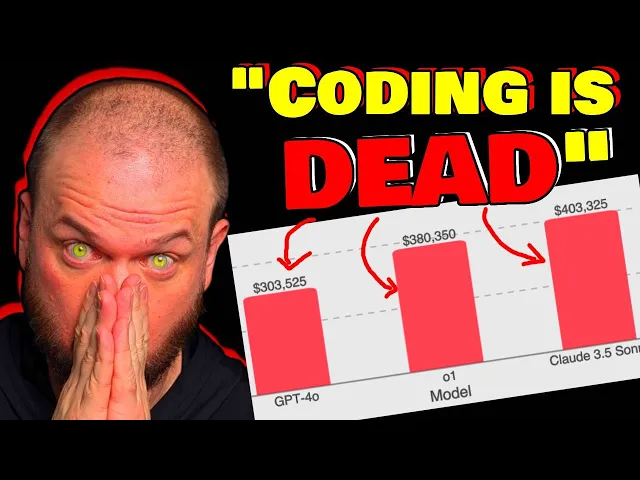
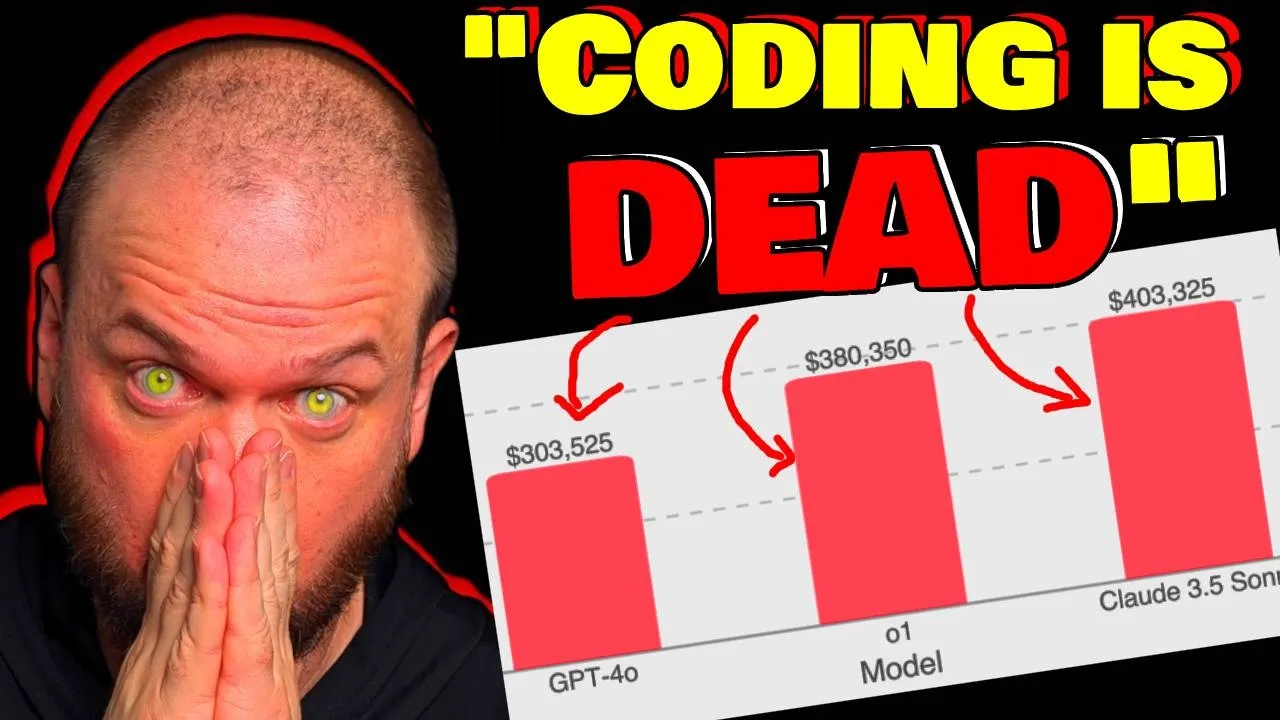
I got 99 problems but a glitch ain't one opening eye introduces theu Lancer a benchmark of over 1,400 freelance software engineering tasks from upwork Real World software engineering tasks which are valued at 1 million Us in real world payouts if I had a million bucks it wouldn't be enough cuz I'd still be writing clever hacks this encompasses both independent engineering tasks ranging from $50 bug fixes to 32,000 feature implementations as well as managerial tasks where models choose between technical implementation proposals open ey thinks that by mapping model performance to actual monetary value they hope that s Lancer enables greater Research into the economic impact of AI model development I got Pennies from my thoughts now I'm rich open ey drops sweet Lancer can Frontier LMS earn $1 million from Real World freelance software engineering one thing that constantly comes up is this idea of how large language models and various other AI tools how they are going to impact software development how they are going to impact the future of coding is it going to be used to sort of replace those High salary positions and replace them with AI tools and this paper I think kind of makes that big leap from talking about you know benchmarks and scores to real world payments to real world currency to actually getting paid for completing tasks right work employment here's from the little announcement of this thing this is an important point to understand so they're saying by mapping model performance to monetary value we hope thatu Lancer enables greater Research into the economic impact of AI model development but I think it's important to kind of keep this in mind so the first reasoning model that opening I had was the millionth best coder in the world I I I would guess they probably had it somewhere around the end of 23 then I believe the 01 in September 2024 that was around the 10,000th best coder in the world then this year right 03 January 2025 the 03 is ranked as the 175th best coder in the world according to code forces so again this is the 03 right there Sam in this interview in Japan shared with us that they do have an internal model that's the 50th best goer in the world and he's kind of guessing that we might have something in near at the top in 2025 you know again we're talking about benchmarks not necessarily how that's translating into real world tasks but we're kind of like approaching that time we slowly going to be transitioning into like what can you actually do in the real world and so what you're seeing that more and more you know Sam Alman is one of the people talking about this but he's certainly not the only one they're beginning to talk more and more in terms of monetary impact job loss what percentage of the workforce can this potentially automate make redundant so let's take a look at this swe software engineering I'll just say s cuz it's easier to say and kind of fun to say too so they introduce a s Lancer a Benchmark that contains over 1,400 freelance software engineering tasks from upor but as you can see here so they've selected various software engineering tasks that are valued you know in aggregate altogether at 1 million Us in real world payout so this is the the salary that you'll be getting paid if you completed all those tasks and S Lancer encompasses both independent engineering tasks ranging from very simple you know $50 bug fixes to $332,000 feature implementations as well as managerial tasks where models choose between technical implementation proposals and of course they they find that you know the frontier models are still not able to solve the majority of tasks but they do provide an open- Source sort of like ability for everybody to test their agents on it to help with future research so that everybody can kind of have visibility in this and test their agents on it and we can see how this field is progressing all right so again they split up into sort of two groups of tasks we have the you know they're going to call it the IC individual contributor right so this is where models generate code patches to resolve real world issues right so the the end sort of the deliverable is some code that satisfies the requirements and there's the S manager tasks where models act as sort of technical leads by selecting the best implementation proposal for a a given problem all right so what are the actual things that we're doing to kind of test these models out to see how well they're able to code here's an example of that kind of independent contractor task so as you can see up here so the original issue so again so this is like one of the little modules within this Benchmark one of little test samples right test problems and we have the the problem the description and the price so here we have an $88,000 sort of issue and the zip SL postcode validation error message not displayed for entering comma on the home address screen so what they do is they take the the code base and they revert it to just right before the fix was implemented right so with a lot of software development you can of have a version control so different sort of checkpoints or save files so you basically able to like go back in time and restore everything to right before it was fixed so human being came in right found the solution and fixed the problem but right before that we have a checkpoint so now we're reverting to that checkpoint and we're telling this model okay now you try fixing it so the model is prompted with a task and ask to produce a patch that resolves the issue so in this example it just adds a zip code validation utility human software Engineers create N2 and tests for the issues right then we have the score and evaluate so the greater human generated n2n test are run against the model's updated codebase and the scoring so if the n2n test is passed the model fix is successful which translates to earned payout so kaching $2,000 earned or $0 earned if it's not successful and then so the other sort of side of the problem the other type of problems that it solves is theu manager tasks right so the original issue this is has a bounty of $250 or or payout rather and reason appears bolded briefly after holding the request and then you have the various proposals on how to approach fixing this right so this is submitted by various users and so the AI model was prompted with a task and told its objective is to choose the proposal that best resolves the issue it chooses proposal number four because and it gives a reasoning it looks like so so it provides a focused quick fix for the Bold styling issue without unnecessary dependencies and for this one if you recall we're just trying to compare it to what the sort of the experienced human manager would do in that situation so compare the lm's choice of solution with the ultimately implemented solution if the model chooses the same thing then earns $1,000 why I think this is such an interesting Benchmark because the the payout that's associated with each task each tasks has an Associated payment with it it's not an estimate right it's the actual amount paid paid to the freelancer who completed it and two those amounts they're they're not trivial right so 35% of tasks are worth more than a th000 34% of the task are 500 to a th000 so as an example of like the task selection right so they've used expensify which is a 300 million USD public company that's traded on NASDAQ with 12 million users who rely on software mean that it's commercially valuable software engineering tasks the open source expensify repository post tasks on upor for freelance Engineers with concrete payouts now the reason I point this out is because um you know obviously the prices that people pay for this stuff you know how do you determine kind of like what's the actual price that the different tasks are worth it's a dynamically priced based on real world difficulty so again that expensify so it's an open source repository right so they they post their issues so that remember that little zip code issue that we were having that the model solved by adding that little test to make sure that um everything's working correctly so this thing where it adds a zip code of validation utility so when I saw the price I was like $8,000 that seems uh that seems like a lot I was a little bit surprised to see that amount being paid for what seemed at first I mean you don't know what's happening sort of behind the scenes but at first glance that seems like a lot of money for that fix well how they arrived at that number is so week one you know when they first posted they're like H we'll pay $1,000 to whomever can solve this issue whenever they're not able to solve it within that week they increase how much they're willing to to pay for it so $2,000 it was increased to $2,000 there were five proposals that were rejected for failing to solve the issue right so you might have had an experience like that where at first you glance at something you're like all right this this should be pretty easy let's let's knock it down one week let's pay a little bit of money if you seen those like home restoration remodeling shows right they're like oh how much is going to cost to like knock down this wall in the bathroom and add a mirror they're like oh it's just going to be $1,000 right then you see him going out of the Hammers right like knocking down the wall they're like oh you have mold that will be $250,000 now please and you see like the couple crying they're like we don't have that kind of money it never makes sense to me what those people like their careers right cuz they're like one is a St stay-at home mom and one is like a middle school teacher and they're like we're buying this 10 Mill home it's like how like who are these people you know anyways but week four they double the price to 4,000 complexity of issue becomes apparent so the independent contractors search for a solution that validates across all Global postal codes right cuz if you remember recall the solution had like whatever 8 to 10 lines where it checks every country's postal code and finally like all right $88,000 after further irration on the last Proposal with the site manager the Bounty doubles and the fix is made so this seems like a really good way to price these problems because we're posting to the entire world of of people that work on this stuff we like we'll pay you $1,000 to do it right if no if the world is not able to to solell that a th000 we do 2,000 then 4,000 then 8,000 then if right the global Marketplace is able to come up with somebody who is able to and willing to to solve that for $8,000 then that would be like an accurate sort of uh price for that specific request let me know in the comments if you disagree but this seems like a pretty good way of how to Value these tasks but okay take a guess at what these models were doing let's say the 01 the Sonet and the 40 right so from earning $0 and just failing at uh doing this to earning 1 million like where are we in this process right now right is it is it is it here is it almost at a million right that would be kind of scary where do you think these models kind of fall for me I was going to guess like somewhere like 10% so that's like 100,000 somewhere in this range I was kind of surprised it's definitely higher than where I thought it would be so here it is GPT 40 the 01 and Cloud 3. 5 Sonet Sonet is of course a lot of people love it a lot of people are are saying this is this is the best model I think that's the first model that maybe like sit up and take notice of like whoo like it's getting pretty good at coding and so of course um you know 400,000 out of a million right so so 40% out of the total tasks that um it could complete to to earn money it did right 40% 400,000 out of 1 million that seems scary doesn't it that seems like a lot higher than I would have guessed at this point in time right then the 01 at 380 so you can say 38% and then GPT 40300 so 30% the other thing to keep in mind here is so Cloud 3. 5 is you know if we're looking at something like this we verified right so in coding it's one of the better models on those benchmarks but there's a lot of ones like the 03 mini High the 01 I mean they're up there as well right so as you can see here Cloud 3.
5 is at 50. 8 but we we've got some close contenders we have deep seek R1 open AI 01 openi 3 mini High I mean they're all with just a few ten of a uh % of each other they're pretty close but can you spot the problem the problem is CL 3. 5 Sonet it's not the best right so there is the best one it's this one right here open ai3 and openi 03 sits at 71.
7 now it's unreleased and so you know we can't like confirm it and also we don't know if that directly you know sort of translates into it being as good on you know the other sort of like the real world tasks but it's it's 42% better than Cloud 3.