[Música] Olá pessoal tudo bem continuando então com a nossa vídeo aula sobre classificação de textos né no dia de hoje a gente vai falar um pouquinho sobre redes neurais Profundas tá aqui tá a sequência de tópicos que a gente vai trabalhar na aula de hoje né falar um pouquinho sobre modelos sectio Sec depois sobre atenção e Auto atenção que são conceitos importantíssimos né e essenciais para chegar nos Transformers né que é o que a gente tem de estado da arte aí de algoritmos de aprendizado de máquinas e por fim falar um pouquinho sobre o algoritmo
Berti que vocês já viram um pouquinho como é que funciona quando você trabalhou com um modelo pré treinado que a gente já carregou né um modelo desse para treinado a gente não entrou em muitos detalhes né E a gente vai dar uma espiada nele hoje ver o que que ele tem vamos dizer de tecnologia né de coisas atuais aí de conceitos atuais que tornam é um modelo de bastante sucesso só para relembrar um pouquinho de novo a gente tá falando de ordem beds né porque isso é importante então a gente viu que a representação né
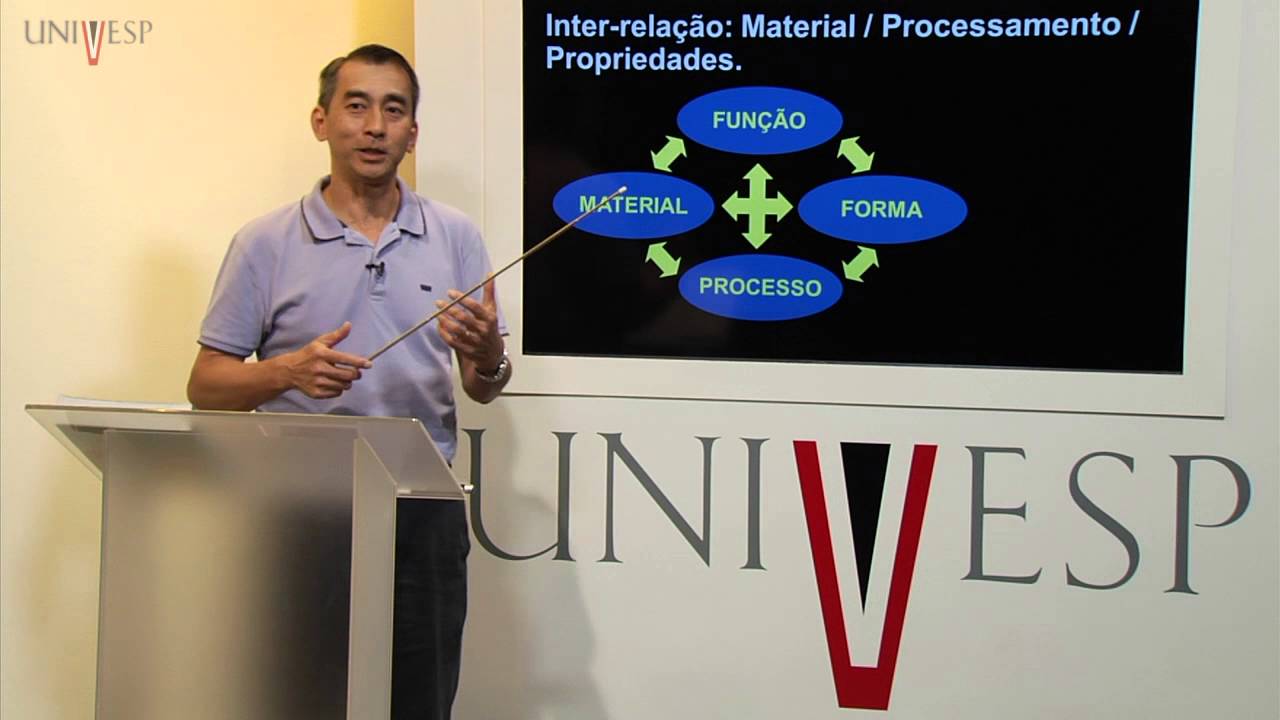
das nossas textos das nossas documentos sentenças etc por informes de Ambev em relação bastante importantes né Vocês leram durante essa semana já o conteúdo de redes neurais artificiais que eu passei para vocês no nosso roteiro né E vocês imaginam já deve ter aprendido bem né sobre o conteúdo de redes neurais artificiais e agora Vocês conseguem por exemplo entender melhor o funcionamento daquele algoritmo o objetivo Vec né que é um algoritmo que utiliza redes neurais para poder gerar zenberries né então isso já permite que vocês quiserem voltar um pouquinho e estudar um pouco com mais detalhes
né sobre como funciona esse wordito Vec por exemplo vocês podem uma mensagem ler os artigos já é onde o próprio zero né esse método ler em detalhes procurar na Internet vocês vão achar bastante coisa também né e Vocês conseguem evoluir um pouco mais o conhecimento de vocês e sobre esse conteúdo Mais especificamente né e as redes neurais não só para construção de imbelles né Elas também são muito utilizadas como a gente já viu também né como modelo de classificação depois a parte final vamos dizer assim para definir qual é o rótulo por exemplo de um
documento né então você pode usar um Word 2ck para gerar os ambevs e a partir dos nbeldes a gente é que treina uma outra rede neural né para poder fazer a classificação né dos textos de entrada e na saída ele classificar um texto como sendo de uma classe A ou B por exemplo né e com esses detalhes mais específico vocês podem ver então se vocês forem procurar aí pelo World togek né como é que essa rede neural é utilizada nisso né E a gente tem alguns modelos para treinados também né outros né Não só pra
questão de ambelles mas a gente tem várias outras tarefas aí que a gente utiliza para fazer é utilizar redes neurais para trabalhar com PLN que tem alguns exemplos alguns a gente já viu né e um deles também é Albert que a gente vai trabalhar um pouco hoje tá Quais são as tarefas que a gente tem em PLN aí pessoal é interessante né que a gente só para dar uma relembrada né é que a gente pode realizar após essa codificação das palavras nessa construção dos embeldens né então a gente pode fazer por exemplo a previsão a
previsão da próxima palavra em uma sequência de texto uma tradução automática de textos também isso a gente vê que se forem utilizar o Google hoje né quem não é tão jovem vai saber né O que que eu tô falando de uma forma mais clara né antigamente pessoal a gente utilizar o Google Translator e às vezes até uma pessoa que não trabalha muito com a língua conseguia não entende muito inglês conseguia perceber Ah esse cara usou outras letras porque a tradução era bem ruim vamos dizer né mas isso é muitos anos né E aí a gente
vai ver a relação muito com essa nossa aula dele que a gente vai que a gente vai tendo hoje né é a partir do momento que você começou a trabalhar Correios Profundas Hoje teve texto meu por exemplo que eu escrevi em inglês é um certo momento eu precisava passar para português assim ah eu vou para facilitar né eu tenho que fazer um documento português e não em inglês eu já tinha tudo feito em inglês eu vou usar o translator e depois eu vou arrumando porque é mais fácil depois eu em português a gente arruma de
uma forma bem mais natural né e eu vou dizer para vocês assim traduzir textos e praticamente e eu não consegui eh Não precisei mexer em Nada de tão bem que foi feita a tradução né então é algo que hoje é bem diferente de antigamente esses modelos essas redes neurais Profundas né que que surgiram aí já um bom tempo elas permitiram né evoluíram Muito em várias aplicações e essa é uma delas a aplicação de tradução automática de texto né porque se a gente consegue ver no nosso dia a dia né É principalmente para quem conseguiu ver
a diferença né desde antes e após o surgimento dessas redes Profundas né então aqui a gente tem também a geração de resumos é geração de texto vocês também já é já viram bastante falar sobre o chat GPT por exemplo ele utiliza os conteúdos que a gente vai aprender hoje que são os transformas né às vezes transforma e também classificação de texto naturalmente que é o que a gente tá trabalhando aí durante a nossa semana então são várias aplicações que a gente tem nesse sentido né em PLL tá antes de falar um pouquinho sobre o modelo
só para contextualizar vocês né O que que seria a redes anurais Profundas né eles ainda mais profundas é muito o que vocês já viram sobre redes orais só que são redes orais que tem uma grande quantidade né de camadas escondidas em neurônios e camadas escondidas então o profundo ele é muito subjetivo né então profundo são aquelas redes em que a gente tem dezenas por exemplo às vezes centenas de camadas né vamos dizer né E daqui a pouco Alguém tem uma rede com 10 camadas a 9 10 Ah mas é profunda não é então por isso
que é difícil de definir assim o que que é profundo o que que não é porque não tem um cálculo numa forma exata para dizer isso né mas quanto mais né como vocês já viram quanto mais camadas ocultas a gente tem em uma rede neural é mais lento feito o processo de aprendizado mais difícil né mas é lento não só no processo de aprender mas também no processamento das informações né é o treinamento ele não é só lento pela questão do do do conteúdo que está sendo aprendido e modelado mas também da questão de Às
vezes a gente precisa de 10 épocas vamos dizer assim em 10 épocas para poder fazer aprender um determinado treinamento durante 10 épocas para aprender a determinado conhecimento se a gente usar uma rede profunda para isso a gente vai precisar de muito mais épocas né e para cada época o tempo que a gente vai demorar também para alterar os pesos vai ser bem maior também então são esses dois sentidos principalmente que a gente tem né Além da questão de memória armazenamento né processamento de informações e etc né então para isso se trabalha muito atualmente a gente
já viu isso em algumas aulas práticas embora e muitos momentos a gente não sabia nem o porquê lembra que eu falei pra vocês oh quando for fazer treinamento coloque a GTU né ativa e GPU aqui no no Google colab porque o processamento vai ser mais rápido Justamente por isso né porque com as gpus a gente tem milhares de processadores que embora eles não sejam tão velozes tão rápidos como são o cpus né A questão ali é que ele pode fazer esse trabalho todo em paralelo e E acabamos ganhando muito tempo isso foi também determinante para
que fosse possível né a utilização S redes sociais Profundas porque antes desse tipo de unidade de processamento a gente não conseguia trabalhar com tanta é com redes tão Profundas né e os modelos sextil Sec pessoal basicamente ele acaba o que interessa aqui que são redes que tem como entrada na sequência de caracteres e geram também como saídas sequência de caracteres por isso sectio Sec então a ideia basicamente é utilizar um Encoder né que a gente tem aqui esses esses modelos são divididos em duas partes básicas né que seriam o Encoder e um decoder certo o
que que seria o Encoder né basicamente a gente vai transformar a nossa entrada e uma representação de contexto lembra que a gente tem a nossas entradas por exemplo que são os ambevs né então a gente pode utilizar os embages como entrada e aqui na saída do nosso encontro a gente teria uma outra representação que vai analisar não apenas né a ideia desse encontro é justamente isso né não analisar apenas textos individualmente mas analisar o contexto em que essa sequência de palavras são lidas né então aqui nesse nesse exemplo que eu tô colocando pra vocês aqui
utilizando essas redes neurais recorrentes se vocês quiserem também dar uma Vocês já viram né que existem embora a gente não ter entrado em muitos detalhes né mas às vezes a nós recorrentes são aquelas que de plataformas as memorizam algumas informações né a gente tem ciclos né a gente tem que a saída de uma camada ela pode ser conectada a entrada de uma camada anterior e aí vocês podem também estudar isso com mais detalhes né mas a ideia aqui então é que esses modelos aqui nesse exemplo utiliza essas redes recorrentes para fazer a leitura palavra por
palavra aqui por exemplo a gente tem na entrada X1 X2 X3 é como se a gente tivesse lendo o texto X1 aí depois o X2 X3 aí a próxima palavra vai pro X1 e a outra vai pro X2 pro X3 é como se tivesse alguém lendo o texto palavra né E essas E aí a ideia é tentar relacionar essas palavras também essa sequência com que efeito essa lida essa essa leitura né pra depois a gente ter uma representação então de contexto seria uma representação intermediária né e a partir dessa representação intermediária por exemplo é fazer
uma analogia para vocês entenderem um pouco melhor né aqui a gente teria uma um texto sendo lido é em português por exemplo se a gente tá trabalhando com uma tradução vamos dizer né língua portuguesa aqui nessa representação intermediária a gente teria uma representação é que não tem nenhuma vamos dizer assim uma representação genérica de um texto e aí a partir disso aqui poderia utilizar então para gerar uma nova sequência Então a partir desses essa representação interna para uma outra língua por exemplo então isso aqui se utiliza muito também tradução de textos né então decoder vai
usar essa representação de contexto que a gente tá falando aqui que é a saída do Encoder para gerar uma nova sequência de saída Então se trabalhou muitos anos esse trabalho né com modelos Sect né Principalmente aí quando a gente trabalha com a ideia de tradução de textos por exemplo Ah mas por que que estão falando de tradução e não estamos falando de classificação né bom primeiro porque a tradução é uma tarefa importantíssima que é importante que você saibam também né E também porque esses modelos também podem ser usados como classificadores mas a gente vamos falar
um pouco mais detalhes para vocês mas na frente mas a gente pode por exemplo pegar a saída desse encontro que tá aqui Como Eu mencionei para vocês como uma representação diferente né uma forma diferente de representar os nossos textos e a partir desse cara que tá na saída em vez de fazer a gente pega só o sexo e tira o tio seque né Pra Outra Sequência em vez de fazer utilizar um decoder a gente pode colocar um classificador ali uma rede neural por exemplo né dar-lhe como entrada para ela esses caras que foram gerados aqui
intermediariamente né e na saída dá um rótulo de um texto Então se faz muito isso e nós vamos ver isso na nossa aula prática no final da semana tá E por isso que é importante a gente aprender esses modelos aí né bom algumas limitações que que eu tô colocando para vocês ao histórico para mostrar para vocês porque que a gente se chegou no que chegou hoje que são os Transformers né algumas limitações desse tipo de modelo que a gente viu ali né a gente tem um viés de contexto muito próximo né porque como a leitura
é feita de forma sequencial né então acaba que isso a gente não consegue colocar ali um valor trabalho com valor fixo né de entrada né então sei lá naquele exemplo tinha três a gente vamos supor que a gente botasse ideias né então a gente vai fazendo a leitura um por um né E quanto maior for né quanto menos quanto maior for o texto e quanto menos entradas a gente coloca nessa rede mais rapidamente vamos dizer assim a memória da rede ela vai vai perdendo essa memória vai se esquecendo vamos dizer né então acaba que as
últimas palavras elas vão ter um peso maior na representação é como a gente faz a nossa leitura de um texto a gente tá lendo um texto tá lá na décima página que que tá mais fresca na nossa memória a nona na página a oitava E aí pra lembrar lá da primeira a gente vai ter mais dificuldade é mais ou menos essa analogia que a gente pode fazer né então isso aqui principalmente que a gente tem esse limite fixo né do tamanho do contexto também né que a forma com que essa sentença são quantificadas nessa camada
intermediária né E principalmente pelo processamento sequencial né então é demorado a gente não consegue usar paralelismo aqui né porque porque a gente vai fazendo a leitura de forma sequencial e esses modelos dependem dessa leitura de forma sequencial não adianta a gente colocar Ah vou no texto tem 100 palavras Então vou botar um cara de tamanho 100 aqui não vai resolver porque porque eu preciso passar a primeira para depois ir pra segunda porque se a leitura é feita de forma sequencial tá então isso acaba limitando também né o tempo de treinamento acaba demorando muito para fazer
o treinamento aprendizado dessas redes né aqui tem um exemplo de aplicação que a gente trabalha com uma tradução por exemplo de inglês para português né para contextualizar para vocês aqui que principalmente o exemplo da tradição é interessante para a gente poder entender isso né quando a gente vai pegar um texto de uma língua para outra algumas palavras a gente consegue fazer de forma direta assim né então a gente tá colocando aqui a ideia de atenção vamos dizer né que se utiliza muito hoje né a tradução ela vai exigir a tensão apenas em algumas partes da
sentença né E também outras linguagens que a gente vai trabalhar outras traduções é as atenções elas são diferentes né e dependendo não é uma forma simples não é mapeamento simples Às vezes a gente vai fazer uma tradução de uma de um texto que tem uma frase Vamos colocar aqui tem cinco palavras de português pra língua inglesa por exemplo em inglês em vez de usar cinco vai usar oito ou vai usar duas três não tem um mapeamento direto né então a gente tem essa característica interessante aí nessa aplicação de tradução né E aí chega essa ideia
né do mecanismo de atenção né porque porque o que que seria o que que a gente tem naquela representação daquele Sect que Eu mencionei para vocês né que a gente vai ter aquela saída no meio da saída do Encoder e aquilo que é utilizado depois poder colder né mas tudo aquilo que foi processado lá no meio do caminho né que a gente chama das dos Estados escondidos estados ocultos né aquilo acaba não sendo utilizado né então a ideia da atenção basicamente pessoal só para tentar colocar de uma forma mais simples possível para vocês né a
ideia de atenção basicamente é utilizar também esses estados intermediários né que estão lá nas camadas ocultas e utilizar essas relações para poder também fazer as previsões próximas que a gente vai fazer utilizar também no contexto né das nossas das nossas das nossas representações né E aí a gente tem uma ideia de contexto acumulado né que até aquela palavra não vai ter só o conhecimento daquela palavra daqueles caras que estão muito próximos mas sim do que foi aprendido durante acumulado durante todo aquele caminho basicamente a ideia de atenção seria um pouco em relação a isso né
e aqui a gente teria uma ideia só de como que é feita né a importância que a gente teria o score de atenção vamos dizer assim né de umas palavras em relação às outras em uma língua e em outra língua então a gente vê que algumas são muito ou quanto mais escuro aqui a gente vê que tem muito mais importância né E as outras vão ficando mais clara a gente vê que tem uma relação embora seja menor e etc né E quando a gente trabalha com isso também se mecanismo de atenção nos dá essa ideia
como essa que a gente tá vendo aqui um pouco de semântica para tentar entender também o comportamento o que que tá sendo feito durante o aprendizado né quem tá sendo feito internamente na rede né e isso aqui tudo aquilo que eu conversei com vocês né então a ideia básica que o problema que a gente tem na questão do mecanismo de atenção né é que a atenção vai melhorar a memória né mas não a computação das redes porque por causa da questão sequencial que eu falei para vocês né acaba que é o gargalo dessas redes quando
a gente trabalha com com essa leitura sequencial né E aí que saiu esse artigo aqui propondo os Transformers né que vem com a ideia então de até encher que é o artigo que vocês podem ler depois tá aqui a referência para você para vocês darem uma olhada né que vem com a ideia então propôs o denominado dos modelos Transformers né que é o que você tenha utilizado muito atualmente né que dentro de todas as ideias que a gente trabalhou ele traz algumas é alguns conceitos mais interessantes Como por exemplo o conceito de Alto atenção então
não é só atenção desses mapeamento que a gente tem feito com outras palavras mas também dos toques com eles mesmo né com dados da sentenças com elas mesmo né isso nos dá informações adicionais que a gente tem aí né como vocês podem ver interdependência e importância relativa entre as palavras da sequência né a gente aprende relações de lobo alcance não só aqueles próximos que a gente está vendo e o principal né permite que a gente faça o paralelismo isso é a grande vantagem que a gente tem aqui nesse ponto porque porque a partir do momento
que a gente trabalha com Transformers a gente consegue agora fazer de uma forma muito mais eficiente e ter resultados bem mais interessante né Então aqui tem uma ideia né como é que funciona no Transformer só para vocês terem uma ideia a gente continua com aquela ideia de um set ou seque né um modelo sectio Sec que não necessariamente que nem eu falei para você a gente pode pegar a representação intermediária aqui e fazer a classificação e é isso que a gente vai fazer tá na nossa aula prática então aqui a gente tem o nosso encontro
e aqui a gente tem o nosso decoder né basicamente só que aqui ele tá usando esses conhecimentos de alta tensão e aqui também tá usando Então esse conceito de auto atenção e aqui são as diversas aplicações que a gente tem que estar trabalhando muito com esse modelo de desses modelos de redes neurais Profundas conhecidas como Transformers né então só para a gente ter uma ideia de como é composto como como são compostos esses esses blocos né Desse nosso Transformer né então a gente vai ver dá uma olhada para o encontder O que que a gente
tem na nossa encolder né a gente tem seis camadas que são formadas por dois componentes uma camada de alta tensão e uma rede alimentada adiante né inclui laços residuais também tá então só pra gente dar uma olhadinha aqui o que que seria o nosso encontro né Tá vendo a primeira parte a saída do encontro vai pra entrada do Decoder Como Eu mencionei para vocês esse cara aqui em vez de usar um decoder aqui a gente pode usar um uma rede neural ou qualquer outro modelo de classificação para classificar então a gente já tá fazendo a
leitura desse texto né utilizando esse conteúdo tá tendo uma nova forma de representação do texto e depois pode usar uma abordagem clássica aí um algoritmo de aprendizado para fazer classificação de textos né E o nosso decoder né que seria a segunda parte para fazer geração de textos né que aí vocês tem um exemplo do chat GPT etc né que utiliza essa etapa de decoder né que na verdade agora a partir daquela representação a gente vai fazer a geração de texto que também tem seis camadas e além dos blocos em colder utiliza um bloco Extra de
atenção também aqui né que são os tokens gerados tá então o que que a gente tem aqui de vantagens né da da utilização de Transformers né a gente tem eficiência no processamento flexibilidade na modelagem de relações não lineares introduz esse mecanismo de alta tensão né que isso tentando sinalizar os transformas né E tem alguns modelos de estado da arte né A gente vai ver aqui agora que utilizam esses Transformers o back é um deles já tinha PT já PT é outro né então só para falar para vocês um pouquinho rapidinho sobre o Bert né ele
vem o nome dela que vem do BT vende-se dessa sigla aqui né vai Direction for Transformers então é um modelo de redes orais Profundas conhecido como Transformers também né então a gente tem aqui que o entendimento de linguagem intrisicamente bidirecional por isso que ele utiliza esse modelo bidirecional né então ele tem um decoder bidimensional também então ele acaba treinando esse Encoder de um Transformer para prever algumas palavras mascaradas né que a gente acaba definindo então quando a gente tem pouco a gente mais cara a pouco a gente tem um treinamento muito lento e quando a
gente mascara muito a gente tem pouco contexto para se aproveitar então é importante também encontrar um Trader off né nessa nessa questão Para poder melhorar o funcionamento do Bert né então ele também coloca aqui uma outra ideia pessoal ele também tem uma outra função objetiva que é durante o que são objetivo o que que ele tenta otimizar o que é que ele tenta melhorar durante o treinamento né que é o que se chama nsp né senta se predition então ele utiliza algumas sentenças e verifica se tenta otimizar sempre que uma sem pensar uma sentença saber
é tem que uma sequência da outra né então isso é importante também então a medida você consegue fazer isso otimizar esse tipo de informação é interessante também porque quando a gente vai fazer não só a leitura mas geração do texto é importante que esses textos tenham sejam contextualizados não adianta falar uma frase uma frase seguinte eu falar algo que não tem relação nenhuma com a frase anterior né então isso é uma coisa importante também que o Bart utiliza né Aqui tem alguns detalhes do treinamento de como foi feito o treinamento do BRT né então ele
utiliza o Encoder de transformer ele foi treinado com os dados da Wikipédia né e corpos de livros né e aqui tem dois modelos principais aí que vocês podem dar uma olhada depois nos detalhes tá como utilizar o Berti na prática nós vamos ver isso também na nossa aula prática né então a gente pode aprender um classificador nessa última camada para poder fazer essa tarefa né de dar um stream que a gente quer aprender que nem conversei com vocês antes né a gente tem etapa de pode ter etapa de pré-treinamento e depois fazer uma tunagem né
vamos dizer assim né aprimorar esses esses parâmetros do nosso modelo né então aqui para finalizar pessoal o conteúdo é para mostrar para vocês o que que o Transformers tem na atualidade né os métodos o que a gente tem de estado da arte ultimamente aqui desses últimos quatro vamos dizer assim né três deles utilizam modelos de Transformers né o gpt1 o próprio Bert e o gpt2 por exemplo né então vocês têm aí bastante coisa para poder investigar e aprender né vocês podem dar uma olhada como é que funciona o chat gpt1 para depois ver o que
que melhorou do um pro dois etc vocês vão ver se deparar com esse tipo de de aula que eu tô dando para vocês aqui de forma complementar né que a gente já viu bastante sobre Reis Morais agora vamos ver um pouquinho sobre as redes sociais Profundas para dar um estímulo para vocês aí para aprender um pouco mais né na área né então a gente trabalhou hoje com os modelos Secco Sec falamos sobre mecanismos de atenção e alta tensão até chegar nos Transformers e finalmente falar um pouquinho do algoritmo então na próxima vídeo aula pessoal a
gente vai fazer a nossa aula prática então de classificação de texto tá aqui são as referências que foram utilizadas para essa aula eu agradeço então até a próxima [Música] [Música]