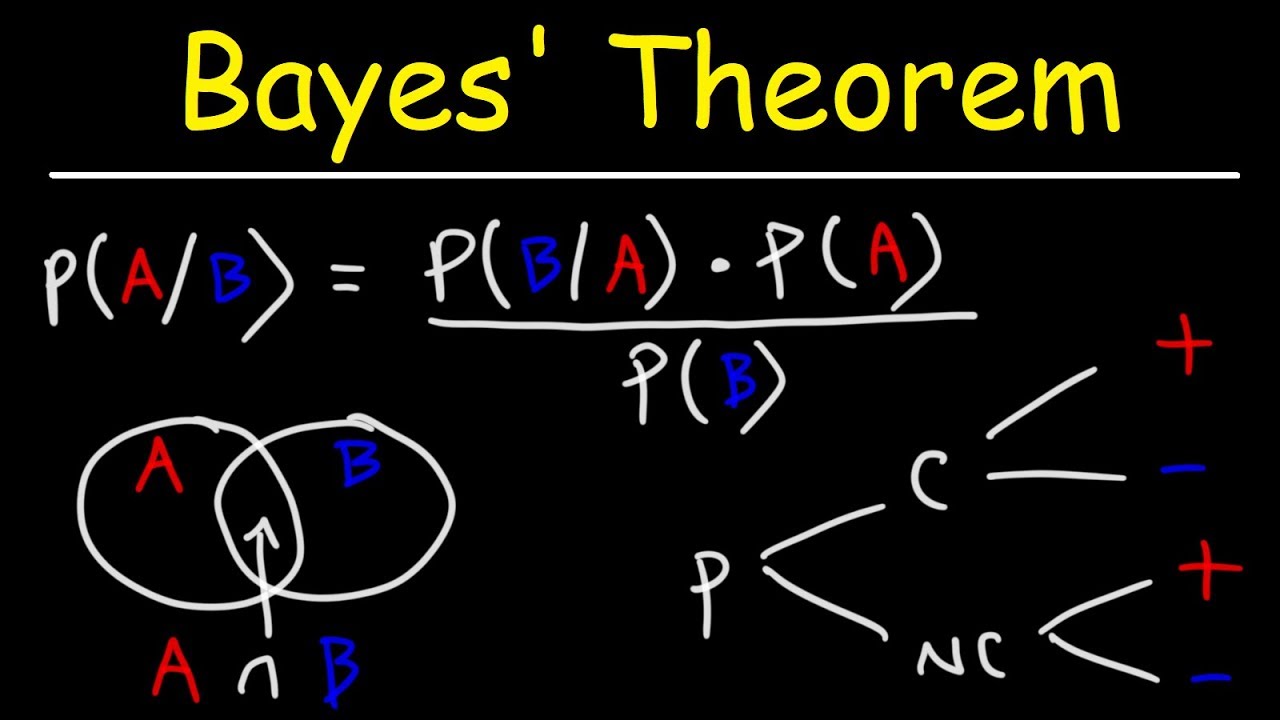
welcome back so today we're going to introduce one of the most useful ideas in all of probability which is BAS theorem this is used all across the board in statistics uh practicing statisticians use Bas theorem all the time this is a Cornerstone of machine learning inverse problems and Engineering inference problems uh one of the most important ideas so we introduced this notion of a conditional probability that maybe I'm trying to compute the probability of event a happening but I have some additional partial information about event B some other event um that could have happened and so I can update or improve my estimation of the probability of a happening given that I know that b also happened so the probability of a given B is the probability that both things happened divided by the probability that event B happened um this makes a lot of sense um pretty pretty straightforward idea um I'm going to write down one extra fact here I think uh we're going to need later is that you can multiply these and say that the probability of A and B is probability of a given btimes probability of B this is just the multiplication law but in statistics and in probability often we want the opposite uh information so maybe um a is maybe B is some disease whether or not you do or don't have cancer and maybe a is a test result or some symptom that you present so I could you know compute the probability of having that symptom given that I have cancer but what's much more useful is given that I have a positive test result or given that I have symptom a what is the probability of an underlying cause like cancer this is much much more useful and this is called an inverse problem because I'm trying to compute the probability of something that's actually quite difficult to measure using uh some observable some measurement that I actually can measure this event a so Baye theorem is going to flip this on its head and I want us to always be thinking what can you measure what do you have access to um and what is an inverse problem or a forward problem because I mean I could always just switch the order of the letters um and this becomes that but that's circular so you know think about it this way uh what's the probability that I have cancer given that I have a positive test result or I have a symptom okay that's the kind of thing you would want to estimate and this one's hard to measure this one is easy to measure or expensive and cheap or invasive and non-invasive okay and so Baye rule I'm just going to State it essentially I'm going to State it in in easy medium and advanced uh is the following so Baye theorem maybe I'll write this in blue says that the probability of B given a is equal to the probability of a given B times the probability of B divided by the probability of a now we'll we'll work through where this all comes from how to do this in a minute um and it essentially comes from the fact that probability of B given a and probability of a given B both have this term in common this probability of A and B so probability of A and B is probability of a given btimes probability of B it's also the probability of B given a times the probability of a okay that's this is also true I could literally just uh flip these two and you know this would become probability of A and B divided by probability of a good and so now I can rewrite this as um yeah so I can set these two equal to each other and I get the probability that b given a is all of this divided by the probability of a really really simple okay so this is kind of a trivial outfall of of just the definition of a conditional probability and this basic multiplication uh law here okay so you know this is true for any sets A and B and this is true for any sets A and B and so now if I have something that's hard to measure B I can do this inverse problem with the information that I do have access to okay um and these things have names in beian inference in the field of beian statistics and beian machine learning so I'm just going to like remind you of what these things are called this uh probability of B given a is um is essentially called your posterior uh sometimes called your derrier distribution the posterior uh probability of B is your prior so again if I'm saying like what is the chances that I have cancer if I don't know anything else then I have the same chances of having cancer as anyone else with my basic approximate you know whatever demographic um age group and that would be my prior is like a whatever one in whatever chance um population statistics but then if I take a test or if I have a symptom I can update my probability of having cancer given that extra information about a and I do it using uh using this kind of this kind of update so probability of a given B is my update this is my prior this is my best guess before I got this piece of information a and this is my update uh and then this is you know some normalization constant based on what's the probability of you know getting a pro positive test result period and in its simplest form this is Bay theorem this is how you compute this inverse probability using things that I can calculate pretty easily and my prior distribution now I'm going to have like a whole series of lectures on B theorem and beian inference and beijan statistics um probably later probably in the kind of Statistics module but the reason this is called an update is because this can help me do all kinds of interesting things like um imagine I have a coin actually I do have a coin somewhere here I have a coin and I'm going to start flipping this coin and let's say I don't know anything about this coin I don't know you know maybe I assume it's fair let's say I that's my assumption my prior is that it's a fair coin and you know the probability of heads is 50% but let's say I flip this over and over and over again I flip it 10 times and I get ta Tails 10 times in a row that is new information that I can update my probability of it being a Fair coin and every time I gather new information I take my prior and I update that probability and then the next time I collect information this becomes my prior for the next experiment I gather that information and I update my probability then it becomes my prior for the next experiment I gather more information a and I update my probability I'm massively oversimplifying but that's the basic idea of all of bean statistics is that I run sequential experiments I gather data sequentially and I have some initial guess and I update that distribution or that probability or that that estimation using this new piece of information this update that I got that's a massive simplification but that's the basic idea okay um so this is one way of writing it this probability of a happening is sometimes also hard to compute so I'm going to write another version of this let's uh let's write this kind of next version here so now I'm going to say the probability of B given a is the probability of a given B times the probability of B nothing is changing here but now this probability of a I'm going to use my law of total probability to say that this is the probability uh of a given B times the probability of B plus the probability of a given not b a given we're going to call this B complement that means not B times the probability of B complement that is is another uh formulation probability of a the law of total probability says that it is you know the probability of a given B * probability of B plus probability of a given not B times probability of not B this is again kind of obvious but maybe we don't know what probability of a happening is we don't know the probability of of a positive test result so I can compute it you know using the information I gather and then a final generalization of this if I have a bunch of disjoint sets be a bunch of different disjoint sets is that I can write the probability of um of B let's say that I have you know a bunch of sets B that are covering Omega the probability that event J happens given a is um the probability of a a given this event B J times the probability of that event happening divided by again law of total probabilities the probability of a is going to be the sum over all of these disjoint uh B's probability of a given B times probability of B item J okay so this is just three different levels of the same exact theorem this is if I can compute the the probability of a of my test result being positive this is you know writing this probability using the law of total probability and then this is a generalization if I have a bunch of different events be that I could be testing over okay so realistically this is the one I mostly want you to be thinking about um is Bay theorem here okay super super super super useful okay and this is going to allow us to compute these inverse probabilities let's do some examples I have two examples I want to show you that are going to make this really really concrete okay um maybe the first one I'll do is uh cancer screening I think this is a really good example I'm going to do it over here because this is where my notes are uh and let me just draw a line so the example I want to do first is cancer screening so let's say that I have a test that is 99% accurate I have a test a that's 99% accurate in detecting a rare form of cancer so uh say my test is 99% uh accurate but the disease I'm testing for the cancer I'm testing for is is fairly rare um but the disease or the cancer is very rare is is uh very rare So 0. 001% of population have this disease okay so one in a thousand people have the disease not 0. 001% I'm sorry just 0.
001 1 in a, . 1% uh of the population have this disease and the test is 99% accurate simple simple um let's now see what is the probability of actually having that disease given a positive test so let's define our A's and our B's okay so a is a positive test I'm going to write that as positive and B is I have the disease the cancer uh or not so you know again disease or not disease so the way we compute this we want to compute the probability of having the disease given a positive test okay so the probability of having the disease given a positive test let's use Baye theorem here actually we're going to use this second form of bay theorem it's the probability of having a positive test given the disease times the probability of disease okay divided by by this same probability probability of positive given disease time probability of disease plus probability of positive given not having the disease times the probability of not having the disease good okay good uh and we can compute all of these things so I want you to be thinking could I compute this or this or this in this example this happens to be the easiest form because I can compute all of these things so let's just plug in the numbers okay so the probability of having a positive test given the disease it's 99% accurate so this is 099 the probability of having the disease is 0. 001 this is 0.
001 divided by these things so again probability of positive test given the disease 099 probability of having the disease . 0 o1 plus the probability of the probability of a positive test given that you don't have the disease this is only 1% it's a very very accurate test so this is only 0 01 but the probability of not having the disease is 999 999 out of a th people don't have the disease so you can multiply these out just you know do this on your calculator do this in Google whatever and you're going to find very quickly that this is um actually have the answer here it's 0099 divided 01098 which is about 0.