GPT stands for Generative Pre-trained Transformer, the core technology behind ChatGPT, but what is this technology, really? Let's get into it. So let's break this down into what a GPT is, a little bit of history of GPT models, and then an example of how we've put GPTs to work right here in the studio, and let's start with what.
What is a GPT? Well, a GPT is a type of large language model that uses deep learning to produce natural language text based on a given inputs. And GPT models work by analyzing an input sequence and predicting the most likely outputs.
So let's break this down. So we have generative is the G, Pre-trained is the P, and the T that is for Transformer. So what does all of this actually mean?
Well, in generative pre-training, let's let's start with that. So generative pre-training teaches the model to detect patterns in data and then apply those patterns to new inputs. It's actually a form of learning called unsupervised learning, where the model is given unlabeled data.
That means data that doesn't have any predefined labels or categories. And then it must interpret it independently. And by learning to detect patterns in those datasets.
The model can draw similar conclusions when exposed to new unseen inputs. Now, GPT models are trained with billions or even trillions of parameters which are refined over the training process. Now, the T in GPT that stands for Transformer.
Transformers are a type of neural network specialized in natural language processing. Transformers don't understand language in the same way that humans do. Instead, they process words into discrete units.
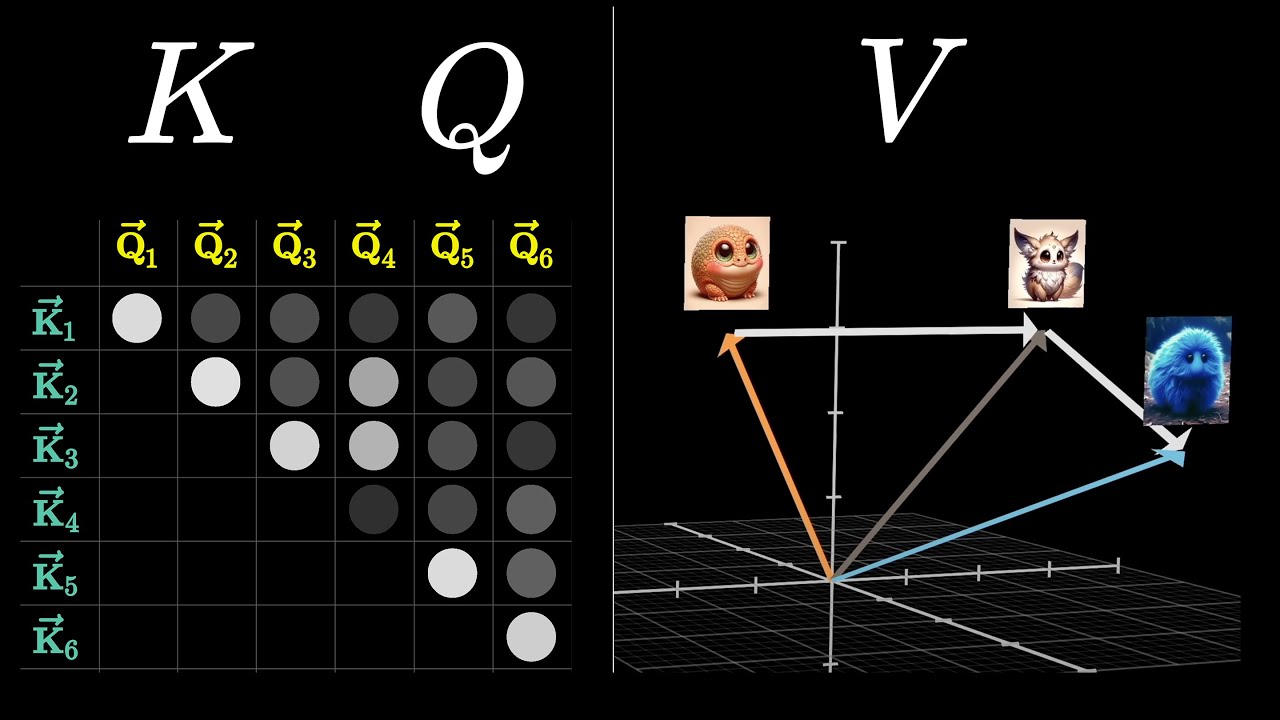
Those units are called tokens, and for those tokens, they're smaller chunks of words or characters that the model can understand and transform all models of process data with two modules known as encoders and decoders. And they use something called self attention mechanisms to establish dependencies and relationships. So let's define what those are and let's start with self attention.
So what is a self attention mechanism? Well, it's really the signature feature of Transform is the secret sauce, if you like, older models like recurrent neural networks or convolutional neural networks. They assess input data sequentially or hierarchically, but transformers can self direct to their attention to the most important tokens in the input sequence, no matter where they are.
They allow the model to evaluate each word significance within the context of the complete input sequence, making it possible for the model to understand linkages and dependencies between words. Okay, so that self attention. What about the encoder?
Well, the encoder module maps tokens onto a three dimensional vector space in a process called embedding tokens encoded nearby in the 3D space or seem to be more similar in meaning. The encoder blocks in the transformer network assigns each embedding a weight which determines its relative importance and positioned encode as capture semantics, which lets GPT models differentiate between groupings of the same words in different orders. So for example, the egg came before the chicken as compared to the chicken came before the egg.
Same words in that sentence, but different meanings. There's also a decoder module as well. And the decoder.
What that does is it predicts the most statistically probable response to the embeddings prepared by the encoders, by identifying the most important portions of the input sequence with self attention and then determining the output most likely to be correct. Now a quick word on the history of generative Pre-trained Transformers. The transformer architecture was first introduced in 2017 in the Google brain paper, "Attention is all you need.
" Today there are a whole bunch of generative A. I. models built on this architecture, including open source models like Llama from Meta and Granite from IBM, and closed source frontier models like Google Gemini and Claude from Anthropic, but I think the GPT model that most comes to mind for most people is ChatGPT from OpenAI.
Now ChatGPT is not a specific GPT model. It's a chat interface that allows users to interact with various generative pre-trained transformers. You pick the model you want from a list and today xthere's likely to be a GPT4 model like GPT4o.
But the first GPT model from OpenAI was GPT-1, and that came out back in 2018. It was able to answer questions in a humanlike way to an extent, but it was also highly prone to hallucinations and just general bouts of nonsense. GPT2 That came out the following year as a much larger model boasting 1.
5 billion parameters. Sounds like quite a lot. Since then, linear scaling has resulted in each subsequent model becoming larger and more capable.
So by the time we get to today's GPT4 models, well, those are estimated to contain something like 1. 8 trillion parameters, which is a whole lot more. So we talked about how a GPT is a fundamentally different type of model, one that uses self attention mechanisms to see the big picture and evaluate the relationships between words in a sequence, allowing it to generate contextually relevant responses.
And I'd like to share a quick example of how that's helped right here in my role in video education. We create close captions for every video using a speech to text service. Now here's a snippet from the course I was working on this week showing the transcript and the timestamps.
Now it's not bad, but there are some errors. It's mis transcribed Cobal as CBL. It's missed me saying a T in HTTP and it had no idea that K.
S. is actually a product called CICS, which is pronounced kicks. And that's all typical of air models built on recurrent neural networks that process data sequentially one word at a time.
So I gave this transcript to a GPT model, along with the script that I based my talk on, which I called the ground truth. So this was the actual script that I was reading from. Then I told the GPT to fix the transcript, and here's what it came up with.
It fixed all three errors. CBL is Cobal, KS is CICS, and HTP is HTTP, and in fact, I tried this again, but this time removing the ground truth entirely and instead just gave it a brief synopsis that said This is a video about a modern CISC application and it was still able to fix those three errors. And that's the self attention mechanism at work, processing the entire input sequence and better understanding the context of what I was discussing.
Even without having the exact script in front of it. The GPT model uses broader language and software knowledge to correct technical terms and acronyms. So that's generative Pre-trained, Transformers or GPT as they form the foundation of generative A.
I. applications using transformer architecture and undergoing supervised pre training on vast amounts of unlabeled data. And if you happen to turn video captions on in this video and you spotted an error, well now you know which model to blame.