Ta ¿Qué tal? Muy buenos días. Eh, bienvenidos. Sean ustedes bienvenidos. Permítanme, voy a hacer un pequeño ajuste, pero este. Bueno, bien, vamos a comenzar. Eh, sean bienvenidos. Mi nombre es José Luis Sánchez Cervantes y antes de iniciar con la sesión de del día de hoy, les voy a Hacer un recordatorio muy importante para dar inicio con el tema aprendizaje automático. Todas las clases son sincrónicas, las evaluaciones se rigen por el horario de la Ciudad de México, lo cual es algo que deben que deben tener en cuenta. También durante las sesiones sincrónicas es indispensable, o sea,
durante estas sesiones es indispensable que ingresen su nombre completo a través del enlace de asistencia, El cual se encuentra en la descripción de la sesión de la sesión correspondiente. El horario que se comprendido para esta sesión es entre es de 9 a de 9 de la mañana a 9 de la noche, es decir, de 9 a 21 horas. Con esto se garantiza un adecuado control de la asistencia. Sí. Eh, bueno, en cuanto al folio que se solicita, esto es opcional. Ustedes tendrán la información en la descripción del de de la de la presentación. Eh, se
les invita a a a escribir sus inquietudes en el foro en el foro de este curso propedéutico, en este caso inteligencia artificial. Este se encuentra disponible en la plataforma del Tecnm. Hm. no existe o no se maneja una creación de de grupos, no manejamos una una creación de grupos como tal. H el usuario Eh va a contar, esto es muy muy importante, va a contar con dos intentos para realizar la evaluación. Sí, estas evaluaciones se encontrarán disponibles el sábado 17 de enero en un horario de 0 a 23:59 horas. Reitero, el sábado 17 de enero,
en un horario de 0 a 23:59 horas se realizarán las evaluaciones. Finalmente, aunque cuentan con lecturas y material de estudio de MOC, esto es una sugerencia propia, eh pues sería bueno que tomen anotaciones para que con Base en su nivel de abstracción vayan eh eh detando los conceptos con los cuales tengan dudas y esto. Entonces, de esta manera, pues tienen información relevante y aquella que no que consideren no es de utilidad, por así decirlo, eh pues la la desechen y hagan preguntas más concretas. Muy bien. Eh vamos a iniciar con el eh con el QR
de asistencia. damos alrededor de De tres unos 5 minutos para que eh tomen tomen su asistencia. Me gustaría saber eh en el foro de dónde nos acompañan. Incluso aquí se dedican algunos son del área de computación, otros son de otras áreas, supongo. Entonces, sí sería interesante saber de dónde nos acompañan y qué actividades realizan. ¿Por qué? Porque el aprendizaje automático tiene aplicación en muchos dominios, por no Decir en todos. Entonces, es tan vasta su aplicación que que podrían ustedes incluso diseñar un modelo que resuelva ciertas ciertas problemáticas de su día a día. Muy bien, eh
vamos a a iniciar. Entiendo que ya bien. Eh, recordemos eh un poquito sobre lo que implica la inteligencia artificial. Ya lo vieron con la este doctora Telma en la sesión pasada. Vamos a hacer un breve repaso y voy a Complementar algunas cuestiones que eh que son importantes. Muy bien, vamos a a primero que nada hm voy a dar a a conocer el acerca de aprendizaje automático y eh unos pequeños fundamentos. ¿De acuerdo? Eh, lo que se va a lo que estamos viendo es eh qué es inteligencia artificial. Bueno, la capacidad que tiene un sistema de
informática para pensar De manera autónoma y genuina, es decir, que no tenga intervención humana. Eso es muy importante. Sí debe tener capacidades de imitar el pensamiento de nosotros los seres humanos en distintos ámbitos, sea médico, educación, finanzas, salud, seguridad. Y entonces esto va a ayudar a la toma de decisiones, la percepción racional del entorno y la selección de estrategias para conseguir un objetivo determinado. Sí. Eh, la inteligencia artificial no es no es nueva. Estamos hablando de de por ahí de 1956, donde su su origen como término. Y pues bueno, si ustedes buscan en la web
la cronología de la inteligencia artificial, se van a encontrar con con algo muy con algunas cosas muy interesantes, como eh una parte que le llaman oscurantismo, donde tuvo un tuvo un bloqueo, digamos, donde tuvo donde ya no ya no ya no tuvo hacia dónde crecer y Se quedó hasta ahí se utilizó que que fueron los algoritmos los algoritmos clásicos que tenemos. ¿De acuerdo? Eh, dicho eso eh lo que es inteligencia artificial, eh tengamos en cuenta eh algo muy importante actualmente. Hay inteligencia artificial débil o estrecha, ¿sí? Y es el único tipo de inteligencia artificial que
existe actualmente. Hay esfuerzos porque estos crezcan. Entonces, eh tenemos, por ejemplo, Amazon, Alexa, Siri, Google, eh diversos asistentes, Spotify, Netflix, tenemos una serie de una serie de de de sistemas con los cuales nosotros interactuamos día a día y pese a que conlleva mucho trabajo, mucho esfuerzo de entrenamiento, mucho modelado, Hm. Pues prácticamente estamos hablando de de que en realidad todavía no es algo s super avanzado como lo llegamos a ver en las películas. Otra categoría es la inteligencia artificial fuerte. Esto ya es hipotético, es es un concepto teórico al cual se quiere llegar y y
bueno, lo que lo que busca es que cualquier computadora, cualquier equipo eh informático eh pueda h realizar cualquiera cualquier tarea como un ser humano. Sí, incluso que este se pueda adaptar a nuevos contextos. Entonces, el salto entre una y otra es abismal. El ejemplo que que me que bueno que Usualmente manejo es eh por aquellos que hayan visto y si lo han visto pues podrían poner en el foro. Sería interesante que que pusieran si conocen si han visto yo Robot y en qué momento de la película es en el que en en el que Sony,
el robot eh actúa como un humano, es decir, ya toma una decisión de de asociarse con con el actor. Bueno, en este caso era Will Smith. eh no recuerdo el nombre del personaje, pero eh en aquel momento de la película Se se asocia y y Sony actúa por propia por propia inteligencia para este para salvar la la vida de de Will Smith en ese caso. Bueno, si si no lo recuerdan, eh es en una escena y si no pues quienes no la han visto, dense un tiempo y veanla. Cuando Sony cierra el ojo, le hace
un guiño al al detective el detective, entonces él él hace un guiño y en ese guiño le está indicando de que confíe en él porque va a hacer algo para salvarles la vida, ¿no? Y Empieza a disparar eso. Ese eso es cuando él por sí mismo ya pensó, identificó el entorno que era peligroso y tomó una decisión para salvarles la vida. Entonces, esa es una inteligencia artificial fuerte. Otro ejemplo que podríamos tener son los aviones que por sí mismos puedan identificar espacios aéreos restringidos y que que turbulencias que puedan autocontrolar sin la intervención del piloto
para no Caer. Posibles eh accidentes para prevenir posibles accidentes. Los vehículos autónomos también, aunque manejan cuestiones algorítmicas últimamente, también están llenos de sensores, manejan modelos de inteligencia artificial, pero eh podrían todavía les falta para para considerarlos como que tengan una inteligencia artificial fuerte. Después de esta eh eh sigue la superinteligencia artificial. La superinteligencia Artificial, pues algunos de algunos de ustedes han visto eh inteligencia artificial, una película, han visto eh Robocop eh y también ciudades inteligentes donde si me acerco a un lugar donde está muy asoleado y eso de repente pues no sé, hay alguna brisa
porque el entorno eh interactúa con interactúa con el usuario de manera natural en la cual eh Pues todo es muy cómodo porque la misma inteligencia nos provee de las comodidades, de los Servicios, de la seguridad para no este para que el humano no intervenga. Entonces es tan transparente, pero eso eh sigue siendo sigue siendo hipotético. Entonces, nosotros actualmente, reitero, estamos en la inteligencia artificial débil. Mm. Mm. Bien. Eh, existen algunas tecnologías clave, algunas existen algunas tecnologías Clave que eh que deben seguir desarrollándose, claro. Ah, de esta manera, eh, para que esta manera se vuelva realidad.
todo esto que vimos aquí, eh todo, bueno, aunque estamos acá y la idea es hm brincar o o dar un salto hacia hacia fuerte y luego a superinteligencia, requiere que, por ejemplo, las redes neuronales requiere una maduración de las redes neuronales, ¿no? que necesitamos que que el software aprenda, que aprenda de manera eh a Través de imágenes, a través de de diversas fuentes de información para entender un entorno. Necesitamos que la computación neuromórfica, al igual o o vinculando estrechamente vinculadas con las redes neuronales, eh pues prácticamente permitan eh eh establecer interfaces entre el cerebro humano
y pues los microchips y y las propias redes neuronales para agilizar ciertos procesos a una Velocidad realmente impresionante. Algunos ejemplos eh que hemos visto por ahí son eh con el que tiene por aquí un chip para este para que las personas puedan, me parece, escuchar música y bueno, una serie de de cosas que que de iniciativas muy interesantes que se están trabajando actualmente. Eh, de ahí necesitamos que la computación evolutiva siga evolucionando, la redundancia. Eh, Tenemos muchas soluciones como Hm. por ejemplo, el análisis de algunos insectos o de algunas aves o de algunos eh de
algunos animales, el comportamiento para extrapolarlo a situaciones reales y ver la manera en la cual podemos eh eh obtener soluciones basándonos en el análisis de la naturaleza. Hm. Después, eh, bueno, los LLMs que se que surgen a partir del procesamiento de lenguaje natural, el cual ya me parece Que vieron ese tema y eh y son muy importantes. ¿Por qué? Pues porque de ahí, por ejemplo, tenemos chatt y todas estas herramientas de generativas de de texto que que aunque se basan en estadística, pero son de gran utilidad para nosotros. También la IA multisensorial, necesitamos que se
que se interpreten eh múltiples tipos de entradas de datos, porque eso es un reto, el hecho de que puedas adquirir información sobre eh Sobre sensores, pero también sobre voz, también sobre video, también sobre eh el clima, eh una serie de de una serie de h de elementos que integrados nos permitan especializarnos en en dar soluciones a través de múltiples fuentes eh multisensor sensorial, como se menciona. Y luego también tenemos la eh programación generada por por IA, ¿no? Ya muchos de ustedes utilizan algunas herramientas por ahí de este para generar sus Códigos, aquellos que se dedican
a al área de de programación y y e informática. Eh, dicho esto, les, como les mencioné, sería interesante saber a qué se dedican eh varios de ustedes para eh para que en un momento dado pues piensen cómo podrían elaborar un modelito para su para su este para su negocio, para ustedes mismos, para su comunidad. Eh, bien. Entonces, ¿qué significa cada uno? tenemos una clasificación de Inteligencia artificial. Bien, tenemos máquinas que simulan el comportamiento y el razonamiento eh el razonamiento de los humanos. Sí. Eh, vuelvo a reiterar, Alexa Siri Devil. Después tenemos lo que compete a
este a este a este curso, a esta sesión que es el aprendizaje, el aprendizaje máquina, el aprendizaje automático, que sería la capacidad de las computadoras para aprender por sí mismas a partir de su Experiencia, a partir de datos que se le proporcionan. Esa experiencia se basa en fuentes de datos. Esas fuentes de datos pueden ser tan diversas como uno quiera, eh, y como uno necesite. El uso más complejo, pues lo se utiliza en Deep Learning, donde ya requiere de imágenes y videos, ¿no? Incluso streamings. Por ejemplo, eh pues tenemos el análisis predictivo de vehículos autónomos,
personalización de contenidos De acuerdo con patrones de de comportamiento. Vamos a profundizar un poquito más adelante acerca de estos temas. Y finalmente, deep learning. Ya hablamos de redes neuronales, convolucionales y cuestiones que nos permiten clasificar y relacionar grandes volúmenes de información imitando las redes neuronales, ¿no? Los chatbots, eh las opciones que son avanzadas de traducción, el reconocimiento del Dialecto, hay algunas iniciativas en para la traducción de maya, de nawal. Entonces, eh ese es un es un avance importante. Y ahora tenemos unas ramas eh que que esto eh nos va a ayudar y nos va a
ayudar a nos va a ayudar a a a entender un poquito más el por qué les dije que la inteligencia artificial no es nueva, aunque así lo parezca para muchos. eh tiene un boom importante y no solo es Aprendizaje máquina, no solo es clasificación, no solo es una computadora que te dice que sin este que te que te da alternativas de solución o recomendaciones, sino que por ejemplo hay sistemas basados en conocimiento. ¿Sí? Entonces tenemos sistemas expertos dedicados a una tarea en específica para detectar alguna enfermedad, cáncer, puede ser. eh etcétera, agentes inteligentes, los cuales
ya no requieren de Intervención humana y pues con base en ciertas eh entradas de datos, estos proporcionan este respuestas, soluciones, sistemas vinculados en los cuales si hay ciertas compatibilidades, ellos mismos ellos mismos por sí mismos se se este se vinculan y se comparten información sin la necesidad de intervención humana. sistemas basados en casos, sistemas basados de de razonamiento basados en casos, es decir, con base en una Experiencia, yo puedo ofrecer una alternativa de solución y entonces entra en muchos dominios. Tenemos por otro lado la visión por computadora, la cual es muy apasionante. mucha gente le
gusta eh eh los temas de visión por computadora, restauración de imágenes, eh quienes hayan tenido la oportunidad de ir a algún museo algo eh que no nos permiten sacar flash y esto es porque justamente eh esos pequeñas partículas de lúmenes y Eso pueden dañar y son luego cuadros muy antiguos eh ciertos rasgos y entonces ellos hacen unas reproducciones para restaurar muy muy con software muy potente para eh para conservar esas obras invaluables, algunas de ellas, reconstrucción de escenas o también como últimamente está que no tienes idea de cómo vas a eh a remodelar una habitación
con la IA lo puedes hacer y tomas la fotografía y te hace muchas recomendaciones de cómo de Cómo poder hacerlo, ¿no? o este o incluso de cómo era antes de un desastre natural para poder hacer, por ejemplo, gemelos digitales y poder identificar qué es rescatable, qué no de si se cayó un puente, si se desbordó un río, n cosas. Análisis de de movimiento. Eh, nosotros hemos trabajado con con análisis de movimiento corporal para identificar caídas. Ese es otro de los ejemplos y reconocimiento, ¿no? Eh, reconocimiento También es otra parte de la visión por computadora. Hm.
tenemos la robótica, la cual es también muy interesante. Aquí siempre hay un dilema que es con los de mecatrónica, con los de robótica como tal, con los de electrónica y esto y pues el dilema es la inteligencia artificial la tienen los robots, la tiene el software, pues yo soy de software, soy doctor en Inteligencia artificial y les puedo decir que la parte inteligente a la parte electrónica se la da el software. ¿Sí? Entonces, eh pero nosotros sin el hardware no podríamos o sin los robots no tendríamos donde hacer que el robot vea, que el robot
toque, que el robot escale, el climbing, que el robot escale, entonces que mida las alturas, todo es de programación, entonces la altura de unos escalones que que haga estimaciones. Entonces hay algunas cosas Que que se complementan, ¿sí? Pero al final robóticas, por eso es parte de la inteligencia artificial. Eh eh eh censados, locomo actuación y hay muchas más cosas en cuanto a robótica. procesamiento de lenguaje natural, tenemos texto, tenemos speech, speech recognition, que para que nosotros eh de alguna manera podamos eh eh hablar hablar y y sea reconocida nuestra voz. Eh, entonces ahí hay cuestiones
éticas, Cabe recalcar, en las que necesitan, es necesario pues cuidar, ¿no? Cuidar que que nuestra voz no sea utilizada para para otros para fines que no son que no sean permitidos. eh planeación planeación de este planeación la planeación automatizada este esa esos estos calendarios, estas agendas, estos correos electrónicos que te detectan de manera inmediata, no solo el spam, sino aquellos correos para clasificar cuáles son los más Importantes, para agruparlos eh en tu agenda, recomendaciones sobre tus patrones. de comportamiento de de notas. Entonces, todo esto también es muy muy interesante. La optimización también este algoritmos genéticos,
algoritmos de evolución, evolución diferencial, entre otros. Como pueden ver, hay mucho, ¿no? Tenemos eh estoy dejando al final machine learning, pero eh componentes de la inteligencia artificial, pues están los este representación del Conocimiento, la percepción, las acciones, la comunicación, la planeación, el aprendizaje. Esos son sus componentes. Tenemos los tipos de inteligencia artificial y como ya les mencioné está la superinteligencia, está la general y este y la la débil, ¿no? Y bueno, por aquí ya hablando de de aprendizaje automático, pues tenemos aprendizaje supervisado, aprendizaje no supervisado, aprendizaje por refuerzo y entra una categoría especial que es
Aprendizaje profundo. El aprendizaje profundo no es algo que se vaya tratar en esta sesión ni en la siguiente, pero en si ustedes gustan a través del foro yo les puedo compartir información sin ningún sin ningún problema. ¿Sí? Entonces, con esto ya tenemos las ramas de inteligencia artificial para que vean cuán extenso es, qué significa lo que necesitamos que maduren para poder dar saltos entre débil, estrecha a a inteligencia Artificial fuerte o incluso inteligencia artificial. Y no estamos hablando de que va a suceder, aunque hay pasos afiecantados, no estamos hablando de algo que va a suceder
en un año, en dos años. En realidad todo esto va creciendo, va creciendo y no sabemos hasta dónde va a parar, pero es muy importante que sepan sobre inteligencia artificial, ¿vale? Ah, y bien, creo que es suficiente repaso y Complemento de de por hoy, por hoy, porque mañana les voy a dar otra otra información, pero me gustaría que dediquemos tiempo para comentar en el foro. y podemos destinar unos 3 5 minutos donde si por favor pueden mencionar con qué sistemas o medios o recursos de inteligencia artificial interactúan a diario, seguramente con Alexa, pero posiblemente otros
nos sorprendan y y y mencionen otras cosas. Entonces, sería sería bueno saberlo para Que tengan identificado que están trabajando con IA débil actualmente. Y otra cosa también, si realizan un planteamiento muy breve de en qué podría ser aplicada una fuerte o una supería, no se limiten a que a que es hipotético, a que es futurista, porque de ahí surgen las grandes ideas y yo no sé si en un futuro ustedes puedan eh crear algo que puedan generar algo que que sea eh de utilidad. Sí. Entonces, eh pues si si participan en Esta en esta actividad
eh va a ser bastante este bastante enriquecedora para para esta para este para esta sesión. Recuerden que su talento de ingenio eh no tiene límites. O sea, tal ingenio no tienen límites. Quizá como les dije no existe la tecnología aún para que lo que plantean, pero no sabemos en un futuro. Sí. Entonces, eh yo por aquí tengo un una ventanita para cargar el foro y ver algunas de sus De sus algunos de sus comentarios en el foro. Eh, nada más tengo que estar recargando y pues, ¿qué les parece si destinamos 5 minutos para que hagan
su eh esta actividad? los sistemas o medios con los que interactúan de IA Devil diariamente y un planteamiento de en qué lo aplicarían. En YouTube tengo eh reportados 2412 usuarios conectados. Eso quiere decir que es posible que tengamos varias Varias participaciones en el foro. Bueno, es lo que esperaría o me gustaría. en lo que hacen su actividad. Eh, no olviden eh registrar su asistencia aquellos que se están incorporando. No olviden registrar su asistencia en la descripción del curso y también el examen, la evaluación. Sí, la que la evaluación será el sábado 17 de enero de
a partir de las 0 horas hasta las 23:59, ¿de acuerdo? Para que no se les olvide y este esfuerzo que están haciendo pues valga valga la pena, ¿no? A través de su de su evaluación. ¿Qué? 2 minutos más. 2 minutos más y eh y ya inicio con el con el eh ahí tienen el ahí tienen el QR. Eh, aprovechando que aprovechando que que van a que están realizando su su actividad, eh tienen el QR para el pase de de lista. No olviden, No olviden realizarlo. Esto es muy importante. Recuerden que todas las clases sincrónicas son
regidas eh por el horario de la Ciudad de México. Las evaluaciones también así lo son. No olviden también que pues bueno, es indispensable que ingresen su nombre su nombre completo a través del enlace de asistencia a través de este QR. El folio solicitado para él, pues pues es opcional, lo pueden dejar en blanco. Ah, las inquietudes a través del foro, dudas, comentarios, observaciones, todo a través del foro, ya que no se manejan grupos de ninguna índole, no hay cursos, no hay cursos, disculpen, no hay eh no hay grupos para este propedéutico como tal. Bueno, en
todos creo en los que estén inscritos. Ah. Cuando hagan su evaluación van a tener dos intentos para realizarla. Sí. Eh, Reitero, 17 de enero para que no se les pase en un horario de de 0 a 23 horas. El material se encuentra disponible en el MOC de TNM virtual. pueden descargar las lecturas, pueden acceder a las a las presentaciones y sobre estas van a eh van a bueno, se van a realizar las preguntas y que se van a encontrar en su examen. Así que pues más la información que eh pues su servidor y todo el
equipo de inteligencia artificial eh le estamos les estamos Proporcionando. Por eso es que les comentaba que que sería importante que tengan eh papel, papel y lápiz. Bien, eh me tarda un poquito en cargar. Okay, ya está, pero voy a voy a a dar inicio a este a presentar eh a la a la siguiente siguiente presentación. Y bueno, eh ya vimos un repaso sobre inteligencia Artificial, ya vimos sus ramas, ya vimos en dónde estamos actualmente, así que Ya vimos en en dónde nos encontramos actualmente. Así que pues ahora vamos a ver los eh los conceptos fundamentales
del aprendizaje automático. Pues el objetivo que se busca es que al final de este tema ustedes tengan la capacidad de comprender qué es el aprendizaje automático, qué es lo que se Busca, cuáles son los componentes clave, el ciclo típico de desarrollo y de desarrollo de un modelo de aprendizaje automático. Eh, y qué técnicas ayudan a mejorar el desempeño. por ejemplo, la división de datos, la ingeniería de características, la reducción de dimensionalidad y métodos de conjunto. ¿Sí? Entonces, eh es es eh eh va a ser muy interesante eh va a ser muy interesante este tema y
pues está por aquí. Muy bien. Eh, ¿qué es eh aprendizaje automático o machine learning? Bueno, permítanme. Hm. Antes de dar respuesta como tal a esta pregunta, quisiera yo saber, quisiera que lo planteemos de la siguiente manera. ¿Cómo logramos que una computadora aprenda a partir de datos para hacer predicciones, tomar decisiones sin programar una regla distinta para cada uno de los casos? Sí. Eh, que aquellos que sigan en el foro si si pueden plantear una respuesta, eh, sería sería bastante estaría bastante bien. Si no, pues lo pueden lo pueden lo pueden anotar, ¿sí? el cómo vamos
a hacer que una computadora aprenda a partir de datos para hacer predicciones o tomas de decisiones sin programar reglas distintas para cada situación o para cada caso. Vamos a pensar en algo cotidiano. Vamos a pensar en eh una plataforma streaming, la que quieran, la que quieran que utilizan para ver películas o para para ver películas, eh la que ustedes quieran. Si una plataforma streaming les recomienda una serie, eh no es porque alguien programó la regla, una regla por regla, es decir, no es porque alguien programó, si si vio muchas de de suspenso, va a ver,
le voy a recomendar películas de suspenso. Sí, Bueno, te pueden recomendar películas de suspenso, pero pueden ser poco de de poco interés. En realidad, eh si nosotros vemos una película y de repente la dejamos de ver, h es porque ya no nos interesó. Entonces ahí hay algo que aprender. El modelo tiene que aprender. ¿Por qué? Pues a lo mejor y ese tipo de de película, aunque sea del género de suspenso, no fue de las de las del gusto de de la persona que está viendo, ¿no? Entonces, Esto es no es porque alguien programó regla por
regla, es decir, si te gusta X, entonces muéstrale Y. Sí, en realidad no es tan así tan simple, ¿sí? Sino que el sistema aprende patrones a partir de datos. Es decir, nosotros estamos viendo una película, ¿qué película viste? ¿Cuánto tiempo la viste? ¿La viste más de una vez cuando abandonaste alguna película o qué es lo que abandonaste? Es decir, no, pues de plano a mí no me gustó y no la Pude terminar de ver. Como les dije, que es lo que repites. Y también eh con esta información e incluso más se forman los perfiles y
se predice qué podrías querer después. Por eso es que tenemos el me te podría gustar tal cosa, tal película. Sí. Fuerces. Espero haber sido claro con con con este con esta situación cotidiana que tenemos. Eso en esencia es aprendizaje automático. Lograr que la computadora identifique patrones en Datos y nos haga las predicciones sin que se programe de manera explícita cada caso posible. Sí, yo ya aprendí y ya puedo predecir qué es lo que te gustó con base en el género, el tiempo que le estuviste viendo, la rep número de repetid veces que le estuviste tal,
incluso creo que ya algunos traen que si te gustó, que si no es para ti y traen ahí este dedito arriba, dedito abajo y todo eso, ¿no? Entonces eso eh eh eso es aprendizaje automático. Por lo tanto, y Dando respuesta a al que es el aprendizaje nos automático nos va a permitir o permite más bien que las computadoras a partir de datos hagan predicciones sin sin programar explícitamente cada caso. Lo que significa que en lugar de escribir miles o cientos de miles de reglas del tipo si pasa esto, entonces hago esto, lo que le damos
son ejemplos. lo que le damos son eh ejemplos con ciertos parámetros, con ciertos valores Y de esta manera aprende ciertas regularidades, ¿no? Es decir, con regularidad ve estos géneros, con regularidad evita estos, con en este horario ve más ve más películas o series entre entre otros. Eh, bien, dicho esto, eh tenemos un objetivo central para desarrollar modelos de aprendizaje automático y esto es que generalicen, que funcionen bien con datos nuevos, con datos no vistos y que no solo repitan lo Que ya vieron como si fuera de memoria. Eso es muy importante. Los modelos de aprendizaje
automático no deben memorizar, deben aprender y tener cierto nivel de resiliencia. Sí. Es decir, yo ya el el modelo ya aprendió cómo es el comporte del usuario, qué películas ve, eh que en qué horario lo ve, eh cuáles son las que no eh y le hago las recomendaciones, Pero eh posiblemente si hay nuevas películas, hay nuevos cambios, se las voy a recomendar y si el usuario eh hace algún cambio y de repente lo que no le gustaba sí le gustaba el el modelo o o el sistema de inteligencia artificial debe tener la capacidad de aprender
que tiene un gusto nuevo, debe resistir y recuperarse rápidamente a cambios, a condiciones inesperadas, en algunos casos a interrupciones, a Fallas que son del mundo real. Eso es lo que hace que un sistema de de aprendizaje automático pues sea eh resiliente. Sí, de esta manera, pues lo que hace es que el sistema basado en inteligencia artificial propiamente eh aprendizaje automático mantenga la continuidad, la confianza del usuario e incluso eh lo ayude a enfrentar adversidades o ciertas frustraciones dependiendo del dominio. Sí. Pero este básicamente es eh es eso, ¿sí? que que pueda continuar pese a las
pese a las adversidades. Vamos a ver, por ejemplo, eh supongamos que yo tengo muchos correos marcados como spam y como no spam. Mi correo, mi bandeja va a aprender. Mi bandeja que con que incluye inteligencia artificial va o debe aprender qué señales suelen aparecer en cada grupo y luego clasificar correos nuevos. Sí. Entonces, ya me me ahorra un trabajo. Eh, una idea clave que les puedo eh compartir es cuando diseñan o cuando trabajan con con modelos de aprendizaje automático es no queremos que el modelo sea bueno con el pasado, porque del pasado va a aprender,
es decir, de la experiencia, de los datos, de la de la información, de las fuentes de información que se encuentran en en el pasado. de ahí va a aprender. No queremos que sea bueno con el pasado, queremos que sea bueno con el futuro con Base en la información del pasado. Esa es una idea clave que les puede ayudar. ¿Por qué? Pues porque eh como les dije hm voy a predecir el gusto, pero voy a primero analizar qué hizo antes. Voy a eh dicho esta eh este este concepto eh me gustaría preguntarles y a través del
foro si si e dónde han visto predicciones en su vida Diaria. Sí. Este, ¿dónde dónde dónde han visto predicciones? Aparte de de los de streaming y de música, eh, no sé, algunas recomendaciones, mapas, filtros de correo, compras. Sería interesante eh saber que que en el foro que en el foro nos nos compartieran eh dónde han dónde han visto predicciones que que incluso lo sorprendan o por aquello del de la brecha generacional eh Que hasta asusten, ¿no? En el caso de nuestros abuelos o de nuestros papás que oye, ¿cómo es que sabe que estoy aquí? cómo
es que aquí sabe que que quiero que me gustó esto, cómo es que me recomiendó estos productos, incluso cómo es que sabe que necesito algo que yo no sabía que necesitaba, ¿no? Entonces hay algunas algunas cosas muy interesantes eh que que podría Entonces si si en el foro Pueden manifestar algo algo de eso, pues estaría estaría genial. Bueno, eh para continuar h dentro de la definición objetivos. Eh, vamos a formalizar la idea porque nosotros tenemos el el qué es, ¿no? Entonces, el aprendizaje automático se basa en procesar datos y usar algoritmos matemáticos para descubrir relaciones
complejas entre variables. Esa es una formalidad para darle una definición. Sí. Eh, es importante que sepan, bueno, Pues matemáticas y estadística y y cuestiones eh que nos enseñan, ¿no?, en las ingenierías. El objetivo central del aprendizaje automático no es memorizar ejemplos, sino construir modelos que generalicen, que funcionen en datos no vistos y que puedan aplicar lo aprendido en situaciones nuevas con un cierto nivel de resiliencia. Sale. Entonces, enfaticemos eh enfaticemos una Una frase que que yo considero es es bastante eh eh útil para cuando estamos estudiando. Si el modelo solo repite o los modelos o
el aprendizaje automático únicamente repite lo que lo que vio, no aprendió, memorizó, entonces no va a ser resiliente porque cuando haya un cambio no va a funcionar. Lo único que hizo fue almacenar información, pero no aprendió, memorizó. ¿Sí? Entonces, esto tiene una estrecha relación con la importancia de evaluar y separar correctamente los datos, que es un tema que vamos a ver un poquito más adelante. Bueno, espero que hayan puesto eh su eh Espero que hayan que hayan puesto algunas de las predicciones con las que han con las que han vivido. Y voy a voy a
seguir con la siguiente. Bien, la eh el aprendizaje automático, los modelos de aprendizaje automático eh tienen ciertos componentes, tienen componentes edifenciales, son básicamente eh tres, ¿no? La representación, la evaluación y la optimización. Vamos a hablar de cada uno de ellos para ah que quede claro. Casi cualquier proyecto o de manera general cualquier proyecto de aprendizaje automático tendrá estos elementos: representación, evaluación y Optimización. ¿Sí? Entonces, ¿qué pasa con con cuando voy a hacer un un modelito para para que aprenda algo y me prediga algo? Eh, voy a la voy a utilizar una eh la primera parte
que es representación y es voy a definir qué parte del conocimiento va a capturar el modelo y cómo se va a estructurar internamente, porque no voy a no voy a agarrar todo. Eh, hay dominios muy amplios, la Medicina, la salud, las finanzas, eh la agricultura, eh son tan vastos, tan tan diversas las fuentes incluso de información. que que no que a veces nos nos debemos centrar en algo muy particular. Entonces, ¿qué parte de todo ese conocimiento es el que deseo capturar para que mi modelo aprenda y ya después cómo lo voy a estructurar internamente para
que ese ese aprendizaje se vuelva una predicción o una clasificación? Una vez que yo ya tengo definido el conocimiento y estructurada la este el conocimiento eh del dominio en el que voy a trabajar, lo voy a evaluar. Es decir, aquí entra la segunda parte, la evaluación. ¿Cómo voy a diferenciar buenos modelos y malos modelos con métricas? Hm. Perdón. Eh, ah, sí, la evaluación es la eh eh cómo Ya que tengo, les decía yo, ya que tengo identificados eh identificado mi mi estructura interna de lo que voy a a a capturar como modelo, eh cómo voy
a diferenciar, es decir, yo puedo tener varias versiones del del modelo y a través de métricas cuantificables eh las cuales bueno, espero mañana abordar ar de manera eh eh de manera rápida, pero pero sustanciosa, digamos. Eh eh qué modelos Van a ser los buenos y cuáles van a ser los que no me sirven. Sí. Entonces, me deshecho aquellos que no me sirvan y ya. Una vez que ya identifiqué y que evalué el modelo que me es de útil para el dominio en el cual yo quiero eh eh pues el cual el dominio en el cual
yo quiero generar una una predicción, una recomendación, una clasificación, entonces hago una optimización para que se ajuste lo más fino, lo más fino a mi necesidad. Entonces hago el ajuste de Parámetros para minimizar errores y entonces encontrar ya el modelo que se adecúa, que se adecúa perfectamente a mi necesidad. Sí, espero eh haber sido claro. Eh, si hacemos una analogía menos formal o menos técnica de SIM, podemos decir que, bueno, la representación es como una herramienta, como un tipo de herramienta, es decir, tenemos no es lo mismo un mapa, una Tabla o una receta, ya
que cada formato permite expresar cosas distintas, ¿no? Mientras que un mapa es para ubicarme o localizar, una tabla para representar datos tabulares y una receta pues que me va a decir este cómo cocinar algo. Son informaciones distintas sobre una de ellas debo tener. Eso sería la representación. Ya después, ¿cómo evaluamos? Bueno, pues si no hay ningún criterio, no sabemos si mejoramos o empeoramos, ¿no? En el caso de las Recetas, si no le pongo más parámetros de sal, no voy a saber si va a tener o no mejor sabor. En el caso de un mapa, si
no le indico la latitud y la longitud, pues no me va a marcar más allá, ¿no? De de donde estoy. Y bueno, una vez hecho esto, pues optimizar es cómo lo voy a afinar. En el en el caso de una receta, pues hacer pruebas, ajustas y vuelves a probar. ¿Sí? Entonces, antes de irnos eh a un a un breve descanso de 5 minutos, Eh quisiera yo eh pues hacer una una pequeña dinámica eh en el foro. Hm pues eh imagínense que tenemos dos modelos. Uno acierta mucho, un modelo acierta mucho y otro modelo acierta acierta
poco. Es decir, eh un modelo con ejemplos conocidos y otro modelo falla en nuevos. Reitero, Un modelo acierta mucho en ejemplos conocidos, pero falla en nuevos y otro acierta un poco menos en los conocidos, pero se mantienen nuevos. ¿Cuál es el que les conviene? Aquí es donde donde debemos pensar en generalizar. Sí. Y bueno, otra cosa, pues como ya les había dicho, si pueden indicar el área del conocimiento a la que se dedican. de todas las personas que están Conectadas, igual todos son ingenieros, pero podrían, como ya les dije, eh establecer a qué área del
conocimiento podrían aplicar un modelo de aprendizaje automático. Sí. Entonces, vuelvo a repetir, tenemos o imagínense que tenemos dos modelos. El primero acierta mucho en ejemplos conocidos, pero falla en nuevos. Otro acierta poco menos en los conocidos, Pero se mantiene bien en los nuevos. Entonces, ¿cuál de los dos modelos convendría? Eh, vamos a a vamos a a este a tomarnos un receso de 5 minutos para pues también si que si gustan ir al foro y contestar eh eh estas preguntas. y nos vemos en un momento. Recuerden su pase de su pase de lista también. Recuerden su
pase de lista en en el QR o en la descripción del del Video. Sí. Y pues reitero nuevamente las clases, estas clases sincrónicas y las evaluaciones son regidas en el horario de la Ciudad de México. Hm. Es indispensable que registren su nombre completo ahorita que están haciendo su pase de lista, la cual es muy muy importante. Ah, pues todas las inquietudes, por ejemplo, la actividad o o esto en el foro, pues Que lo hagan. Bueno, esta actividad y todas las hagan a través del foro, ya que no hay grupos de ninguna índole. La comunicación es
a través del foro y pues lo que nosotros aquí compartimos. Ah, eh, otra cosa, un recordatorio es para su evaluación el próximo sábado 17 de enero de de cero a 23:59 horas y para que lo hagan, para que hagan su su evaluación. confío en que les irá bien. Y pues bueno, ya a título personal, pues hagan algunas anotaciones o algo para Que de manera abstracta tengan notas propias, lo cual enriquece mucho el aprendizaje. Bien, retomemos lo que en lo que estábamos en cuanto a componentes esenciales. Sí. Eh, recuerden algo muy importante, no olvidar lo siguiente.
Cualquier sistema de aprendizaje automático, por muy sofisticado que parezca, se sostiene de tres elementos que siempre van a Aparecer: la representación, la evaluación y la optimización. ¿Sí? Es decir, eh la representación es la forma interna del conocimiento. Este va a definir qué puede aprender el modelo y cómo se estructura. Por ejemplo, una regla, un árbol, una ecuación, una red neuronal. Después de esto, de la representación de la información ya estructurada, viene la evaluación. Necesitamos una manera cuantificable de distinguir los modelos Buenos de los malos a través de ciertas métricas para que finalmente una vez que
está identificado el modelo, el modelo eh el modelo que más nos conviene eh entonces lo voy a optimizar. Sí, ajusto ciertos parámetros para minimizar errores, encontrar un modelo bueno dentro del espacio de posibilidades que me que me permite la representación. Sí. Entonces, eh con eso ya ya cubrimos una buena parte de de de cómo se inicia un modelo de de Inteligencia artificial, este propiamente aprendizaje automático. Ahora, todos los software, todos los sistemas tienen un ciclo de vida y tienen un ciclo de desarrollo. Eh, bien, en cuanto al al ciclo de desarrollo, h tenemos la recopilación
de datos, la división de los datos, el entrenamiento, la sintonización y las predicciones. ¿Sí? Entonces, vamos a hablar sobre Ellos para pues para saber cómo cómo lo vamos a cómo se va a trabajar, cómo se hace un un desarrollo de de este tipo. Bien. Ah, en la práctica, ya en la práctica, cuando ustedes tienen un modelo, van a diseñar, bueno, diseñan y luego van a implementar un modelo de aprendizaje máquina, eh no es una sola ejecución, es un ciclo iterativo e incremental. Sí, normalmente vas aplicando mejoras, mejoras, mejoras hasta obtener el el que Te sirve
y aún así hay posibilidades en las que tengas que hacer un reentrenamiento para alcanzar todavía posibles cambios, ¿no? Esa resiliencia de la que hablaba de los modelos de de inteligencia artificial, de prisión automático. Entonces, para nuevos enfrentamientos o nuevas variantes, un ejemplo muy sencillo de esto es eh el dengue. tú puedes tener un modelo para estas enfermedades de vectores transmisibles y Decir, "Ah, pues mi modelo eh está para esto." Pero de repente cambiaron las condiciones climatológicas, hay mayor humedad y se dan las condiciones para que este pase a sica y mi modelo ya no me
va a servir. necesito reentrenarlo para que tenga las capacidades de detectar tanto dengue como sica y luego chicunguya y entonces y así varios bosquitos que van evolucionando y entonces nuestro modelo se va quedando, se va quedando. Entonces Eh no funciona así, tienen que estar eh entrenando, entrenando constantemente conforme va pasando el tiempo, nuevas versiones para atender nuevas necesidades. Dicho esto, eh bueno, primero lo que hacemos es recopilar datos. Sí, dentro de la recopilación de datos eso. ¿Por qué? Porque el del desempeño depende fuertemente de la calidad y la relevancia de esos datos. Ojo, la la
calidad de los datos h debe estar los Datos deben estar bien estructurados, deben ser válidos, deben ser validados por especialistas, por decir, no, depende del contexto. Yo no voy a bajar informedica. No debe ser de de pues no sé de de instituciones de salud nacionales o reconocidas cuyos datos sean libres. Eh, espero explicarme. Sí. Entonces, primero se recopilan datos. Sí. Las fuentes de datos pueden ser tan vastas. Por ejemplo, Ay, se me viene me viene la a la mente. Aquí yo tengo un dispositivo, este de aquí, no si lo ven. Este me monitoriza la frecuencia
cardíaca y la presión y todo. Sí, si me ponían nervioso ahorita dándoles la clase. Entonces lo que hace es manda los datos a mi móvil. Y yo a través de mi móvil lo que hago es pues me los exporto a una hoja de Excel, a una hoja tabular y esa y esa Hojita lo que lo que hace es eh pues tiene tiene mi mis datos. Esta esta señal es fotopletismográfica, así se llama. Sí, es es el el foquito que prende esto, cruza por la avenita, tu tu rebota eh y manda la señal y pues ya
la exporto. Sale. Entonces, esta es una fuente de información. Yo a partir de aquí eh con base si ahorita me baja la presión, si me siento mal o algo, va a quedar Registrado. Y esos datos me sirven para un modelo, porque yo puedo utilizarlos para predecir una posible una de posible descompensación, una posible baja de de de presión o subida de presión, eh no sé, n n cosas, ¿no? Incluso el sueño también. Entonces uno puede hacer predicciones. Esta es una fuente de información. Otra fuente de información son a través de sensores, el clima, eh eh
flujos de ríos, ruidos del Motor. También el ruido es una fuente de información. Voy a quitar esto, eh, no sé, pueden tener muchas, es decir, es heterogénea y su modelo puede recibir de todas o de una sola, pero siempre y cuando sean validadas. nosotros como expertos o como ingenieros, como especialistas en inteligencia artificial, este nosotros lo que lo que sí hacemos o lo que podem nos Especializamos en esto, en IA, pero yo no soy un médico, ¿no? Entonces, yo no puedo ni ni me ni me automedico ni me autodiagnostico, voy con un especialista. Entonces, hay
que tener en cuenta eso. Cuando van a antes de iniciar con el ciclo de desarrollo deben pensar una vinculación, deben pensar una alianza para decir, voy a voy a hacer mi modelo de este sobre presión arterial, pero debo ir con un nefrólogo o debo hacer una vinculación con una entidad Médica la cual me valide los datos, me proporcione datos este que me puedan servir o que me sean de utilidad para mi modelo, porque si no voy a tener información que no que no me sirve sirve. Sí. Entonces, eso es muy importante o que ya al
menos si no me dan los datos por cuestiones de privacidad que me que me validen mis resultados para que de alguna manera e este esté convencido de que de que mi trabajo o mi esfuerzo al hacer un Sistema de aprendizaje automático valió la pena. ¿Por qué? Pues porque un experto en el dominio en el que estoy trabajando me lo validó. ¿Sí? Entonces, ya que se recopilaron los datos, se deben dividir, debemos dividirlos en entrenamiento, validación y prueba. ¿Sí? ¿Para qué? Para que, bueno, de ese de ese 100% de datos que tengo de señal fotopletismográfica en
en el ejemplito que les acabo de dar, eh, de hecho, aquí está funcionando, eh, toda Esa información la tengo que dividir. Sí. ¿Para qué? Bueno, en la práctica hay una sugerencia, eh, la división típica es del 100% de datos, el 70% lo voy a utilizar para entrenar el modelo. Después el 15% lo voy a utilizar para validar y el otro 15% lo voy a utilizar para pruebas. Hay algunos casos donde utilizan 70 30, es decir, el 70% lo utilizan para entrenar y el 30% lo utilizan para Validar y ya después buscan datos del mundo real,
este, para poner a prueba el modelo y también es es válido, ya depende de de de cómo lo quieren llevar, pero lo típico es 70 15 y ya luego este toma datos del mundo real. La idea aquí es clara, eh, el entrenamiento va a enseñar, la validación va a afinar y la prueba va a examinar. Sí, reitero, aquí es primero entreno para enseñar, Valido para para afinar los detalles y luego hago las pruebas para examinar, para ver si me va los resultados correctamente. Con base eh con esa base eh con esto que les acabo de
mencionar, se entrena un algoritmo para que aprenda patrones. Sí. En el caso de esto de la fotopelitismografía que les mencionaba, aprende quizá a qué hora o en qué momento subí más escaleras, en qué momento mi Corazón latió más rápido, en qué momento no, en qué momento estornudé. Pues es decir, bueno, no es que sepa que estornudez, sino que cada vez que estornudamos se detiene un poquito el corazón y todo eso. Entonces después de una señal que va con picos, quizá hay una línea porque es el momento nanosegundo en el que se detuvo por mi estornudo
y luego continuó. Entonces todo eso es información. Entonces va aprendiendo ciertos Patrones. Luego eh se sintonizan los hiperparámetros, es decir, que estas son los hiperparámetros son configuraciones externas y que se ajustan a se ajustan al para controlar el proceso del entrenamiento en en en aprendizaje automático. Es algo ya bastante técnico y ya bueno, esto es ya en la en la validación y al final pues se generan las predicciones con datos nuevos. Algunos ejemplos de hiperparámetros, por ejemplo, la tasa de aprendizaje, qué tan Rápido aprende, el número de lote, cuántos datos se procesan a la vez,
cuántas señales se se analizan, número de épicas, cuántas veces se ve todo el dataset, porque bueno, en aprendizaje profundo no son ciclos, son épocas. Entonces, así lo van a poder ver en sus ideas de desarrollo. Y bueno, por ejemplo, también la profundidad. En el caso de los árboles, la decisión o los árboles aleatorios, el número de capas y neuronas que en las redes Neuronales, también la profundidad en cómo eh qué tanto qué tanto voy sumergiéndome para obtener la información dentro de ciertas capas de de datos, ¿no? Eh, a manera de resumen para el para el
desarrollo de un de un modelo automático es realizo una una recopilación, o sea, primero reúno los datos. Si los datos están incompletos o sesgados, el resultado también lo estará. Necesitamos completitud. Después se hace la división, les reitero, 70 para validar, 15 para prueba, 15 para evaluar o 70 30 y y ya después este los otros datos que falten serían para probar que vendría del mundo real, ¿vale? En el entrenamiento, eh, pues ya el modelo aprende ciertos patrones con los datos de entrenamiento, con la sintonización se hacen los ajustes, las decisiones del modelo utilizando la Validación
y pues finalmente es pues ya se hacen las predicciones con los datos nuevos, ¿no? Se estiman, se hacen predicciones, se hacen clasificaciones, entre otras. Ah, siempre tengan en consideración lo que les voy a comentar. Si eh ahorita que que van a tener un examen el bueno, ahora que tendrán una evaluación el el sábado 17, eh imagínense que se aprenden, Se memorizan todas las las preguntas y lo responden y pues qué bueno y después vuelven a presentarlo y pues ya les tienen memorizado y lo van a probar y el momento en el que les cambian una
pregunta van a tener problemas. Así el aprendizaje automático. Sí. Si ustedes se evalúan con lo mismo que aprendieron, están evaluándose o están examinándose con el mismo examen resuelto, entonces no son resilientes. Por eso es que más vale comprensión que Memorización. Eso de la división 70 1515 o 7030 no es una ley universal, eso no es algo que esté escrito, pero la literatura pues sí es una sugerencia. Eh, muchos modelos así se manejan. Hm. Y bien, tomando el tema de de ingeniería de características como tal, bueno, pues eh es como preparar ingredientes antes de cocinar. la
ingeniería de características es este tomarlo aquellos Elementos que que me son útiles para mi modelo. Por ejemplo, en esto de de que les decía yo del del que significaba yo de la fotoclifismografía con el dispositivo, eh datos útiles o características útiles puede ser el eh este la la señal, los picos, el tiempo los tiempos, los tiempos en los que estoy más activo, en los tiempos en los que estoy más inactivo. de la morfología de la señal ya a un Nivel un poco más electrónico y de diseño, análisis de señales, la morfología de la señal, este,
no sé, identificación de cuándo sub escalores, escaleras, cuando no, a qué hora dormí, todo eso, incluso cuando comí, por aquello de que la digestión hace que se nos disminuya un poquito la el flujo sanguíneo también podría ser útil, cosas inútiles. Ah. Pues no sé si si voy manejando, si Hm no sé la verdad si me agaché o si escribí algo, o sea, cosas que en realidad no son tan relevantes para entrenar un modelo, da da lo mismo. Entonces esos datos o esa información no es de utilidad para el modelo. Entonces eso es donde hay que
empezar a descartar ciertas cosas. Eh, ahora tengo una pregunta para ustedes dentro del para que en el foro pueda Contestarla. Este, ¿qué creen que pasa si sus datos tienen ruido? ¿Son duplicados o tienen formatos diferentes? Reitero, ¿qué creen que pasa si sus datos tienen ruido? ¿Son duplicados o tienen formatos diferentes? Eh, meter ruido es, por ejemplo, como este, yo lo levanto y ya no está traspasando nada, solo está emitiendo una señalita. Entonces, eh ahí le estoy metiendo ruido porque cuando yo lo pase a a mis datos tabulares, pues en ese Momento o en este momento
me va a marcar el tiempo y no va a saber ni qué información es. Entonces, tengo que limpiar toda esa información, tengo que hacer cierta depuración para que obtenga una señal limpia y así con toda la información que que manejen deben hacer cierta extracción, limpieza de datos también es importante. Entonces, eh si pueden poner su respuesta en el foro, ¿qué creen que pasa si sus datos tienen ruido? ¿Son duplicados o tienen formatos Diferentes? Y es como decirles a ustedes qué cre este qué sucede si yo como maestro no les enseño la información ordenada o estructurada
congruente o bueno, con congruencia y eh este clara y concisa. Bueno, bajo esta analogía o bajo esta premisa, lo que va a suceder es que voy a hacer que aprendan en desorden, que no aprendan como debe ser el ciclo de vida eh de recopilación, división. ¿Qué Pasaría si empezamos con el entrenamiento y luego recopilamos? No, no tenemos, no debe tener un orden. Lo mismo pasa con los modelos. El modelo aprende desordenado o aprende en desorden. ¿Sí? Entonces, esa sería la respuesta por si no la por si no la han puesto. Ah, eh, bueno, aquí está
lo de la división de datos. Ya les ya les ya les hablé de de esto de de nuestro 70, nuestro 15 y Nuestro 15 o nuestro 70 30 completo y ya luego eh una por aquí una este eh eh datos reales, ¿no? Para probar. Ah, vámonos a la a la ingeniería de características. Eh, vamos a avanzar un poquito a nuestro para nuestro tema porque todavía tenemos más que más que comentar, ¿no? Este es un tema, pero todavía nos falta más más charla. Espero no se aburran. Eh, bien. La ingeniería de características y reducción de dimensionalidad.
Mm, lo que suele marcar la diferencia no es tanto el algoritmo que vayan a utilizar. Mañana vamos a hablar de algoritmos y un poquito de de información eh al respecto, ¿sí? Sino más bien cómo se representan los datos y la la fuente de datos, es decir, que estos sean eh eh nutrientes, que sean realmente eh válidos o o importantes para entrenar nuestro modelo. Sí. Entonces, la fuente depende de la Fuente de datos es como vamos a extraer las características. Entonces, aplicamos cierta ingeniería de características para representar los datos de manera correcta. Esto implica o la
ingeniería de características implica seleccionar de mi fuente de datos, extraer mi fuente de datos y transformar esas características para mejorar la eficacia del modelo. Entonces, implica la limpieza de los Datos. Por ejemplo, les hablaba yo del ruido que acabo de meter al aparatito este, el escalado de variables, ¿qué variables son escalables? Pueden pueden evolucionar para volverse de dato de información. reducción de dimensionalidad. Es decir, si si yo dentro de mi de todos mis datos tengo igual y 10 20 características y y cuando hago mi validación este eh eh con métricas cuantitativas me da un porcentaje
Eh de 99% 98% y tengo 20 características y la reduzco a 12 y me da el 98% también. Pues entonces eh puedo optimizar de alguna manera porque ya no voy a utilizar las 20, voy a utilizar menos y si puedo reducir los menos y me da los resultados muy similares o los mismos, pues es a donde me dará cuenta que en realidad no necesito todas las características, ¿vale? Entonces, hay que saber Seleccionar las características de eh de nuestros modelos de aprendizaje automático. Ah, dentro de la reducción de dimensionalidad, que ya es otra otra parte, pues
hay dos rutas que vale la pena mencionar claramente. Primero, selección de características es elegir el subconjunto de atributos sin alterarlos. Yo los tomo todos o solo los que necesite. Ya cuando haga mis validaciones veré cuáles me sirven Realmente o cuáles no. Eh, extracción de características y dos, la extracción de esas características, transformarlos a un nuevo espacio de menor de dimensión, que es aduneles lo que les acabo de comenzar comentar. Ah, como ejemplo clave, h el análisis de componentes principales o PCA. Sí, lo un ejemplo es, por ejemplo, que el PCA mapea los datos de alta
dimensión o a características, datos complejos o o o muchos datos. Este, hace mi mapeo a características Que estas no son correlacionas correlacionadas y aportan beneficios como una mejor visualización, mejor rendimiento predictivo y menor costo computacional. ¿Sí? Entonces, lo que hace el análisis de de componentes principales es que me me ayuda a que el costo computacional, el procesamiento y que incluso también económicamente impacta, este, pues sea menor. Hm. Con el PCA lo que hacemos es reducir el Número de dimensiones de grandes conjuntos de de datos. conservamos la mayor parte de la información original y bueno, pues
esto lo logramos cuando transformamos eh variables potencialmente correlacionadas en un conjunto más pequeñito. Si hacemos una analogía al respecto, lo que vamos a hacer es, por ejemplo, nosotros tenemos un texto largo, Un texto un texto bastante largo, principalmente los los lectores se dan cuenta y buscan quedarse con lo esencial para entenderlo y trabajar más rápido. Entonces es la abstracción. tú dices, "No, pues es que de todo este texto tan largo ya no me interesa mucho todo esto, solo me centro en en en lo en la información que que me interesa." Un un ejemplo muy básico
es cuando últimamente algunas herramientas como Acrobat, bueno, editores o visualizadores de Documentos te dicen, "¿Quieres una versión reducida de todo este texto?" y pues te hace un resumen, ¿no? Eso podría ser este la parte nada. El asunto es aquí cómo sabe que que a ti te interesa cierto contenido de ese texto en particular. Posiblemente porque ya analizó tus lecturas o ya estadísticamente identificó aquellas palabras o aquellos elementos dentro del texto que son comúnmente este aceptados o o utilizados. M, bueno, ya acabo de hablar de reducción de dimensionalidad. Todo este material, entiendo, bueno, se encuentra en
el en el foro. Ah, hay algunos métodos eh hay algunos métodos que que de ensamble o de métodos de ensamble que son baging, Boston y stocking, que es es importante porque son combinaciones. Sí, aquí entra una idea Bastante fuerte. Eh, si en vez de apostar todo a un solo modelo eh combinamos combinamos varios, entonces ya igual y podemos obtener mejores resultados, ¿no? Ya no hay ya no igual y hay casos en los que no sea necesario eh trabajar con un único modelo, sino que combinas varios modelos y entonces hay ciertas técnicas o ensambles. En el
caso de del Boostracking, que sería el bugging, Este, en este se entrenan múltiples modelos en paralelo con muestras aleatorias como con reemplazo del del entrenamiento. Al agregar predicciones se reduce la varianza estadísticamente, es decir, la votación por la clasificación por medio para regresores. Eh, en el caso, un ejemplo de esto es Random Forest. Ese es el el algoritmo de los más utilizados. Sí. Entonces, eh, en en bagging analogía, para que quede un poquito más claro, no sea tan técnico, Una analogía sería de del bagging, es cuando es h pedir la opinión a varias personas y
quedarte con el consenso. Básicamente ese es el vaging. Sí. Entonces, con esto reducimos reducimos las poca objetividad de algunos de algunas personas o incluso caprichos, es decir, en un solo modelo o de una sola persona. ¿Sí? Entonces, esa es una analogía que creo que es bastante válida para la comprensión de este Método de ensamble. Por otra parte, el bosting, eh, en el bosting los modelos se entrenan secuencialmente, cada uno corrige los ángulos del anterior, a gran depende que van así y pues este avanza y este corrige lo que dejó mal y este avanza y el
de atrás corrige lo que dejó mal y así se lo va a llevar y entonces ayuda a reducir el sesgo y convierte aprendizajes débiles en una solución bastante fuerte. ¿Por qué? porque hubo una prácticamente una Este una solución a cada error eh eh que se iba presentando. XB eh el algoritmo que más se utiliza es XG Boost, por si gustan buscarlo por ahí, XG Bost o XG Boost. Y bueno, eh en términos un poco más simples, eh la analogía para el bosting, eh bueno, pues vamos a considerar h nosotros, bueno, los alumnos tienen un tutor
eh con ciertas sesiones programadas para aprender algo o un asesor o los Tesistas. Entonces hay sesiones programadas semanales, mensuales, no sé. Entonces, cada ronda de asesoría se enfoca en lo que antes salió mal para corregirlo hasta obtener el conocimiento necesario. Esa sería la analogía más apropiada desde mi punto de vista para el bosting, ¿no? Cito a mi alumno, analizo, le hago observaciones, las atiende, me trae nuevas, ah, las analizo, tienes nuevas observaciones, lo corrijo Y hasta que tenemos una tesis buena. Bueno, de calidad. Y el stacking, en el stacking, pues ya lo que lo que
hace es que se combinan distintos tipos de modelos en y un metamodelo es el que aprende cómo ponderar eh las predicciones. Es más complejo. Eh, realmente no es no es muy utilizado eh computacionalmente consume mucho, es muy es muy exigente este consume muchos recursos. Pero bueno, si hacemos una analogía para este ensamble, eh supongamos que un un equipo con especialistas proporcionan argumentos algún tema, ¿no? Y todos empie todos empiezan a hablar, pero finalmente un líder es el que decide cuánto creerle a cada quien para tomar una decisión. siempre va a haber uno un poquito más
influyente y y se va a basar en en la en en el en el modelo, en en el destaque, en la pelita, cuál es El que cuál es el que le conviene o el que le convence. Sale. Entonces, eh a manera de mm a manera de conclusión, este aquí estaba a manera de conclusión. Ah, si se junta si juntamos todos los conceptos que hablamos en esta en esta sesión, en este tema, porque todavía nos falta otro, eh si si juntamos todo lo anterior, el el mensaje final que yo les Puedo decir para para esta para
esta parte es los conceptos fundamentales de obtener fuentes de datos validadas, coherentes, legales. el eh después el dividir datos de manera estratégica con el diseño de buenas variables y el siguiente punto, reducir la dimensionalidad y y este bueno, finalmente si lo amerita el problema resolver, utilizamos un método de conjunto de Ensambles. Esto si es que lo amerita y no no necesitemos un único modelo, sino necesitamos combinar, entonces ya tendremos las capacidades de construir sistemas eh aprendizaje automático que realmente aprendan, se adaptan y generalicen. Y esta combinación va a permitir transformar datos en conocimiento eh accionable
con modelos más robustos, incluso podría eh interactuar con con modelos más grandes. Sí. Entonces, pues bueno, esa eh Es este tema ya este pues lo lo finalizo para dar pie al siguiente. Todavía tengo tiempo, qué bueno. Así que vamos a trabajar con los tipos deizaje automático. Ya hablamos del ciclo de adquisición de de de este de fuentes de datos, recopilación, características, este reducción de dimensionalidad de pruebas, Todo esto. Pero bueno, eh vamos a a iniciar. Ah, okay. Para el tema de tipos de aprendizaje automático, eh, sin profundizar en cada uno de estos, les voy a
proporcionar una descripción general, ya que mañana vamos a hablar de cada uno de ellos de manera puntual, ¿sí? Pero nos centraremos en cómo elegir el en esta parte, en este punto en los tiempos de aprendizaje automático. Nos Vamos a a centrar en cómo elegir el paradigma adecuado según el tipo de datos y el tipo de problema para que ustedes a través del foro eh puedan identificar o describir algunas situaciones que consideren. Sí. Bien, vamos a ver. Tenemos tres paradigmas fundamentales. Primero, el aprendizaje supervisado, el aprendizaje no supervisado y el Aprendizaje por refuerzo. Hay quienes ya
han escuchado hablar de ellos, hay quienes nunca lo han hecho y hay quienes, bueno, pues de manera somera les suena el tema. Sí. lo que conlleva a que bueno, este el objetivo de de este tema o lo que se busca menos en en en lo que tengo preparado, es que reconozcan a través de ejemplos si se trata de una predicción, si es un Descubrimiento de patrones o si se trata de una decisión secuencial con retroalimentación. Entonces, cada una de estas se alínea a los tipos de aprendizaje, ¿sí? Las predicciones se alínean al aprendizaje supervisado, el
descubrimiento de patrones se alínea al al no supervisado y el aprendizaje por refuerzo, pues se alínea a las decisiones secuenciales con retroalimentación. Bueno, primero eh El el supervisado, el aprendizaje supervisado aprende con datos etiquetados, es decir, ejemplos con entrada y salida conocida. Se me pasó aquí es este. Sí. Entonces, aquí los datos son son etiquetados. Segundo, el no supervisado trabaja sin etiquetas, es información desconocida, incluso eh se encuentra en grupos, en patrones o Asociaciones que incluso están son no conocemos. Entonces, como no tienen etiquetas, hay que hacer descubrimientos sobre ellos, sobre estos grupos. Y bien,
el tercero, que es el aprendizaje refuerzo, pues va a aprender por la interacción con el entorno para utilizar recompensas y penalizaciones, ¿vale? Básicamente, o si lo vemos de una manera simple, los aprendizajes son con respuestas, sin respuesta, Por prueba y error, con premios y castigos. Es una forma muy simple o llana de de este de describirlo. Ahora tenemos el aprendizaje supervisado. Este es muy útil en la práctica, o sea, en la investigación el no supervisado para hacer ciertos descubrimientos, pero en la práctica eh el supervisado, ya que hay modelos preentrenados con ciertas características que hay
que afinar para que se adecúen a nuestro a nuestra Necesidad. En el aprendizaje supervisado, el algoritmo aprende a partir de un mapeo de entradas y salidas utilizando ejemplos etiquetados. Sí. Es decir, eh son son etiquetas las que las que tienen eh hm y este bueno, tiene el objetivo de de predecir bien en datos en datos nuevos. Eh, volviendo al al a este tema de de aquí, eh si nosotros la la el dispositivo este tomo la señal, No voy a saber qué es porque porque viene con picos y así, ¿no? Valles y crestas y viene y
viene y viene. le puedo aplicar derivadas, le puedo aplicar primera derivada, segunda derivada y me va a devolver la la presión arterial y con algunos elementos adicionales me podría predecir algunas otras este ateroesclerosis posiblemente, ¿no? Pero no es porque analice la señal, sino porque la transformo y la etiqueto. Entonces, la vuelvo de manera tabular y Se vuelven números y ya esos números un especialista me valida si son correctos, si tengo que hacer una limpieza y pues ya esos números reciben cierre etiqueta. Por ejemplo, uno de los números puede ser correspondiente a la a la presión
sanguínea o al flujo sanguíneo o a la elasticidad de la avena, no sé, ciertas cosas o características que vienen de la señal. Entonces, eh eh ahí hago ciertos descubrimientos porque yo no sé, tengo Que analizar la señal, su morfología, pero ya eh ya después ya que la tengo eh eh entonces aplico aprendizaje no supervisado porque empiezo a identificar ciertos patrones en la señal y pues ya ya puedo decir que incluso lo puedo volver después un aprendizaje supervisado. Perdón. Bien. Ah eh en el aprendizaje supervisado tenemos dos categorías, la clasificación, que Son etiquetas finitas, y la
regresión, que son valores continuos. En este caso son valores continuos porque es una frecuencia, lleva tiempo. Las regresiones y las clasificaciones, pues son llevan llevan etiquetas. Eh, para el caso de para este caso eh podría podría etiquetar los numeritos eh para asignarle cierto valor o cierto nombre y ya identificar si se encuentra dentro de ciertos rangos que me permitan eh eh hacer cierta clasificación con Base en la señal. De lo contrario, pues una una regresión es lo ideal. Hay que recordar que en el aprendizaje supervisado el el sistema aprende con datos eh que deben estar
etiquetados, entradas y salidas y eso nos va a ayudar a predecir nuevos casos. Entonces vamos a analizar h algunos ejemplos. Sí, En el caso de las ingenierías, ah, si hay algún mecánico entre los asistentes en el los enlazados al al foro o los conectados al foro, el mantenimiento predictivo de las máquinas o de los vehículos, por ejemplo, si falla o no falla, con un historial de equipos y pues es algo cotidiano el uso. Entonces, de repente empieza el vehículo a a a mostrar señales de alerta. Eh, este es un ejercicio es un ejemplo de clasificación.
es un equipo, es de clasificación porque con base en ciertos ruidos, en ciertas flujos que salen, en ciertas cosas que un mecánico conoce, este, y ya tiene identificados que serían las etiquetas, ya puede clasificar lo que podría hacer, el daño que podría tener el vehículo. Entonces, ese es un ejemplo de este para prevenir daños en el vehículo. Otro Ejemplo para los administradores y los especialistas en finanzas son los ah los eh las detecciones de fraude, ¿sí? las detciones de fraude, de riesgo en créditos utilizando historiales y entonces es un caso un caso clásico de clasificación
si hay fraude o no hay fraude, si este va a ser alto o va a ser bajo. Eh, cabe mencionar que las clasificaciones muchas veces son binarias, es decir, fraude o no fraude, Pero también pueden ser multiclase, es decir, puede haar un riesgo bajo, un riesgo medio o un riesgo alto o muy alto dependiendo de la necesidad. Entonces, también hay que considerar eso. Las clasificaciones no pueden ser solo eh binarias de tiene o no tiene, sino también este por ciertos niveles de progresión. Y en educación, otro ejemplo, pues la predicción de riesgo de abandono es
algo muy común. La predicción de riesgo de abandono o aprobación probable con datos históricos del estudiante. Es decir, con los datos históricos del estudiante nosotros podemos estimar la probabilidad de que este apruebe y ya después eh la calificación final con base en el historial de las materias anteriores, podríamos eh estimar cuál va a ser la calificación final y eso ya no es haría una clasificación, sería una regación. Y ahí Tenemos dos cosas. tenemos eh voy a predecir el riesgo de que abandono de de que abandone la escuela o de que o de que apruebe la
materia con los datos históricos. ¿Cuáles datos históricos podrían ser? Pues su asistencia, sus calificaciones y todos estos datos que son identificables, es decir, que son este etiquetados y ya después una estimación de la calificación final que va a tener. Y eso es regresión. ¿Por qué? pues porque con El paso del tiempo ha tenido ciertas calificaciones en lo largo del semestre y con todas sus evaluaciones que pues a través de una regresión es como podría yo determinar cómo va a salir o cuál va a ser su promedio. Sí. Entonces, ah, si como actividad para el foro,
eh, sí me gustaría que que describan un ejemplo real o hipotético en el que se aplique o pueda aplicarse el aprendizaje supervisado, eh, además de los que ya De los que ya que aquí comenté, este, alguno que ustedes se les ocurra eh o hayan vivido o hayan trabajado también pues sería bueno que nos lo compartan. Voy a dar unos 2 minutos. Hm. Hace tiempo eh, por ejemplo, hicimos un trabajo para predecir hígado graso, eh daño hepático eh en hígado graso no alcohólico y solo íbamos a predecir eso. obtuvieron inform se obtuvieron datos de Solo como
anécdota, se obtuvieron datos de de de un de un hospital de una clínica aquí en Morizaba y resultó que el especialista el médico, ya que ya teníamos etiquetado las los biomarcadores del hígado, nos dijo, "Es que ustedes además de eso, podrían descubrir si puede padecer cirrosis, si puede padecer cualquier otra enfer enfermedad sin especificar cuál, porque nos daba los porcentajes. Entonces, eh Muchas veces eh con todo la información o todas las características que extraen, eh, tienen un propósito, pero de repente el especialista les puede decir que pueden que pueden que pueden descubrir cosas adicionales. Okay.
es solo como solo como anécdota. Bien, ahora vamos a al siguiente que es aprendizaje no aprendizaje no supervisado. El aprendizaje no supervisado eh ya como les mencioné Trabaja con datos sin etiquetas, identifica patrones o clústeres o grupitos de sin resultados previamente definidos. Cabe mencionar que muchos de los modelos de aprendizaje supervisado o generalmente eh iniciaron como no supervisado y ya posteriormente aquellos de a excepción de los de regresiones, aquellos que sí se podían etiquetar y que y que aquellos que sí se pueden etiquetar Y que antes no eran identificables, este pasaron de no supervisado a
supervisado y a partir de ahí tienen ya modelos preentrenados, ¿vale? Entonces, es algo que que se debe tener en cuenta. y puedo ver con agrado que que dan algunas algunas respuestas a las a las preguntas que qué gusto que participen en el en el foro porque es importante ya que pues bueno, es una es una participación, ¿no? Y y cualquier duda o comentario pues también Estamos aquí para servirles. Bien, retomamos o recapitulemos. Eh, en el aprendizaje no supervisado, no hay etiquetas, ya se los mencioné. El modelo se encuentra patrones, agrupamientos y formas de simplificar los
datos. Es decir, la forma de simplificar los datos es lo llamado reducción de de dimensionalidad. Ahora, algunos ejemplos eh aparte de los que los que puedan tener en la presentación, La cual pueden leer sin ningún problema es en el caso de la ingeniería, me voy por ramas para que para que quede claro, porque entiendo que hay de eh conectados de diferentes áreas. eh la detección de anomalías en sensores, es decir, me me marca anomalías, pero no identifico cuál es. Entonces, de una manera puedo alertar de un comportamiento raro porque todavía no lo tengo identificado y
a lo mejor y tengo varias varios sensores que me están Alertando algo y que todavía no sé qué es. Sí, como como los eh eh como los los del carro, los escanners de los vehículos antes de que lo hicieran seguramente no sabían. Entonces fueron asociando las fallas del carro y les fueron etiquetando para que el momento en el llega un momento en el que son tan especializados que lo conectan y te dice tiene fallo en el motor, tiene esto, tiene esto, pero ya ya fue etiquetado. Es por citar un ejemplo. Entonces, No hay quien haya
etiquetado las fallas en el caso de estos sensores que me están detectando cuestiones raras, pues es es a donde yo tengo que trabajar para ver qué sucede, apoyado quizá de especialistas, dependiendo del dominio y pues ya puedo eh eh este aplicar agrupamientos o puedo reducir o simplificar todos los datos para obtener cierta información útil para modelos. En el caso de marketing y de los administradores, pues la segmentación de Clientes, eso es muy muy típico. Puedo agrupar los comportamientos para campañas personalizadas y pues es una aplicación típica eh el hecho de que incluso cuánto tiempo pasas
cuando van al súper en cierta área. de eso de que tengan el wifi y todo eso, pues también tienen identificadas las zonas dentro de que si están en la de ropa, en la dechonería, en la de, no sé, en la de trastes o productos indicas, cuánto tiempo pasan en cada una y cómo Recorren todo eso es información, incluso cómo cómo seleccionan. Entonces, eh ahí se forman ciertos perfiles y pues también somos susceptibles de ser etiquetados de acuerdo a a los de marketing, el qué tipo de clientes somos, que al vernos entrar pues a lo mejor
y te ofrecen una oferta de zapatos en X tienda o centro comercial y eso, ¿no? Entonces ese es otro ejemplo. para los que entusiastas de la salud o especialistas en salud, Pues también agrupar clientes de pacientes por exploraciones, ¿no?, que nos permitan identificar patrones similares. En el caso de las este de las pandemias y eso es algo muy útil porque no conoces de que se están enfermando, entonces tienes que agrupar y entonces cuando no tienes un diagnóstico o es decir una etiqueta bien establecida, empiezas a a agrupar y ya determinas eh después tras el análisis
de las características o de las Variables eh cuál cuál es la enfermedad. Y para aquellos que trabajan también en en cosas de cultura, puedes organizar grandes volúmenes de obras como imágenes, descripciones y audio de autores desconocidos o incluso de técnicas desconocidas, pero por cuestiones de similitud entre ellas podrías crear un archivo cultural inicial. Entonces, eso también es es algo. Por lo tanto, pues es importante mencionar que una ventaja clave del Aprendizaje y no supervisado es la reducción de costos de preparación, ya que no requiere un etiquetado manual. Sin embargo, muchos modelos del aprendizaje supervisado, es
decir, etiquetados, primero fueron sin etiquetar, es decir, no supervisados. Ah. Al igual que en con el aprendizaje supervisado, eh se pueden tomar unos 2 minutitos para describir algún ejemplo, caso real o hipotético en el que se Aplique o se pueda aplicar el aprendizaje no supervisado. Sería sería bueno para ver si si quedó claro como a través de ejemplos eh pues pues queda comprendido el el tema. Me estoy amarrando el tenis. Ah, bueno, ya estamos por terminar. Todo lo tenemos fríamente calculado, así que eh aprendizaje por refuerzo es prácticamente las recompensas, ¿no? Son Decisiones secuenciales. Con
el el aprendizaje por refuerzo se describe como el más similar al aprendizaje humano. Es decir, un agente eh un agente computacional que no requiere intervención humana aprende interactuando con el entorno y mediante recompensas y penalizaciones realiza ciertas cosas y de esta manera maximiza el éxito de unos resultados a largo plazo. Entonces, para este tipo de aprendizaje Se este prácticamente se para este tipo de aprendizaje se entra en un ciclo en donde observo, ejecuto una acción, obtengo una recompensa o soy acreedor a una penalización y tengo que realizar una actualización para obtener un resultado. Repito, eh
el agente observa, está al pendiente de los valores que que recibe, ejecuta una acción, un proceso. Este es recompensado O penalizado, depende de lo que haya hecho. Y entonces si esto es positivo o negativo, es como va a dar como resultado una actualización o tiene que regresarse y volver a observar y ejecutar cierta acción con nuevos valores y obtener recompensa o penalización. Entonces es prácticamente como como nosotros, ¿no? Bueno, algo similar. Y si lo vemos de una manera simple, el aprendizaje por refuerzo, pues es un Sistema que mejora jugando muchas veces aprendiendo qué decisiones convienen.
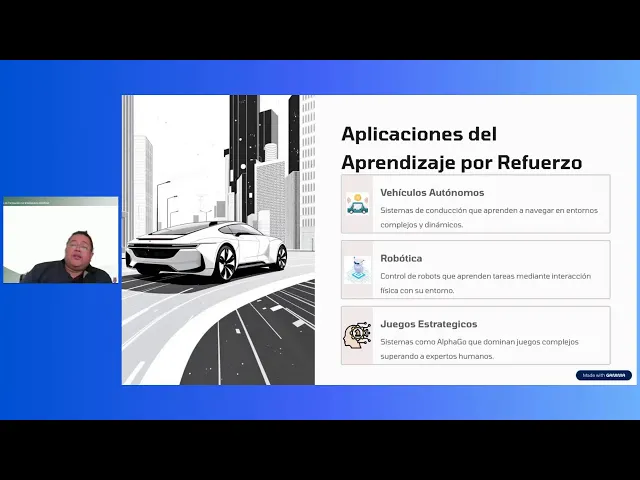
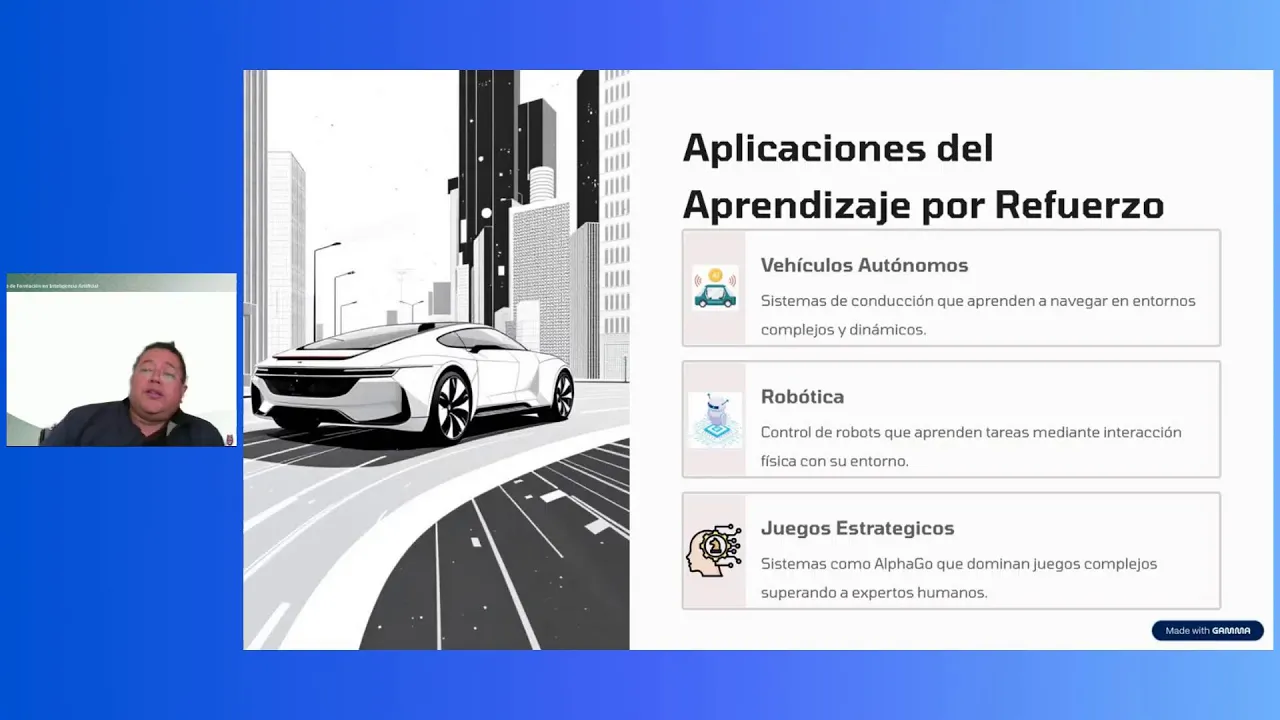
Entre los ejemplos entre entre los ejemplos del aprendizaje no supervisado, tenemos, por ejemplo, la robótica. la robótica, eh, con sus respectivos software y hardware, el robotcito, este, podemos hacer que aprenda tareas de interacción física con el entorno. en algún momento el robot si está entrenado para saludar a lo mejor y ejerza Demasiada fuerza sobre mi mano y como que me lastime, pero con sus sensores y con toda la información que pueda recibir o incluso la voz que diga me duele o algo así podría eh hacer el saludo más suave, ¿no? Entonces va aprendiendo este como
y va reforzando su aprendizaje y yo tengo un nivel de tolerancia o un umbral de dolor distinto al de una al de una mujer, por ejemplo. Al de una mujer igual y lo apriete un poquito más suave. Entonces hay ciertas recompensas o penalizaciones que puede ir recibiendo este robot para saludar, ¿no? Es un ejemplo muy simple. juegos estratégicos, por ejemplo, el Alpha Go, no sé si lo conocen, es un tablerito con fichas y blancas y negras. Bueno, este eh llegó a superar expertos humanos. Para aquellos que no identifican el Alpha Go, este es un programa
que de inteligencia artificial que hicieron en Google Depm para jugar el juego de Mesago. Entonces Eh ha ha ido aprendiendo por recompensas este para ganar para ganarle a expertos. En cuanto a electromovilidad, eh la conducción autónoma como aprendizaje de navegación en entornos complejos y dinámicos. Es decir, pues para no para no atropellar o no causar accidentes, también puede ser a través de de ciertas recompensas, ¿no? No te subas a las aceras o no te pases los semáforos. Entonces, algunas cuestiones de ese tipo también son Este eh pues son son a considerar en la agricultura. En
la agricultura también tenemos estrategias, por ejemplo, el riego y la fertilización. Eh, cada acción afecta el estado del cultivo, entonces hay que optimizar el resultado y el uso de agua o el o el uso de de nutrientes y y estas este los bueno eh eh la composta o la calidad de Los de lo que se le echa al a los cultivos para para que estos puedan puedan crecer bien. Este, entonces esa es una forma, ¿no? El el optimizar el rendimiento y el uso de agua con y este con base en cierta retroalimentación. Es como vas
a utilizar uno más agua o vas a utilizar un este más ah se me olvidó el nombre del de los del de este del ah bueno, no sé, semillas o o o Lo o lo que utilicen para que las para que la la siembra crezca crezca adecuadamente. ente y no se gaste mucha agua, ¿no? También. Y pues bueno, lo mismo que con los dos casos anteriores, si me apoyan eh pues también dónde podrían o en qué podrían aplicar aprendizaje por refuerzo en el foro. Estaría genial para revisar revisarlo y pues cualquier duda se este se
atienda. M finalmente eh vamos a hablemos sobre exploración y contraexplotación o frente a explotación. Sí. Eh la la exploración en cuanto al aprendizaje aprendizaje máquina es o aprendizaje automático es probar acciones nuevas para tener un resultado. Mientras explotar es repetir lo que ya funcionó. estoy explotando las pruebas que ya se hicieron. Pero si nosotros equilibramos ambos, vamos a maximizar el beneficio, Eh vamos a maximizar un un y vamos a obtener un beneficio acumulado. En este sentido, eh en cuanto a los modelos de aprendizaje automático, deben tener un equilibrio de ambas partes, tanto de exploración como
de explotación, para maximizar los beneficios a lo largo del tiempo. Ya para para cerrar el tema de manera concisa y este fertilizantes era la palabra, pero no sé por qué la olvidé para el caso de Para este caso para el caso de que les que les platiqué de la agricultura eran fertilizantes para no desperdiciar este fertilizantes y para no desperdiciar agua. Bueno, ya este aplicada mi fe de ratas verbal. Ah, cerremos este tema de manera concisa. El aprendizaje supervisado predice o clasifica con ejemplos. El aprendizaje no supervisado descubre estructuras y se puede convertir en aprendizaje
supervisado y el aprendizaje por refuerzo decide y Aprende con retroalimentación. Sale. Y pues bueno, antes de de irnos a a descansar, este, recuerden, todas las clases son sincrónicas, todas y en y las evaluaciones también y se rigen por el horario de la Ciudad de México. También es indispensable que ingresen su nombre completo en la descripción de del curso o a través del enlace que se les proporciona a lo largo de de la sesión En el QRC que amablemente aparece. Este tiene un horario, bueno, la la asistencia de 9 a 21 horas. Hm. El folio pues
no es obligatorio. Eh, todas las inquietudes diríjanlas al al foro, por favor. No hay creación de grupos, ¿no? No existen grupos. Y bueno, pues algo muy importante ya para el sábado 17 de enero, eh, en un horario de 0 a 23:59 horas podrán tener dos oportunidades para realizar su sus evaluaciones. Le Espero que les vaya muy bien y por mi parte es todo. Que tengan muy buena tarde. A nombre del equipo de inteligencia artificial y en agradecimiento a el equipo de Tecnemm e Infotec, pues finalizo mi sesión de hoy para continuar el día de mañana
a la misma hora. Saludos.