Okay. So on Friday, Mistral released a cryptic tweet with a magnet link to a torrent for people to be able to download a new model. And it turned out that this model was a Mixture of Experts model.
Basically it's like having eight Mistral 7 billion models all combined together to make one model in this. So in this video, I'm going to go through what Mixture of Experts are. I'm going to look a little bit at the history of some of these, Like most things in AI, these are old ideas that are being recycled and rehashed.
Now that we've got the compute and data available to make some of these things work. And then at the end, we'll also have a play with the actual Mistral model. I'll give you some links where you can play You can get it working locally but for most people it's going to be probably out of the realms of being able to do that.
You're going to need, probably at least 2 80 GB A100s or 4 of the 40 GB A100s to be able to run it locally or to run it on your own server in the cloud, et cetera. So let's start off by jumping in and have a look at what Mixture of Experts are, why they're so interesting, their relation to GPT 4, and then some of the things that are already out there before this, before we actually ever look at the actual Mistral model itself. All right.
So first off what actually is a Mixture of Experts. So in a normal network, we'd basically just have our input go through the network and then we would come out. At inference time, we'd basically just be doing a forward pass through like this.
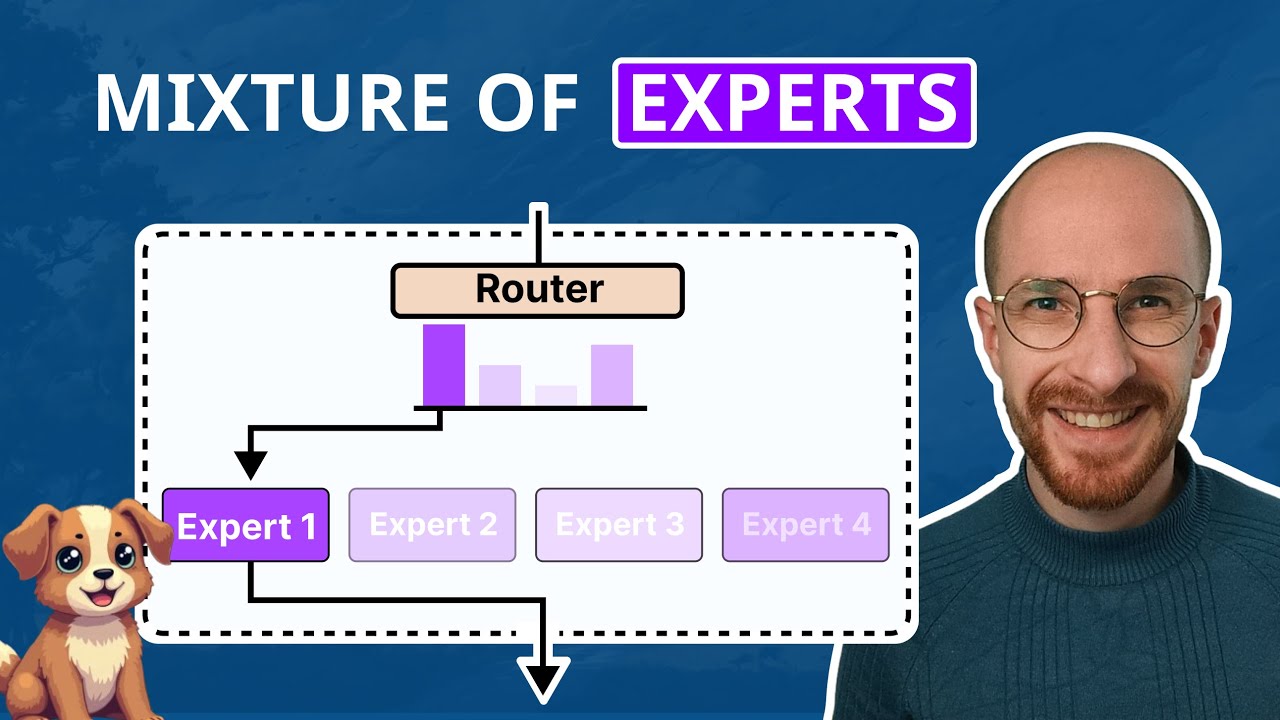
The idea with Mixture of Experts is that we're actually going to have like multiple networks going on here. So you can see in the diagram that I've got here, I've put four experts. It's how we sort of term these things.
And the idea is that we have an input that goes into a gating network or a sort of gating layer function in there. And the gating layer basically decides, or the gating layers, decide which expert to allocate, to this. So here, I'm talking about a standard Mixture of Experts.
There have been a number of varieties of these things over the years. The idea then is that once the gating network has decided which expert to choose it basically sends the signal up that expert and we take the output from that expert. And the other experts aren't contributing, in that sense then.
So they're each an expert at each particular thing. So the idea here is that this allows the experts to kind of specialize in different tasks. You could imagine that you have one expert that is really good at one task.
Another one is really good at another task. And then the gating layer basically sees the task coming in and decides, ah, this is going to be more appropriate for expert three rather an expert one or this is more appropriate for expert two, rather than expert 4, in this thing. So you can think of the experts as being sort of like separate little models themselves.
And actually in the Mistral one that they've released, they've got eight experts each of those being 7 billion parameters. So you you could imagine that they possibly started and initialized with the Mistral 7B, copy that over eight times and then did, you know, training for this to create each expert. Anyway, the idea is that when you're training these things, you're training each expert to get better at one set of particular tasks.
and you're training the gating function to get better at being able to determine what the input is and which expert it should allocate the task to as we go through this. So it is possible to also have it where it decides to allocate to multiple experts and then they combine the answer at the end. So here I don't have anything at the end, but you could imagine that you've got another layer at the end where you're combining these things to come together at the end and basically have us final softmax out over the tokens that you're predicting if you're doing language modeling for this kind of thing.
So one of the key things to understand is that the parameters to learn here are both the actual experts and the gating element. So when you're training this, you would need to train each of these things to be able to do this. Now, there are different takes on how people train this.
I think traditionally, most people train the entire network together. But I think there's also some ideas of that people could sort of do pre-training on an expert with one set of certain tasks. And you could imagine that if you get that to work, then it starts to allow you to sort of split up your training of your large language model in many ways as well.
So why is it suddenly everyone interested in, the actual Mixture of Experts model? Well, the whole reason for this is that, earlier this year, one of the key rumors about GPT 4 was that it was a Mixture of Experts model. And what the rumor claimed was that GPT 4 is actually a Mixture of Experts model.
Where you have eight experts Each of those experts is 220 billion parameters. And you have your gating function or your gating layers. on top of that as well.
So you could imagine that for OpenAI, this would be really cool where they could then take sort of one expert and dedicate it to function calling. So you can see here, like out of the eight experts, if you've got one that you can suddenly then train up and get it to be really good at function calling, you could almost have a model that's just for function calling and allow the other experts to handle sort of other key things in here. So this is one of the ideas that people have proposed around GPT 4.
It's also one of the things that it's quite possible that, Gemini uses some kind of architectural similar to this. Or uses some ideas taken from this. So compared to the open source models where people would basically just had one transformer decoder model stacked up, you know, depending on the size, the number of layers will change.
The number of heads will change and stuff like that. But basically it's one transformer decoder. Whereas these things are actually quite a different architecture in some ways.
Where these things are like an extension of that architecture in some ways that You would therefore have eight of these transformer decoders being able to stack them up. Now, this idea is not something that's new. As you can see here, this is one of the first peoples around using Mixture of Experts for Deep Learning which I think is 10 years old.
This was the third revision of the paper and that's 2014. And if you look at it, you will see that there's some very familiar names on here. We've got Ilya Sutskever as being one of the authors of this paper.
Another very sort of key Mixture of Experts paper was this Sparsely-Gated Mixture of Experts. The first author is Noam Shazeer who is now, the CEO and co-founder of CharacterAI. And you can see also that, Quoc Le is another famous people Geoffrey Hinton himself, Jeff Dean is on this paper.
The key thing here is that these ideas are not new. People have been thinking about, this idea of that what if we had multiple networks where each one could be sort of specialized in something for this Another really good paper that sort of came from Noam Shazeer and his group where the Switch Transformers, Which was one of the first models to actually train models going up beyond a trillion parameters. So the first version of this paper was in early 2021.
I think This is version three here that was edited June 22. Again, the idea of, how could you create a model that you could do this? Now, this was based on the sort of T5.
architecture and, extending that T5 sort of concept in here. Another fantastic project is the whole OpenMoE project. So this was started earlier this year.
The main person behind this came and gave a talk in October to our meetup. And went through some of the challenges of building an opensource MoE model. So just to get the compute alone required, a grant from, uh, TPU research cloud from Google.
And you see that they worked on and are still working on a number of different sizes of Mixture of Experts implementations, and how you would actually put these things into a model. That then you could run as an open source project here. So Mistral is certainly not the first, to come up with this idea or to even make an open source version.
I think Google open source some things from the switch transformers. on hugging face. I think there are a number of other projects of people trying out this Mixture of Experts idea.
But that brings us to the Mistral one. And they themselves certainly didn't claim to be the first. In fact they didn't claim anything when they put out their tweet, they literally just put out a link to a torrent.
And you could imagine that perhaps this is their first try at training one of these things that is 7 billion parameters per expert. They have certainly raised more money since their Mistral 7B model, which I still think is one of the best open source models out there as a base model. People are doing fantastic fine tunings on it.
And getting really good results from those fine tunings. Okay. So if you want to test out the model yourself, you've got a number of different options that you can try out.
On hugging face already, some people have uploaded a version of the Mistral - 7B-8Expert. You can also try it out with GPTQ TheBloke has released some of the weights for this. You will need to play around with the implementation of that a bit.
Also there's some versions online already that you can get started with. So replicate has one up here. I'll put the link in the description, just like normal.
And the other one that I've been playing with is this SDK Vercel AI. So in here you can actually compare two models and run them against each other. So you can see here, I'm basically taking the prompt that I have for doing the Sam Altman thing.
And you can see that we get the output for both, the Mistral 7 standard one here. And also the mixture of experts will version here. you must remember that the.
Mixture of expert version is a base model. It's not instruction. Fine tuned yet.
my guess is that we will see people try to do instruction, fine tunes over the next, few days or next couple of weeks, et cetera. but just keep that mind when you're putting in your prompts to actually try things out at yourself. So I'm not going to go through a lot of different prompts here.
You can certainly get online and have a play with it yourself. it's putting in one of the GSM-8Ks in here, so we can have a look and see, okay. How does this actually, do you notice that obviously the normal seven B model is coming up faster here?
but considering with sending this through the full mixture of experts, it's going to take a little bit longer to actually get it to work. in here. So, if we look at the output on this one, neither of them have gotten the correct answer.
but anyway, I will leave it to you to basically have a play. with the model yourself and decide on this yourself, I haven't actually had a chance to run any benchmarks against it. there are people reporting, benchmarks online.
The model card on hugging face for this one is actually reporting. You know, some pretty good benchmarks for things like MMLU you in here. And an okay.
Score for the GSM eight K in here. It's still quite a way off, what GPT four would be getting for this. and I'm actually not sure.
the methodology they've used for doing the evaluations in here. But have a play with the model yourself. You're going to find the inference on these things is definitely going to be slow.
the mixture of experts are not really sort of designed for running locally. they are designed for running with quite a lot of, hardware and Really the advantage. there can be, that you can actually make a lot bigger model and then distill it down to a smaller model.
So this is one of the things that we may see over time. Is that. the next big trend becomes distillation of some of these bigger models down to smaller models.
So there's been some interesting papers about that recently. And perhaps we can look at that in a future video. Anyway as always.
if you found the video useful give it a like, and subscribe. I will talk to you in the next video. Bye for now.