nesse vídeo eu quero falar com você sobre monitoramento e os quatro sinais de ouro para você saber por onde deve começar a monitorar a sua aplicação e a sua infraestrutura Então bora [Aplausos] [Música] [Aplausos] [Música] lá Fala aí beleza seja bem-vindo seja bem-vinda a mais um vídeo aqui no canal eu sou Fabrício Veronez e eu tô aqui para ajudar você a entender mais sobre devops e sobre Cloud Então já s inscreve aqui no canal aciona o Sininho aí embaixo para você não perder nenhum conteúdo irado como esse aqui quando falamos em aplicações modernas projetos desafiadores
e soluções que fazem você se diferenciar no mercado de tecnologia não tem como não pensarmos em monitoramento porque afinal de contas me conta aqui você compraria um carro sem marcador de velocidade sem marcador de combustível ou sinais de alerta no caso de algum problema não né Então por que você ent entrega soluções de software ou infraestrutura sem isso então bora entender o monitoramento e como você pode começar a implementar vamos começar do começo o que é monitoramento monitoramento é o processo de coletar processar e exibir dados de forma quantitativa baseada em end do tempo o
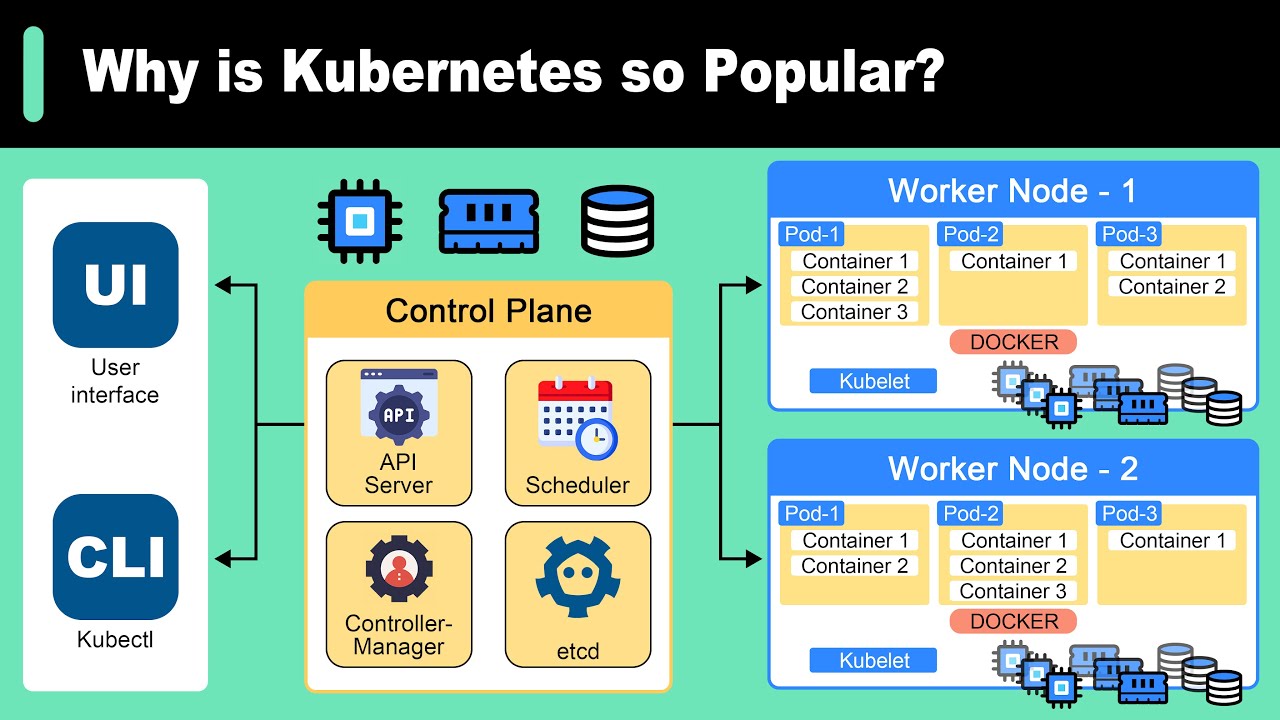
monitoramento vai envolver dados sistêmicos e dados de negócio aqui nós vamos focar em dados sistêmicos ou seja dados da aplicação e da infraestrutura monitorar as suas aplicações e a infraestrutura é um dos princípios básicos do devops com o monitoramento você se antecipa em relação a detecção de erros e pode acabar resolvendo o problema antes mesmo do usuário reparar trazendo uma experiência e confiabilidade muito maior para quem utiliza seus sistemas e dando muito mais segurança para você e pra sua equipe E além disso o monitoramento ele faz parte dos três pilares da observabilidade que é o
monitoramento o log e o Trace e para você se diferenciar nesse mercado de tecnologia você precisa saber esses conceitos então eu vou fazer o seguinte eu vou deixar também aí embaixo na descrição do vídeo onde eu falo sobre observabilidade para você conferir depois beleza agora que você entende o que é monitoramento você deve estar pensando legal Fabrício mas por onde eu começo o que eu devo monitorar logo de cara essa pergunta é muito comum e esse é o maior objetivo do do vídeo te ajudar a entender o seu ponto de partida Então vamos falar agora
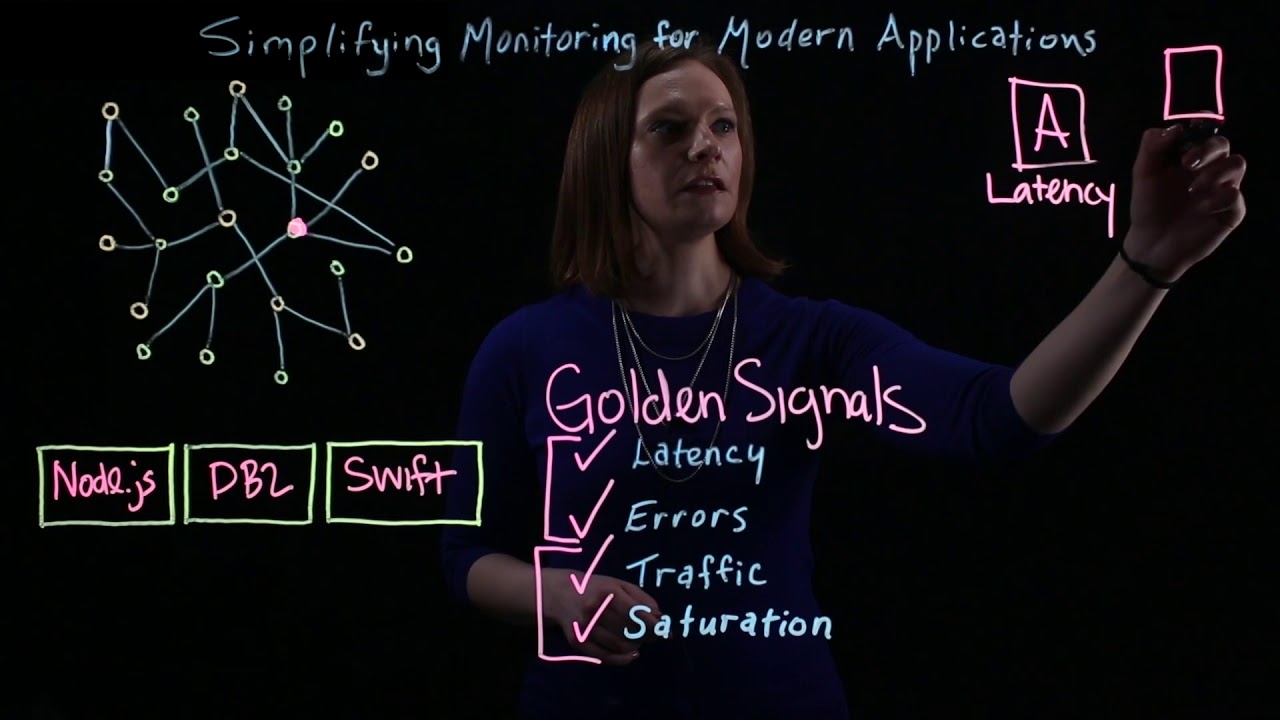
sobre os quatro sinais de ouro os quatro sinais de jogo são as quatro métricas básicas que você deve medir no seu sistema latência tráfego erros e saturação elas são recomendadas pelo time de sre do Google e você pode ler mais sobre isso no livro engenharia de confiabilidade do Google como o Google administra seus sistemas de produção vai tá aparecendo aí em algum lugar do vídeo a capa para você dar uma conferida cara é uma leitura que eu recomendo muito então se você não puder medir mais nada você deve ter pelo menos essas quatro métricas Então
vai é um excelente ponto de partida aqui para você começar a monitorar show de bola mas antes da gente falar sobre essas quatro métricas faz o seguinte solta um like aí no vídeo pro YouTube entender que esse conteúdo é de qualidade Vale a Pena Ser distribuído Fala sério um assunto importante como esse solta o like aí para de trazer mais pessoas aqui pro Canal e também se inscreve aí no canal se você ainda não se inscreveu Beleza então agora que você deu o like vamos começar aqui falando sobre latência latência é o tempo que leva
para responder uma requisição por que isso é crítico porque A latência é Muitas vezes a primeira métrica que o seu usuário vai perceber mas ele vai falar isso de uma outra forma para você e vai ligar para você e falar assim olha eu tô tentando acessar aqui minha aplicação mas tá muito lento Então você já pode medir o tempo de respostas das requisições da sua aplicação monitorando o tempo que as suas apis levam para retornar a resposta das requisições ou você pode também medir o tempo de carregamento da página e por aí vai cada aplicação
vai ter uma forma de medir mas é importante você separar a latência das requisições bem sucedidas das mal das mal sucedidas ou seja dos erros porque pode acontecer das respostas com erro comprometer a exatidão da sua métrica então separa a latência das respostas com sucesso e também as sem sucesso o tráfego representa o volume de demandas que uma aplicação ou o seu ou seu serviço recebe pode ser ali o número de requisições ou chamadas da sua aplicação web a quantidade de usuários simultâneos acessando ali um serviço ou a quantidade de operações de leitura e escrita
em um banco de dados tudo isso é o tráfego normalmente o tráfego você vai medir usando a quantidade de requisições ou chamadas em um segundo medir o tráfego da sua aplicação vai ajudar a você entender mais os padrões de uso os momentos que a sua aplicação ou serviço são mais ou menos utilizados pode ajudar você também a prever e medir momentos que você vai precisar escalar sua infraestrutura e os momentos que você pode diminuir os recursos computacionais trazendo aí também economia na sua solução e uma outra dica é separar as requisições em grupos específicos por
exemplo em aplicações web você pode medir as requisições feitas para serviços estáticos e conteúdos que precisam ser executados de forma dinâmica consultar ali um banco de dados ou algo assim legal então depois de entender a latência e o tráfego precisamos falar também sobre erros os erros podem dizer muita coisa sobre a saúde da sua aplicação e também da sua infraestrutura Então obiter os erros e categorizar eles da maneira correta ajuda muito você a atuar da maneira mais rápida no problema real da sua aplicação ou da sua infraestrutura trazendo aí uma experiência fantástica pro usuário mas
o que são os erros e como eu posso categorizar eles exatamente Erros podem ser requisições http que Retornam ali o os conhecidos códigos né http 404 de notfound e o 500 de interno server erro e por aí vai não ten que falar aqui devagar porque meu inglês é aquela parada né Mas além disso podem ser exceções lançadas pela sua aplicação como falhas de autenticação também e timeout de conexão ou até mesmo transações que não foram completadas ali Conforme você esperava a importância de monitor ar e categorizar os erros tá na capacidade de identificar rapidamente Onde
e por algo falou e aqui também é muito importante que devis e Ops consigam ali seguir boas práticas de tratamento e propagação de erro você nunca viu olha isso é muito comum eu já vi várias vezes mas você nunca viu retornar um código de status 200 retornando uma mensagem de erro Pois é isso é erro ou é sucesso então Então esse tipo de retorno fica complexo de você pegar pela ferramenta de monitoramento então é importante você desenvolver os retornos de forma correta seguindo ali os padrões e sendo assertivo para ajudar a resolver problemas realmente Então
cara deu erro Retorna ali o http status de erro deu sucesso beleza Retorna ali o http status eh com de sucesso e isso também você vai utilizar em aplicações que não são necessariamente web Mas você tem que seguir boas práticas e agora por último mas não menos importante nós temos a saturação e se você acha que erros e latências são críticos espera até você ver o que a saturação pode fazer a saturação ela mede quanto um serviço tá sobrecarregado ou sobrecarregando os recursos disponibilizados e tá diretamente ligado à capacidade do sistema a saturação não é
só um servidor que atinge ali 100% de consumo de CPU ou de memória pode ser uma fila de processamento que tá sempre ali crescendo um disco que tá lento por conta de excessos de operações de escrita ou até mesmo a banda de rede que pode est próxima do limite então é importantíssimo monitorar a saturação monitorar a saturação faz você entender onde a sua infraestrutura ou aplicação tá sobrecarregada onde tá um possível gargalo antes que isso se torne realmente um problema e fique visível pro usuário além disso a saturação pode ser um indicador de que você
precisa escalar o seu serviço Ou a sua infraestrutura Então monitore as principais métricas de desempenho de hardware como uso de CPU memória disco rede e também da aplicação e você pode inclusive utilizar essas métricas para itar recursos de autoscaling também show de bola agora que você sabe por onde deve começar a monitorar o seu ambiente você deve estar com a seguinte dúvida né qual ferramenta eu uso e aí eu vou te responder da forma que você não vai curtir tudo isso depende que existem diversas ferramentas de monitoramento hoje no mercado tem zabic datadog New helic
e d Trace tem elastic Prometeus tudo depende dos requisitos da da empresa o Skill técnico da equipe o ambiente das aplicações e também né o orçamento que você tem para isso mas eu vou fazer o seguinte eu vou deixar aqui embaixo na descrição do vídeo uma aula que eu fiz aqui no canal sobre monitoramento de aplicações com Prometeus e pode ter certeza que vai ser um excelente ponto de partida para você então é isso eu espero que o conteúdo do vídeo tem ajudado você a entender mais sobre monitoramento e os quatro sinais de ouro para
você você começar a monitorar as suas aplicações e a sua infraestrutura Então você já pode começar a monitorar a latência o tráfego e os erros também junto com também a saturação para você não ser mais pego de surpresa beleza e se esse conteúdo te ajudou Coloca aí embaixo nos comentários #rumo Elite e não esquece também de pegar aqui esse vídeo postar no seu LinkedIn dizendo que você aprendeu mais sobre monitoramento e os quatro sinais de ouro para que a sua rede de de rede social né e os recrutadores e recrutadoras vejam que você tá evoluindo
e se preparando para grandes projetos e desafios na área de devops e de cloud E é claro também né solta aquele like Maroto no vídeo pro YouTube entender que esse conteúdo é relevante e vale a pena ser distribuído também não deixa né de se inscrever no canal acionar o Sininho para você não perder mais nenhum conteúdo como esse E é claro a gente se vê no próximo vídeo valeu