chat GPT is now able to process images opening up a range of new possibilities for example I drew this picture of a signup form and asked GPT to write me the HTML for it including the CSS in JavaScript after a few seconds that outp put the code and if we open it in a browser we can see that it works perfectly it even captured that I specifically mentioned Instagram in the diagram in fact I even used GPT to write the interface that allowed me to ask that question after a short conversation with GPT in a
jupyter notebook the interface code was complete and working as I had asked I didn't write any of it on my own and it's not just images AI can even generate music based on text like this melody that music LM created after I gave it the description a rhythmic East Coast boombap hip hop beat uplifting and [Music] inspirational the ability of an AI model to work with different types of data like text audio and images is called multimodality but how does multimodality actually work in other words how are AI models able to process these distinct modal
ities of data hey everyone in this video we're going to talk about how multimodal AI works first we'll talk about how text to image models like Dolly work to get an understanding of multimodality in general and then we'll talk about how interfaces like chat GPT are able to both take in and generate text audio and images at their core multimodal models tend to share similar operating principles regardless of the particular modalities considered so let's start with text to image models like Dolly modern image models are generally built on what's called diffusion models which generate images
from Pure gausian Noise one limitation of diffusion models is that they just generate any image at random without any way to control the process text the image models on the other hand add the modality of text to guide the image generation process to understand how these models work with both text and images it's important to first see that both modalities can represent the same semantic Concept in other words when we see the word woman and we see an image of a woman we understand that these are just two representations of the same underlying meaning which
is the concept of a woman itself one is a visual representation and one is a textual representation rather than working with these representations themselves a multimodal AI model will often work with the meaning directly multimodal models use embedding models to convert text and images to vectors that capture their meaning to learn more about how and why this works you can check out our video on word embeddings the relevant question for us is how are these embedding models trained there's no single answer to this question but a model like Dolly 2 for example actually uses another
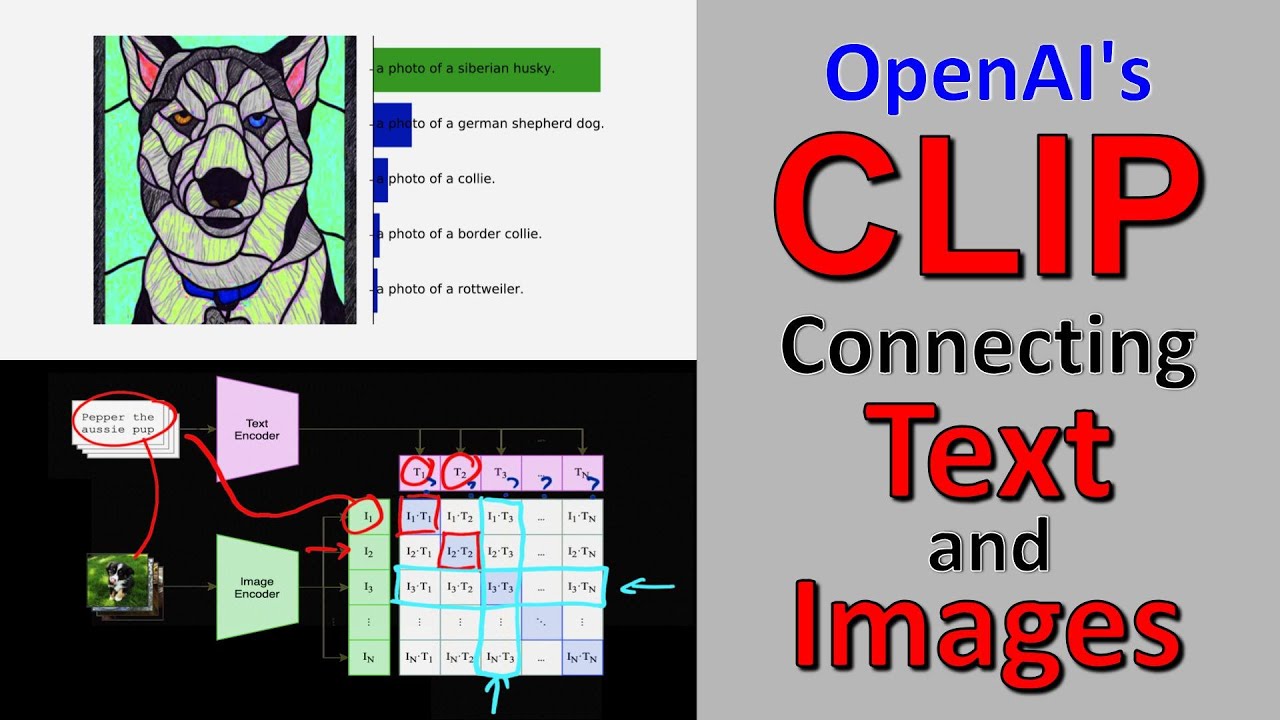
model called clip to train these embedders and therefore learn this meaning space let's take a look at how clip is trained now since our goal is to learn how images and text relate to the same concept we start with a data set of images and their captions for every pair we encode the text and image using the respective encoder so we're left with a pair of vectors for each image caption pair in our case we have a pair of vectors for an Apple for a chair and for a dog we then Train by maxing the
cosine similarity of these pairs the cosine similarity is a distance metric for Vector spaces that measures the angle between vectors by Max maximizing the similarity we are pointing the text and image vectors for the same concept in the same direction giving this direction meaning in the space similarly we train to minimize the cosine similarity of text and image vectors for two different concepts and we repeat this process for every combination of text and image Vector in the batch in this way we'll train the encoders to map both text and images to the same space in
such a way that their meaning is preserved the learning of the space lies at the Crux of how multimodality actually works in this instance to generate an image 2 will embed the input text into this meaning space map the meaning textual Vector to a visual meaning vector and then decode this visual meaning Vector into an image how this actually works in practice is by conditioning the diffusion model which generates the image this gets a little complicated but diffusion models use what are called units to iteratively denoise a gausian input into an image and the meeting
Vector is used to condition this process to generate a specific image you can read our article on building your own text to image model if you want to actually see how this works Works under the hood but what about models that can both input and output multiple modalities like chat GPT text to image models only handle one modality at each end of the model text on the input and images on the output on the other hand chat GPT can now accept images text and audio and generate images text and audio this ability actually leads to
an issue that may not be immediately obvious for example imagine a detective who describes a crime and then ask Chad GPT to paint me a picture of a man who would commit such a crime what is the detective asking the model to do is he asking the model to metaphorically paint a picture of such a man like his backstory his motives Etc or is he asking the model to literally paint the picture of a man that is a literal image of his face perhaps using details from witness reports a priori the model really has no
way to know and in fact humans would give different responses to the same question the fundamental thing to note here is that when somebody says chat GPT he's actually referring to two distinct things first there's the llm chat GPT which is just GPT with rhf finetuning and then there's the UI chat GPT which is the web application that users use to actually interact with the model when chat GPT first launched there was a onetoone correspondence and so this distinction didn't matter but now that the chat GPT UI can accept multiple modalities this distinction does matter
the user interface no longer just uses the llm chat GPT under the hood it also uses Dolly 3 likely whisper and some sort of text to speech model if we speak to chat GPT and ask it to draw a picture of a rabbit this audio will first be converted to text by Whisper then it will use the llm chat GPT to interpret this request and then that response will be passed off to Dolly 3 for the actual image generation we're performing audio to image but there's no actual audio to image multimodal model instead we're using
an audio to image pipeline that actually uses three multimodal models under the hood text is used as the common factor to tie all of these modalities together because of the power and expressivity inherent to natural language still the process process to determine what modality is actually output is unclear and the details have not been published there may be an element of rhf here where during training the model is allowed to Output both images and text and the user decides which one he prefers in this way the model will learn what output modality humans expect in
different requests you can read more about how Dolly 3 might work in chat GPT in our blog all right I hope that gave you a good idea of how multimodality actually works and the distinction between multimodal models and multimodal interfaces if you have any other questions feel free to comment below otherwise I'll see you in the next [Applause] [Music] video














![[1hr Talk] Intro to Large Language Models](https://img.youtube.com/vi/zjkBMFhNj_g/maxresdefault.jpg)