[Música] uma arquitetura e infraestrutura de inteligência artificial para tratar e transformar dados não estruturados da legislação brasileira né Eh esse esse entregável aqui ele ganhou importância né depois do do das reuniões da gente eh eh do projeto E aí especialmente aí o DR DR Thiago ele ele ele gostou né ele achou que isso daqui tem potencial então a gente acabou investindo E aí chegou no ponto que a gente tá hoje aqui para para fazer essa apresentação e e transferência tecnológica a motivação para pro trabalho que a gente esse trabalho que a gente desenvolveu foi justamente
eh a existência desses portais aí de de com informações da legislação brasileira o portal da legislação eh o portal da Assembleia Legislativa do Estado do Ceará e a rede de informação Legislativa e jurídica né o lexml Eh esses portais eles têm eh com com com boa né taxa de atualização né Toda a legislação brasileira né ela tá ela tá exposta aqui eh apesar da da da da quantidade de informação e da riqueza desse dado né a gente enxergou um problema aqui né porque o dado tá todo em formato de texto Então tá disponível para as
pessoas as pessoas podem acessar eh consultar mas como se tratam de de cada cada legislação dessa são páginas e páginas com inúmeros artigos inúmeros parágrafos alinas de informação o acesso direto a a certas partes dela tem tem alguma complexidade Talvez o pessoal do direito até consiga fazer mais com maior facilidade justamente pela por por estar familiarizado com essa estrutura mas a gente entende entendeu aqui que que as pessoas de outras áreas inclusive Ciência da Computação física pessoas que querem explorar eh as informações que estão na legislação brasileira explorar de forma científica elas teriam dificuldade porque
tá tudo em linguagem natural então a gente percebeu aqui a a a a necessidade de de projetar e implementar uma arquitetura computacional capaz de coletar estruturar disponibilizar de maneira autônoma e incremental toda a legislação brasileira Então a nossa ideia aqui é dado essas legislações que elas estão nesse texto aqui que então aqui nessa área aqui isso aqui é um texto certo que tá dentro desses portais eh um artigo aqui com com com quatro parágrafos e o nosso objetivo é criar uma infraestrutura computacional para gerar uma coisa desse tipo aqui é um arquivo Jon que tá
todo estruturado em que a gente tem separado aqui a legislação os artigos os parágrafos e tudo pode ser acessado eh eh de forma direta através de índice né quando a formação tá estruturada dessa forma a gente pode acessar eh dizer por exemplo legislação eh 8242 artigo 34 par parágrafo 2 e acessar direto o descomprimento nesse texto que tá aqui o descomprimento do termo de ajuste de gratuidade implicará no cancelamento E por aí vai Então essa é a nossa e eh eh é o nosso objetivo a gente quer gerar aquele arquivo final e a gente construiu
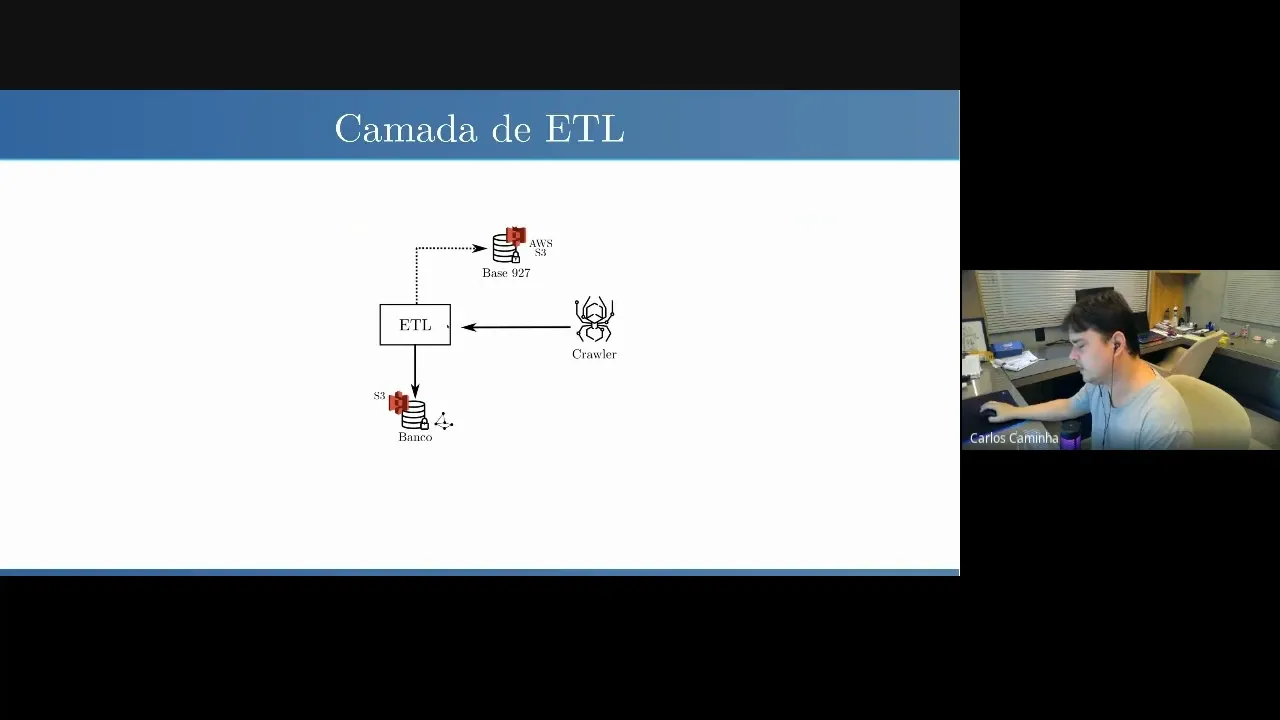
aqui uma uma infraestrutura mínima para para coletar esse dado estruturar e mantê-lo atualizado disponível para PR as pessoas eh eu vou passar aqui os próximos minutos da apresentação eu vou me concentrar em explicar essa figura aqui para vocês parte a parte delas por enquanto eu quero só que vocês fiquem atentos a existe uma representação aqui de uma nuvem que então que a infraestrutura vai ser colocado e alguns serviços de nuvem a gente já fez alguns testes aqui no na WS por isso que vocês estão vendo alguns Logos aqui com referência a serviços deles mas pode
ser colocado em qualquer eh eh eu imagino que qualquer infraestrutura dessa de nuvem qualquer grande Player desse tem recursos similares que que a gente pode fazer adaptações eh e aqui eh fora da nuvem tem os portais que os nossos os recursos computacionais da gente vão acessar esses portais para baixar os dados tem dois tipos de ligação aqui de arestas aqui que estão ligando esses componentes tá que é de consumo aresta de consumo então quando ten uma seta desse jeito eu tô dizendo que esse componente consome a informação que tá aqui e tem também um outro
de fluxo de dado que é um dado que tá aqui ele envia para esse cara que é essa seta que ela tá contínua né que ela não é pontilhada bom então o primeiro elemento que eu acho que que eu que para falar aqui para vocês é é é é o crawler que a gente desenvolveu né Ele é um script em Python quase todo aliás todo o código que tá aqui nessa infraestrutura computacional ele foi feito em Python a gente desenvolveu um crowler que navega nesses portais eh E baixa os conteúdos das legislações quando a gente
baixa essas informações elas vê os as páginas Retornam texto em HTML né com com as tagz inhas lá que tem as descrições a estrutura da página essa essas tags pra gente elas não ajudam muito né A gente já vai ter uma representação de parágrafo aqui que inclusive algumas dessas tags servem para isso para definir essas eh eh eh parágrafos né uma estrutura de um texto que tá na página mas a gente vai remover toda essa informação então um dos Passos que que que a nossa camada de ET vai fazer é remover isso mas o crawler
a tarefa dele é essa ele navega página a página e at E baixa a eh eh a página eh eh com o o o texto da legislação quando o cow executa ele vai enviar esse dado esse esse essa aquele aquela página HTML as páginas htmls para uma camada de etl essa camada de etl né etl é abreviação para extraction transformation load ela vai fazer ela vai tá fazendo justamente pegando esse texto extraindo só pegando esse essa essa esse conteúdo dessa página extraindo só o texto e usando rejects para fazer a separação do documento por toda
a estrutura eh eh que a gente percebeu que existe na legislação quando a gente viu no site eh na nas informações onde tinha a documentação de como a sintaxe né como é que deveria ser respeitada essa estrutura tinha um caminho lá que o pessoal tinha colocado lá que era parágrafo não que era que era legislação aí artigo parágrafo inciso a linha tinha um caminho lá a gente percebeu que não é bem assim às vezes troca Às vezes vem direto uma linha no antes de um de um de um de um de um inciso Tem situações
específicas a gente a nossa equipe aqui de de do direito ajudou a gente a conhecer os padrões que são mais comuns então todo esse tratamento de de de reex foi feito para fazer essa estruturação para quebrar as legislações em todas essas partes nessa hierarquia que ela que ela é formada a gente também tá fazendo o uso da da base 927 né o Avelino inicialmente disponibilizou a base pra gente e a gente colocou ela de forma estática lá no no dentro do do dessa infraestrutura posteriormente a gente recebeu eh uma informação de como como eh eh
acessar a base 927 de forma atualizada hoje já está dessa forma então quando o nosso crawler roda e baixa as legislações Ele já eh eh já consulta a base 927 atualizada e traz a jurisprudência associada à legislação então ou seja além de remover as impurezas né tags htmls coisas que não são do conteúdo do do do do conteúdo que a gente tá interessado em explorar além de remoção dessas impurezas a gente faz a estruturação eh separando a incisos alinas toda aquela estrutura hierárquica hierárquica e ainda né o o esse script Python também atualiza eh eh
a jurisprudência da base 927 atualizada né da dela dela da versão atual dela depois disso esse software que manda esse recurso já no formato que pode ser inclusive modelado como um grafo já já tá todo a gente tem aqui relações por exemplo de citações e se uma legislação cita outra se ela revoga outra se ela altera outra então todas essas informações aí já estão eh eh eh colocadas aqui dentro desse arquivo estruturado que a gente tá mandando para um para um S3 né para um para um para um repositório lá dentro da Amazon para fazer
o armazenamento desse arquivo então recapitulando aqui essa camada de gtl né ela realiza limpeza do dos textos realiza a agregação da jurisprudência das legislações identifica artigos parágrafos incisos alinhas e itens e ela também faz a identificação de relações de citação alteração regulação e e revogação de leis então de fato aqui o que a gente tem eh um gráfico com um gráfico mas com várias eh eh níveis de representação semântica das arestas a aresta pode ser uma citação pode ser uma alteração pode ser inclusive uma legislação eh eu posso montar um grafo aqui que na verdade
seria uma árvore né com com com apontando paraa subestrutura da legislação né então um um vértice poderia ser a legislação e as arestas conectando todos os parágrafos ou todos os artigos daquela legislação e cada artigo conectando seus parágrafos Então a gente tem aqui uma estrutura de um grafo que ela pode ser representada com esse recurso computacional eh aqui são os resultados aqui os números que a gente tem certo até o momento são 200 21000 legislações aqui são todos os tipos que a gente encontrou lá dentro do desses portais então isso tá tudo dentro de um
arquivo estruturado hoje dentro lá da WS na infraestrutura que a gente que a gente criou a título de de ilustração aí pro pessoal né de como como a gente imagina que esse recurso pode ser acessado a gente desenvolveu também uma página lá dentro da dentro da da nossa da infraestrutura vocês perceberam que tinha lá fora tinha feito o desenho desse usuário que acessava um portal web eh que aponta por exemplo pro para aquele recurso né onde onde ele tá lá no S3 esse Portal web a gente fez aqui uma sugestão de uma página pegando a
a a a própria o próprio layout aqui da página lá do CNJ mas obviamente isso pode ficar em qualquer canto pode ficar eh dentro lá do do do das plataformas de Inteligência Artificial do CNJ isso é a se definir a gente fez como sugestão eu acho que eu tenho até ela aqui aberta então a gente fez aqui nessa página a título de sugestão né Tem uma explicação aqui do do do do que é do que foi o trabalho eh explicando como é que a gente fez o grafo de conhecimento O que é um grafico de
conhecimento como ele foi feito da onde tirar a gente tirou o recurso as quantidades que a gente conseguiu baixar e tem uma referência aqui também pro artigo científico que a gente fornece mais detalhes sobre esse processo esse artigo não não é ele não tem todo o trabalho que a gente fez aqui porque ele foi publicado eh no meio do ano passado né e a gente andou avançou na pesquisa de lá para cá mas ele tem toda a parte de de como a gente baixa as informações dos portais como a gente tira retira eh as impurezas
e Como cria as as relações de citação revogação entre as leis ou seja não tem a parte da estrutura da hierarquia né de pegar um texto e separar parágrafo inciso alinha isso realmente não tá descrito Nesse artigo aqui mas a gente tá tá vai gerar uma publicação posteriormente passa a referência aqui para vocês e um um botão para download né Então dessa forma eu explico todo o fluxo a nível mais teórico eh então agora a figura tá toda explicada né Tá aqui o usuário fora a relação dele com o portal o portal obviamente poderia estar
fora também ele está eh eh fora dentro dessa infraestrutura Mas eu deixei aqui dentro porque eu imagino que quando for colocado dentro do da estrutura do CNJ isso tudo de forma transparente vai est dentro da de uma mesma representação mas é dessa forma que tá representado e a gente percebeu que a gente precisaria fazer algumas atualizações né no do no projeto uma eu já expliquei que foi a atualização do Corpus 927 Mas aí o professor Caio vai falar aqui um pouquinho das das das das orientações que o Thiago passou pra gente e como ele tá
Sat [Música]