Transformers vamos dar uma olhada nas funcionalidades desse modelo e ver como funciona com base no paper attention is how you need Ou atenção é tudo que você precisa esse vai ser um conteúdo um pouco mais denso que o normal então não espere um tutorial com código para fazer uma aplicação qualquer com llm a ideia para esse vídeo é construir uma base sólida para no futuro falarmos mais sobre fine tuning e configurações avançadas nos llms antes de mergulharmos no Transformer vamos primeiro revisar as redes neurais recorrentes ou rnns essas redes eram usadas para a maioria das
tarefas de sequência para sequência antes da introdução do transformer as rnns existem há bastante tempo e permitem o mapeamento de uma sequência de entrada para outra sequência de saída aqui começamos com x como Nossa entrada onde desejamos gerar uma sequência Y inicialmente dividimos a sequência em itens individuais o primeiro item X1 é então usado como entrada paraa rede neural recorrente com o estado Inicial composto tipicamente apenas por zeros a rede neural recorrente produz uma saída chamada y1 no primeiro time step isso é chamado de Hide and state ou estado oculto da rede em cada time
step pegamos o estado oculto da time step anterior junto com o token da entrada atual e passamos pela rede para produzir um token de saída esse processo é repetido para cada time step na sequência até que tenhamos gerado um token de saída para cada token de entrada resultando em uma sequência de saída com o mesmo comprimento que a sequência de entrada em outras palavras se você tem n tokens precisa de n time steps para mapear uma entrada de sequência n em uma saída de sequência n bom rnns funcionam bem para muitas tarefas mas tem problemas
com sequências longas elas são lentas por causa da operação for loop para cada token de entrada isso torna o treino difícil para sequências mais longas então quanto mais longa a sequência maior é o gasto computacional tornando a rede mais desafiadora para treinar sequências longas outro problema são os vanishing ou exploding gradients ou gradientes que explodem é um problema comum em redes neurais usando frameworks como pyos nossas redes são convertidas em um grafo computacional esse grafo calcula a derivada da função de perda ou loss function para cada peso na rede para entender melhor esse problema ah
Vamos considerar o grafo simples Suponha que temos duas entradas x e y nosso gráfico multiplica essas duas entradas para obter um resultado que é dado a outra função que o eleva ao quadrado A derivada da função de perda para cada peso é calculada tomando a derivada da função de saída a função ao quadrado para todas as suas entradas no entanto quando os gradientes se tornam muito pequenos ou muito grandes isso pode causar problemas com o processo de treino is é conhecido como problema de gradientes que desaparecem ou explodem técnicas como weight initialization radiant clipping e
Bat normalization são usad para lidar com esse problema quando temos uma sequência uma cadeia uma Shen com muitos nós o comprimento da sequência aumenta por exemplo a computação se torna mais longa Se tivermos 100 ou 1000 nós em uma Shen vamos supor que temos dois nós e ambos contém 0.5 quando multiplicamos esses dois números O resultado é 0.25 menor que os números iniciais se os números forem menores que um multiplicá-los juntos vai produzir um número menor agora o inverso Suponha que os números sejam maiores que um nesse caso essa multiplicação Vai resultar em um número
maior que ambos quando temos uma sequência longa ela pode eventualmente produzir um número muito grande ou muito pequeno o que também não é desejável primeiro porque nossa CPU ou GPU só pode representar números até uma certa precisão digamos 32 bits ou 64 bits se o número se tornar muito pequeno a contribuição desse número pra saída vai se tornar muito pequena então quando o pytorch ou outro Framework calcula Como ajustar os pesos o peso vai se mover muito lentamente porque a contribuição desse produto vai ser um número muito pequeno isso significa que o gradiente está desaparecendo
em outras palavras ele pode explodir e se tornar um número muito grande que é um problema grave bom o próximo problema que precisamos resolver agora está relacionado à dificuldade de recuperar informações de muito tempo atrás para entender isso precisamos primeiro Lembrar que no exemplo anterior Vimos que o primeiro token de entrada é dado a rede neural recorrente junto com o primeiro estado é importante notar que a rede neural recorrente Como eu disse antes é um longo grafo computacional ela vai produzir um novo Hidden state depois outro e outro então ela usará o último Hide and
state e o próximo Token para gerar a próxima saída no entanto Suponha que temos uma sequência de entrada muito longa o último token será um Hidden state que é muito diferente do primeiro token devido a long a sequência de multiplicação Isso significa que o último token não é tão dependente do primeiro isso é problemático porque os humanos sabem que em um texto longo o contexto que vimos centenas de palavras atrás ainda é relevante para o contexto das palavras atuais infelizmente a rede neural recorrente não pode modelar isso de maneira efetiva e é por isso que
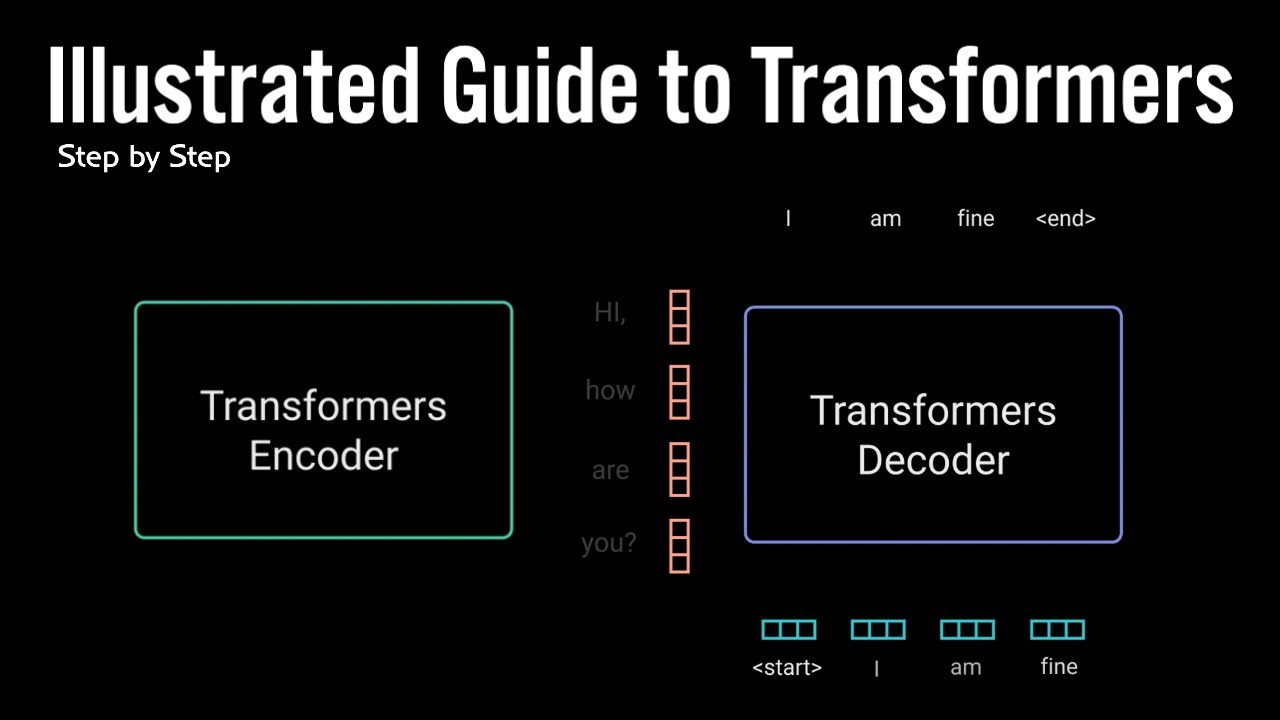
temos o Transformer esse modelo resolve esses problemas e agora vamos ver como a arquitetura do transformer tem duas partes principais o o Encoder e o Decoder o Encoder é a primeira parte o Decoder é a segunda parte a terceira parte é uma camada linear com a função específica que veremos mais tarde a o Encoder e o Decoder são conectados por uma conexão onde a saída do Encoder é enviada como entrada para o Decoder agora Vamos explorar essa conexão em mais detalhes vamos começar apresentando algumas notações que usarei ao longo dessa explicação e é importante que
você esteja familiarizado com elas para começar vamos vamos revisar a multiplicação de matrizes Imagine que temos uma matriz de entrada que é uma sequência de palavras essa sequência é um de moddel e eu vou explicar porque ela é chamada assim mais tarde então temos uma matriz de 6 por 512 onde cada linha representa uma palavra mas a palavra não é feita de caracteres em vez disso é feita por 512 números então cada palavra é representada por 512 números na matriz São 512 números ao longo de cada linha e seis linhas no total Então vamos nomear
essas palavras como a b c d e e f se multiplicarmos essa Matriz com outra Matriz que é a transposta da Matriz original as linhas se tornarão colunas e as colunas se tornarão linhas Então essa Matriz será uma matriz de 52 por 6 onde a primeira coluna representará palavras a segunda coluna representará as palavras a b c d e e e f cada coluna terá 512 números assim como antes se multiplicarmos essas duas matrizes vamos obter uma nova Matriz de 6x 6 cancelamos as dimensões internas e obtemos a dimensão externa então a nova Matriz terá
seis linhas e seis colunas para obter os valores nessa Matriz de saída 6x 6 pegamos o produto escalar de linhas e Colunas da primeira Matriz nesse caso a matriz A o primeiro valor é obtido multiplicando a primeira linha da primeira Matriz com a primeira coluna da segunda Matriz até a última coluna o produto escalar é a soma dos produtos dos elementos correspondentes em dois vetores nesse caso pegamos o produto escalar das linhas da Matriz a com suas colunas para obter os valores da Matriz de saída bom no Transformer vamos começar olhando para o Encoder o
Encoder começa com embs de entrada mas o que exatamente são inputting bearings bem Imagine que temos uma frase nós a dividimos em palavras e Então mapeamos essas palavras em números esses números mostram a posição das palavras em nosso vocabulário Suponha que temos um vocabulário de todas as palavras em nosso conjunto de treino nesse caso cada palavra terá uma posição nesse vocabulário por exemplo your ou seu pode estar na posição 105 e a palavra Cat ou gato na posição 42 42 e assim por diante pois bem pegamos esses números chamados ids de entrada e os mapeamos
em um vetor de tamanho 512 esse vetor é feito de 512 números e sempre mapeamos a mesma palavra para o mesmo elling no entanto esse número não é fixo é um parâmetro pro nosso modelo então ele vai aprender a mudar esses números para representar o significado da palavra já os ids de entrada nunca mudam porque nosso vocabulário é fixo mas os in berings vão mudar junto com o processo de treino do modelo eh Então os números usados para ining eh mudarão com base nos requisitos da função de perda ou Lost function o emb de entrada
basicamente mapeia nossas palavras únicas em um emb de tamanho 512 e nós chamamos essa quantidade de 512 de módel porque o mesmo nome usado no paper attention isal unit passando para a próxima camada do Encoder temos o positional encoding o propósito disso é fornecer informações sobre a posição de cada palavra dentro da frase embora a gente tenha uma matriz de em berings elas não transmitem nenhuma informação sobre a posição da palavra na frase portanto Encoder de posição ou positional encoding é responsável por fornecer essas informações queremos que o modelo trate palavras próximas umas das outras
como próximas e palavras distantes como distantes Essas são informações espaciais que observamos com nossos olhos quando lemos uma frase porém o modelo não consegue perceber essas informações Então precisamos fornecer alguns detalhes sobre como as palavras são distribuídas espacialmente dentro da frase ou seja queremos que o modelo seja capaz de aprender com um padrão criado pelo positional encoding para fazer isso começamos com uma frase como your cat is a lovely cat ou seu gato é um gato adorável e convertemos essa frase em em berings usando a camada anterior essas inputting bearings T um tamanho de 512
então criamos vetores de positional encoding vetores especiais que adicionamos as in berings o vetor vermelho aqui é um vetor fixo de tamanho 512 que não é aprendido ele é computado uma vez e não é aprendido junto com o processo de treino ou seja ele é fixo e representa a posição da palavra na frase quando somamos esse vetor com o vetor de entrada obtemos um novo Vetor de mesmo tamanho do vetor de entrada esse processo nos permite criar um padrão a partir do Qual o modelo pode aprender beleza mas como esses vetores de positional encoding São
calculados vamos ver vamos considerar uma frase menor your cat is primeiro criamos um vetor com o tamanho de 512 então para cada posição nesse vetor calculamos o valor usando duas expressões dependendo da posição da palavra na frase para posições pares como 02 4 510 e outros mais usamos a primeira expressão que é uma função seno e para posições ímpares usamos a segunda expressão esse cálculo é feito para todas as palavras na frase nome da inber é pi que significa positional encoding e é calculado com base na posição da palavra na frase por exemplo a in
Bering para a primeira palavra your é calculada usando os argumentos pos e two I então isso aqui representa o argumento posos e esse zero representa o argumento tu aqui a dimensão para a primeira palavra é um então usamos a função cosseno PR imber o mesmo processo é repetido para todas as palavras na frase ao trabalhar com modelos baseados em frases é importante observar que as codificações posicionais ou positional encoding permanecerão as mesmas para todas as frases Isso significa que mesmo para sentenças diferentes os vetores serão idênticos porque a positional encoding e são computadas apenas uma
vez durante a criação do modelo então Nós salvamos essas encodings e as usamos para treino e inferência eliminando a necessidade de computável mas porque os autores escolheram as funções de seno e cosseno para representar positional encodings bom podemos visualizar o gráfico dessas duas funções conforme elas se relacionam com a posição é importante notar que a profundidade a dimensão ao longo do vetor representado por 2 I nas expressões anteriores e ao plotar Essas funções podemos ver um padrão que Esperamos que o modelo possa reconhecer Ok a próxima camada do Encoder é a multihead attention mas primeiro
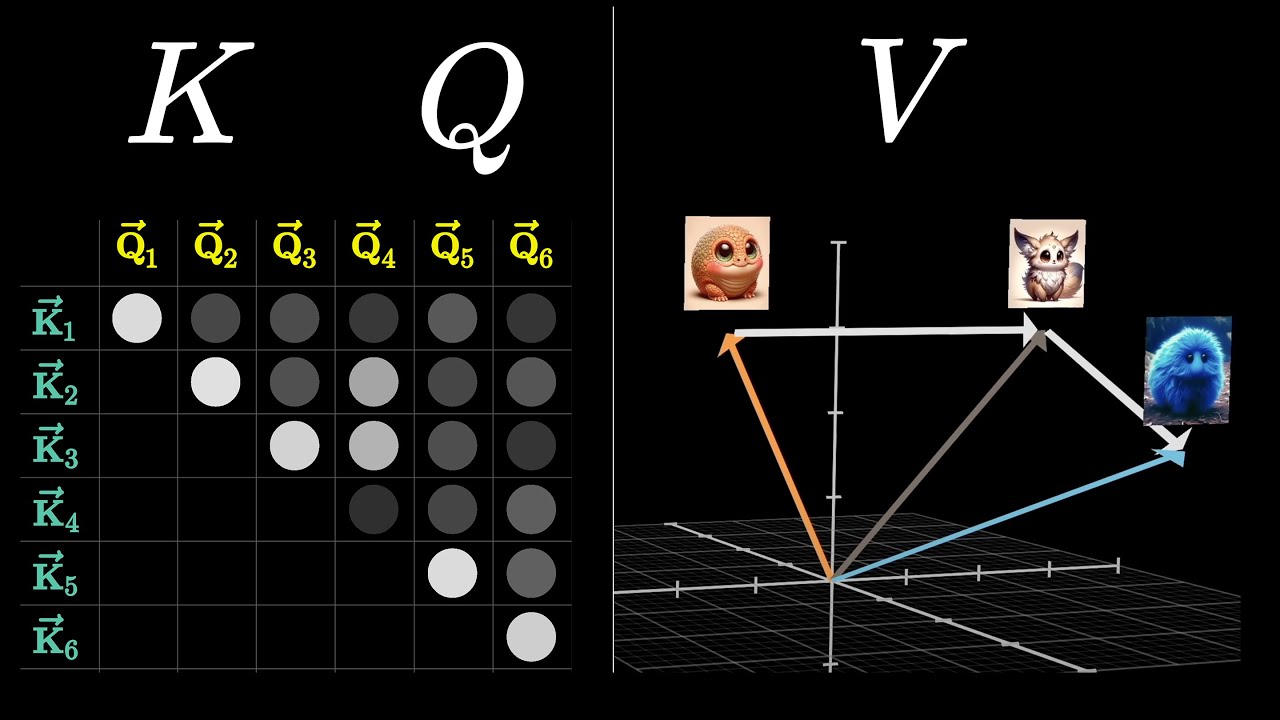
vamos visualizar o mecanismo de autoatenção ou self attention como uma única cabeça antes de entrar em multihead attention a autoatenção É um mecanismo que existia antes da introdução do transformer os autores do transformer apenas fizeram uma adaptação para multihead self atention permite que o modelo relacione palavras entre si para entender a alta tensão considere uma sequência de entrada de seis palavras com de Model de tamanho 512 podemos representar como uma matriz q K e V V onde cada palavra é expressa como um vetor de tamanho 512 q K e V são a mesma Matriz representando
a entrada então aplicamos essa fórmula do paper para calcular a tensão ou alta tensão nesse caso Ah o que permite que cada palavra na frase se relacione com outras palavras na mesma frase é por isso que é chamado de alta atensão Vamos começar com a matriz q que é a frase de entrada Digamos que temos seis linhas e 512 colunas para visualizar então multiplicamos essa Matriz pela mesma frase mas a transpomos a transposição do k é a mesma sequência de entrada então dividimos pela raiz quadrada de 512 e aplicamos o soft Max a saída é
uma nova Matriz que é 6x 6 cada valor nessa Matriz representa o produto escalar da primeira linha com a primeira coluna A primeira linha com a segunda coluna e assim por diante o soft Max garante que todos os valores somem um os valores da Matriz São gerados aleatoriamente o produto escalar da primeira palavra com a iming da própria palavra é representado por um valor na matriz esse valor aqui significa o produto escalar da ining da palavra your ou seu com aing da palavra Cat da mesma forma outro valor representa o produto escalar da ining da
palavra your com ining da palavra is esses valores indicam a intensidade do relacionamento entre uma palavra e outra vamos prosseguir com a fórmula multiplicamos q por K dividimos pela raiz quadrada de DK e aplicamos o soft Max no entanto Ainda precisamos multiplicar por V para prosseguir precisamos multiplicar essa Matriz por v o que Vai resultar em uma nova Matriz de tamanho 6 por 512 quando multiplicamos uma matriz de 6 por 6 com uma matriz de 6 por 512 obtemos uma nova Matriz de tamanho 6 por 512 uma coisa importante aqui é que a dimensão dessa
Matriz é exatamente a dimensão da Matriz Inicial Isso significa que obtemos uma matriz de seis linhas e 512 colunas onde cada linha corresponde a uma palavra e cada palavra tem um embem de 512 dimensões essa inber representa não apenas o significado e a posição da palavra dada mas também sua relação com todas as outras palavras na frase os valores particulares nessa iming capturam a relação única que essa palavra específica tem com todas as outras palavras ou seja essa imber reflete com precisão o significado da palavra e a posição dentro da frase só lembrando que estamos
focando apenas no mecanismo de aut atensão que usa uma única cabeça veremos como isso pode se tornar uma multihead attention mais tarde bom a alta atensão tem algumas propriedades interessantes A primeira é a paration invariant isso significa que se tivermos uma matriz de palavras digamos a b c e d e aplicarmos a fórmula que temos Vamos obter uma nova Matriz com embs específicas para cada palavra a Prime B Prime C Prime e d Prime se mudarmos as posições de quaisquer duas linhas na matriz os valores em cada vetor não mudarão apenas a posição essa é
uma propriedade desejável porque significa que se tivermos outra frase a posição da saída vai mudar de acordo ainda assim os valores de cada vetor vão permanecer os mesmos outro detalhe é que a alta tensão não requer que nenhum parâmetro seja aprendido Pelo modelo para ser mais preciso usei a base inicial de seis palavras multipliquei por ela mesma e então dividi por um valor fixo a raiz Quada de 512 finalmente apliquei o softmax que não introduz nenhum parâmetro Ou seja a alta tensão atualmente requer apenas as in berings como um parâmetro os valores da Matriz ah
softmax de alta tensão são calculados multiplicando cada INB de palavra por ela mesma e pelas outras palavras resultando nos valores mais altos ao longo da Diagonal Além disso substituir um valor específico por minos Infinite Ou infinito negativo impede palavras específicas de interagirem umas com as outras por exemplo não queremos que as palavras your e Cat interajam umas com as outras nesse caso podemos substituir seu valor por minos Infinite então quando aplicarmos o soft Max ele vai substituir esse infinito negativo por zero porque o soft Max é i a potência de X se x for para
menos Infinite e a potência de menos Infinite vai chegar muito próximo de zero esse comportamento é desejável e útil no Decoder do transformer agora vamos dar uma olhada no que é multihead attention já vimos o mecanismo de alta atensão Mas agora vamos converter em multihead attention se você não estiver familiarizado com as expressões não se preocupe porque eu vou explicá-las uma por uma Suponha que temos um Encoder no lado do transformer e uma frase de entrada por exemplo Digamos que a frase de entrada tenha seis palavras e cada palavra tenha um tamanho de em de
512 Isso significa que a sequência tem seis palavras e cada palavra tem um tamanho de Vetor de 512 dimensões nosso processo aqui envolve pegar uma entrada e criar quatro cópias uma cópia enviada por meio de uma conexão visível em contraste as outras três são enviadas para o mecanismo de multihead attention com seus respectivos nomes fazemos três matrizes query Key value todas iguais à entrada Elas têm as mesmas dimensões e são simples ente cópias diferentes da entrada original mas o que esse mecanismo faz primeiro ele multiplica essas três matrizes por três matrizes de parâmetros wq WK
w essas matrizes têm uma dimensão do dmel por dmel quando multiplicamos uma sequência por uma matriz de módel com outra de módel por uma matriz de módel obtemos uma nova Matriz com a mesma dimensão da Matriz Inicial essas novas matrizes são chamadas de q Prime k Prime e v Prime em essa Essência O multihead attention multiplica três matrizes por essas matrizes de parâmetros para obter o novo q Prime kpe e v Prime nosso próximo passo é dividir as matrizes em matrizes menores para conseguir isso Podemos dividir a matriz q Prime pela sequência ou dimensão do
dmel no entanto nós sempre dividimos pela dimensão do de Model Isso significa que cada head vai ver a frase completa mais uma parte Menor da ining de cada palavra por exemplo se tivermos uma ember de 512 dividiremos em empes menores de 512 divididos por 4 que chamamos de Decay portanto Dek é o de Model dividido por e8 onde e8 é o número de Heads no nosso caso atual temos H = 4 usamos a expressão mencionada no paper para calcular a tensão entre matrizes menores Q1 k1 e v1 isso nos dá quatro matrizes pequenas chamadas de
head 1 head 2 Head 3 e head 4 o sequenciamento da dimensão de cada head de head 1 a head 4 é baseado em div div é igual a DK mas é chamado de divi porque a última multiplicação é feita por v o PEP se refere a essa multiplicação final como DV Ah então estamos usando a mesma terminologia aqui agora Precisamos combinar as pequenas matrizes ou Heads concatenando elas ao longo da dimensão de v conforme descrito no paper essa concatenação resulta em uma nova Matriz com a a sequência por 8 multiplicada por D Shape como
D é igual a DK 8 multiplicado por dv é igual a dmel portanto a forma ou Shape original é restaurada e sequenciada pelo dmel próximo passo é multiplicar o resultado da concatenação por w w é uma matriz obtida pela multiplicação de 8 por div O resultado é uma nova Matriz obtida pela multihead attention e sequenciada pelo dmod em vez de calcular a atenção entre as matrizes q Prime k Prime e v Prime a multihead attention as divide ao longo da dimensão do dmel em matrizes menores e calcula a tensão entre essas matrizes menores Isso significa
que cada cabeça observa a frase completa de uma perspectiva Diferente ao fazer o in Bering de cada palavra bom nosso objetivo aqui é usar multihead attention para permitir que cada cabeça se concentre em um aspecto específico da palavra isso é muito útil para idiomas como o chinês onde uma única palavra pode funcionar como um substantivo verbo ou advérbio dependendo do contexto ao implementar multihead attention podemos treinar cada head para reconhecer a palavra como substantivo como verbo ou advérbio melhorando A precisão do processamento da linguagem você provavelmente já deve ter visto que esses mecanismos de atenção
podem ser visualizados vou mostrar como isso é feito quando calculamos a atenção entre as matrizes q e k nessa operação primeiro pegamos o soft Max de q ah depois multiplicamos por k e dividimos pela raiz quadrada de DK isso nos dá uma nova Matriz assim como vimos antes que representa a relação entre cada par de palavras esse score indica a intensidade da relação entre as duas palavras podemos visualizar essa relação produzindo uma visualização semelhante à do paper mostrando como todas as Heads funcionam por exemplo se focarmos na palavra making podemos ver que making está relacionada
a palavra difficult pela blue head pela head head e pela Green head mas não pela Violet head ou pela Pink head a violeta ou a pink head ah relaciona a palavra making a outras palavras como 2009 isso pode ser porque a pink head vê uma parte da ining que as outras cabeças não vem permitindo essa interação entre as duas palavras uma curiosidade e porque essas três matrizes são chamadas de query Keys e values bom os termos vem da terminologia de banco de dados ou de dicionários Python no entanto eu vou deixar a minha interpretação usando
um exemplo simples Vamos considerar um cenário em que temos uma coleção de categorias de filmes e seus respectivos filmes armazenados em um dicionário Python ou em um banco de dados cada categoria de filme fil é uma chave e os filmes pertencentes a cada categoria são os valores quando o usuário faz uma consulta como Love o Transformer vai converter a consulta em um inber de 512 assim como todas as categorias de filmes então ele calculou produto escalar entre a consulta e todas as categorias como mostra a fórmula essa pontuação de similaridade amplifica algumas categorias e reduz
o impacto de outras por exemplo Love e Romantic estão intimamente relacionados enquanto amor e comédia tem uma relação porém menos forte por outro lado Love e kill não estão relacionados de forma alguma esse processo nos ajuda a encontrar as categorias mais relacionadas à consulta do usuário voltando ao Encoder a próxima camada é a camada add enorm vamos começar entendendo o que é a normalização de camadas Imagine que temos um lote de n itens onde n é igual a 3 item Um item do e item 3 isso cada item tem características como uma ining ou um
vetor de tamanho 512 processo envolve calcular a média e a variância de cada item de forma independente depois substituir cada valor por um novo valor normalizado entre 0 e 1 esse novo valor é obtido por uma expressão específica Ah ele é multiplicado por um parâmetro Gama e adicionado a um parâmetro Beta esses parâmetros Gama e beta são aprendí o que significa que o modelo aprende a ajustar esses parâmetros esse processo ajuda a amplificar ou diminuir valores Com base no que é necessário Vamos considerar o seguinte para representar visualmente a diferença entre betat norm e layer
norm na normalização da camada calculamos os valores pertencentes a Um item no lote tratando cada item no lote de forma independente e tendo sua própria média e variância por outro lado na bnm nós calculamos o mesmo M recurso para todos os itens no lote misturando valores de itens diferentes no mesmo lote Bom agora vamos dar uma olhada no decoder comparados ao Encoder os enss de entrada agora são chamados de embs de saída mas funcionam de forma semelhante o Decoder também inclui um positional encoding semelhante ao Encoder a próxima camada é a masc multihead attention temos
também a multihead attention aqui podemos ver que o Encoder produz a saída enviada para o Decoder como Keys e values enquanto a query vem do Decoder nessa multired attention é uma Cross attention Ou atenção cruzada não é um mecanismo de alta atenção comum pois envolve duas sentenças uma do Encoder e uma do Decoder a saída da masked multihead attention é usada como query nessa multihead attention essa atenção Se concentra na sentença de entrada do Decoder transformamos a sentença de entrada do Decoder em em bings adicionamos positional encoding e passamos para mulhe attention onde a consulta
chave e valor são a mesma sequência de entrada depois de executar AD norm nós usamos a saída como as queries da multihead attention enquanto as chaves e valores vem do Encoder em seguida executamos a add e norm novamente aqui eu não vou cobrir o feed forward que é simplesmente uma camada totalmente conectada a saída do feed forward é enviada para adorm e finalmente para a linear layer que veremos mais tarde vamos ver agora como a masca de multihead attention difere a da multihead attention normal para alcançar a causalidade no modelo queremos que a saída em
uma posição específica dependa apenas das palavras da posição anterior Isso significa que o modelo não deve ser capaz de ver palavras futuras podemos manipular a saída soft Max ah na fórmula de cálculo de atenção para atingir isso podemos ocultar a interação de certas palavras com palavras futuras substituindo valores específicos por Minus e finite antes de aplicar o soft Max isso vai fazer com que o soft Max substitua esses valores por Zero ao fazer isso garantimos que certas palavras não interajam com palavras futuras permitindo que o modelo aprenda a não deixar essas palavras interagirem Ok vamos
ver agora como o Transformer funciona para treino E inferência para isso vamos focar em tarefas de tradução começando com o treino do modelo usaremos o exemplo de traduzir a frase em inglês I love you very much para a frase em português te amo muito para começar descrevemos o modelo Transformer E começamos com a nossa frase em inglês primeiro adicionamos tokens especiais um indicando o início da frase e outro indicando o fim esses tokens fazem parte do vocabulário do modelo e ajudam a identificar o início e o fim da frase vamos entender a importância disso mais
à frente Ah mas por enquanto pense AP que precisamos adicionar esses tokens especiais à nossa frase começamos transformando os inputs em eddings de entrada então adicionamos positional encoding e enviamos ao Encoder Essa é a entrada do nosso Encoder sequenciada pelo dmel o Encoder processa a entrada e produz uma saída conhecida como Encoder output a saída do Encoder é uma matriz com as mesmas dimenções da Matriz de entrada a inber ind de cada palavra captura seu significado posição ação com todas as outras palavras graças ao mecanismo de alta tensão isso significa que cada palavra na frase
interage com todas as outras palavras precisamos traduzir essa frase para o português para fazer isso começamos com a frase te amo muito como entrada para o Decoder o diagrama do transformer mostra que as saídas são deslocadas para a direita o que isso significa isso significa que adicionamos um token especial chamado SOS ou start of sentence o início da frase no início Observe que essas duas sequências são tratadas da mesma forma no Transformer por exemplo se tivermos uma frase curta como teama muito ou uma sequência mais longa elas terão todas o mesmo comprimento quando inseridas no
Transformer mas como fazemos isso adicionamos palavras extras para torná-las do mesmo comprimento por exemplo se nosso modelo puder trabalhar com a sequência de comprimento de 1000 tokens e tivermos apenas oito tokens ah vamos adicionar os outros 992 tokens de preenchimento para tornar essa frase longa o suficiente para atingir o comprimento necessário da sequência primeiro preparamos a entrada para o Decoder a isso envolve transformá-la em bearings e adicionar positional encoding o próximo passo é enviar isso para multihead attention e a causal mask posteriormente enviamos a saída do Encoder como Keys e valys para o Decoder com
as consultas vindas da camada mascarada a saída de todo esse processo é uma matriz sequenciada pela dem mod e ainda um a Bering devido ao seu tamanho de Vetor de 512 para entender o significado da palavra em nosso vocabulário Precisamos de uma camada linear para mapear a sequência pelo dmel Em Outra Sequência por tamanho de vocabulário isso ajuda a identificar a posição de cada palavra em nosso vocabulário em seguida aplicamos o soft Max e então determinamos nosso Label nesse caso Esperamos que o modelo Produza te amo muito End of sentence isso é chamado de Label
ou target uma vez que temos a saída do modelo e o Label correspondente calculamos a perda que é a Cross entropy loss depois disso retropropagação de palavras usamos esses tokens para marcar o início e o fim da sequência por exemplo se tivermos a sequência te amo muito adicionaremos o token de início de frase no início e o token de fim de frase no final ao processar a sequência o modelo vai emitir cada palavra em ordem começando com ti quando vir o start of sentence token e terminando com muito quando ver o End of sentence token
indicando que a tradução está completa o transforme pode resolver um problema geralmente dando múltiplos Passos com redes neurais recorrentes em uma única etapa com o Transformer damos uma sequência de entrada ao Encoder e uma sequência de entrada ao coder produzimos algumas saídas e calculamos a Cross entropy loss com a Label tudo acontece em um único passo esse é o poder do transformer torna fácil o treinamento de sequências muito longas e rápido como visto no chat GPT lama BT mistra e outros modelos mais ok usando o Transformer na inferência para traduzir uma frase em inglês I
love you very much para uma frase em português chamo muito primeiro nós preparamos a entrada para o Encoder adicionando um um token de início de frase depois a frase em inglês e geralmente um token de fim de frase o Encoder processa essa entrada e produz uma sequência de saída essa saída contém em berings especiais que capturam o significado e a posição e as interações das palavras entre si em seguida para o Decoder damos a Ele o token de início de frase e adicionamos tokens de embs suficientes para corresponder ao comprimento da sequência o Decode então
processo essa entrada junto com as chaves e Valores do Encoder para produzir uma sequência de saída usamos uma camada linear para projetar essa sequência de volta ao nosso vocabulário Ah um processo conhecido como logits aplicando soft Max aos logits nos ajuda a escolher a palavra de saída com o score máximo que nos diz qual palavra selecionar do vocabulário se todo o processo de treino tiver sido feito de forma correta essa etapa deve produzir o primeiro token de saída que é ti nesse caso ao treinar o Transformer Model fornecemos uma sequência de entrada e uma sequência
de saída por vez ah das quais o modelo aprende durante a inferência precisamos processar token por token não precisamos recalcular a saída do Encoder ah em cada time step porque a frase em inglês permanece a mesma em vez disso adicionamos a saída da frase anterior à entrada do Decoder esse processo continua anexando a saída da Etapa anterior a entrada do Decoder em cada time step até chegarmos ao token de fim de frase indicando o fim da inferência é assim que o processo de inferência funciona usamos quatro time steps para inferência no modelo de tradução a
estratégia que usamos é chamada de Grid strategy ou estratégia gananciosa onde em cada etapa ah escolhemos a palavra com valor máximo de soft Max essa estratégia geralmente funciona bem mas temos estratégias melhores como a bam search com bam search e selecionamos os principais valores bi em vez de sempre escolher o valor máximo de soft Max então analisamos os próximos tokens possíveis para cada uma dessas escolhas e mantemos apenas as sequências B mais prováveis descartando as outras bim search geralmente tem melhor desempenho do que a Grid strategy e ainda tem quem acredite que esse é o
caminho para egi bom Espero que você tenha gostado desse t no paper attention is all you need Ah se você gostou e quer ver mais vídeos como esse deixa aí nos comentários muito obrigado por assistir e nos vemos no próximo