Um so i'll be talking about kind of the two faces of the coin i'll be talking about 20 fpgas at least in my personal experience we're not good at deep learning and then i'll describe three ways in which we can really use fpgas in amazing ways for deep learning so i won't really give a background on deep learning or anything if you don't know what that is at this point you should Kind of go read the blog post and come back but i will start with giving a retrospective of dla this is the deep learning
accelerator that i worked on during my time at intel which was around in 2016. um and this is the part where i think it didn't go as well as as i thought for fpjs in the area of deep learning so um so again to set kind of the stage Where in 2016 uh nvidia just released the pascal architecture and it's i think the first gpu that actually had native support for fp16 for half precision floating point it had a healthy kind of 20 teraflops of that and it's also the first gpu that's starting adding these
kind of specialized instructions things like a four-way dot product using a single instruction instead of the conventional fused multiply ad that gpus had And we were kind of a really small team at intel i remember we were five engineers and eleven interns at one point and we were trying to basically take on that pascal architecture we thought fpgas had what it takes to you know outperform pascal or outperform gpus on deep learning inference at least at batch one and at least at low latency regimes right and so we built this deep learning accelerator we built
hardware For it and software and we basically were hoping to be gpus in that case and so i'll tell you the story of of what happened there and i'll focus on kind of three optimizations that we really thought would give us the leg up and i'll also describe how didn't quite work as we thought it would so the first optimization or the first key thing that we focused on was arithmetic gpus were already noticed you know that Arithmetic is very important and that deep neural networks were tolerant to lower precision arithmetic things like fp16 but
you can also you can only you know do what's embedded on the gpu in this case it was fp16 and floating point arithmetic you know if you don't remember it has a sign exponent and a matissa and so we came up with this you know a block floating point for maps or maybe we used it i Don't know if we came up with it uh but the idea there is that we don't need all of them anticipates in our or even all of the exponent bits in our floating point number and in fact we found
that fp11 was a really uh good format that worked really well for deep neural networks even if we take the neural network and we quantize it post training and we don't do any fine tuning that was basically sufficient to get the kind of the highest accuracy for that neural Network further we took kind of a block of eight numbers in this example or different block sizes and we aligned them all to the same exponent and so what this gave us was uh you know basically we can now do arithmetic on these sign and mantissa separately
and then realign them to another exponent and produce a floating point number and what this means is that we can do integer match instead of floating point maps in the fpga and that was way More efficient so for kind of to show a visual example this is a floating point adder you have a lot of shifters you have a lot of alignment units a lot of you know sign computation and various things whereas the integer adder would be just this unit here which you know adds um the two matrices together and so integer addition or
integer multiplication for that matter is much more efficient than its floating point counterpart and we Thought you know this was the first key thing that we had to focus on and the results were great you know because we stored our model in this block floating point format we actually used way less memory than we would have done so we used two and a half x less memory so in this example here we're using 53 bits instead of 128 and we had an order of magnitude in Terms of area reduction which allowed us to scale up
our accelerator and make it much faster we also organized our multipliers in a systolic array which is something you can't do with gpus so gpus have to synchronize over their on-chip memory things like register files which costs almost as much as the arithmetic unit itself whereas we can forward data directly from one pe to the next pe without Synchronizing over memory which was also an advantage that you can do this on fpgas and so at this point we were feeling pretty good about ourselves and we started looking at the next thing gpus you know they
have this programming overhead and you know from slides from nvidia people uh here it's showing kind of the fused multiply add how much energy it consumes and the control Overhead just for that instruction is about 20 times the energy it takes to do a fused multiply ads right so things like you know instruction fetch instruction decode um operand um loading the operands from the register files and doing all of that stuff costs a lot of overhead right and then you know with the pascal architecture they already started in introducing these more coarser grain operations things
like a four-way dot Product in a single operation so you're doing four times the kind of arithmetic work with the same operation and with the same overhead and so that overhead you know um became four times less it became just 5x but that was still a very high overhead um for if you want to pay it for just doing some arithmetic and we thought you know on fpgas we can do much better because we can define our own instruction set and we can define our own hardware and We can define the granularity of our operations
in whatever way we want and so that's the first thing that we did we came up with these very coarse grained instructions so um basically do convolution was one instruction do max pooling do a linear layer matrix small these these were very coarse grained operations and we didn't stop there we didn't actually send these instructions to hardware and decode them on hardware which is conventionally what you would Do for a programmable accelerator we decoded the instructions in software in a kind of a software unit that we call the assembler and what came out of that
assembler was something that we called config data and that was basically you know specific counter values that went into our hardware and enabled bits that went into various kernels and you know multiplexer control bits and things like that so it was literally kind of The controlled data that's going to the accelerator so you know conventionally you would have instructions uh you would have an instruction decode unit in hardware and usually that's kind of the frequency bottleneck whenever you support a new instruction you need to update this unit and make sure it still you know has
good timing and a good delay and then you need to find a way to kind of broadcast these instructions to all of your Kernels things like you know obviously dot product array um you know different activation functions cooling and crossbars so the different kernels you have in hardware but what we did instead as i said you know we decoded these instructions and software and we had a very lightweight kernel called the vliw reader which read this config data and then we had a very lightweight unidirectional network on step that forwarded this configuration data to all
Kernels in what we call the configuration phase before uh using the accelerator for uh the actual acceleration and so you know the config packet would kind of move along this network and uh useful or um you know the required configuration data would be deposited in the kernels as the config packet made its way around and it had no performance overhead because we overlapped this with the execution of the previous layer And it had you know a tiny kind of area overhead this whole thing cost about one percent overhead in terms of area and it was
very scalable because it's a network on chip it's uh like a unidirectional ring i guess um it you could easily kind of attach a new kernel for example um without you know changing anything else really you didn't change the bliw reader you changed a few things in software to add support for this new kernel and to add The configuration data required for this new kernel but then you simply attached it off of the end of the configuration network and it worked out of the box um so again we were feeling good about ourselves now compared
to this 500 percent overhead the gpus have for uh executing kind of a four-way dot product we had a very small overhead in terms of efficiency at least a very small area of overhead of supporting this lightweight way of Programming our accelerator and we moved a lot of the complexity actually to software and then you know speaking of new kernels we also had a very custom way of adding new kernels at that point we really thought you know the silver bullet would be you know as soon as a new kind of primitive comes up in
the deep learning world we'll be able to support it and we had kind of a configurable we called it crossbar but It's actually a depopulated custom interconnect that we generated and we were able to connect any new kernel to it judge sewing um kind of max cooling and local response normalization here but we also used this to kind of connect an lstm and dedicated kernel we looked at it for element-wise operations as well and we would automatically generate with adaptation to basically build these kernels as big as only as because they Need to be so
if it's used just once in the network it would be very small it doesn't have to be very high bandwidth but if it's kind of the performance bottleneck then we can scale it up or scale it down as we want and so this is something you can't do on gpus right if if you have a new primitive you can write a new software kernel for it but you were stuck with the same hardware in this case we had this ability of hardware accelerating Any new primitive that comes out and so we thought you know this
configurability is a really kind of key feature here um another you know key feature of our hardware is that you know we didn't actually need to build a generic overlay that ran all neural networks all the time um we actually customized the you know the precision um the the parallel the parallelization factors and even the balance between on-chip memory and Compute to exactly match our workload so if our neural network has a you know you know you all know kind of the roofline plots where we look at the operational intensity of the workload and the
compute versus memory trade-off of the hardware it can exactly match our hardware to each neural network uh through kind of a design space exploration framework and so again you know you can't change the hardware in gpus so this we thought was a really Kind of a strong feature so um so at that time also back you know 2016 2017 um more sophisticated networks were kind of being invented so we we moved we're moving from alexnet to googlenet and resnet and so on and they had kind of very interesting structures um they weren't really they were
still feed forward in many cases but they had a lot of branches and things like that so to make sure we used our on-chip memory very carefully we Actually built out this uh kind of full-featured graph compiler which had a lot of focus on managing the on-chip memory i'll show just an example of that so in this slide here i'm just kind of going to show two ways of allocating memory in our onshore buffer and at this point i should also mention you know fpgas have slightly more on-chip memory than most gpus at least if
we compare to the register Files on gpus and it's all explicitly managed memory it's all very flexible in terms of these block cramps or these spot ramps or registers and so um kind of careful the use of this on-chip memory could also be a major advantage in using fpgas and so um so yeah so i was going to show an example here where you know this thing is my memory my on-chip memory laid out linearly and also two ways of Allocating tensors to it one of them is wrong one of them is right and our
software kind of handles this in the first case you know we're allocating tensor a and then when we allocate a tensor b we have the option of putting it right next way or putting it on the other end of the buffer obviously the second one is better because once we de-allocate a we end up with a fragmented buffer in the first case whereas we end up with the Contiguous buffer and the second case so this is an example of the kind of thing that we cared about during allocation and kind of a more real example
of that showing here the scheduling of this inception module in memory over multiple timestamps basically by um by we modeled this as like a 2d tetris basically like we were trying to fit those two-dimensional space-time shapes of the tensors into our Space-time diagram of our memories and by just changing the traversal order of this graph only slightly to take into account kind of larger tensors first we were able to save kind of the utilization of on-chip memory for google net by about 30 and so that really kind of highlighted the importance of software but also
highlighted kind of these key optimizations that we can perform on our explicitly managed local Memory so um so yeah so i mean um for a very short period of time we really thought you know we can uh we we had this you know block mini float we had a very efficient numerical format we had a very lightweight way of configuring delay we had very sophisticated you know on-chip memory management passes to make sure we get you know all the juice out of whatever memory we have on chip we had this extra you know silver bullet
Of customization so if there are new kernels that come out then you know we can implement them in hardware right away we also had different uh optimizations things like quinograd and other things that i that i didn't talk about and we you know we thought that tips the scales in our favor kind of and remember we're competing against pascal which has you know 20 teraflops of fp16 which isn't a small number but it isn't you know It isn't huge either it's manageable we can compete with that and it had this you know um the best
instruction it had for deep learning was a four-way dot product that had 500 control overhead uh or overhead rather so it was um it was kind of a heavy slow-moving device as well at least compared to other devices that are available now and so yeah so for this brief period of time we thought we were on top um In our imagination at least you know nvidia was said jensen was really sad and you know we were really happy um of course in the following year volta was released um and in volta you know they added
these tensor cores and tensor cores meant that they were able to add these high precision matrix small operations and these can multiply two 16 by 16 matrices in a single operation with only the overhead of about 27 percent in terms of um control and so That's 500 percent shrunk to 27 percent in one year um in terms of um you know peak teraflops the device had five times as many peak teraflops as the pascal architecture so they really doubled down on low precision arithmetic and if we look at these numbers today it's like 2000 teraflops
in the hopper architecture and even our you know beloved mini float was now supported on gpu so yeah you now Have 4000 teraflops of mini float fp8 on hopper and gpus as well and so in that case you know um i think in in my mind at least nvidia is much happier and you know fpgas aren't really on their radar we're not kind of competing in the same market or in the same kind of competition at least anymore and i mean the key thing here is that you know many many of the optimizations that we
did Things like to amortize overhead to have a really small um overhead of instructions that was adapted for gpus to have a kind of an innovative um arithmetic or low precision arithmetic that was adapted by gpus um yeah so so there were many things that we relied on that was you know uh you know adapted and used in gpus and other asics as well later and that meant that fpgas were always behind because you know Fpgas are fundamentally less efficient than asics they're about an order of magnitude less efficient in terms of area and power
and they're about three to four times slower on average and so these things weren't enough to compensate for that you know fpga versus asic uh gap um and so you know towards my the end of my time at the intel we wrote up a paper about what we've been working on at the High level we described various you know compiler passes and the hardware and you know uh these guys that i worked with um at intel they were a dream team really were kind of an amazing set of people uh and kind of further testament
as to how badly we lost that competition against gpus you know all of these guys are now at different chip startups where they do have a much better chance of outperforming gpus in the deep learning game um and so yeah So um at least i'm routine for them and i will see what happens there um so so this is kind of um the end of part one uh which is the more somber kind of um less happy more sad uh kind of part of the talk i would say uh and kind of going through this
retrospective of um building fpga accelerators um on fpga based accelerators for deep learning and i will say that kind of i'm just talking about my experience so Obviously there are other accelerators out there that work really well and that you know leverage features that um are not possible to do on gpus and they can get great performance that way i'm just describing kind of what happened at least when i was with intel um four years ago now um and so the key thing is you know it's kind of obvious but if you can build it
onto an asic if it's a general enough Feature that can be hardened into an asic then it won't be competitive on an fpga i know it's a very anti-climactic and very obvious conclusion to this story but but that's basically what's what i learned from the two years i spent there so now on to kind of the more interesting part of this talk and it's you know is there's still hope for fpgas in the deep learning space and i really think there is fpgas are Wonderful devices they're the only thing that you can configure or reconfigure
in hardware and i'll talk about three ways in which i started some work already to kind of see how well fpgas can operate for deep learning also i'll talk about you know three different things um they're kind of things that we started working on but they mainly constitute my current and future work as well so it will be kind of um in some cases have complete ideas That i'm discussing at a more kind of abstract level but i think that's what could make them interesting so the first one i call automl code design and you
know at intel uh when we were building dla because we have this fpga we waited for people to tell us you know what is the best deep neural network architecture you know first it was alexnet obviously And quickly became resnet and you know our job as hardware engineers was to go and optimize our hardware and software to run this workload really efficiently and that is kind of conventionally what we do as fpga engineers but with deep learning especially i would like to advocate for a co-design framework the deep learning workload is very flexible it's not
rigid at all it's not like building you know an aes encryption thing on an fpga or a specific protocol Or or even a compression method that has to adhere to a specific standard or something it is it is multipliers and ads that can be organized in any way and as long as you can train them using back propagation and get good enough accuracy then it will work so um so i'd really advocate for kind of co-optimizing both the hardware and dnm together as opposed to just optimizing the hardware to fit the qr network and for
context let me tell you about Automated machine learning so actually when i left intel i didn't go and work for one of those chip startups i worked for samsung and there we really focused on this idea of neural architecture research and so at a very high level and it's in its most kind of simple form you have an intelligent search algorithm that proposes a deep neural network architecture let's say it proposes this green one here So this neural network would then be evaluated using an evaluator which gives us accuracy in this case it just trained
it gave us the accuracy we would take that accuracy feed it back to our search algorithm and slowly it would kind of influence the search algorithm to propose you know a better neural network in this case this yellow one here which would have a higher accuracy and so if we do this repeatedly that's called neural architecture search And specifically sample based neural architecture search and we can use many fancy algorithms here things like you know reinforcement learning uh genetic and evolutionary algorithms there are even differentiable methods to use here in the search or optimization algorithm
um and again the kind of the key observation is that you know this has become the norm for designing neural networks now in the industry um you don't just take you know efficientnet or Resnet off the shelf and use it i mean sometimes you do that but if you're a bigger lab or a bigger group you usually customize the neural network to your exact you know accuracy target or whatever target you have and so the key thing i want you to take from this slide is that different dnns can perform the same task you can
change the algorithm you can change the structure you can change the topology it's fine And so as i said that samsung really had a big focus on that mainly because we didn't want to just focus on accuracy as an objective but we wanted to customize the neural networks to run on samsung phones in this case so samsung is a device company so so it's different than you know google amazon facebook because these guys have data centers they have a lot of compute there and their business is mainly to get your data through the data center
To kind of use it for making your ads better or something and so um and so uh so they're in the data center business and they might not care as much about running things on device whereas samsung is a device company they sell the biases they want these devices to still be smart so they want to run the ai algorithms on the devices itself as well um so um so what we were doing there is you know we had our search algorithm Again propose a deep neural network but when we're evaluating it we didn't just
look at accuracy we also looked at latency on that specific device so we ran the neural network on the device we got the latency and then fed back to the searching algorithm typically we would put kind of a latency threshold so within three milliseconds of inference uh what is the best accuracy that i can get and we will keep optimizing this neural network structure Until we find um that accuracy and so at samsung i kind of worked on a couple of a few different applications actually in which we used hardware aware neural architecture search so
in this case you know the hardware is fixed in one case it was the samsung tvs where we were building a kind of a super resolution network based on generative adversarial networks and we were able to shrink it by about 30x just by adding it to our kind of neural architecture search framework in another case we were trying to implement the kind of speech assistant on samsung phones to be actually implemented on device instead of having kind of a call to the server and coming back with the result we wanted it all to happen on
device and so in this case we achieved kind of a 5x compression um compared to one unoptimized version Just by kind of adding this hardware spec to the automated machine learning formulation and so so why do they say all that why am i talking about automated machine learning and neural architecture research i'm talking about it to convince you that changing the neural network architecture is the norm now in industry um you change it to fit your hardware but then we have these fpgas which in Which you can change the hardware you know it's a reconfigurable
hardware and so this leads me to kind of you know the natural thing is to put both into an auto mal formulation to have co-design neural architecture searches what we called it and so and our searching algorithm will propose a neural network architecture but it would also propose some kind of hardware so to build both the hardware and the neural architecture in tandem and then when we evaluate it We will train the deep neural network and then run it on that specific hardware or simulate it and we would not just get accuracy but we'll get
accuracy on all of the hardware parameters so things like latency power area throughput if you want so basically would have this multiple objectives that speak not just to the neural network's um parameters but also to the hardware parameters because you can change both In that formulation and so we wanted to try this out and so we made a very simple kind of proof of concept experiment where we had a simple dnn search space so the deep neural network had three stacks each stack had three cells and each cell had kind of this searchable component where
you know the algorithm or the search algorithm can change the different operations here and can connect them up in different ways as Well and this was the only thing that changed and then it was repeated in the network and we also took kind of an open source hardware actually i should write its name here called chai dnm from xilinx and so it was a very simple accelerator that works on uh zinka pga i think um and the idea was um that it had some configurable parameters and we thought for this proof-of-concept Experiment we will just
expose those very simple configurable parameters to the search problem and see what we get and so it was things like you know buffered depth um the parallelization in the convolution engine the memory interface width and whether a pooling engine existed or not so these were basically our parameters and the ranges are annotated here very very simple parameters nothing fundamental uh or profound about how we parametrize our Hardware but when you put those parameters with kind of these uh the neural network parameters together we already had like 3.7 billion valid combinations of deep neural network and
hardware together and we found through enumeration that only 3000 of them were pareto optimal so we were starting that spiritual optimum in terms of accuracy latency or area fpga area and so we already said you know it's Very hard to find this uh to find these periods to optimal points it's like a needle in a haystack basically and so we were getting more confidence that you know compared to a hand optimized and hand designed neural network and a hand optimized hand-designed hardware i think we can do better so we ran an actual search to compare
this and as i said you know this um this accelerator we were using was actually Hand designed to run resnet in google nets and here i'm showing them an accuracy kind of efficiency plot um so efficiency as in performance per area in this case and so when we ran our co-design framework after a few iterations we found this network that we called cod1 and it was already dominating kind of the resnet cell running on this hand-tuned accelerator For it and then um and it was dominating it in in terms of both accuracy and area and
performance per area at the same time so we improved accuracy by about two percent while simultaneously improving efficiency by 40 um and so we thought that was a great result when we continued to run our tool we also dominated the google net cell by a smaller margin but it was still Better than the hand design alternative and so the key takeaway here is that you know just by exposing these architecture parameters these hardware parameters to an automated search uh formulation we were able to find things that are much better than when we had optimized the
hardware for a specific neural network even though that Neural network is very widely used and very and has very good accuracy we still can find something better by just putting them both in a co-design formulation and by running it to discover both automatically um together and so um so you know dnns are very flexible workload um i i'm i'm advocating especially in the case of fpgas of you know i don't Want someone to come and tell me you know my dla can achieve uh 80 images per second on resnet 50. instead if we run this
through an automated co-design framework and we expose really non-obvious hardware parameters and detailed hardware parameters to the search problem i want us to kind of reach a stage where we say you know this fpga can achieve 100 images per second on the task of imagenet classification Irrespective of what the network looks like it's just this task i'm finding the network that works best with my device um and we're not quite there yet so obviously the example i showed is where we only exposed some parameters of a predefined accelerator but i think the more hardware parameters
that we expose to an automated code design framework the more we can find you know non-obvious ways of accelerating this you know deep neural network workloads Onto fpgas and of course you know a key thing is that you know gpus can do this the hardware is fixed and so fpgas are the only device to that we can use for this kind of customization okay so now quickly on to the second thing that i want to talk about logic neural networks um and so so i'm showing a diagram here of you know a neural network And
neural networks have this mathematical abstraction right um so they're formed of multiplications they're formed of additions and non-linear functions and the key thing the key reason for using this mathematical abstraction is because you know we first of all we can understand it and second of all it's differentiable we can train it using black propagation which is the main reason you know the neural networks work and they can do Different tests but through you know a process uh that's you know called is called synthesis we can transform this network uh let's say if we're kind of
unrolling it completely and synthesizing the whole thing um into a circuit net list formed out of lookup tables and so um so there was a paper locknet by you know early wang james davis peter chang and george costantinides a really amazing paper that changed my view of How i look at these deep neural networks and they looked at the circuit net list and they thought you know we can also train the circuit networks so let's go through an example here of kind of a one input slot you can write it out as an equation with
these c parameters deciding on whether that plot implements like a straight through wire or a not gate so these are the two options here and what they found in there or what They proposed in their last paper is that we can interpolate between those discrete points that are implemented by the lot using something called lagrange interpolating polynomial to allow us to implement the continuous backward function uh using real values you know gradients and real valued um activations and so so now i'm not looking at this and saying you know this is a circuit Netlist and
now this is also differentiable and i can also train this so this is just another neural network just formed of much finer grained components um and i can still train it and i can still kind of reason about it in the same way um so let me kind of talk about this work that we did together um you know if you have a deep neural network i'm showing here a single dot product of the Deep neural network where x's are you know my activations w's are my weights you have multiplications and then in addition you
can binarize this deep neural network uh basically an extreme form of quantization which makes the x's and w's into a single bit each uh changing those multipliers into xnor gates and that's great that's something that you know again we can accelerate on fpgas quite well because it's kind of the only suitable platform uh for vienna And acceleration i don't think there are any other chips that are suited for bit operations as well but a key problem of bnns is that they have this really huge fan in here even though we made this operation uh we
simplified it all the way you know from a multiplication into a simple uh single logic gate for one bit multiplier we still have this very high fan in here which usually um you know Is the bottleneck for these bni implementations on fpgas and what um what the imperial group did in their lot network is that they managed to change this bnn um representation into something they called lutnet in which they replaced these xnor gates with you know multi-input lookup tables much like the ones you find on your fpga and that meant that they were able
to kind of increase the logic density of These operations here and they were able to get you know a lower fan in uh coming into the accumulator here so they basically they found uh they were able to change um bnn uh neural network topology to better fit fpgas by doing that and because they were able to train in the lot domain um using these like brand interpolating polynomials they did that at no accuracy loss essentially and so they've really Shifted where operations happen they did the top-up training and it still worked as well but with
higher efficiency on the fpgas and also so i really like these papers i actually approached them and we collaborated on a work that we call logic shrinkage and that was kind of presented in fpga earlier this year where we um you know looking at this from a circuit perspective I want to be able to optimize that circuit in however way i like and then i want to be able to do top-up training for it which is something i can do now with these lagrange interpolating polynomials as i said so we basically adapted pruning a very
fine-grained pruning actually a very fine-grained activation pruning into this circuit netlist domain and we pruned away pieces of the circuit which we thought were not contributing to the function as much So low saliency inputs basically in our lots and we were able to do uh top-up training to kind of regain the accuracy so what that meant is that you know compared to a state-of-the-art bnn but not just the state-of-the-art dnn a state-of-the-art bnn that was heavily pruned in the bnn domain compared to that our logic shrunk you know prone blocknet was 3 to 5x more
area efficient when implemented on the fpga And you can think of it as just you know we are reorganizing how computations are happening to better fit the fpga lots and then we are removing all redundant um computations at this very fundamental you know lot level uh of fpgas and so so i think i think this is a very promising direction and one that is uniquely suited to the fpga to the programmable fpga fabric um and so the idea here is Looking forward i want to explore this idea of you know having an unrolled neural network
combining that with fine-grained pruning which you can only kind of take advantage of well with an unrolled neural network and then with this extra you know unique feature of being able to train in the blood domain i think we can really translate you know a fine-grained neural network that looks much different than what we have today into fpgas in a Very efficient way uh obviously you can't do this on on gpus in fact when gpus try to support fine-grained sparsity they support a very constrained form of fine-grained sparsity in their ampere architecture where two out
of every four elements in a weight matrix had to be zero and then they kind of stored it in a compressed format and they were able to implement it in their tensor cores in Kind of a really efficient way um but for fifty percent fine grained sparse t you expect a 2x speedup right but in this case it was between the speed up according to nvidia's own numbers so this is taken from their blog post it was between 10 and 15 so very small speed up a very modest speed up compared to the amount of
sparsity here so i really think kind of going down the path of unrolled neural Networks um and perhaps also leveraging this idea of training in the lab domain can get us to much finer grained higher efficiency networks um in hardware on the fpga and i don't think we actually need to stick with the current fpga fabric um for these kinds of problems and i haven't looked into that yet but you know i'll just leave you with that question is what if we also change the fpga logic fabric to suit Kind of these logic neural networks
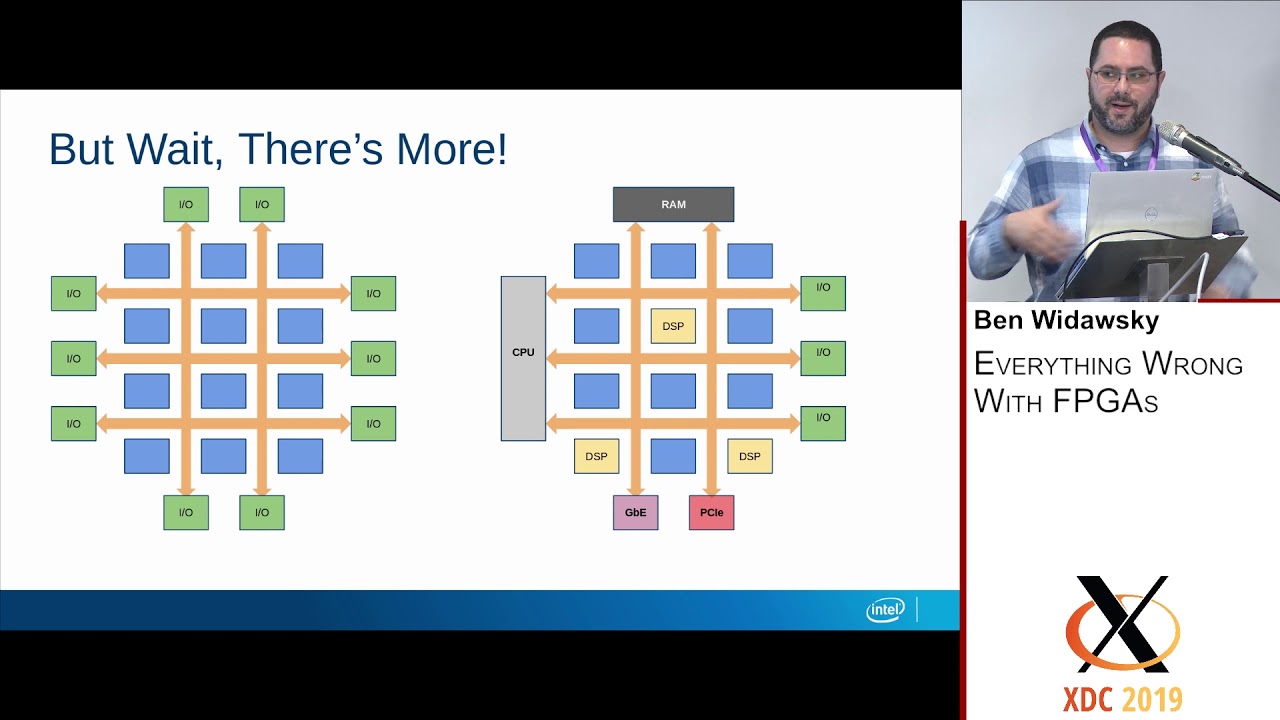
and this is something i'm really interested in looking at in the near future hopefully okay so so two things two ways of using fpgas for deep learning which i think works really well now the third one is actually the most relevant one to the crossroads research center and i'll talk about kind of fpga dla devices uh so i'll start by saying you know that deep learning is heterogeneous so so far I've been focusing on this concept of a deep neural network but that's only one piece of a deep learning workload if you look at that
what happens in a data center or even on your phone or anywhere dnn does not live in isolation there's stuff that happens before uh things like you know packet processing compression encryption data augmentation data manipulations and so on and there's stuff that happens after as well as a Result of whatever the network predicts or um or finds and so um so people are starting to realize that and there is this paper from google trying to quantify um what is the percentage percent of time spent in the input pipeline of common deep learning workloads so they've
profiled their deep learning workloads in their data center this is a Cdf a cumulative distributed distribution function of what they found and what they found is that on average thirty percent of the time is spent in the input pipeline so it's not a small number and for twenty percent of the workload there was this long tail distribution where twenty percent of the work twenty percent of their jobs basically consumed more than 35 in their input pipeline up to i guess 100 In this case a separate study that focused on training specifically um found that you
know between 50 and 65 percent of each epoch of training was spent doing other stuff other than the forward pass the backboard has and the parameter updates it was spent you know sampling the mini badges was spent on data manipulations and data augmentations and things like that and so there is a lot of overhead there um and it's not because you know I'm not speeding up my neural net deep neural network well it's because i'm neglecting all these other parts right so you know my talk so far has been focused on the dnn and how
to build hardware for the dnn and the focus of most stocks and most groups they're actually um and most startups are exactly that you know focusing on the deep neural network you know but what happens to everything else in modern data centers um Everything else usually falls back to a cpu um and they have nothing against cpus they're very important components in the data center they run the operating system and they need to be very general and very robust but because of that for these data intensive kind of functions things like processing inline compression and
encryption data manipulations they are actually very slow They also have unpredictable latency because this you know they have to do all of this other stuff as well like an operating system and so at this point i kind of just want to quickly review andel's law so going back to our undergraduate degrees you know we we studied this law and it's it's always kind of a hindsight thing i find at least what i found when i was in industry people think about it after the fact But i think with deep learning we can kind of try
to take into into account in the beginning by exploring deep learning applications end-to-end and i'll just give an example here is if i speed up my deep neural network by an order of magnitude by 10x then my overall application speed up will just be limited to 2.7x 2.7 times and that's assuming you know this 30 number That i showed in the previous slide that i'm spending 30 percent of the time in pre-processing no matter how fast i make the neural network i'm kind of limited asymptotically by about 3x applications people so the question here now
is how can we optimize the system architecture to accelerate not just a deep neural network but the end-to-end kind of deep learning workload Um and so how can we think about not just the dla or not just the gpu or a stick but about the whole system um in that context and of course you might expect that what i'll say next is you know let's replace that software fallback with hardware acceleration and you know um i i think there is a a necessity for having kind of a purpose-built single-function deep learning accelerator That's built on
an asic and that runs really efficiently for dense linear algebra because turns out that that's the main workload in deep journal networks no matter how many new layers people come up with that's the main thing that we're doing there so we need that but we we also need something for everything else we don't want to have the software fallback for everything else we want something that matches the bandwidth and The line rate of data going into that dla and it's able to keep up with computations happening there and so um so i think fpgas are
the only reasonable solution there just because of the reconfigurable hardware we can um we can build an asic for certain functions here but it will always like you always have you know different functions and new things that come up that cannot be accelerated um with kind of a fixed function accelerator we need Programmable hardware to become the norm in data centers for that reason and you know i worked a bit on kind of accelerating various relevant applications onto fpgas one of them was gzip compression where we were able to achieve like 20 times performance per
watt improvement versus a kind of uh a zero load um intel cpu server a high-end server um part from intel and so um so i don't think i need to convince you too much That um hardware acceleration on fpgas can outperform cpus and these data intensive functions quite easily if you follow this seminar also james's group and others talked about pegasus where you get a two-order two orders of magnitude improvement and something like network intrusion protection and kind of the list goes on there are so many applications that fit exactly in this step of pre-processing
In deep neural networks that would be quite like accelerated quite a bit by just holding them onto an fpga instead of a cpu and you know in industry people are not kind of um people are noticing this right and so you'll find in microsoft sbjs are already kind of in all of their data centers um nvidia also recently trying to kind of site that the cpu bottleneck and data centers by at attaching the gpu Directly to their kind of melanox switches these connect seven switches um um that are used in data centers so instead of
you know conventionally you would have a cp a gpu attached off of the pcie link from the uh cpu here but in that case you know it's it's uh network attached and so they would come in and it would be accelerated here right away um there are also these um a-caps uh presented by you know uh invented by Xylox right where you have these a dedicated ai engines or deep learning accelerator with the fpga soft logic on a single device and i'm really interested in that last one um and this notion of you know hybrid
fpga dla devices i think as i said before like deep learning is a heterogeneous workload it has other Stuff other than the deep neural network and so if i want to accelerate it i want the device that can accelerate all pieces of that workload and so i really think you know the fpga is the right device there and so we can use it to kind of implement various custom pre-processing or post-processing that needs to be tightly coupled with the deep neural network on the fpga part and then we can have a Purpose built a single
function it doesn't have to be single function it can be somewhat programmable as well but a purpose-built deep learning accelerator on the other side to to accelerate the deep neural network itself and so there are many research questions here and the rest of this stock will not provide answers to all of them because this is kind of my current slash future work over the next few Years hopefully but you know how do we change the fpga architecture and how do we do its cad um you know in this new in this new hybrid device what
design style do we adopt kind of how do we compile applications to it this is something i started looking into with my collaborators basically do we have two separate compilers for each part and then we stitch them up somehow or can we maybe even have a single compiler that Partitions an application automatically onto these two parts um let's you know prototype some applications to see if we actually need that tight coupling or if other architectures are going to be used so we need kind of an architecture exploration framework for these hybrid fpga dla devices as
well what does the dla architecture look like i mean many dla architectures exist but none that have this fine-grained Access to programmable logic and so this one will probably look a bit different and so we need to think about that quite carefully as well what happens with the memory hierarchy do we share memory between those two parts do we have memory coherency or what what are we doing there are they completely kind of separate memory banks um and finally the interconnection network and that's actually where i do have some work um That brings me kind
of all the way back to my phd um so uh so in the next couple of slides i'll talk about what i think is the right interconnection network for this kind of device um which is embedded networks on chip for fpgas and so the idea there was that you know when i started in my phd back in 2011 2012 um fpgas were becoming large enough to be useful for um for kind of computing Applications right for compute not just for you know logic or protocol translation or various kind of communication cores which is where fpga
is usually played but they're getting large enough to implement kind of various you know scientific applications and things obviously like deep neural network and compression and network intrusion detection and all of that stuff But an fpga designer had to worry about so many things they had to worry about their application logic in terms of building the hardware for it they had to worry about the system level interconnects connect pieces of their application they had to worry about connections to external interfaces things like memory controllers and pcie transceivers and you know ethernet and they had to
close timing time and closure is a huge issue something that's Kind of very few people can do efficiently and well and so we thought that we would try to solve all these problems by removing the worry of kind of the fpga designer around the system level interconnects we would build that for them it would be very high bandwidth it would be connected to these external interfaces and it would really help in In shifting the focus of an application developer into just worrying about the application logic itself so i'll attempt to kind of summarize my um
my five years of phd into one slide but basically we looked first at this uh at the noc architecture itself what kind of virtual channels do we use what kind of allocation and switching policies would work well and then the efficiency of implementing this network on chip whether hard or soft on The fpga we found that you know a hard network on chip that's clocked at a very high fixed frequency was the best way to do it but then the next question was you know how do we connect that to the fpga fabric so we
have this high frequency uh noc and we want to connect it to a programmable soft you know fpga module that can have any kind of data width and any frequency so we built a very flexible kind of fabric Report it's like a kind of the on-wrap and the off-ramp from into the network concept to the fpga fabric and obviously we had like um basically handling back pressure from the network on chip um clock crossing clock domains uh adapting the width and packetizing the data into that component and it turned out to be quite essential and
then finally we uh we we started worrying about the design styles how do we support latency sensitive design on On the network on chip can we reserve kind of certain virtual channels and have qualitative service guarantees uh how do we support both streaming and transaction communication onto the network concept like a response request kind of a master slave communication um and so we built all of that into kind of a cad system where we identified kind of the communication patterns on a data flow graph we did a clustering step and Then mapped different modules onto
the network conchip and finally created some traffic managers to allow kind of the use of this shared interconnect resource on the fpga quite efficiently and the final comparison was kind of taking all of this taking this embedded network on chip with the cad flow and with you know the fabric port and everything comparing it to commercial bust based interconnect generation tools We were about three times faster in terms of frequency or up to three times faster i should say and up to 78 times smaller so the interconnect overhead was much smaller when we do that
so this kind of hopefully should convince you that we should put embedded networks on chip on our fpga to handle system level communication but to take it a step further we also kind of prototyped a bunch of relevant Applications um and they are relevant also for kind of the uh this idea of pre-processing and deep neural networks i didn't know at the time that they were relevant but they're now relevant in retrospect um things like you know jpeg compression for example we were able to show that with the network control the design can be much
more predictable and can have a much higher frequency if we use an nlc we looked into ethernet switching and Because we can use the network on chip as a switch essentially as a hardened switch on the fpga we were able to achieve way more switching than was previously possible on the fpga we were able to almost match the transceiver band with that generation of fpgas actually and finally we looked at back processing with my collaborator at the time andrew uh and he showed that he can build kind of 100 gigabit per second packet processor on
the fpga with much higher throughput and smaller area than what we can do previously and so i'm getting close to the end of my talk now but basically um what i just talked about was you know how we can use an noc enabled fpga to connect to to implement important pre and post processing functions Of a deep learning workload and connect that efficiently to in an abstract way to um to a deep learning accelerator that is really focused on you know the deep neural network part and so i think that that's kind of an amazing
device to continue to look at in the context of accelerating these deep learning applications end to end And so and so that's it really that's all i have for today so to answer the question is there's still hope for fpgas yes there is a lot of hope i think fpgas are wonderful reconfigurable devices and there are so many things that we can do with them and we're barely just scratching the surface um i talked first about you know this idea of automated co-design Um the fact that we can change um both the neural network and
the hardware to fit each other in the same problem formulation can get us to kind of new ways of accelerating these neural networks in hardware and then i talked about logic neural networks where we have this profound thing of being able to retrain a circuit net list so imagine what optimizations we can do at the net list level and at the lock level that we can then um do and then regain accuracy By performing this retraining step and finally i talked about fpga dla devices as potentially the ultimate devices to kind of accelerate deep learning
applications end-to-end and to um to really replace this idea of software fallback and modern data centers uh and throughout this talk i've been kind of trying to see okay what is the key property of fpgas that allows it to kind of work really well And i didn't find anything more profound than just the fact that it's reconfigured it's hardware and it's reconfigurable that's the only thing uh that's the only kind of device that you can use for that with that property um so i should also mention at this point that this has been kind of
a walkthrough of my personal work uh with lots of collaborators of course but there are so many other Interesting data points out there i was hoping to make the slide deck a bit more complete and talk about other people's work as well but it's just i didn't have time to put it all together so this is just an acknowledgment that this the things i presented are some ways of using fpgas but there are a lot of other interesting and potentially better ways of using fpas as well that are out there For deep learning so that's
all i had so thank you so much and i'm happy to take any questions at this point you





![OverGen: Improving FPGA Usability through Domain-specific Overlay Generation [Invited]](https://img.youtube.com/vi/Vf1cJr-q1ns/maxresdefault.jpg)








![Under the Hood of OpenFPGA [Invited]](https://img.youtube.com/vi/PseTkJ-HfKU/maxresdefault.jpg)
![Groq’s Software-Defined Hardware for Dataflow Compute [Invited]](https://img.youtube.com/vi/nP_9lkDsD-E/maxresdefault.jpg)



