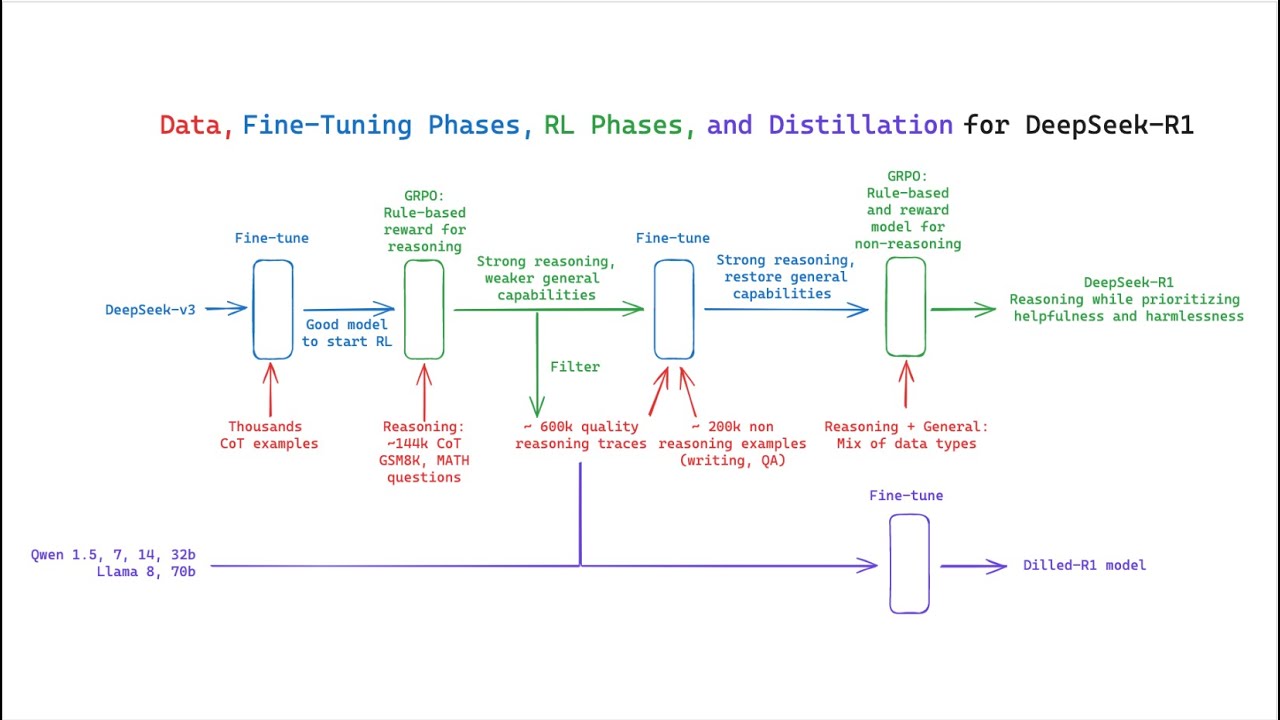
hello welcome back super excited to be able to do this I've got some benchmarks I want to show you on the 7900 xdx this is early testing that I'm doing um I want to know if people are interested in benchmarking so I am trying to put together some tooling around being able to do this more so I can pop in and out more gpus and kind of understand how different models work but it's very timec consuming because I need to run multiple passes over and over and over again and then also trying to understand what to measure properly to me it what I landed on as tokens per second makes the most sense it's like a very easy understandable thing but I also want to say that is also a little bit convoluted because for some of these models you can give it a large prompt and it could sit there and process for a long time before it starts actually generating tokens so just so the tokens per second is kind of um kind of nuance there so what I've done is I've basically taken the time from when the prompt is sent to when the prompt is done this is all done programmatically and I I take that time period and then take the number of tokens that were generated and that is how I'm generating the tokens per second I'm doing it all on a 4096 context I'm using the Q4 korm model for each of the ones I'm going to be talking about this is a one shot performance what I do is I do six passes at each PRP size so that's small medium and large and then I have the temperature set to 0. 7 one thing to note I do throw out the lowest pass just to try to remove some outliers because there can just be times that it you just get one that's like half the performance of others and I just try to like Smooth It Out by getting kind of the average over time anyway let's jump into that this is Quinn 2. 5 32 billion I ran the distilled model versus the non-distilled model the original and you can see they're BAS basically the same what I would say here is you can kind of see the curve moving up so very short prompts perform slow or they have a lower tokens per second because of that initial ramp up time because you can send it something it takes a mod like actually get it going and but you can see kind of the curve and it it's probably going to continue flattening out uh I would need to kind of run even larger ones but typically you can you could get around five to a little over uh five tokens per second maybe uh if you're doing a really small one you might see you know 4.
3 or 4. 2 but really I didn't notice much difference in the number of tokens per second generated between the original and the distilled one which I thought was really interesting because I kind of anticipated that there would be a little bit more variance in that and I'm actually a little surprised at the distilled model kind of curving down more more it I would I actually when I get time I actually want to run that out further like what happens when you do Max tokens of 15 and you do a larger promp there I would love to kind of understand that and actually some of the examples I'm going to show you have enormous outputs and those are going to be interesting because their tokens per second are a lot lower than like these averages because they're so big all right and this is the Quinn 14 billion parameter one pretty much neck and neck they're kind of the same land you know anywhere the small ones again very very low tokens per second because you're just doing a lot less but when you start getting up into like the 300 tokens or 750 you know you're seeing about 40 to little over 40 tokens per second for each of those Quinn models on the 7900 XTX paired with the 7800 x3d and finally I'm going to be talking about the Quin 2. 57 billion parameter model you can see they're basically identical um I've got a highlight here just to kind of show you 7.
28 4 compared to 7 72. 85 at the peak and they're continuing like kind of the incline there so I would imagine I could probably squeak closer to 75 if I you know did a th000 Tok or a th000 Max tokens on the output anyway I thought this this performance was phenomenal and it's interesting seeing there's no difference between the coder version and the distilled version I didn't think there'd be much difference but I did think you know as you get more tokens it probably slow down some um and I do need to test that I would love to test that on like a 8,000 or 10,000 token prompt like where it's doing a lot of reasoning a lot of thinking I want to talk a little bit about some of tests I've been running I spent a decent amount of time running these tests to kind of determine how well it is how well it's doing overall like is it something I could actually use locally one issue just is the speed you saw on the The Benchmark get about you know four to five tokens per second and I'll show you some of that as we go forward here I'm pulling up my uh my notes over here on the side because I want to make sure we can verify these answers I have not gone through every one of these to verify the answer is correct so we'll do that kind of together so this is the baker's dilemma a baker needs to make 60 muffin each batch requires two eggs and makes four muffins eggs are sold in cartons of 10 a c carton cost $4 and she can't buy individual eggs what's the minimal amount she must spend on eggs to make all the muffins so the answer should be three cartons she needs times $4 so 12 so $12 should be the answer and that's ultimately what it ended up getting you can see here 5. 46 tokens per second it did a really good job um I do want to figure out some of my templating here and if anyone knows how to fix that I've been trying to dig through that because I'd love to be able to clean up these slash text things that come out uh so we're going to go to library book Return now and Sarah bar bar a 400 page book from the library she reads 25 pages per each weekday and 40 pages each weekend day if she started reading on a Tuesday on what day would she finish the book The answer is Thursday of the second week now if you go through this one you can see here that it comes up with week one 7even days but notice that we actually started on Tuesday so it made a flaw here it had a flaw here but all it comes down here and kind of corrects that so here it ends up correcting week one Tuesday Sunday so it get gets 180 this is correct then it goes to week two and it sees that basically if all of week two is done um we'd end up having 125 during the weekday because we ended up there so that would put us at 305 so 180 plus 125 and then what that ends up doing is going like okay since Sarah reads 25 pages each weekday she will finish the remaining 95 days as follows 95 Pages as follows so 25 25 25 25 total readed 405 this is the right answer Thursday however here only needs to reach 200 pages so it was so close this one ended up failing so I did read through this I was so sad about that because it technically had the right answer but it ended up thinking about it wrong and said Wednesday because it assumed that 405 was over and it couldn't go over paint mixer um this one's kind of fun the painter has three paint colors red blue and yellow he needs to mix them to create green purple and orange if mixing any two colors takes 5 minutes and he can only mix two colors at a time what's the minimum time needed to create all the secondary colors what was very interesting about this one is all the questioning it did to itself so wait is there any way to do this faster like if some secondary color creation doesn't require all three payers no and then it was then it actually talked about like can I do some of it in parallel this one ultimately came up with the correct answer which is 15 minutes 4.
92 tokens per second 32 3281 tokens and notice this 6. 56 seconds the first token so that was uh that was a very good answer so we're two in one currently the growing Garden the growing Garden also was one that I dug into with him for uh into quite a bit so this one's kind of interesting so basically if you have a square garden and you want flowers planted in a pattern where each flower needs one square meter around round it so basically there has to be a path between each flower if the garden is 5 meters on each side which means a 5x5 what's the maximum number of flowers that can be planted this one did a great job of kind of like laying out its own little map of them so put a flower here or empty here flower empty flower empty but it didn't account for the diagonal the right answer is not to have have them like that it's to skip this entire second row and actually fill it in here is really the only way to do that so you can only do a 3X3 grid so this one was also Incorrect and came up with the answer 13 so now we are two and two this one had a very quick time to First token you can kind of see the variance there um then we end up with this temperature puzzle and this one was kind of interesting so a scientist records temperatures for five consecutive days the average temperature was 20° C each day was exactly 2° so 2° warmer than the previous day what was the temperature on the first day so remember the average right so if you come down here the answer should be 16° it actually did come up with that correctly and the way it did it seemed very straightforward it didn't Ramble On much only 541 tokens which ended up being a lot faster there now we end up on the elevator in a 20 story building an elevator starts at the ground floor goes up five down three up seven down four and finally up eight if each floor takes 30 seconds to travel between how long did the entire Journey take and on which floor did it end the correct answer is let me look this up 13. 5 minutes on the 13th floor and so we ended up getting the 13.
5 minutes and if you look up here we ended up getting the 13th floor the next one is the water tank a tank is being filled at a rate of 10 L per minute if the tank is 2 m in height and 1 m in diameter and it's currently 25% full how many minutes will it take to fill it to 75% and you can use Pi is equal to 3. 14 the correct answer for this one should be 78. 5 minutes and again it did a very straightforward calculation and it did come up with 78.
5 so we are currently 5 and two for our answers which is really really cool um the next one that we're going to talk about is the time traveler schedule a business person needs to attend meetings in three different time zones New York London and Tokyo if they have a meeting in New York at 2: p. m. then one in London at 3 hours later finally one in Tokyo 4 hours after the London meeting what time will it be in Tokyo during the final meeting I'll be honest with you when I first did this one by hand actually got it wrong uh I was off two hours but this one did it correct on the first try and it did it very quickly 11:00 a.
m. and remember that is going to be in Tokyo time 11:00 a. m.
and then package sorder all right this is the one that I wanted to probably talk about the most first off you can see down here the context is gigantic this one rambled on a ton the idea behind this question is how does it handle situations where there's more than one answer a human could look at this and they could be like okay a shipping company has boxes of three different sizes small medium and large 1 kgr 2 kgr 3 kilogram if they need to ship exactly 20 kg using exactly 10 boxes how many of each size box should they use simple answer there you just use 10 medium boxes right there's also other options you can use uh three medium or three small four medium three large there's a few others too but it goes through and let me just see if I can find some of the spots in here anyway ultimately it landed correct the correct answer but it ended up generating 8,35 tokens and it took a very very long time and some of the funny things I saw but considering the initial problem statement in Chinese might have been translated differently or had specific context implying only one solution is expected but without more information it's hard to say I thought that was interesting initial problem statement in Chinese I had not seen that one before wait maybe in China when they see such problem they expect that you have at least one type of each at least one of each type hence for a solution so there is definitely some Chinese influence in the output of this this model and in fact it even talks about it being translated I'd be curious um if you guys are seeing similar behavior in there but it only happened in a particular like this one that was like just absolutely massive all right let's talk about the clock angle this is one that I just I think is very fun because the clock hand hands are moving and exactly 345 what is the smaller angle between the hour and minute hand on the analog clock not the hour hand moves continuously not in jumps okay so it does a really good job kind of walking through this and actually gets the answer perfectly I threw this in clawed and it actually got the answer wrong I asked it about it and then it got it right so kind of a a win there you will see really poor like tokens per second this is one of the lower ones that I've seen um does use a lot of that context for the 4069 now I moved over to coding this is actually a problem that I've been working on uh or I have worked on in the past so ultimately I give it some code basically some features that I've been engineering and I asked it to help me generate a machine learning model to predict customer churn and what it ended up coming with up with is like it ended up with a binary Target variable it split data into training sets which I thought was great like you definitely want to do that and then it wants to choose a learning uh machine learning algorithm this is a fine Choice honestly random Force to a totally fine choice for this type of data that's here and then it runs through all the different steps for evaluating training then analyzing the importance and then it even does a grid search on it to optimize the parameters on it for the hyper preter it's got the saving of the model so that we can actually load it in later then it gives me the full implementation honestly I was very impressed with this particular output here I thought it was incredibly well done and I'm actually going to try to start using this more for coding if it wasn't for how slow it is and then the the limitations of my system only being able to load you know like 4096 contacts let me just pull this down here to show you so if you look here um I'm at 21805 of my utilization and 44. 3 most of this unfortunately is Chrome which is ridiculous uh but it is using just my system is just like maxed absolutely maxed at this point so I would defin itely use the Quinn 32 billion perameter model the reasoning model for coding more if I could run a version with more um context and faster ideally all right this is when I just wanted to kind of see like if it could come up with a good board game design I have not read through this one much but ultimately let's see here it's a game named Farm fry it did a little bit of thinking between here which I I love the way it does that and I love the way it kind of feels like humanid at times it's like oh my son was actually watching he's like wow it talks like a human and it kind of does at times especially when it makes a mistake so it it did a I would say a mediocre job here this doesn't seem like it's going to actually be anything groundbreaking it doesn't go into details about the cards it barely used any of the context it um I'd say this is kind of poor although I gave it a very light uh design guidelin so I probably wouldn't need to special uh spe specify a lot more specifically what I wanted the outcome to be but it you know it can do it and again tokens per second were very slow there as I've kind of been running more and more all right that's a wrap I'm going to stop there I've got other tests that I've I'm doing I actually have some running right now on my computer that are taking a very long time that'll be interesting that are more of like mathematical and equation based I'm curious what you guys all think do you think Quinn 2 5 32 billion parameter model is the model that we could actually use on a day-to-day basis I'm starting to lean towards J my only limitation is my Hardware I would love to be able to get to the point where I can actually run it faster than five tokens per second and I makes me really really want to get the 5090 in a few days here because I would love to be able to test that model love to also be able to profile it also let me know what you think about the profiling I did I have have tons of data I'm trying to booll it down to where it's simple CU I see a lot of people saying like how fast is that model on that card how how much can you actually run and what I'm trying to do is start building some of my data up so I can actually do larger uh benchmarking videos on that so this is just kind of like a taste of that some of the data I've been put together and that data took a day and a half of straight running my GPU to generate it because I Ran So Many iterations and across so many models like I only showed a few I ran uh 54 I ran all the Llama models I've ran a ton to see how they compare I've ran some of the 1.





![Roo Cline Vs Code + DeepSeek R1 + Copilot Sonnet FREE AI IDE [Better than Windsurf/ Cursor in 5min]](https://img.youtube.com/vi/Jg9xDg99Kic/maxresdefault.jpg)