Hi everyone we're gonna started now so this week's lecture is really picking up where last weeks left off right remember we spent last week talking about tall building friends and I told you how for last week we're just gonna focus on a one time step setting well as we know lots of medicine has to do with multiple sequential decisions across time and that'll be the focus of this whole week's worth of discussions and as I Thought about ruling what should I teach in this lecture I realized that the person who knew the most about the
topic was in fact a postdoctoral researcher in my lab most when that's not bacon you know I'll take I'll take that I'll take that it's very fair it's very and this is Frederick Johansen he'll be a professor in Chalmers and Sweden starting in September anyway thank you so much David that's very generous yeah so as David mentioned last time we Looked at a lot at causal effects and that's where we will start this discussion too so I'll just start with this reminder here we we essentially introduced four quantities last time or the last two lectures
so first I know we had two potential outcomes which represented the outcomes that we would see of some treatment choice under the various choices or the two different choices one is zero and we had two covariates over start we had a Covariates sudoko variate axe and a treatment t and we were interested in essentially what is the effect of this treatment T on the outcome Y given the covariates X and the effect that we focused on that time was the conditional average treatment effect which is exactly the difference between these potential outcomes conditioned on the
features so the whole last week was about trying to identify this quantity using various methods and the question That didn't come up so much or one question that didn't come up too much is how do we use this quantity we might be interested in it just in terms of of its absolute magnitude how but we might also be interested in designing a policy for how to treat our patients based on this quantity so today we will focus on policies and what I mean by that specifically is something that takes into account what we know about
a patient and produces a choice or Inaction as an output typically we'll think of policies as depending on medical history perhaps which treatments they have received previously what state is the patient currently n but we can also base it's purely on this number that we produce last time the conditional average treatment effect and one very or natural policy is to say PI of X is equal to the indicator function representing if the state is positive so if the effect is positive we treat the Patient if the effect is negative we don't and of course positive
will be relative to the the usefulness of the outcome being high but yeah this is a very natural policy to consider however we can also think about much more complicated policies that that are not just based on this this number the quality of the outcome we can think about policies are taking into account legislation or cost of medication or side effects we're not going to do that Today but that's something that you can keep in mind as we discuss these things so David mentioned we should now move from the one-step setting where we have a
single treatment acting at a single time and we only have to take into account the state of a patient at once basically and we will move from that to the sequential setting and my first example of such a setting is sepsis management so sepsis is a complication of an infection which can have very Disastrous consequences it can lead to organ failure and ultimately death and it's actually one of the leading causes of deaths in the ICU so it's of course important that we can manage and treat this condition when you start treating stuff just the
primary target the first thing is you should think about fixing its the infection itself if we don't treat the infection things are going to keep being bad but even if you figure out the right antibiotic to treat the Infection it's the source of the septic shock of the septic inflammation there are a lot of different conditions that we need to manage because this the infection itself can lead to fever breathing difficulty slow heart s or low blood pressure high heart rate all these kinds of things that are symptoms but not the causing themselves but we
still have to manage them somehow so that the patient survives and is comfortable so when I Say sepsis management I I'm talking about managing such quantities over time over a patient stay in the in the hospital so last time again just to really hammer this in we talked about potential outcomes and the choice of a single treatment so we can think about this in the septic setting as a patient coming in or a patient already being in the hospital assumably and it's presenting with breathing difficulties so that means that their blood oxygen Will be low
because they can't breathe on their own and we might want to put them on mechanical ventilation so that we can ensure that they get sufficient oxygen we can view this as a single choice should we put the the the patient on mechanical ventilation or not but what we need to take into account here is what will happen after we make that choice well what would be the side effects of this choice going further because we want to make sure that the Patient is comfortable and in good health throughout their stay so today we will move
towards sequential decision making and in particular what I alluded to just now is that decisions made in sequence may have the property that choice is early on rule out certain choices later and we'll see an example of that very very soon and in particular we'll be interested in coming up with a policy for making decisions repeatedly that optimizes a given outcome something That we care about it could be optimizes the or reduce minimize the risk of death it could be a reward that says that the vitals of the patients are in the right range you
might want off to my stat but essentially think about it now as as having this this choice of administering a medication or an intervention at any time T and having the best policy for doing some okay I'm gonna skip that one okay So I mentioned already one potential choice that we might want to make in the management of a septic patient which is to put them on mechanical ventilation because they can't breathe on their own a side effect of doing so is that they might be my suffer discomfort from having from being intubated and well
the procedure is not painless is not without discomfort so something that you might have to do putting them on mechanical ventilation is to sedate the patient so This is a sort of an action that is informed by the previous action because if we didn't put the patient on mechanical ventilation maybe we wouldn't consider them for sedation when we sedate a patient we run the risk of lowering their blood pressure so we might need to manage that too so if their blood pressure gets too low maybe we need to administer vasopressors which artificially raise the blood
pressure or fluids or anything else that that takes Care of this issue so just just think of this as an example of choices cascading in terms of their consequences as we roll forward in time ultimately we will face the end of the the patient's stay and hopefully we managed the patient in a successful way so that their the response or their their outcome is a good one what I what I'm illustrating here is that for any one patient in our hospitals or in the healthcare system we will only observe one trajectory through These options so
I will show this type of illustration many many times but I hope you can the you can realize the the the scope of the decision space here essentially at any point we can choose a different action and usually the number of decisions that we make in a in a ICU setting for example is much larger than we could ever test in in a randomized trial think of all of these different trajectories as being different alarms in a randomized control trial That you want compare the effects or the outcomes of its infeasible to run such a
trial typically so one of the big reasons that we were talking about reinforcement learning today and talking about learning policies rather than causal effects in the setup that we did last week is because the space of possible action trajectories is so large so said having said that we now turn to trying to find essentially the policy that Picks this orange path here that leads to a good outcome and to to reason about such a thing we need to also reason about what is a good outcome what is a good reward for for our agent as
it proceeds through time and it makes choices some policies that we that we produce as machine or this might not be appropriate for a healthcare setting and like we had to have to somehow restrict ourself to something that's realistic I won't focus very much in this today it's Something that will come up in the discussion tomorrow hopefully and also the the notion of evaluating something for for use in the healthcare system will also be talked about tomorrow Thursday sorry Thursday next time okay so I'll start by just briefly mentioning some success stories and these are
not from the healthcare setting as you can guess from the pictures how many have seen some of these pictures okay great great almost everyone yeah so these are From from various video games almost all of them well games anyhow and these are these are good examples of when reinforcement learning works essentially that's why I use this in this in this slide here because essentially it's very hard to argue that the computer or the the program that eventually beat Lisa dole I think it's in this picture but also later go champions essentially in the alphago picture
in the top left it's hard to argue that they're not doing a Good job because they clearly beat humans here but one of the one of the things I want you to keep in mind is throughout this talk is what is different between these kinds of scenarios and we'll come back to that later and what is what is different to to the healthcare setting essentially so I just simply added another exemplar that's why I recognized so there was a reasonably one that's a little bit closer to my Heart which is Alvis star the play Starcraft
I like Starcraft so you know it should be on the slide anyway let's move on broadly speaking these can be summarized in the following picture what goes all into those systems there's a lot more nuance when it comes to something like go but for the purpose of this class we will summarize them with a slide so essentially one of the three quantities that matters for a reinforcement Learning is this state of the environment the state of the game the state of the patient the state of the thing that we want to optimize essentially so in
this case I've chosen tic-tac-toe here we have a state which represents the current positions of the of the circles and crosses and given that that state of the game my job as a player is to choose one of the possible or yeah the possible actions one of the three squares to put my cross in so I'm The blue player here and I can consider these five is it choices for where to put my next cross and each of those will lead me to a new state of the game if I put my my cross over
here that means that I mean now in this box and I have a new set of actions available to me for the next round depending on what the red player does so we have the state we have the actions and we have the next status and so we have a trajectory or a transition of states and the last Quantity that we need is the notion of a reward that's very important for reinforcement learning because that's what's drive the learning itself we strive to optimize the reward or the outcome of something so if we look at
the action to the farthest right here essentially I left myself open to an attack by the red player here because I didn't put my cross there which means that probably if the red player is decent he will put his circle here and I Will incur a loss so my reward will be negative if we take positivity be good and this is something that I can learn from going forward essentially what I want to avoid is ending up in the state that's shown in the bottom right here this is the the basic idea of reinforcement learning
for for videogames and for anything else so if we take this board analogy or this example and and move to the healthcare setting we can think of the state of a Patient ask the game board or the state of the game we will always call this s T in this talk the treatments that we prescribe or interventions will be a T and these are like the actions in the game obviously the outcomes of a patient could be mortality could be managing vitals will be just like the rewards in the game having lost or won and
then I put the end here what could possibly go wrong well as I alluded to before healthcare is not a game in the same Sense that a video game is a game but they share a lot of mathematical structure so that's why I make the analogy here these quantities here si and R will form something called a decision process and that's what we'll talk about next this is the outline for today and Thursday I won't get to this today but these are the topics were considering so a decision process is essentially the the world that
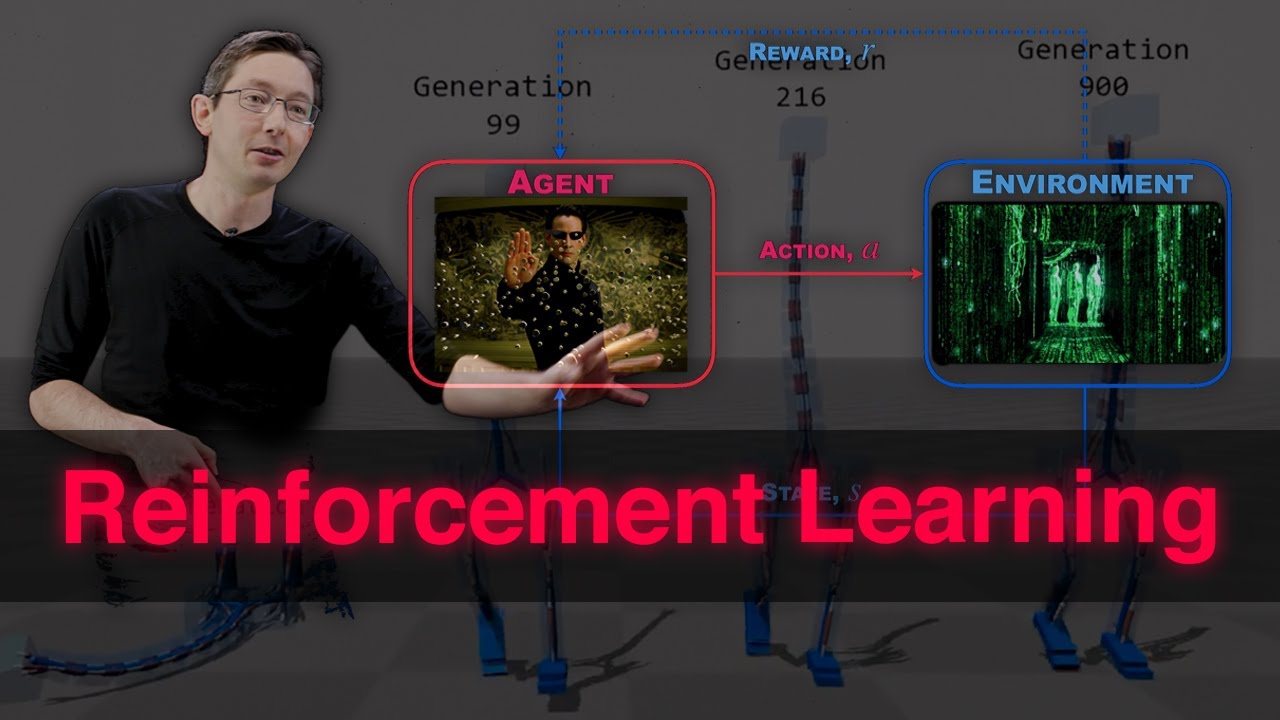
describes the data that we access or the the world That we were managing our agent in and it's often very often if you've ever seen reinforcement learning taught is you have seen this picture in some form usually sometimes there's some mouse and some cheese and there's other things going on but you know what I'm talking about and but there are the same basic components so there's the concept of an agent let's think doctor for now that takes actions repeatedly over time so This T here indicates an index of time and we see that essentially increasing
as we spin around this wheel here we move forward in time so an agent takes an action and at any time point receives an award reward for that action and that would as I said before the environment is responsible for giving that reward so for example if I'm the doctor I'm the agent I make an action or an intervention to my patient the patient Will be the environment and essential response to does not respond to my intervention the state here is the state of the patient as I mentioned before for example but it might also
be a state of more broadly than the patient like the the the the settings of the Machine that they're attached to or the the availability of certain drugs in the hospital or something like that so we can think a little bit more broadly in a Patient - I said partially observed here in that I might not actually know everything about the patient that's relevant to me and we will come back a little bit later to that so there are two different formulations that are very close to each other which is when you know everything about
s and which when you don't well for the longest part of this talk focus on where I know everything that is irrelevant about the environment okay to make this all a bit More concrete I'll return to the picture that I showed you before but now put it in context of the paper that you read right was that the compulsory one the mechanical ventilation okay great so in this case they had an interesting reward structure essentially the thing that they were trying to optimize was a reward related to the vitals of the patient but also to
whether they were kept on mechanical ventilation or not and the idea of this paper is that you Don't want to keep a patient unnecessarily on mechanical ventilation because it has the sight aspects that we talked about before so at any time a point in time since we can think about taking a patient on or off and also dealing with the sedatives that are prescribed to them so in this example the state that they consider in this in this application included the demographic information of the patient it doesn't really change over time their Physiological measurements ventilator
settings control consciousness level the dosages of the sedatives they use which could be an action I suppose and a number of other things and these are the values that we have to keep track on of moving forward in time the actions concretely included whether to intubate or extubate the patient as well as the administer and dosing the sedatives so this is again an example of a so-called decision Process and essentially the the process is the distribution of these quantities that have been talking about over time so we have the states the actions and the rewards
they all traverse or they all evolve over time and the the loss of how that happens is the decision process I mentioned before that we will be talking about policies today and typically there's a distinction between what is called a behavior policy and a target policy or there are different Words for this essentially the thing that we observe is usually called a behavior policy by that I mean if we go to a hospital and watch what's what's happening there at the moment that will be the behavior policy and I will denote that mu so that
is what we have to learn from essentially so decision processes so far are incredibly general I haven't said anything about what this distribution is like but the the absolutely dominant restriction that People make when they study the system processes is to look at and mark of decision processes and these have a specific conditional independence structure that I will illustrate in the next slide but I'll just define it mathematically here it says essentially that all of the quantities that we care about the states I guess that should say state reports in the actions only depend on
the most most recent state in action so if we want to or if we observe an Action taken by a doctor in the hospital for example to make a mark of assumption would would say that this doctor did not look at anything that happened earlier in time or any other information than what is in the state variable that we observe at that time that is the assumption that we make yeah like the consumption you can make for a healthcare because yet you don't measure you don't have access to the real estate but only about what's
measured about Your state in healthcare it's a very good question so the nice thing in terms of inferring causal quantities is that we only need the things that we're used to make the decision in the first place so the doctor can only act on such information - unless we don't record everything that the doctor knows which is also the case so it's it's something that we have to worry about for sure yeah another another way to to lose information as I mentioned that is Relevant for this is if we we look to to like to
tune what's the opposite of far to knee our back in time essentially so we don't look at the entire history of the patient and when I say St here it doesn't have to be they instill the instantaneous like a snapshot of a patient we can also include history there again we'll come back to that a little later yeah okay so the Markham assumption essentially looks like this or this is How I will illustrate anyway we have a sequence of states here that evolve over time I'm not allowing myself to put some dots here because I
don't want to draw forever and but essentially you can think of this pattern repeating where the previous state goes into the next state the action goes into the next stage and the action and state goes into the reward this is the world that we will live in for this lecture something that's not allowed under the mark of Assumption is an edge like this which says that the an action in the early time in places' an action at a later time and specifically it can't do so without casting through estates for example it very well can
have an influence on 80 by this trajectory here but not directly that's the amount Markov assumption in this case so you can see that there's if I were to draw the graph of all the different measurements We that we see and during a stay essentially you could there are a lot of errors that I could have had in this picture that I don't have so it may seem that the Markham assumption is a very very strong one but one way to ensure that the Markov assumption is more likely is to include more things in your
state including some reason of the history etc but I mentioned before an even stronger restriction of decision processes is to assume that the states Over time are themselves independent so this goes by different names sometimes under the name contextual bandits but the bandits part of that itself is not so relevant here so let's not go into that name for too much but essentially what we can say is here then the the state at that later time point is not influenced directly by the state at the previous time point nor the action at a previous time
point so if you've if you remember what we did last week this Looks like basically T repetitions of the very simple graph that we had for estimating potential outcomes and that is indeed mathematically equivalent if we assume that this s here represents the state of a patient and all patients are drawn from some some process essentially so that s 0 1 etc from up to s T are all iid draws of the same distribution then we have essentially the model for T different patients without a single time step or single Single action instead of them
being dependent in some way so we can see that by by going backwards through my slides this is essentially what we had last week and we just have to add more arrows to get to whatever we have this week which indicates that last week was a special case of this just as David said before it also hints at the reinforcement learning probably more complicated than the potential outcomes problem and we'll see more examples of That later but like with causal effect estimation that we did last week we're interested in the influences of just a few
variables essentially so last time we study the effect of a single treatment choice and in this case we will study the influence of these various actions that we take along the way that will be the goal and it could be either through an immediate effect on the the immediate reward or it can be through the impact that an action has on The state trajectory itself so okay I told you the about the world now that we live in we have these essays and ours and I haven't told you so much about the the goal that
we're trying to solve or the the problem that we're trying to solve most RL or reinforcement learning is aimed at optimizing the value of a policy or finding a policy that has a good return a good sum of rewards there are many names for this but essentially a policy that does well the notion of Well that we will be using in this lecture is that of a return so the return at a time step T following the policy PI that I had before is the sum of the future rewards that we see if we were
to act according to that policy so essentially I stop now I ask ok how if I keep on doing the same as I've done through my whole life maybe that was a good policy I don't know and keep going until the end of time what is that how well will I do what is The sum of those rewards that I get essentially that's the return the value is the expectation of such things so if if I'm not the only person but there's the whole population of us the expectation over that population is the value of
the policy so if we take patients as a better analogy than my life may be what the expectation is over patients if we act on every patient in our population the same way according to the same policy that is what is the Expected return over those patients so as an example I drew a few trajectories again because I like drawing and we can think about three different patients here they start in different states and they will have different action trajectories as a result so we're treating them with the same policy let's call it pi but
because they're in different states they will have different actions at different at the same times so here we take a action we Go down here we take a selection we go down that's what that means here the specifics of this is not so important that's why what I want you to pay attention to is that after each at each action we get our reward and at the end we can sum those up and that's our return so each patient has one set of one value for their own trajectory and the value of the policy is
then the average value of such trajectories okay so that is What we're trying to optimize we have now a notion of good and we want to find a PI such that V PI up there is good that's the goal all right so I think it's time for for a bit of an example here I want you to play along in a second you're gonna you're going to solve this problem it's not a hard one so I think you'll manage I think I think you'll be fine but this is now on yet another example of a
world to be in this is the Robot in a room and I've stolen this slide from David who stole it from Peter boudic I am yeah and yeah so credits to him all right the rules of this world says the following if you tell the robot who is traversing this the set of tiles here if you tell the robot to go up there's a chance he doesn't go up but go somewhere else so we have stochastic transitions essentially if I say up it goes up with point a probability and somewhere else With uniform probability say
so point eight up and then point to this the only possible direction to go in if you start here so point two in that way okay there's a chance you've moved in the wrong direction what I'm trying to illustrate you know there's no chance that they're going in the opposite direction say so if I say right here it can't go that way right their rewards in this game is +1 in the Green box up there and -1 in the box here and these are also terminal states so I haven't told you what that is but
is essentially a state in which the game ends so once you get to either plus 1 or minus 1 the game is over for each step that the robot takes it incurs 0.04 negative reward so that says essentially that if you keep going for a long time your reward would be bad your value of the value of the policy will be bad so you want to be efficient so basically You can you can figure out you want to get to the green thing that's one part of it but you also want to do it quickly
so what I want you to do now is to essentially figure out what is the best policy mm in terms of in which way I should the arrows point in each of these different boxes fill in the question mark with an arrow pointing in some direction we know that transitions will be stochastic so you might need to take that into account But essentially figure out how do I have a policy that gives me the biggest expected reward and I'll ask you in a few minutes if one of you is brave enough to put it on
the board or something ok there's no discount it's accursed so I had a question which what is the action space and essentially the action space is always up down left or right depending on if there's a wall or not so you can't you can't go right Here for example you can't go left you exactly yeah good point so each each box at the end when you're done should contain an arrow pointing in some direction all right I think we'll we'll see if anybody has solved this problem now who thinks they have solved it Gretchen would
you would you like to share your solution yes yeah sake it's going to go up first okay I'm gonna try and look at this oh sorry about that okay you're saying up here Yeah okay yes okay okay and then okay so what about these ones this is also part of the policy by the way oh so this usually means something else we'll get to that later but there is a reward for for just taking any step so it's yeah if you move into a space that is not terminal you incurred that negative reward exactly right
long- if we had this there's some chance I'd never get out about there's very little Chance of negative gap but it's a very bad policy because you keep moving back and forth alright we had an arm somewhere what should I do here huh you could take a vote okay here things right really everything's left remember so this is the well good yeah so this is the part that we already determined if we had deterministic transitions this would be great okay because we don't have to think about the other ones this is what Peter put on
the Slide so I'm gonna have to disagree with the with the vote there actually and it it depends actually heavily on the minus 0.04 so if you increase that by a little bit you might want to go that way instead or if you decrease it remember decrease exactly and if you increase it you might get something else it might actually be good to terminate so those details matters a little bit but I think you got the idea and especially I like that you Commented that you want to stay away from the red one because if
you look at these different paths you go up there and there they have the same number of states but there's less chance you end up in the red box if you take the the upper route great so we have an example of a policy and we have an example of a decision process and things are working out so far but how do we do this I mean as far as the class goes this was a black box experiment I don't know Anything about how you figured that out so reinforcement learning is about that music enforcement
learning is to try and come up with a policy in a sort of rigorous way hopefully ideally so that would be the next topic here up until this point are any questions study you've been dying to ask but haven't interesting I guess it depends a little bit on how it manifests in that if it also influenced your previous like your most recent action maybe you'll you have An observation of that already in some sense it will it's a very broad question how do what effect will they have did you have something specific in mind interesting
so I guess my response there is that the the the the action didn't really depend on the choice of action before because the policy remained the same you can have it you could have a bias towards an action without that being dependent on what you gave as action before if you Know what I mean say that it's a my probability of giving action one is one then it doesn't matter that I gave it in the past but policy is still the same so not necessarily it could have other consequences that we we might we have
reason to come back to that question later yeah yep practically I would think that a doctor would want to be consistent and so you wouldn't for example want to put somebody on a ventilator and completely Yeah I think it's a great example and what what you would hope is that the the state variable in that case includes some notion of treatment history but that's what you what's your job is then yeah so that's why state can be somewhat misleading as a term at least for me I don't know I'm not American so or english-speaking but
but but but yeah I think of it as two instantaneous sometimes so we'll move into reinforcement learning now and what I Had you do on the last slide well I don't know which method you use but most likely the middle one there are three very common paradigms for reinforcement learning and they are essentially divided by what they focus on modeling unsurprisingly model based RL focused on well it has some sort of model in it at least and the model that they did what do you mean by model in this case is a model of the
transitions so what state will I end up in given the action in the State I'm in at the moment so model based RL tries to essentially create a model for the environment or of the environment and there are many well there are several examples of model based RL one of them is G computation which comes out of the statistic literature if you like an MD piece or essentially that's the MD piece that's remarkable decision process which is essentially trying to estimate the whole distribution that we talked about before The there are various ups and downsides
of this we won't have time to go into all of these paradigms today we will actually focus only on value-based RL today but yeah you can ask me offline if you're interested in model-based RL the rightmost one here is policy based RL where you essentially focus only on modeling the policy that the was acted or you act that was used in the data that you observed and the policy that your that You want to essentially arrive at so you're optimizing a policy and you're estimating a policy that was used in the past and the metal
one focuses on either of those and focus on only estimating the return that was the G or the the reward function as a function of your actions and States and it's kind of interesting to me that you can kind of pick any of the variables a s and R and model those and you can arrive at something reasonable in reinforcement Learning this one is particularly interesting because it doesn't even look at yeah it doesn't try to understand how do you arrive at a certain return based on the actions in the States is just optimize the
policy directly and it has some obvious well not obvious but it has some downsides not doing that so okay anyway we're going to focus on value base RL and the very very dominant instantiation of value base RL is q-learning I'm sure you've heard of it It was a drill it is what drove the success stories that I showed before the the goal and the Starcraft and everything G estimation is another example of this which again is coming from the statistic literature but we'll focus on q-learning today so Q learning is an example of dynamic programming
in some sense that's how it's usually explained and I just wanted to check how many I've heard the phrase dynamic programming before okay great so I think That I won't go into details of dynamic program in general but the general idea is is one of recursion that you in in this case you know something about what is what is a good terminal state and then you want to figure out how to get there and what how to get to the state before that and the state before that and so on that is the recursion that
we will be talking about so and inst with the end state that is the best here it's fairly obvious that it's the plus one Here and the best way or the only way to get there is by by stopping here first because you can't move from here since it's a terminal State so your only your only bet is that one and then we can ask what is the best way to get to three one how do we get to the state before the best date well we can say that one way is to get from
go from here and one way from here and as we got from the audience before this is a slightly worse way to get there than from there because Here we have an possibility of ending up in minus one so then we recurse further and essentially we end up with something like this that says like the try to illustrate here is that the green boxes hope you can I'm sorry for any colorblind members of the audience because this was a poor choice of mine anyway this bottom side here is mostly red and this is mostly green
and you can follow the green color here essentially to get to the best end state and what I Used here too to color this in is this idea of knowing how good is status depending on how good the state after that status so I knew that +1 is a good end State over there and that led me to to recurse backwards essentially so the question then is how do we get how do we know that that state over there is a good one when we have it visualized in front of us it's very easy to
see and it's very easy because we know that +1 is a Terminal state here it ends there so that's the only those are the only sort of states we need to consider in this case but more in general how do we learn what is the value of a state that will be the purpose of Q learning ok after if we have an idea of what is a good state we can always sort of do that recursion that I explained very briefly you find a state that has two high value and you figure out how to
get there ok so we're going to have to define now what is what I mean by value I've used that word a few different times I say recall here but I don't know if I actually had it on a slide before so let's just say this is the definition of value that we will be working with so the value is I think I had it looks like before actually this is the expected return remember this G here was the sum of rewards going into the future starting at time T and the value then of this
state is the expectation of such returns so before I Said that the value of a policy was the expectation of returns period and the value the value of a States and the policy is the value of such returns starting in a certain state we can stratify this further if you like and say that the value of a state action pair is the expected return starting in a certain state and taking an action a and after that following the policy PI this would be the the sort of this circle Q value of the state action pair
S a okay and this is where Q learning gets its name so Q learning attempts to estimate the Q function the expected return starting in a state s and taking action a from data and it does so the Q learning is also associated with a deterministic policy so the policy and the Q function go together in this specific way if we have a Q function Q that tries to estimate the value of a policy pie the pie itself is the arc max according to that Q it sounds a little Recursive but hopefully it will be
okay it may be it's more obviously if we look here so Q I said before what's the value of starting and s taking action a and then following policy PI okay this is defined by the the the the decision process itself the best PI the best policy is the one that has the highest Q and this is what we call a Q star okay this is it well that it's not what we call Q so this will cook little Q star Q star the best estimate of this is Obviously the thing itself so if you
can find a good function that assigns a value to a state action pair the best such function you can get is the one that has that is equal to a little Q star I hope that wasn't too confusing I'll show on the next slide right that might be reasonable so cue learning is based on a general idea from dynamic programming which is the so-called bellman equation there we go so bellman optimality says that if This is an association of bellman optimality which says that the the best the Q star the best state action value function
has the property that it is equal to the immediate reward of taking action and state s plus this which is the maximum Q value for the next state so we're going to stare at this for a bit because it's something to digest that I think little bit here to digest remember Q star assigns the value to any state action pair so we have Q star here We have Q star here this thing here is supposed to represent the value going forward in time after I've made this choice action a in state s so if I
have a good idea of how good it is to take action in state s it should both incorporate the immediate rewards that I guess that's our T and how good that choice was going forward so think about mechanical ventilation as I said before if we put a patient on mechanical ventilation we have to do a bunch of Other things after that if none of those other things lead to a good outcome this part will be low even if the immediate return is good so for the optimal Q star this this quantity wholes we know that
we can prove that okay so the question is how do we find this thing how we find Q star because Q star is not only the thing that gives you the optimal policy it also satisfied this equality this is not true for every Q function but it's True for the optimal one questions this is uh yeah if you haven't seen this before it might be a little tough to digest it's the notation clear essentially here you have the the state that you arriving at the next time a prime is the parameter of this here or
the argument to this you're taking the best possible Q star value in the state that you arrived at after yeah good example you have in the board yes Actually I might do a full example of Q learning in a second yes I will I'll get to that a gentleman okay yeah I was debating where the do they might take some time but it could be useful so where are we yes okay so what I showed you before the bellman inequality we know that this holds for the optimal thing and if there's a equality that is
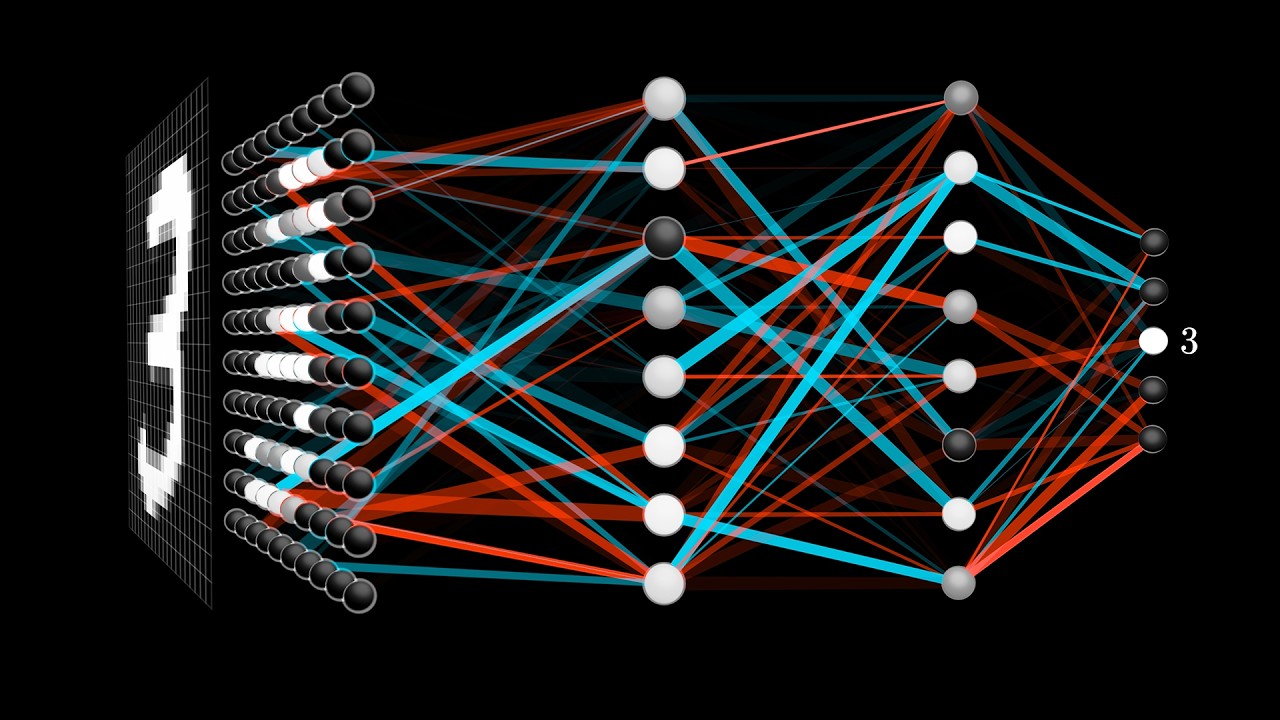
true at an optimum one general idea in optimization is this a so-called fixed point Iteration that you can do to arrive there and that's essentially what we will do to get to a good Q yeah so a nice thing about Q learning is that if you're states and action spaces are small and discreet you can represent the Q function as a table so all you have to keep track of is how good is the the the a certain action in a certain state or all actions in whole states rather so that's what we did here
this is a table I've essentially I've described to you the policy here but what we'll do next is to to describe the value of each action so you can think of it a value of taking the right one bottom top and left essentially those will be the values that we need to consider and so what Q learning can do with the screech States is to essentially start from somewhere start from some idea of what Q is it could be random could be zero and then repeat the following fixed point iteration where You update your former
idea of what Q should be when its current value plus some essentially a mixture of the immediate reward for taking action 80 in that state and the future reward as judged by your current estimate of the Q function some will do that now in practice yeah this the probabilities are like the game so they're not used here actually a value based RL I didn't say that explicitly but they don't rely on knowing the Transition probabilities what you might ask is where do we get the s and the ACE and they're ours from and we'll get
to that how do we estimate these we'll get to that later good question um okay I'm gonna throw a very messy slide at you here you go a lot of numbers so what I done now here is some more exhaustive version of what I put on the board for each little triangle here it represents the Q value for the state action pair so this Triangle is again for the action right if you're in this state okay so what I've put on the first slide here is the immediate reward of each action so we know that
any step will cost us cost us minus 0.04 so that's why there's a lot of those here these white boxes here are not possible actions okay up here you have a point nine six because it's one which is the immediate reward of going right here minus point oh four these two are minus one point oh four for the same Reason but because we arrived in minus one okay so that's the first step and the second step done we initialized Q's to be zero and then we picked these two parameters of the problem alpha and gamma
to be one and then we did the first iteration of Q learning where we set the Q to be at the old version of Q which was zero plus alpha times this this thing here so Q is zero that means that this is also zero so the only thing we need to look at is this thing here This also is 0 because the Q's for all states were 0 so the only thing we're not with this are and that's what populated this table here okay next time step where I'm doing cooling now in a way
where I update all the states at once all the station action pairs at once how can I do that well it depends on the question I got there essentially what data do I observe or how do I get to know the rewards of the SNA pairs and we'll come back to that so In the next step I have to update everything again so it's a previous Q value which was minus 0.04 for a lot of things then plus the immediate reward which was this RT and I have to keep going so that the the dominant
thing for the table this time was that the best q value for for almost all of these boxes was minus 0.04 so essentially I will add the immediate reward plus that almost everywhere what is interesting though is that here the best q value was 0.96 and It will remain remains so that means that the best Q value for the adjacent states would look at this max here and get 0.96 out okay and then add the immediate rewards so this thing here getting to here gives me point 96 minus 0.04 for the immediate reward and now
we can sort of figure out what will happen next this this these values would sort of spread out as you go further away from the further away from the +1 I don't think we should go through all of This but you get a sense for extent essentially how information is moved from the +1 and away and I'm sure that's sort of how you solved it yourself in your head but this this makes it clear why you can do that even if you don't know where the terminal states are or where the best where the value
of these state action pairs are yep this calculation assumed you want to move in a certain direction yes sorry thanks for reminding me that's Your Lebanon slide yes thank you yeah I'm gonna I'm gonna skip the rest of this I hope you forgive me we can talk more about it later but one of the one of the things that is thanks for reminding me Pete there that one of the things I exported here was that I assumed deterministic transitions another thing that I relied very heavily on here is that I can represent this q function
as a table like I drew all these boxes and I fill the numbers in That's easy enough but what if I have thousands of states and thousands of actions that's a large table and not only is that a large table for me to keep in memory it's also very bad for me statistically if I want to observe anything about a state action pair I have to do that action in that state and if you think about treating patients in a hospital you're not going to try everything in every stage usually you're also not going to
have infinite number Of numbers of patients so how do you how do you figure out what is the immediate reward of taking a certain state action in a certain state and this is where function approximation comes in essentially if you can't represent your data as a table either for statistical reasons or for well memory reasons let's say you might want to approximate the Q function with with a parametric function or with a number matching function and this is exactly what we can do so we can Draw now an analogy to what we did last week
I'm gonna come back to this but essentially instead of of doing this fixed point iteration that we did before we will try and look for a function Q theta that is equal to R plus gamma max max Q and this is the the remember before we had the bellmen inequality we said that Q star si is equal to R si let's say plus gamma max max a prime you Jesus please start s prime a prime where s Prime is the state we get to after taking X in a in state s so the only thing
I've done here is to take this equality and make it instead a loss function on the violation of this equality so by minimizing this quantity I will find something that has approximately the bellmen equality that we talked about before this is the idea of fitted q-learning where you substitute the the tabular representation where they with a Function approximation essentially so just to make this a bit more concrete we can think about the case where we have only a single step there's only a single action to make which means that there is no future part of
this equation here this part goes away because there's only one one stage in our trajectory so we have only the immediate reward and we have only the Q function now this is exactly a regression like equation in the way that you've seen it when Estimating potential outcomes RT here represents the sorry the the the outcome of doing action a in state s and Q here will be our estimate of this RT so if if we only again I've said this before if we have a single time point in our inner process that the problem reduces
to estimating potential outcomes just the way as the way we saw it last time we have curves that correspond to the different the outcomes under different actions and we can do regression Adjustment trying to find an F such that this quantity is small so that we can model each different potential outcomes and that's exactly what happens with the fit acute iteration if you have a single time step two so to make it even more concrete we can say that this there's some some target value G hat which represents the immediate reward in the future rewards
that is the target of our regression and we're fitting some function to that value okay So the question we got before was how do i how do I make use of or how do I know the transition matrix well how do I get like any information about this thing okay I say here on the sly that okay we have some target that's our plus future Q values we have some prediction we have an expectation over transitions here but how do I evaluate this thing the transitions I have to get from somewhere right and another way
to say that is what are the inputs in the outputs of Our regression because in in when we estimate potential outcomes we have a very clear idea of this we know that Y is the outcome itself is a target and the the input is the you know the covariance X okay but here we have a sort of moving torii because this Y or this Q hat it has to come from somewhere - this is something that we estimate as well so usually what happens is that we we alternate between updating this target Q and Q
theta so essentially we Copy Q theta to become our new Q hat we we iterate this somehow but I still haven't told you how do you evaluate this expectation so usually in RL there are a few different ways to do this and either depending on where you come from essentially these are different or these are varying ly viable so if we look back at this this thing here it relies on having tuples of transitions the states the action the next state and the reward that I got so I have to somehow observe Those and I
can obtain them in various ways a very common one when it comes to learning to play video games for example I said you do something called on policy exploration that means that you observe data from the policy that you're currently optimizing you just play the game according to the policy that you have at the moment and the analogy in healthcare would be that you you have some idea of how how to treat patients and you just do that and see what Happens that could be problematic especially if you got that policy like if you randomly
initialized it or if you got it for some somewhere very suboptimal right a different thing that we more perhaps comfortable with in healthcare in restricted setting is the idea of a randomized trial where instead of trying out some policy in that you're currently learning you decide on a population where it's okay to flip a coin Essentially where between different actions that you have the difference here between the difference between the sequential setting and the one-step setting is that now you have to randomize a sequence of actions which is a little bit unlike the the clinical
trial that you have seen before I think the last one which is the the most study one when it comes to practice I would say is off policy where is the one that we talked about rather today this week Is off policy evaluation or or learning in which case you you you observe healthcare records for example you observe registry so you observe some data from the healthcare system where patients have already been treated and you try to extract a good policy based on that information so that means that you see these transitions between a state
and action in the next state and the reward you see that based on what happened in the past and you have to Figure out a pattern there that helps you come up with a good action or a good policy so we'll focus on that one for now and I'll just end the last part of this talk will be about how we can essentially what we had to be careful with when we learn with off policy data and the question is up until this point yep sorry violence that has to be met my answer yeah I'll
get to that on the next set of Five I get to that in the next two slides yeah thank you any other questions about the queue learning part a colleague of mine Rahul he said or maybe it was he just paraphrased it from someone else but essentially you have to see RL ten times before you get it or something to that effect I had the same experience so hopefully you have questions for me after but what yeah exactly but but I think what you should take From the the last two sections if not how to
do Q learning in detail because I lost over a lot of things you should take into it take with you the idea of dynamic programming and figuring out how can I learn about what's good early on in my process from what's good late and the idea of moving to Ward's the good state and not just arriving there immediately and there are many ways to to think about that okay well moving to off policy learning and again the setup Here is that we we receive trajectories of patient states actions and rewards from some source we don't
know what this source is necessarily I will we probably know what the source is but we don't know how these actions were performed ie we don't know what the policy was that generated these trajectories and this is the same set up as in when you estimated causal effects last week to a large extent we say that the actions are drawn again according to some behavior policy Unknown to us but we want to figure out what is the value of a new policy PI so when I want to show you very early on I wish I
had that slide again but essentially a bunch of patient trajectories and some returned patient trajectory some returned the average of those that's called the value if we have trajectories according to a certain policy that is the value of that policy the average of these things but when we have trajectories according to one Policy and want to figure out the value of another one that's the same problem as the Coverity justman problem that you had last week essentially or what the compounding problem essentially like the the the the trajectories that we draw our biased according to
the policy of the clinician that created them and we want to figure out the value of a different policy so it's the same as the confounding problem from the last time and because it is the Same as the confounding from problems from last time we know that this is at least as hard as doing that we have confounding I already alluded to a various issues when you mentioned overlap or positivity as well and in fact we need to make the same assumptions but even stronger assumptions for this to be possible these are sufficient conditions so
under very certain circumstances you don't need them but in the general case well I Should say these are fairly general assumptions that are still strict that's how I should put it so last time we looked at something called strong ignore ability I realized the text is pretty small here can you see in the back is that okay okay great so strong ignore ability said that the potential outcomes y0 and y1 are conditionally independent of the treatment t given the set of variables x or the variable x and that's saying that it doesn't matter if we
know What treatment was given we can figure out just based on X what would happen under either treatment arm where we to treat this patient with with T equals zero T was one we had an idea of or an assumption of overlap which says that any treatment could be observed in any state or any context X and yeah but that's what that means and that is only to to ensure that we can estimate at least a conditional average treatment effect at X and if we Want to estimate the average treatment effect in a population we
would need to know that we need to have that for every X in a population so what happens in the sequential case is that we need even stronger assumptions there's some notation I haven't introduced here and apologize for that but there's a bar here over the these asses and A's I don't know if you can see it that usually indicates in this literature that you're looking at the sequence up To the index here so all the states up until t have observed and all the actions up until t minus 1 maybe this should yeah exactly
happened - one so in order for the the best policy to be identifiable or the value of a policy to be identifiable we need this strong condition so the the return of a policy is independent of the current action given everything that happened in the past this is not this is weaker than the mark of assumption to be Clear because there we said that anything that happens in the future is conditionally independent given the current state so this is weaker because we we now just need to observe something in the history we need to observe
all the compounds in the history in some sense we don't need to summarize them in s and we'll get back to this on the next slide positivity is the real difficult one though because what we're saying is that at any point in the trajectory any Action should be possible in order for us to figure if - in order for us to estimate the value of any possible policy and that we know that that's not going to be true in practice we're not going to consider every possible action at every different every possible point for in
the health care setting there's just no way so what that tells us is that we should we can't estimate the value of every possible policy we can only estimate the value of policies that Are consistent with the with the with the support that we do have if we never see action for at time 3 there's no way we can learn about a policy that does that that takes action for at time 3 that's what I'm trying to say so in some sense this is yeah it's stronger just because of how sequential settings work it's more
about the application demand than anything I would say in the next set of slides we'll focus on a sequential randomization or sequential Ignore ability is sometimes called and tomorrow we'll talk a little bit about the statistics involved in or resulting from the positivity assumption and and and things like importance meeting etcetera did I say tomorrow I meant Thursday okay so last recap on the potential outcome story this is a slide I'm not sure if you showed this one but it's someone that we use that in a lot of and it's again just serves to illustrate
The idea of a one time step decision so we have here Anna a patient comes in she has high blood blood sugar and some other properties and we're debating whether to give her a medication a or B and to do that we want to figure out what would be her blood sugar under this different choices a few months down the line so I'm just gonna I'm just using this here to introduce you to the patient Anna and we're going to talk about a little bit more so treating Anna Once we can represent as this causal
graph that you've seen a lot of times now we had some treatment a we have some state s and some outcome r we want to figure out the effect of this a on the alkmaar ignore ability in this case just says that the potential outcomes of under each action a is conditional independent of a given s and so we know that the ignore ability is the it's a sufficient inability and overlap is sufficient conditions for Identification of this effect but what happens now if we add another time point okay so in this case if I
have no extra arrows here I just have completely independent time points ignore ability clearly still holds there's no links going from a to R there's no from s to or etc so ignore ability is still fine okay if I if I somehow you know choose or if Anna's health status in the future depends on the actions that I take now here then then I have to take the Situation is a little bit different so this is now not in the completely independent actions that I make with the actions here influence the state in the future
so we've seen this this is again this is a mark of decision process that you've seen before and this is very likely this is very likely in practice also if Anna for example is diabetic as we saw in the example that I mentioned it's likely that she will remain so so these previous state will influence the Future state these things seem very reasonable right but now I'm trying to argue about the sequential ignore ability assumption how can we break that how can we break ignore ability when it comes to the sequential setting well if you
have if you have an action here so the outcome at a later point depends on an earlier choice that might certainly be the case because we could have a delayed effect of something so if we measure say A lab value and which could be in in the right range or not it would could very well depend on medication we gave a long time ago okay and it's also likely that the reward could be depend on a state which is much earlier depending on what we include in that state variable okay we already have an example
I think from the audience on that so actually ignore ability should have a big red cross over it because it doesn't hold there and it's luckily on The next slide because they're even more errors that we can have conceivably in the medical setting right so oh yeah the example that we got from people for words essentially that if we've tried an action previously we might not want to try it again or like if we knew that something worked previously we might want to do it again so if we had a good reward here we might
want to do the same thing twice and this arrow here says that if if we know that A patient had a symptom earlier on we might want to base our actions on it later or even Noah the patient was had an allergic reaction at some point for example we might not want to use that medication at a later time exactly exactly so this depends on what you put in the snake so this is this is the like this is an example where I introduced these arrows to show that if I haven't got that information here
then I introduce this dependence okay so if I If I don't have the information about what was it a allergic reaction or some symptom before in here then I'm then I have to do something else right so exactly that is the point if I can summarize history in some good way if I can compress all of these for valuable of a variables sorry into some some variable age standing for the history then I have you know with respect to that history hmm the problem with that the problem I mean This is this is your solution
and it introduces a new problem because history is usually a really large thing usually I mean we know that history grows with time obviously but usually we don't know serve patience for the same number of time points so how do we represent that in for a program how do we represent that your learning algorithm that's something we have to deal with and you can you can pad a history with zeros etc but if you keep every time step and Repeat every variable in every time step you get a very large object right that might introduce
statistical problems because now you have much more variance if you have new variables etc so one thing that people do is that they look some amount of time backwards so instead of just looking at one time step back you now look at the length K window and your state essentially grows by by a factor K and another alternative is to try and learn a summary function learn Some function that is relevant for predicting the outcome that takes all of the history into account and but has a smaller representation than just T times the variables that
you have but this is something that needs needs to happen usually if you work with any most healthcare data in practice you have to make choices about this I just want to stress that that's something you really can't avoid okay the last point I want to make is that Unobserved confounding is also a problem that is not avoidable just due to summarizing history we can introduce new confounding that is a problem if we don't summarize history well but we can also have unobserved confounders just like we can in the one-step setting so one case is
the the one example is if we have an unobserved confounder for in the same way as we did before it impacts both the immediate or the action at time one and the reward at time one but of Course now we're in the sequential setting the compounding structure could be much more complicated we could have a confounder that influences an early action and a late reward so it might be a little harder for us to characterize what is the set of potential confounders I just wanted to point that out and do it reinforce that this is
only harder than the one subsetting so we're wrapping up now I just want to end on a point about The the games that we looked at before one of the big reasons that they the these algorithms were so successful in playing games was that we have full observability in these settings we know everything from the from the game board itself when it comes to go at least and we can debate that with it when it comes to the video games but but in go we have complete observability of the board everything we need to know
for an optimal decision is there at any time Point so not only not only can we observe it through the history but in the case of go you don't even need to look at history week we certainly have more come to mark of dynamics with respect to the board itself you don't ever have to remember what what wasn't move earlier on unless you want to read into your opponent I suppose but that's a game theoretic sort of notion we're not going to get into here but more importantly we can explore the dynamics Of these systems
almost limitlessly just by simulation and self play and that's true regardless if you have follow-ups of ability or not like in StarCraft you might not have full of serve ability but you can try your things out endlessly and contrast up with having I don't know 700 patients with rheumatoid arthritis or something like that those are the samples you have you're not going to get new ones so that is like this is an amazing obstacle for us to overcome if We want to do this in a good way the current all our albums are really really
inefficient with the data that they use and that's why this limitless exploration where simulation has been so important for these games and that's also why the games are the success stories of this a last point is that typically for these settings that I put here we have we have no noise essentially we get perfect observations of actions and states and outcomes and Everything like that and that's really true in any real world application all right I'm gonna wrap up tomorrow nope Thursday David is going to talk about more explicitly if we want to do this
properly in health care what's going to happen we're gonna have a great discussion I'm sure as well so don't mind this slide it's Thursday alright thanks a lot [Applause]