Hello everyone and welcome to this lecture. In this lecture, we are going to understand about a topic which I've been thinking about for a very long time. And the topic is when you talk with an LLM, let's say when you write something here. Let's say if I ask give me a brief history of chocolate let's say then you see some tokens which are being generated here Which is called as inference right now the inference engine which openai claude geminina use that's closed source we do not know about it then how can we start understanding about
inference engines? Basically the question which I ask myself many times is when you put a prompt over here what exactly happens to the tokens of a prompt as they go through the inference engine. So I have made so many lectures so far On the pre-training stage of LLMs, how to build language models from scratch. But there is a beautiful world out there in which a lot of innovations have happened in the inference engine itself. Essentially if you are OpenAI or Chat GPT for example, you would want to perform the inference operation as efficiently as possible.
You would want to use as few GPU resources as possible because it's directly related to cost. So if your inference engine is not Optimized and if you are consuming lots and lots of unnecessary GPU memory and power, it will cost you more and so CH GP will charge us more as the users. So everything comes down to inference engine when we look at production and I really wanted to understand what happens to these prom tokens in production level inference engines and uh one production level inference engine which is open source and which is hugely popular
Uh currently is VLM. this VLM you can see that it has around 58,000 stars at the moment. It's been forked more than 10,000 times and it just an amazing inference engine for language models and it's supposed to be very fast and it's supposed to be extremely efficient as well. So they mention state-of-the-art serving throughput and they have several new innovations such as paged attention, Continuous batching, speculative decoding, chunked prefill, etc. And whenever I looked at these terminologies earlier, I really found it hard to understand what's going on. But then I stumbled upon this blog which
was published around 2 weeks back inside VLM anatomy of a high throughput LLM inference system. I'll admit that it was not that easy for me to read this blog since it was my first time to really Understand um how a production level inference engine actually works. But it opened my eyes to the fact that there are so many things happening during inference. It's not as simple as you give a prompt and there is an output which comes. Right? Between you giving a prompt and the output which comes, there are a huge number of innovations and
efficiency tricks which have been implemented. And knowing those tricks is just very important to any of us who Want to contribute to cutting edge language model research. If you are working in a company as an ML engineer or an LLM engineer and if you want to cut down inference costs, you really need to know what's going on behind the scenes. Now, unfortunately, there is very less amount of material which explains all of this from basics. And uh it is my aim or my desire to open that black box and really try to explain to you
how VLM Works from scratch. How a production level inference system works from scratch. So today we are going to look at page retention. We are going to look at continuous batching. We are going to look at u speculative decoding prefix caching in the next lecture. Today's purpose is very simple. I want you all to develop a visual mental picture or road map of when a token comes in as a prompt. What exactly happens to the Prompt uh when we generate outputs and when you visualize this in your mind it just makes things very clear for
you. So here are the lecture notes which I have prepared. Life of a prompt. The title which I have given this is life of a prompt through LLM inference. A difficult road ahead. So imagine this as the prompt. The road which it has to travel to is not very easy. As you'll see when you interact with chat GPT all Of that intermediate layer is just abstracted away. But let me try to open that black box a bit and explain to you what's going on. So I've divided the lecture into steps. Step number zero, step number
one, step number two, step number three and uh step number yeah three steps. uh and I've tried to make this lecture as highly visual as possible because the more I learned about inference the more there are concepts like blocks Uh taking space um and all of those can be explained very nicely using visual rectangles colored rectangles and that's what I've aimed to do here we'll also be learning a bit about GPU vramm we will also take a deep dive into what exactly is KV cache Now remember that for the purposes of this lecture I am
going to assume that you know what an attention mechanism is when I explain query key and value. Uh When I explain what is an attention matrix what is a context vector. I am expecting that you know the basics of these terms. If you do not it's fine. just watch this lecture but you'll need to go back and watch the build LLM from scratch series videos to understand about these building blocks. So let's get started. Okay. So let's get started with the different steps. Now imagine That for all of the steps which you are going to
which we are going to follow now you can put yourself in the shoes of the prompt right so at the end of this lecture the goal for you is to visualize what exactly happens to all the tokens in the prompt so if in the middle of the lecture you are suddenly confused about oh I don't know what's going on and why is this step being explained refor formulate your thinking in the lens of okay if I am the Prompt what is exactly happening to me at this stage okay so the first step is your arrival
as a prompt some user has typed you somewhere like give me a brief history so let me type this again here give me a brief history of bicycles let's Now that's a prompt. The prompt has arrived over here. The prompts which we are going to consider are three prompts which let's Say a user has given to an inference engine. The first prompt is hi my name is. The second prompt is today is a beautiful summer day and the third prompt is hello there. We are going to send these three prompts to VLM and then VLM
is going to complete these prompts. It's going to generate responses. So the reason I've shown this image over here is twofold. First Because the prompts have arrived over here that's why arrival and second because it's one of my favorite movies of all time. So let's actually install VLM and run us run these three prompts through the VLM engine. And first let's see the output and then we will see how to get from mentioning the prompts to our output. Right? So here you can see that I have first of all installed VLM and then I have
mentioned These three prompts which I' have passed to VLM. P1 is hi my name is. P2 is today is a beautiful summer day and P3 is hello there. Now you of course need to define the language model which you are going to use. And the language model which we are using here is this tiny llama. It's one of the simplest language models which has only about a billion parameters. So this is the language model which we are going to use. And then we just load the language model here and then we call llm.generate and then
the outputs are printed. What we are trying to understand in this lecture is that what happens when this llm.generate is actually called. What happens under the hood? Let's open this black box. So since we have three prompts, I'm going to print all the three outputs and I've defined some conditions over here like temperature equal to8 top B. So it Will sample till the probability reaches 0.95 and the maximum number of tokens to be printed after our each of our prompt is going to be 50. Now when you run this code block you'll see that several
different things happen over here. First of all our model is loaded. The tokenizer of the model is loaded. That's fine. The second thing you'll see here is that there is something called CUDA blocks and there is something called CPU blocks. And Currently it's fine if you don't know what these numbers mean. But we are going to understand what these numbers exactly mean. We are going to from first principles we are going to derive these numbers today. The second thing we'll understand is what is the GPU VRAMm and uh how do different uh components take setup
shop in the GPU VRAMm. So you can think of the GPU VRAM as land or uh I'm just recording. Yeah, I'm just recording a video. Uh yeah, you can sit over here. Yeah, this fine. I'm fine. Okay. But it's not going to disturb you, right? Cuz I'll be speaking. That's fine for me. Yeah. Okay. So, let's get started with the different steps. Now imagine that for all of the steps which you are going to which we are going to follow now you can put yourself in the shoes of The prompt right so at the end
of this lecture the goal for you is to visualize what exactly happens to all the tokens in the prompt so if in the middle of the lecture you are suddenly confused about oh I don't know what's going on and why is this step being explained refor formulate your thinking in the lens of okay if I am the prompt what is exactly happening to me at this stage okay so the first step is your arrival as a Prompt some user has typed you somewhere like give me a brief history so let me type this again here
give me a brief history of bicycles let's Now that's a prompt. The prompt has arrived over here. The prompts which we are going to consider are three prompts which let's say a user has given to an inference engine. The first prompt is hi my name is The second prompt is today is a beautiful summer day and the third prompt is hello there. We are going to send these three prompts to VLM and then VLM is going to complete these prompts. It's going to generate responses. So the reason I've shown this image over here is twofold.
First because the prompts have arrived over here that's why arrival and second because it's one of my favorite movies Of all time. So let's actually install VLM and run us run these three prompts through the VLM engine and first let's see the output and then we will see how to get from mentioning the prompts to our output. Right. So here you can see that I have first of all installed VLM and then I have mentioned these three prompts which I' have passed to VLM. P1 is hi my name is. P2 is today is a beautiful
summer day and P3 is Hello there. Now you of course need to define the language model which you are going to use. And the language model which we are using here is this tiny llama. It's one of the simplest language models which has only about a billion parameters. So this is the language model which we are going to use. And then we just load the language model here and then we call llm.generate and then the outputs are printed. What We are trying to understand in this lecture is that what happens when this llm.generate is actually
called. What happens under the hood? Let's open this black box. So since we have three prompts, I'm going to print all the three outputs and I've defined some conditions over here like temperature equal to.8 top B. So it will sample till the probability reaches 0.95 and the maximum number of tokens to be printed after our each of our prompt Is going to be 50. Now when you run this code block you'll see that several different things happen over here. First of all our model is loaded. The tokenizer of the model is loaded. That's fine. The
second thing you will see here is that there is something called CUDA blocks and there is something called CPU blocks. And currently it's fine if you don't know what these numbers mean. But we are going to understand what these numbers Exactly mean. We are going to from first principles we are going to derive these numbers today. The second thing we'll understand is what is the GPU VRAMm and uh how do different uh components take setup shop in the GPU VR RAM. Think of the GPU VR RAM as a land and uh there are se several
players who want to set up apartment or shop on the land but the land available is limited. So you really need to know How much land is available to you and uh how to best utilize this land. That's one of the key aspects which we are going to understand in today's lecture. We are going to visually learn a lot about GPU VRAMm and understand where do these numbers actually come from and what what actually is allowed to take space on this land. We'll learn all of this. So don't worry about it. And then you'll see
that after all of these statements which have Been mentioned over here, graph capturing finished in 36 seconds. Um creating KV cache took around 42 seconds etc. And then you see the completion output over here. For prompt one, this is the completion. For prompt two, this is a completion. Today is a beautiful summer day, a perfect day to relax at home, etc. And for prompt three, this is the completion. Hello there. I'm really Happy to be part of the WIP Wednesday event etc. So we are actually going to learn today that how do we go from
prompt to completion? What exactly happens to these prompt tokens in the middle? That is the journey which we are going to learn about today. So that's step number one. the prompts or the tokens in the prompt have arrived or I'm calling it step number zero here because that's pretty obvious right someone has to type the prompt for it to Go through the inference engine then we come to step number one which is tokenization now remember that language models or AI for that matter cannot understand English language so we need to convert English language or tokens
into numerical format. So that's the first step which is tokenization where we have three prompts right P1, P2 and P3. All of them are converted into tokens. So prompt P1 let's say is converted into five tokens which are 154 11112 42 756 298. P2 is converted into seven tokens. So this is 5. This is 7 and P3 is converted into two tokens. That's the first thing which happens to these prompt tokens in their journey. Now, how is this tokenization actually selected? The tokenizer which is selected is based on the model itself. So unless we specify
a custom tokenizer, every model on login face comes with its Tokenizer. So that tokenizer is used to tokenize the prompt into individual token ids. Mostly all modern language models use subword tokenization scheme using bite pair encoding. So that's how we generate the token ids. If you want to play around a bit with tokenization, you can also go to this tick tokenizer app where you can just let's say take any prompt. If I want to take Hi, my name is And I want to see how it's tokenized. I can first of all select which tokenizer. Let's
say I'm doing GPT 3.5 Turbo and I put my prompt. So, hi, my name is This is how tokenization is usually done. All right. So, that's the first step where the prompts are converted into their token ids. Now one thing to keep in mind is that for the rest of this workflow or for the rest of this journey we are going to talk a lot in terms of token ids because after this point the LLM really does not see prompts as humans see they only see token ids. So we are also going to look at
token ids from this moment onwards. Okay. After this point, what happens is imagine uh you are going to watch a movie and imagine you are a token. You are not directly let into the cinema hall. There is a waiting queue where you have to first uh present yourself and you have to Wait. So once the tokens are converted into token ID before they are processed by the VLM inference engine, all the prompt tokens enter the waiting queue. And here there are two types of requests. There is something which is called as prefilling which happens first
and then there is something which is called as decoding. We are going to understand what prefill means and what decoding means in a lot of detail. But remember that uh this is how the waiting Area might actually look like. And uh you might there might be a prefilled request for a given token or there might be a decoding request. It can be either of the two. categories. Usually decoding requests are prior prioritized over prefilled requests. We'll understand what these two mean in a lot of detail. But for now, think about this fact that you are
in this waiting queue like this before you are let into the VLM inference engine. Before we move to step number three, we have to take a slight digression over here to actually understand how inference works. what exactly is the KV cache and uh what's the difference between prefilling stage and decoding stage all right so the way inference works is that let's say you have these four tokens hi my name is all of them will be converted into token embeddings then we have the entire architecture of the language model itself which can be Thought of as
transformers which are stacked together so you can Think of the um whole transformer architecture like this. You first have these token embeddings. Then you have the transformer layer number one, layer number two, layer three, number four, etc. Okay? And a given architecture might have many transformer layers. For example, the tiny llama which we considered, I think it has around uh 22 transformer layers if I'm not Mistaken. Um I need to we'll confirm it once but I think the tiny llama has 22 transformer layers. I have just shown four here for reference. So what happens is
that these four token embeddings they go through all of these layers and then finally we have to predict the next token. That's the inference right. What inference essentially means is that we just have to predict new tokens and append these new predicted tokens to the previous Tokens. But to predict the news new token there is there are a number of things which happen within every transformer layer or block. So within every transformer layer we have the query matrices, the key matrices and the value matrices. And then the query multiplied by the keys transpose gives us
the attention scores. We divide by square root of the keys dimension. We apply causal attention and then we get the attention Weights and then we multiply the values with the attention weights to get the context vector. The context vector then goes through neural network feed forward neural network shortcut connection normalization layer etc. And then we then we come out of the transformer loop. So all of these operations which I just described happen in each transformer loop. The key thing which people realized is that whenever you want to predict new Tokens, you don't need to recomputee,
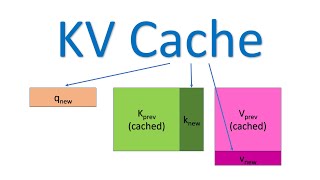
you don't need to recomputee the keys and the values matrices every single time. So you store the previously computed keys and the value matrices. This storage is essentially called as the key value cache. And this key value cache serves as the foundational building block to understand how VLM actually works. So before even new tokens are predicted, we need to first for these given four Tokens itself, we have to compute the keys and the values and we have to cache them. And then when let's say after everything is cached and we predict this new token, this
new token is then appended over here. So let's say it's the new token is Alice, right? This new token is appended over here and then this entire matrix. Then again we go through all of these transformer layers. But now the thing is we don't need to compute the entire key And value again. We can reuse the previous keys and the values which have been computed. Let me explain this once more. Let's say there are these uh let's say there are these four tokens right which have entered. First we have to compute their keys and the
values in every transformer block because that those are needed to get the output of each transformer layer. Now these computations so this will be a 4x4 matrix here and 4x4 matrix here. We'll store these in the KV cache. We'll store these in the KV cache. And now let's say you do one pass and then you get the next token which is Alice. In the next pass you append this token Alice over here. And now when you are wanting to predict the next token, you can reuse these keys and the values which were computed earlier and
then you can predict the new token. Then you append it back here again. let's say Alice is and then you again use the extended key value cache. So that's how the key value cache is reused during inference. So if you closely observe what's going on here before even new tokens are predicted first what we have to do is that first we have to compute the key values for these four tokens and do the first token prediction. So for that we have to compute the entire key and the value. There is no storing which has Happened
yet. Only once all of these prompts are processed we know the keys and the values and we can cache them. So this first stage where all the tokens are processed and uh we have just we are just going to infer one new token that's called as the prefill stage. That's called as the prefill stage. Now in the prefill stage you get one new token which is appended again to the prompts. Uh and once that new token is appended to the prompt then we are going to predict further new tokens after that point and we are
going to reuse the key value cache. This stage number two after the prefilled stage that is called as the decoding stage. So very simply put in the pre-filled st in in the decoding stage all the new tokens are predicted. In the prefill stage the key and the value cache of the prompt is stored and reused. Whereas in The decoding stage new token prediction actually happens. So when you uh when you saw here the waiting Q is prefill versus decode. Uh it can be either of the two things right. Let's say you have multiple prompts are
being processed together by the VLM. For one one prompt prefilling might have been completed and now that for that prompt we are in the decoding stage whereas for another prompt which might have just arrived that prompt might still be in the Prefilling stage. So it depends and remember priority is always given to decoding over preill. I hope all of you have understood the difference between pre-filling stage and decoding stage. For now you can think of prefilling stage as just getting the key value cache and decoding stage as generating new tokens one after the other. Now
you might be thinking that where is this key value cache actually stored and Now we are getting to the crux of uh how the GPU vramm is utilized by VLF. So when I said that let's say you get these four tokens and you compute their key and the value matrices I I mentioned to store these matrices right where do we store these matrices so key and the value matrices computed in each layer when I say each layer it means each transformer layer over here they need to be stored so here is where one concept Needs
to be introduced which is called as blocks. So key and the value matrices which are computed in each layer are stored in something which is called as blocks and this is how one block actually looks like right. So the number of tokens usually is taken to be around 16 and the number of columns here are equal to the keys dimension. The number of columns here are equal to values dimension. So the number of prompt tokens actually can be more than 16 also. In our case, we have just looked at four tokens here. The number of
input tokens can be more than 16. Then they will just carry forward to the next block. In one block, we only have space to save 16 tokens. So the key matrix has 16 rows and number of columns equal to the total embedding dimension. And the value matrix has 16 rows. And the number of columns equal to embedding dimension. Now for the number of columns since we are using multi head attention, it's divided into heads. It's split across heads. So we have head one, head two, we have head one and head two. So the more formal
way of representing the number of columns is number of heads into head dimension. number of heads into head dimension and number of rows are equal to 16. This is a number which is chosen by default. Now every transformer layer will have these KV blocks. So you can think of these blocks as memory they will be these blocks are specially made to store the key value key and value matrices. So for example, let's say if transformer one has four such blocks. Transformer 2 will also have four such blocks. Transformer 3 will also have four such blocks.
Transformer 4 will also have four such blocks. How many maximum number of blocks we can have? We are going to see that. But now if you go back to the Code, you see here the CUDA blocks. This is where the concept of blocks actually comes from. So blocks here refer to those blocks where KV KV matrices are actually stored. Right? So each transformer layer will have these KV blocks. Now let me actually make this a bit more concrete and show you how exactly the KV blocks are populated for our prompts. So we have three prompts
here, right? P1 has five tokens, P2 has seven tokens and P3 has two tokens. So P1 token length is five. Uh so since the P1 token length is five here you can see block number one will be allocated to the first prompt and five tokens will be filled. For P2 the token length is equal to 7. So block number two will be allocated to P2 and here seven rows will be filled. and for P3 block number three will be allocated and two rows will be filled. Now this block one block two block three Allocation will
happen for all the transformer layers. So if P1 is allocated block number one here P1 will also be allocate allocated block number one here P1 is allocated block number one here and here. Similarly, P2 which is the second prompt will be allocated block number two in all the transformer layers and P3 which is the third prompt will be allocated block number three in all the transformer layers. Why do different prompts have Different blocks? Because we don't want attention scores to be calculated between the different prompts, right? We want them to be separate. So we don't
want P1 as well as P2 to be in one block. Eventually the K and V blocks are used to calculate the attention scores. So it's better to keep um one prompt in one block and other prompt in a separate block. Now in the worst case or not in the worst case in a different scenario, what if P1 had uh 18 Tokens? What would have happened in that case? You can pause this video and think about it. If P1 had 18 tokens, what would have happened is that block one would be completely filled by P1 and
block two, two rows would have been allocated to P1 and then P2 would have been moved to block three and then P4 would have been moved to block number four. Okay, so just remember that the maximum number of tokens which can be in one Block is equal to 16. So P1 has five tokens, P2 has seven and P3 has two. And each prompt just needs to use one block over here since all of them have less than 16 tokens. So the total number of blocks used per layer is equal to three. And since we have
four layers with three blocks per layer, the total number of blocks is 3 into 4, which is equal to 12 blocks are being utilized right now uh by VLM. We are going to see exactly how it Happens in the VLAM machine. Right now I just want to want you to conceptually understand how when when let's say tokens come into the VLM engine. Why do the tokens need to take up space think about this right? The tokens have come come into the picture and you want to predict the next token. It's very difficult to understand why
this task would take up space. The one of the major reasons why this task tips takes up space is because you cannot compute The next token unless you have stored the key and the value cache somewhere. So you need blocks where the key and the value cache is stored and these blocks these blocks require memory because uh as we'll soon see every block takes up some memory will calculate how much memory that is taken and that sits in the GPU VRAM. Okay. So basically every block every block takes up space in the VRAM. So if
you look at the GPU, let's say This is the entire memory of my GPU. Uh very broadly speaking, think of this as land. Very broadly speaking, this land is divided into four parts. One major component is available GPU VRAM for the KV cache which I've shown in green. And this available GPU vramm for the KV KV cache is taken up by block. So this is block number one, block number two, block number three, block number four, etc. Right? So every block here which is Filled by the key and the value parameters takes up space in
GPU VRAM. So whenever a prompt token comes in and we want to infer the next token, first we have to see how many blocks need to be acquired to that how many blocks need to be allocated to that prompt. Here we see that these three prompts need three blocks per layer and there are four layers. So they need 12 blocks. Then 12 blocks in the GPU VRAMm are allocated. So this is 5 6 7 8 9 10 11 12. 12 blocks In the GPU VRAM are allocated for processing these props. Okay. So every green tile
which I have shown here is essentially one block. And what are the other tiles in the GPU VRAM? Well, apart from the KV cache, the model weights also need to be stored in the GPU VRAM itself. Then there are something called activations. So when we do back propagation, we need to save activation states that need to be stored in the GPU. And then there is also something called non-torrch memory, which is essentially optimizer states. Those also need to be stored in the GPU VRAM. So if you see everything really depends on the GPU V RAM.
So here you see model weights take 2GB. So that's 2GB of GPU VRAM which has been allocated to model weights. Then we can see here non-torrch memory takes 0.05 GB. So non-torrch memory is this which Takes 0.05 GB. And third thing is PyTorch activation peak memory takes 3GB. So this takes.3 GB. Right? All the rest of the memory as it's written here, the rest of the memory reserved for KV cache is 10.86 GB. So this rest all this rest of the memory which is reserved is for KV cache. That's the maximum portion of the memory.
So if you take a closer look, this is around 10 GB in our code which we just saw. Then the Model weights take around 2GB. The model weights take around 2 GB. The PyTorch the non-Torch memory is 0.05 and PyTorch activation peak memory is30. So PyTorch activation peak memory here is 30 GB. And the non-torsh memory is the smallest which is around just uh 50 0.05 GB. So GPU V RAM is one of the most precious Resources which we have and VLM tries its best to optimally use this resource where it allocates a lot of
space for the KV cache. Okay. Now let us think about um now while we are on VRAM actually let me show you one more thing. If you go to runpod and if you want to actually use a GPU or allocate a GPU for your project you can see that when you are actually selecting a GPU one of the most important parameters is VRAM. So this is 141 GB of VRAM 48 GB of VRAM. The more expensive your GPU is, the more VRAM it will have. That is the most important parameter which you should look for.
So here we were loading a very tiny model, right? So overall it took around just totally 12 GB of VRAM. If you see 10 + 2 around 12 GB of VRAM so any small GPU would work very well. Even a A40 would work very well here. Even a T4 GPU would actually work very well for the particular case which we are trying. Even an RTX A4000 will actually work because it just has 16 GB of VRAM and we are anyway taking only 12 GB of VRAM. Now let me actually demonstrate to you where these numbers
come from. Why do we have a maximum of 3 2 3 5 7 KOD blocks and what are the CPU blocks. So I told you currently that the GPU VRAM is divided into blocks, right? How many maximum number of blocks we can have? Let's just check. So first what we have to do is that we need to Uh find out the memory which is taken by each block. So if you look at one block, how many total number of parameters are there in one block? So we have the number of tokens uh which are the
number of rows multiplied by the number of columns which are the number of heads into head dimension and we have the number of bytes per parameter. So if it's a a 16 bit floating point or 32-bit floating point etc. So the number of uh Each block memory is just two because we have key and value. So two multiplied by uh let me actually reduce the thickness a little bit. So the memory taken up by each block is two because we have key and value. Then these are the number of rows. These are the number of
rows, number of tokens. Then number of heads into head dimension is the number of columns. So the total number of parameters here and here. Until now we have covered this much. And Then we also need to multiply by the bytes per parameter. So this each block memory is given by this formula. That will be the memory taken by each block in bytes. So for our model which we have used over here which is the tiny llama you can check out the configuration of tiny lama on hen face itself but you'll see that the number of
hidden layers or the number of transformer layers is 22. Number of Attention heads is 32. Uh the head dimension is equal to 64. Okay. And here they are using something like grouped query attention. So effectively the number of headers is equal to four. So the bytes per token is equal to two multiplied by So we have two here. It's the same two multiplied by uh number of layers which is equal to 22. Uh this is then multiplied with number of heads which is four head dimension is 64 and number of bytes per element is two
so if it's 16 bit floating point we have two bytes that's why we have two here so this is 22 kilob per token but remember we have still not multiplied it with 16 so the total number of bytes per block turns out to be around 34 mgabytes per block okay and the total budget which we have for the KV cache as mentioned over here It's 10.86 GB right so if the total budget for the KV cache is 10.86 GB and each block takes 34 mab you just divide these 10.86 is gigabytes divided with 34 megabytes
and you'll see that we should have a total of 32350 KV blocks which can be allocated and that's the same number which you see over here we see a total of 3 2 357 CUDA blocks which are allocated but why do we need CPU blocks That also needs to consider so CPU blocks are sometimes needed when some parameters need to be offloaded to the CPU view from the GP. Uh there are many instances when this might be needed. So for example, when you want to do gradient uh uh back propagation, right? You can store the
activation states in the CPU and then you can bring them back to the GPU when needed. So you need some CPU space and the default CPU space is 4 GB per GPU in uh VLn. So we have each block takes around 34 mgabytes right. So we have 4GB. So 4 divided by.34375 that's 11 915 block. So since we are only considering one GPU here we have 4 GB of CPU swap space available and each block takes 34375 MGAB. So the number of CPU blocks is 11 915. That's where these two numbers are actually coming from.
Uh where were the numbers? Yeah, these Two numbers 11915 CPU blocks and 32357 CUDA or GPU blocks. Okay, so I hope that until this point all of you have understood first of all that uh the tokens are in the waiting queue. Remember that in the waiting queue there are two types of requests. Either it's a pre-filled request where KV cache needs to be created in the first place and decoding has not started and the second stage is decoding request where KV cache is created and now the KV Cache will be reused. Remember that one price
which we need to pay for inference is that we need to store the KV cache. Where is the KV cache actually stored? The KV cache is stored in GPU VRAM. There is space allocated in GPU VM for storing the KV cache. And this store this space is allocated in the format of blocks. What does each block look like? Each block looks like this which has space for 16 tokens uh for key and the value matrices. So the formula for the memory taken by each block is 2 multiplied by the number of tokens multiplied by head
number of heads multiplied by head dimension multiplied by bytes per parameter. So if it's 16 bit floating point it's two bytes. It's 32-bit floating point it's four bytes. That's the memory taken by each block. And based on the total GPU memory available to us, we can compute the number of QA blocks which is the GPU pool. And we can compute the number of CPU blocks. That comes out to be 11 915. Remember that the default CPU swap space in VLM is 4 GB per GPU. Why is this swap space needed? because sometimes parameters are offloaded
to the CPU and then brought back to the GPU such as when calculating the gradients during back propagation etc. So during forward pass the activations uh need to be stored somewhere. So they can be stored in CPU and brought back to the GPU when we are doing the gradient Calculation in the backward bus. All this information was very important for you to understand because uh otherwise it's very unclear to know first of all what is uh prefill what is decode then how exactly is the uh memory allocated. So first of all for people it's very
difficult to understand that if I'm just predicting a new token why do I need memory? The memory is needed for having these KV caches and based on The prompt you need to decide how many blocks you need to allocate. So as we have seen we have three prompts right each has less than 16 tokens. So each prompt can just take one block. So we have one block for prompt number one. We have one block for prompt number two. We have one block for prompt number three. So three blocks are taken per transformer layer. And we
have four such transformer layers. So the total number of blocks which are allocated are only 12. And remember the maximum number of blocks which can be allocated is 32 350. So this is definitely a very simple calculation which we are doing right now. Now that we have understood what's the difference between prefill and decoding and uh how tokens need KV cache blocks to be stored in memory. Let's actually move to step number three. So once the tokens are in waiting queue, step number three Is the prefill phase. Now one terminology which is used in VLM
is that after the prefill phase when the tokens move to decoding they are called as running requests whereas while they are in prefill phase it's still called waiting request. So in the prefill phase what actually happens is that first of all VLM looks at the prompt. It looks at the three prompts and then it sees that the total Number of tokens are 5 + 7 + 2 and that adds up to uh 14. These are 14 number of tokens and there is a maximum number of tokens which can be processed in one iteration through ELL
and that's usually equal to 2048 that's called as the token budget. Now the number 14 is way less than the token budget. So all of these can be processed together in that iteration. So here is where two concepts come into the picture. First is called as Continuous batching and second is called as page KV cache. The way I have understood these concepts both of them are interlin with each other. But let's now understand these concepts and we will naturally understand them based on what happens to the tokens. So now again put yourself in the shoes
of the tokens. uh VLM engine has decided to process all these prompts at once because the total length of the tokens is less than the maximum token budget. So VLM forms one Continuous batch of input tokens where it takes the token ids from all the three prompts and then it pulls all of them together. This is the main essence of continuous batching. Everything goes together into one batch and the positions are also me mentioned here. So 0 1 2 3 4 these are five tokens from the first batch. These are seven tokens from the second
batch and the these are the two tokens from the third batch. Okay. Now in the next step we have already Seen what happens over here. In the next step, what is going to happen is that since it's a pre-fill uh phase, we are going to see how many blocks we need to allocate. Okay. So, uh essentially what we are going to do is that we are going to look at the number of tokens in each prompt and we are going to allocate the blocks accordingly. So for example, the first prompt has five tokens. So it
Just needs uh it will be alloc it will fit in block number one since the maximum length is 16. The second prompt has seven tokens. So it will be allocated to block number two. So the here the length is seven. Here the length is five. And the third prompt will be allocated to block number three where the length is equal to two. Now one key thing to note here is that on the CPU there is a queue of free blocks which is Maintained for different layers. So here we are assuming we have four layers right
transformer layer 1 2 3 and four and we have seen the maximum number of blocks across all the layers that's going to be 3 2 3 5 0 across all the layers. So per layer the maximum number of blocks is going to be 32 350 divided by the number of layers. Right? So VLM actually knows the maximum number of blocks which can be there per layer. Here we Have just assumed that each layer will have four blocks and on the CPU there is a list which is maintained which is essentially called as the free block
Q. So on layer 1 all the blocks will be free initially before the tokens come into the picture. Even for layer 2, layer three and layer four all these block number one, block number two, block number three and block number four will essentially be free. Right? But the Moment different blocks get allocated. So for example, now prompt one has taken up block number one, prompt two has taken block two and prompt three has taken block three across all the layers. Right? So now the free block if you see the free block for layer 1 is
only block number four because block number 1 2 and three uh block number 1 2 and three are allocated. Block number one is allocated to prompt number one. Block number two Is allocated to prompt number two and block number three is allocated to prompt number three. So only free block across all the layers is now block number four. So on the CPU the free block Q changes for layer 1 it's four. For layer 2 it's four, layer three it's four and layer four is four. And there is also one page table which is m which
is maintained. The page table essentially points out to which block the current prompts are Using. For example, the sequence one is using block number one. Sequence two is using block number two and sequence three is using block number three. Okay. So page table is actually a concept from data structures where we just create pointers essentially uh which contains essentially which is the block which is allocated to a particular uh prompt. So the page table essentially does not take any memory that's on CPU. It just contains a list of pointers. So here this number one over
here block number one is actually taken up is actually taking up space in the GPU VRAM. Block number two is also taking up space and block number three is also taking up space. But this table itself it just a table of pointers and this is called as a page table. So if you search about uh page if you go to Google and if you search About page table data structure you will see that yeah this is a data structure in a computer's virtual memory system to map a process virtual address to their corresponding physical address
in the RA. So here what's the virtual address and what's the physical address. Physical address is the block number one, block number two and block number three which are actually taking up space in the GPU as we have seen over here and the virtual address is just this list Which is maintained on the CPU. Now both of these things which I'm showing you here right now both of these things this page table and the free block cube are extremely important because think of this as the manager which tells VLLM which block is free which block
is underused. So whenever a new prompt comes the manager can send that prompt to the particular block which is free. uh this mechanism right here this is Called as paged KV cache the reason it is called as paged KV cache is because you we are using the paged table data structure here and it's one of the most important uh pieces to understand in an inference engine if this paged KV cache was actually not there then KV caches just randomly take up huge chunks in the memory and we have no clue when one prompt is processed
Where does the other prompt need to be sent to etc. But now that this list is maintained we can just take a look at the free block Q and uh we can know which block is free. So the moment prompt one is let's say processed then see then block number one will be free and then it will be added to all the layers. It will be added immediately and that makes VLM extremely efficient at processing new prompts and also multiple prompts at the same time. Okay. Uh yeah. So in the prefill stage what has happened
now is that layer 1. So this is layer 1 block one. This is layer 2 block one. This is layer 3 block one. And this layer 4 block one. And I'm showing this only for the first prompt. Right? Now the first prompt has taken up the KV cache in block one across all the layers. Right? So now that the KV cache is stored over here uh we can predict the next token because Now the key and the value matrices are stored and they are computed. So through this mechanism which I have mentioned to you over
here we go through the different transformer layers and we predict the next token. So for prompt number one uh for prompt number one the next token is predicted. For prompt number one, it goes through all of these layers, layer 1, 2, 3, and four. And then we get the next token prediction. Similarly, for Prompt two and prompt three, the next token will be predicted. This is what happens in the prefilling stage. So, one new token is predicted for uh as you can see over here, one new token is predicted for prompt number one, one new
token is predicted for for prompt number two, and one new token is predicted for prompt number three. Now all of these three prompts have finished their prefilled stage. They have finished their pre-filled Stage and now we go towards the decoding phase. Um in the decoding phase what happens is the VLM scheduleuler now moves all these three requests to the running que. So please keep in mind here that waiting Q is dedicated for prefilling and when it's mentioned running Q it means that the sequences have been prefilled their KV caches exist in the memory and now
we are into the decoding stage where we are Going to decode or produce one new token each time let's see how that is done right now. Okay so this is prompt one this is prompt two and this is prompt three. Prompt number one has taken a block number one and it has predicted one new token. Now for that one new token which has been predicted the uh KV cache will be updated since one additional token now has been predicted over here. So let's see how new tokens are now Generated. Uh let's say we want to
produce one new token. You can see that earlier there were five tokens in prompt number one, right? But now new token has been predicted. So new six token have been added here. So there are six tokens here now. And now my KV cache has actually six rows because of the six tokens. And then I go through this entire uh procedure all of these different blocks and then I do my next token prediction again. Now remember Here that the blocks which are shown in green they don't need to be computed again because they are already stored
in my KV cache. That's the advantage of KV cache. We don't need to do too many computations. So this is for prompt number one. For prompt number two again there were seven tokens but now one more new token has been added. Right? So prompt number two also goes through layer 1, layer 2, layer three and layer four. And remember That it has taken up uh block number two in all the layers. Prompt one has taken up block one but prompt two has taken block two and all the green rows here don't need to be recomputed
again. Just one new row is the key value row for this new token and this prompt is processed through all the different layers and then we get the next token prediction for the second prompt. Similarly, now when we go to the third prompt, It has taken up space in block number three in all the layers essentially. And earlier this prompt only had two tokens, but now one more new token has been added. So the KV cache corresponding to the two tokens doesn't need to be computed again. It's shown in green. Only the key value row
for the new token needs to be computed and then we get the next token which is predicted. Okay. As always, you need to keep an eye on what is happening on the CPU. On the CPU, we can see that again uh block number one is still under utilization. Block number two is under utilization. Block number three is under utilization. And the free block is only four. So at the end of the first iteration, all three sequences are still active. When does a sequence become inactive? When it has reached an end condition and that can be
prescribed by the maximum number of new tokens. So when we have a maximum num new tokens here when let's say for Prompt one 50 tokens have been generated then that's an end condition then the sequence is no longer active and only then the block for that sequence becomes completely free. Okay, now pay careful attention here. Although one new token has been generated for all of these prompts, the same block can still be continued to use because there is a lot of space which is remaining in each block. No new block needs to be Allocated. But
if some block goes beyond the 16 tokens, then we'll need to allocate new blocks. For that, we'll need to see the free block Q and then we'll get a new block from there. uh but for now each sequence block has a lot of room. So no new blocks were actually added. So this is one new token which is generated. Now we'll come to the second token which is generate uh another token to be generated. So the previous token Which was generated is appended to all these prompts as we can see. And again here uh the
key value cache has now two red rows because now two new tokens have been generated. You can see that for all the prompts. And then the same process actually happens for all the different prompts. Again they go through the different layers. They go through all the four layers and then the new token is Predicted. The new token is predicted for all the different uh sequences. Now pay very careful attention here. If some sequence reaches the end of produces the end of sequence token, uh that sequence needs to be terminated. So the second sequence has reached
the end of sequence token, right? So that sequence is terminated. So it's immediately removed from the page table and it's added to the free block Q. So see now when if any new prompt is there in the waiting area, If any new prompt is there in the waiting area and it needs to be prefilled first, we see now that two blocks are free. Block number two is also free and block number four is also free. So VLM will smartly allocate these two blocks for the new prompts which are coming in. So that is the beauty
of actually paged KV cache or it's also called as paged attention. Freed blocks can immediately be reused essentially. So if you take a look at VLM, so it's Called as paged KV cache. It's also referred to as paged attention by the way. But that's the main advantage of paged attention. Okay. So the engine proceeds to iteration 2, three, so on as needed to generate more tokens for each request. So now you can see here that how new tokens are generated each time. When a new token is being generated every single time, you know that it
is being allocated some block. And what's the Stop condition? In this case, the stop condition is 50. So the moment the stop condition is reached the block which is allocated uh to this prompt will all be freed and the new prompts can take uh take that space. I want to mention one more thing about continuous batching continuous batching. So in static batching what happens is that in static batching if you see over here Let's say we have one input sequence the second input sequence third input sequence fourth input sequence right and the size is actually
the same over here for all the input sequences. So this input sequence has generated two tokens and it has stopped. Now all this space is still vacant right? it cannot be taken up by any other prompt. Similarly, this third sequence has generated one new token and it has stopped. All this other space is again vacant. So that There's a lot of space wastage in static batching. In continuous batching what happens is that whenever the first sequence finishes that block is freed and then other sequence can immediately start generating its new tokens. Right? So there is
no nothing sitting idle in continuous patching. There is no idle memory also. there is no memory which is uh not being used at the same time. It's an extremely efficient system and the way continuous batching actually can Work so efficiently is due to this paging mechanism which is there. We need to maintain uh which blocks are being utilized by the different prompts and we also need to maintain a system to understand what are the free blocks. This is the paged attention or the page KV cache and uh continuous batching is what I just showed you.
The whole input sequence is um actually put into one batch as we can see over here and then we move uh forward towards the Inference. So I hope in this lecture you have got a visual introduction to what exactly happens to a prompt when it passes through the inference engine. Now just close your eyes and think if the picture is clear to you. Right? The prompt comes in, it's converted into tokens. That's the first thing. It enters the waiting queue. Then we have to decide whether to go with prefilling or decoding. If the prompt has
not reached the decoding Stage, it will definitely go to prefilling first. Right? In pre-filling what happens is that uh first we look at the total number of prompts and we look at the total number of tokens and we see whether the total number of tokens are less than the token budget for each iteration of VLM. By default the token budget is 2048 tokens. So in this case the total tokens are 14 which is way lesser than 2048. So they can be processed all together at once. Maximum Number of tokens which can be processed all together
at once is 2048 by default. Now all these tokens are processed together. So how does it work? You need to first create a continuous batch of these tokens and then you need to see for each prompt how many tokens are there and then based on that you decide the number of blocks which need to be allocated. Each block takes 16 tokens. So if the first prompt has four tokens, it can do with one block. If the second Prompt has seven tokens, it can do another block. If the third prompt has two tokens, it can do
a third block. If some prompt has 18 tokens, it will need two block. It will need two blocks. So it will take the 16 tokens in the first block and two tokens in the second block. Remember that no two prompts can share the same block. Why is that the case? because we need to keep the attention mechanisms of different prompts separate from each Other. We don't want any interaction between the prompts at all. So we form this we allocate blocks for each prompt and once the blocks are allocated then first in the prefilling stage the
K the key value cache is actually computed and it's stored which is shown in the green color here. All the green blocks here are during the prefilling stage. That's block one, block two, block three for layer 1. The same thing happens in all the different Layers. Now while this is happening in the GPU, actual memory is being allocated in the GPU. Right? As I mentioned to you over here, there is also another table which is being maintained on the CPU. And in that we have two things actually. We have a page table data structure which
actually maintains which sequence is allocated which block and that block is actually taking space in the memory. And then we also have a free block Q which me which Mentions or maintains a list of blocks which are free. This helps the uh VLM engine manager to actually know when a new prompt comes which are the free blocks which can be allocated to that new prompt. For example, uh yeah and then once pre-filling is done we have one new token which is generated and in the decoding phase we keep on generating new tokens which are shown
by this red color over here. the key value cache goes on updating and if We need more blocks, we can allocate more blocks. For example, in this case, uh in our example, we generated 50 new tokens, right? So, it's impossible to fit all of that in one block. You'll need at least three to four new blocks for each token because uh each block only has 16 tokens. Now, remember, we have a huge number of blocks. We have around 32,000 blocks. So, for the simple prompts which we are considering, it will not be an issue at
All. In fact, many hundreds of prompts can be run parallelly on VLL because it can efficiently allocate blocks to each prompt. There is also this thing called CPU blocks. So sometimes uh parameters from the GPU need to be swapped to the CPU and then brought back to the GPU. especially during let's say back propagation the forward activation par functions or activation values are stored on the CPU and brought back to GPU During back propagation. Um all right and then we keep on generating new tokens until some end condition is reached. That end condition might be
when an end of sequence token is reached or the end condition might be the maximum number of tokens which we have specified to be generated. So when the end condition is reached that particular block is freed and that freed block is again added to the queue of the free blocks over here right and then whenever A new prompt comes in VLM knows what to do with that prompt. So VN is so efficient that some blocks might be used for decoding, some blocks might be used for prefilling exactly at the same time and that's why it
is so fast at uh analyzing different prompts. So utilizing GPU memory so efficiently also reduces the GPU costs and that's why inference costs are getting lower and lower and lower. All these innovations which we just saw right now they are Definitely being implemented by inference engines of all modern players such as Gemini, OpenAI or Claude. And there are several more things to come. We only discussed about paged attention and continuous batching. Right? In the next lecture of this series, I'm going to discuss prefix catching caching uh speculative decoding and then I'm also going to discuss
multiode dynamic serving etc. Several new things are planned but for before Reaching that first it's very important to understand just two concepts spaced attention continuous batching and prefill and decoding and I hope I have I'm a I have been able to convey this to you in a visual manner in today's lecture so thanks a lot everyone I hope you appreciate the beauty of so many details which go through a prompt which happen to a prompt as a prompt goes through the inference engine After this lecture As an exercise, just close your eyes, put yourself in
the shoes of the prompt, and think what happens as it goes through the inference engine. Thanks a lot, and I'll see you in the next lecture.