hello Community openi has given us the new 03 model and I know everybody is applying right now for Early Access for the safety testing of 03 but you know what is really fascinating where did O3 fail let's have a look at these examples and they here the official a c AGI task with the specific number and I give you the reference in a minute so here we have it here we have examples you know an input and an output another input and an output example and another input and an output example and if my child
would understand now the common pattern and would say okay if this is not a test input what would be the test output but O3 failed in this other ideas let's explore this have a look at this we have the same structure so you see we have here blue indicators here at the borders and if you connect the those two blue indicators all the red boxes that are on these rays of blue they also become blue now we as humans we see this we understand this but given that this is now the test input and you
see the test input increases the complexity also just a little bit with a second line but this is where even 03 fails and this is amazing because it does not just just fail in the low compute mode but it fails in the high compute mode so at the end of this video we will talk is now O3 this AGI model but let's look at another example because this is this is now real simple and this is an examples where O3 fails look at this the blue one the red one the green one and the light
blue one you see all those examples and then the when you're given this and there's an additional layer of complexity because suddenly we have now here the second object but if we have made it to this examples and we understood if suddenly we have here a second example and only one colorcoded bar we understand how to apply it now to a second but if we have now the test task to apply to a third one O3 fails so so much about the performance of 03 and this provides us an insight into the performance and the
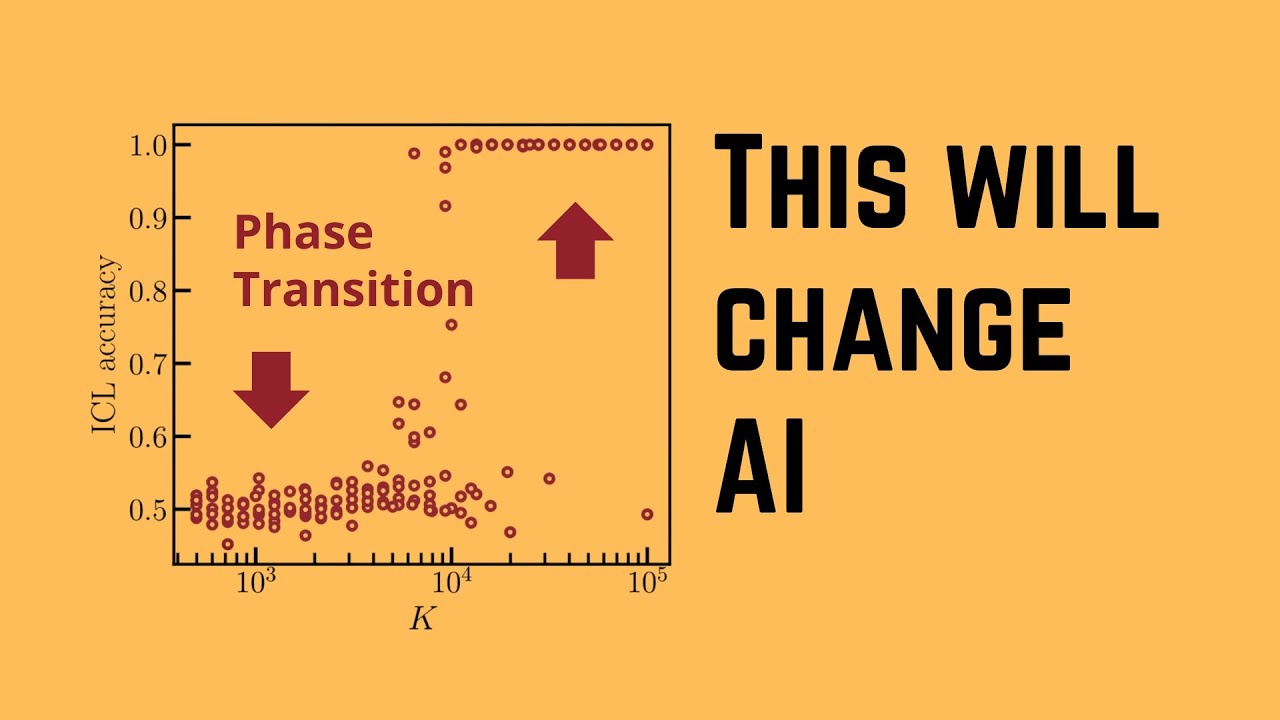
inner workings of 03 now let's look at the performance data and this is amazing so in the x-axis we have the costs per single task $100 $11,000 $2,000 and here you have here a particular performance score on a particular test data set I'm going to show you in a minute just have a look at these two new indicators that we get for the performance data here we have on our RC AGI semi-private evaluation data set here we have the O3 in the low compute version has a performance of 76% and here we have a performance
of 88% in the high compute version now if we compare this now to the 01 model that you might currently pay $200 us per month you see if we have the 01 low the 01 medium and the o1 high performance data they go from 25% to maximum 32% performance in this particular semiprivate evaluation data set so the jump from 01 at 30% to 76 or maybe even close to 90% is a significant performance jump let's have a closer look at this if you want to know here about a particular evaluation data set that 03 was
evaluated against here you have the technical report from December 9 2024 and to make it easy for you if you do want do not want to read the complete report the semi-private RC AGI evaluation data set has 100 specific task specifically designed to assess y models generalization capabilities on novel unseen problems it is withheld from the public because you don't want to have here a contamination here with your training data set and there other evaluation data set and the semiprivate evaluation data set is here a very particular intermediary between the public available data set and
the real private data set for calculating calculation we have a beautiful post here from fora and he given us here this EX exactly evaluation data set because open asked him before O3 was published to evaluate here the performance of 03 and he tells us here beautiful so as I shown you here 75% on the semiprivate evaluation data set in a low compute mode which cost about 20 bucks per task and we go up to 87.5 so this 88% in the high compute mode of 03 which would cost thousands of US dollars per task so just
some rumors on the internet I've seen just hours ago there was the idea that we started here by opening arm with a $20 per month then we have now for 01 to $200 per month and the internet is currently agreeing that the next step will be at $2,000 per month but this is absolutely not possible because think even a sing single task a single task would cost over a thousand of US dollars per one task so this price even have 2,000 per month is I don't think not a reliable idea now we have the data
because this Arc price here is really transparent in the data and if you go today just updated it 10 hours ago to the GitHub REO we have the data we have the results by openi 3 and those are also my source because I wanted to have reliable data from persons who really tested this and were asked by openi to perform the tests on 03 so you go there and you get an understanding and those data are the basis of my understanding I want to show you because I ask myself how does o03 work how is
it possible to gain those performance jumps when everybody told us hey pre-training you know no there's there's a no scaling anymore and whatever so how is this result possible and just to remind you from 30% to close to 90% but at extreme cost at extreme energy but let's understand it from a theoretical point of view now again if you go to Arc price or k the GitHub you get the prompt examples and you get a beautiful blog post here by franois and if you are really interested in read this technical report because there gives us
here the exact ideas and further details so he says at opens are direction we tested you the two levels those are the two levels that you know on the semi-private evaluation data set we have here the 100 task we have here the low and the high performance if you want discorded we achiev the 75 and 87.5 that you all would have seen now they also have a variable sample size the high efficiency go with sample size of six the low efficiency go with sample size of 1,24 and you see tokens 33 million close to 6
billion tokens unbelievable and the cost per task and they were only allowed open I ask them not to publish here the cost of task for the low version but listen if one cost per task is here 20 bucks here for the low score than for the high score version you know since we do have AGI as humans so we have here the 75 to 76% this is a 20 bucks okay so if we have here now the $1,000 Mark per task the cost per task and this is here the end is at $2,000 we can
estimate let's say $1,800 per single task for the high performance mode of o three and remember those are the cost not the price open ey will ask you to pay we continue with and he says hey we worked with openi to test the O3 on this particular Evolution data set and he says we believe it represents a significant real breakthrough in getting EI to adapt to novel task and please note I will continue now this video to focus on novel task not on task that are familiar task that in training data set task that every
every AI system has seen already a million times we will experience how good is it at Unseen tasks and for tells us for now we can only speculate about the exact specifics of how a O3 works but he says the core mechanism and he was testing this model here quite intensively appears to be a natural language program search and execution within the token space so this means at the test time at inference time O3 searches over the space of all possible chain of sorts describing the steps required to solve the task in a fashion that
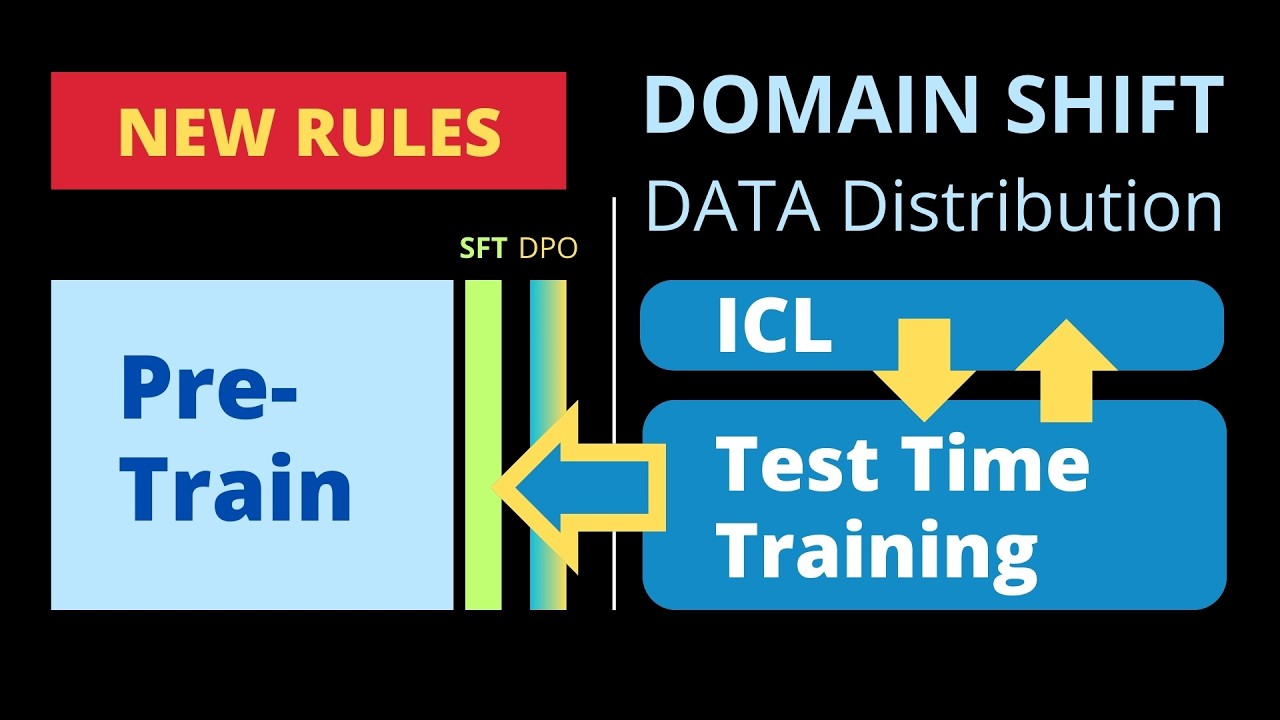
is not too dissimilar to Alpha CER style Monte carot research and he assumes that this search is presumably Guided by some kind of an internal evaluator AI model this is some absolute fascinating information he's providing us so during inference time we have now a complete new task and you know the terms the technical terms are test time Compu or everything to up to test time training where we really do kind of a fine-tuning in the inference run so I would say hey if you look at the time per task execution of 03 and you will
see it has more than 13 minutes when you say this is my prompt go then you have to wait 13 minutes for the result by opening ey it seems reasonable that there's quite a lot of going on and if you pay close to $2,000 per single task yes I think this will be some extreme Computing but you know what this means this means we have to do a pure inference computation on an otherwise perfectly pre-trained perfectly fine-tuned and perfectly preference aligned large language model and this made me thinking so wait a second we spent Millions
not me open ey whatever company millions of dollars to pre-train to fune to align this Lodge language mall and then even the vision language Mall and now you tell me that the performance is not there and now you tell me that I have to have a complete complex inferior experience computation maybe with a mol Research In addition to this and Fasco on it this is here quotation mark effectively oc3 represents a form of deep learning guided program search and the model o three does test time search over a space of programs and in this case
they are natural language program so the space of chain of Swords or more complex tree of Swords or Forest of Swords whatever will be the next step in the evolution of this that described the steps to solve the task at hand guided this search here by a deep learning prior and this is your the base language model so this is now interesting because suddenly we have the pre-training the fine tuning and the DPO alignment and then then we have the real world task by the user and for the real world task this system with thousands
of gpus needs 13 minutes to come up with a correct answer and what it does in those 13 minutes is not interesting partner test time search over space of programs this is constituted here by a different set of chain of sords or even some more complex objects and fris tells us the reason why solving a single Arc AGI task can up taking tens of millions of tokens and cost thousands of us dollarss is because this this search process has to explore an enormous number of all possible path through this huge program space that we learn
during pre-training supervised fine tuning and Alignment including all the backtracking that we know from the mon carot research algorithms and if you want to learn the next step The Forest of sord computation if we are in test time compute starting here from openi o1 with their long chain sorts reasoning structure I show you here in this particular video all the technical details about the forest of sorts now he becomes clearer and clearer that yeah it is not the perfect pre-training not the perfect fine-tuning not the perfect alignment if you really want to have a high
performance system we have to talk now about test time training test time calculation test time adaptation and I have to tell you I thought this is impressive but the very next moment I thought wait a second so for unseen task and this is this is the only focus we have here with this particular evaluation data set in the person one by the way all the train knowledge of the pre-training of the fine-tuning and of the alignment all this is gone because all of this is useless at inferior in time if we have a real world
prompt useless to apply the current pattern of the solution from all of this pre-training and fine-tuning because it will not find the solution is this what you're telling me because fris tells us clearly then we have to start a new process during this inference compute this up to 13 minutes that he showed us to search the mathematical space of all possible solution and maybe this is the space where the functional generative is here the chain of Swords or a forest of Sword so again but now with the specific task by the user we run now
in the inference here this new process and I think this is absolutely fascinating because it shows us that somehow open the ey decided that the pre-training and fine-tuning and Alignment is all beautiful and a lot of beautiful optimization methodologies but if you want to make a jump you have to look at the test time adaptation and honestly when I read this just hours ago I thought this breaks my understanding of current AI optimization techniques and I asked myself does this mean so all of this fine-tuning that we do all of this DPO alignment it only
works for similar task by the user only if the task by the user are similar whatever similar means now similar to the training data distribution that we have in the pre-training and the supervised fine tuning and in the alignment phase in the reinforcement learning phase because if a new task is now too different from anything seen and trained on the fails and I mean really fails and I mean there has a real low performance indicator and look just at the arc test results of all the other models they don't have this test time computer because
we have to start a complete new search process during test time kind of an inference compute with a monal Tre search for the particular task is presented now in the real world example by the user so amazing for me to learn if the new unseen task is too different is not similar enough to the training data distribution this EI system will fail so all of this talk about the EI will come up with some beautiful emergent intelligence and AI will understand the generalization patterns I think with the performance of AO3 open ey showed us that
this is not the case if if you disagree with me hey there are the comments for this video now if you want to learn more about test time training and test time adaptation in detail I have a technical videos in which I explain the inner workings and here the test time optimized EI reasoning computational code structures as developed by MIT Massachusetts Institute of Technology I show you here in this video where we scale the interference based exactly on test time or if you want to go even further deeper more technical I have here for the
reasoning process here at the test time training adaptation process some novel policy reward ideas with amount col reseearch in exactly this space I produced these videos two weeks ago because I had a feeling that those new technologies will become important for us as an AI community so coming back to 03 and Fran now Fran tells us regardless the current performan represents a remarkable achievement and a clear confirmation that this intuition guided test time search over the program space is a powerful Paradigm to build AI system that can adapt to arbitrary task and he tells us
you know the new R Arc AGI 2 Benchmark to be published 2025 is already designed to further challenge 03 and it will highlight and focus on the limitation of 03 and will be the Benchmark to beat and this is the reason why I started this video and I showed you where 03 failed where is O3 not able to deduct the hidden pattern where a Chain of Thought is not able even from billions and maybe trillions of training tokens to come up with a solution even if it has 10 ,000 gpus and I don't know how
many months of pre-training it will fail to discover simple patterns and yeah now to all my YouTuber who love a good AGI story I'm so sorry but I have to tell you and Fran agrees here O3 is not Ai and I know you will read in the news that it is but if you understand it a little bit more from a technical point of view if you look and read here the technical reports and the evaluation reports by Arc you will see that it fails on simple tasks as I've shown you and it remains dependent
on the human Creator data for generating and evaluating our chain of ss it fails here quite significant if the training data are not the highest possible quality and this is I would say of course and O3 lack some autonomous grounding in reality and relies here only on the token space evaluation which it is a limiting factor here especially in the robustness in out of distribution task so again we are back to the old Mantra your data the quality of your data are the most important factor for a good performance llm how many processes we build
in the pre-training in the fine-tuning in the DPO alignment in the reinforcement learning training methodologies I think if we look at 03 we understand that all of those have come to kind of a saturation but now the New Frontier the Undiscovered performance that we are going to achieve in the next year will maybe be with all of this test time compute test time training test time adaptation during the inference where we will have to wait 13 minutes 15 minutes maybe if you really go to high performance up to an hour for an answer ndi builds
here a world of possible solutions and then spends extreme resources to going again with the real task by the user through all of this possible solution until it really comes up with the correct solution I think this is amazing what will await Us in the year 2025 5 so this is just 10 hours after openi released 03 this is what I could find out this is my current knowledge that I have 10 hours after it was published and I hope I've given you some additional information maybe some new ideas and I would be interested in
your ideas in your what you know what you have read so why not share your thoughts in the comment of this video it would be great great to see you in my next video