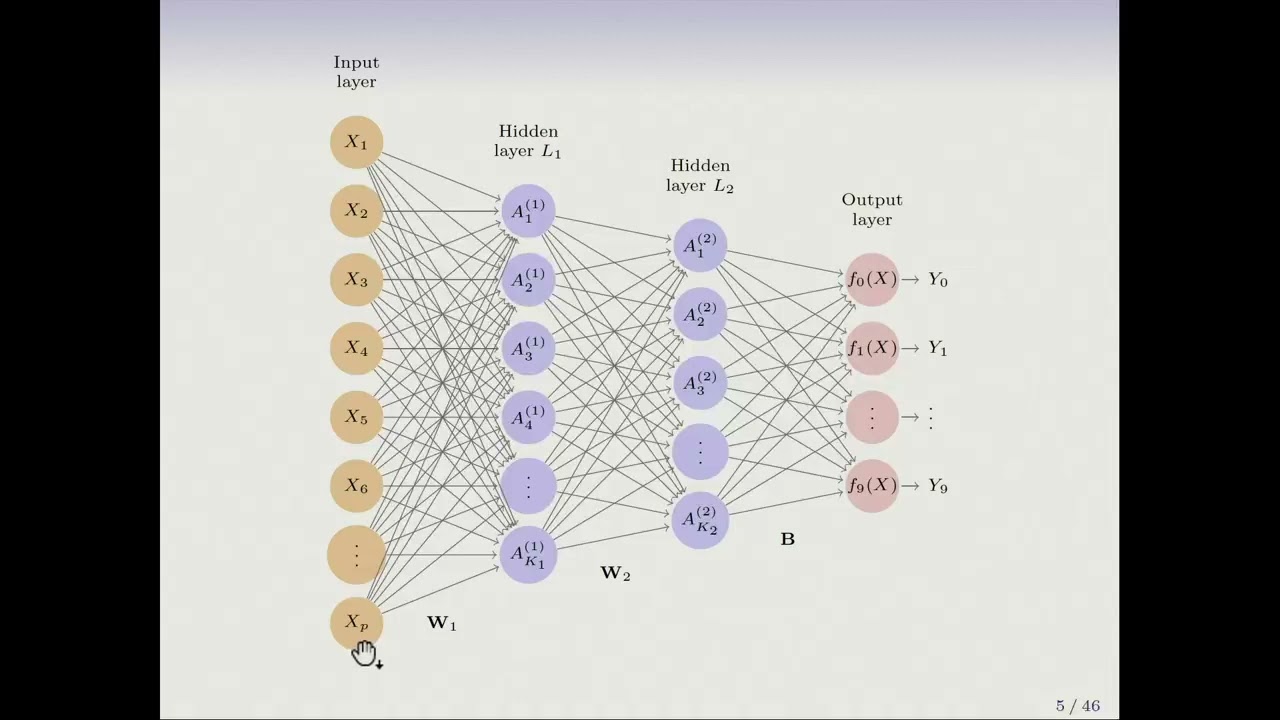
so that's forward stepwise selection um and now we're briefly going to talk about backward stepwise and backwards stepwise is once again just like forward it's an efficient alternative to best subset selection but it actually is exactly the opposite of forward stepwise so remember in forward stepwise we built the model m0 and then we added a feature to get m1 added a feature to get m2 and in contrast for backward stepwise we're going to start with mp which is the model containing p predictors and we're going to remove predictors one at a time one at a
time until we get to m0 which is the model with with just an intercept so in a little more detail we start with mp which is just the regular least squares model if you just didn't do any feature selection and you just wanted to use all of your predictors and then we're going to take that model mp and we're going to consider removing predictors one at a time excuse me we're going to consider removing each of the p predictors and we're going to see which predictor is the least useful to us which predictor can we
remove that's going to have the the smallest effect on either rss or r squared so we're going to remove the least useful predictor and that'll give us the model mp minus one and then we're going to take mp minus one and we're gonna again ask which predictor is the least useful which one can we remove in order to have the least detrimental effect on our our model fit and we're gonna keep doing this until we make it down to the model with just one predictor m1 and finally to the model with with no predictors which
is m0 so that's once again going to give us a set of models from m0 to mp and we're going to choose among them using once again cross validation aic bic or adjusted r squared so just as was the case for forward stepwise selection backward stepwise considers around p squared models instead of two to the p so it's a fantastic computational alternative to to best subset selection especially when p is is moderate or large and actually the exact number of models the backward selection considers you know i've been saying it's around p squared it's actually
more like p squared over two that's the exact formula and that's a good thing to work out at home so you know think about it why is it that if you do forward stepwise selection or backward step by selection you're actually considering this number of models so just like forward stepwise selection backward stepwise is not guaranteed to give us the best model containing a particular subset of the p predictors so it was that same picture that rob draw drew a few minutes ago where we saw that forward stepwise for any given model size might give
a larger rss or equivalently a smaller r squared than best subset so similarly backwards stepwise might not give quite as good of a model in terms of rss or r-squared but that can still be okay and in the long run it could give us better results on a test set not to mention it's more computationally efficient so one major difference as we mentioned between backward and forward stepwise is that with backward stepwise we start with the model containing all of the predictors so in order to be able to do that we need to be in
a situation where we have more observations than variables because remember we can do least squares regression when n is greater than p but if p is greater than n we cannot fit a least squares model it's not even defined so we can only do backward selection when n is greater than p and in contrast we can do forward stepwise whether n is less than p or n is greater than p oops so um we mentioned that um the model containing all of the predictors is always going to have a smaller r squared excuse me the
model containing all the predictors is always going to have a smaller rss and a larger r squared than any other model because these quantities are really related to the training error so again this is the picture that rob drew but if i think about fitting a model with the number of predictors on the y-axis and rss on the if i think about fitting a model with number of predictors on the x-axis and rss on the y-axis this is going to be monotone decreasing and similarly if i think about a picture with number of predictors on
the x-axis and r squared on the y-axis it's going to be monotone increasing so if i so remember we when we do best subset or forward or backward step-wise we end up with these models m0 through mp and i cannot just choose among them using r squared or using rss because i'll always choose the biggest model and again that just boils down to the fact that these quantities are just based on the training error but i want to model with low test error because i wanted to do well on future observations that i haven't seen
like um you know patients who haven't walked into the clinic yet for whom i'm going to want to predict some sort of response and unfortunately just choosing a model with the best training error isn't going to give me a model that has a low test error because in general training error is a really bad predictor of test error a really bad estimate of test error and so rss and r squared just are not suitable for the task of choosing among models with different numbers of predictors