[Música] Olá bom dia a todos então hoje a gente dá continuidade a capacitação acerca do módulo de classificação de assuntos né conforme nós já tratamos tratamos ontem né da parte do do processo que foi utilizado para estruturar esse modelo de classificação né Então até a gente seguiu de forma mais teórica né abordando os pontos relacionados ao processo da classificação e o foco de hoje é tratar um pouco sobre a implementação ou seja numa possibilidade de retreinar eh os organizamos os códigos preparamos de modo a deixar disponível para vocês para essa possibilidade né de retreinar o
que a gente até já tinha apresentado ontem mas para que possa eh dar al um contexto e darmos continuidade tá eh conforme a a estrutura do classificador que nós exibimos Ontem nós eh disponibilizamos o código aqui no Git do do CNJ daí eu vou já mostrar lá o Git O que é que vai estar disponível tá E esse esses esses módulos de implementação foram divididos conforme as etapas do classificador mas especificamente para relembrarmos nós temos aqui um módulo que faz o pré-processamento do texto que é eh aplica especificamente a função trata texto nós temos um
outro módulo que codifica essa petição inicial conforme o tokenizador do modelo de linguagem nós temos um outro mdulo para organizar os dados né pré-processados anteriormente aqui pela função trata texto e codificados Pelo modelo de linguagem que vai fazer uma organização estruturando esses dados em um Data Frame e a depender de qual abordagem nós queremos utilizar Nós temos duas abordagens do classificador uma eh utilizando uma uma abordagem de classificação em grupo daí se essa foi escolhida eh executa-se esse módulo Run classificador grupo ou se preferir utilizar a abordagem hierárquica utiliza-se aqui essa esse módulo Run classificador
hierárquico então Esses são os módulos que nós temos à disposição né do do da classificação né eles são executados nesta ordem tá pré-processamento do trata texto em code Bet get data e aí na sequência Qual é o classificador que vai ser utilizado para treinar tá bom daí na sequência n vou mostrar aqui o Notebook que está disponível também lá no Git eh que faz uso desses módulos tá Eu até já deixei aqui executado cada uma das células o objetivo aqui aí eh passando por cada cada uma delas para que a gente possa eh compreender né
a utilização desses desses módulos de implementação eh como nós falamos ontem em relação à estrutura do processo de classificação a primeira etapa que nós seguimos é o pré-processamento do do texto da petição inicial não é isso então nós fizemos aqui a importação Daquele mesmo código né que eu mostrei lá para vocês eu tenho aqui no Drive então aquele mesmo código a gente fez aqui a importação para poder fazer o uso e a gente chama aqui o pré-processamento trata texto que é aquele primeiro módulo Zinho que o objetivo vai ser o quê obter os textos né
de um conjunto de dados e aplicar a função trata texto de modo que nós tenhamos esse texto tratado a partir das funcionalidades que o trat texto vai aplicar né como a gente viu out o trat texto ele faz a correção e de formatação o tratamento das siglas das abreviaturas das legislações então conforme as funcionalidades presentes dentro do do trat texto esses textos das petições iniciais Eles serão eh tratados né com essas funcionalidades tá Daí como o parâmetro esse módulo vai receber o pef do trat texto né a gente mostrou lá no no Git que a
gente já pôs lá né o a o o a pastinha com os códigos do trat texto Então o um parâmetro de entrada é esse pef outro parâmetro de entrada é o pef do dataset n que a gente vai querer fazer a aplicação do trat texto a gente aqui está considerando que esse dataset Ele Virá em um csv e a estrutura dele é ter o texto né para para ser tratado tá aí a partir desse desse texto é aplicada essa função trata Tex para sair o texto tratado e também um outro pef de saída a gente
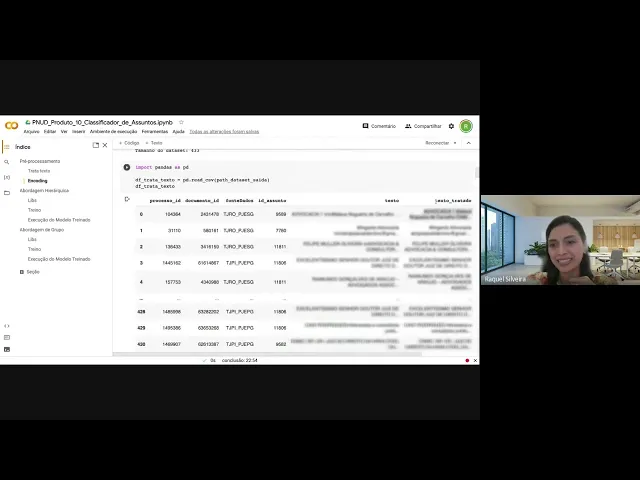
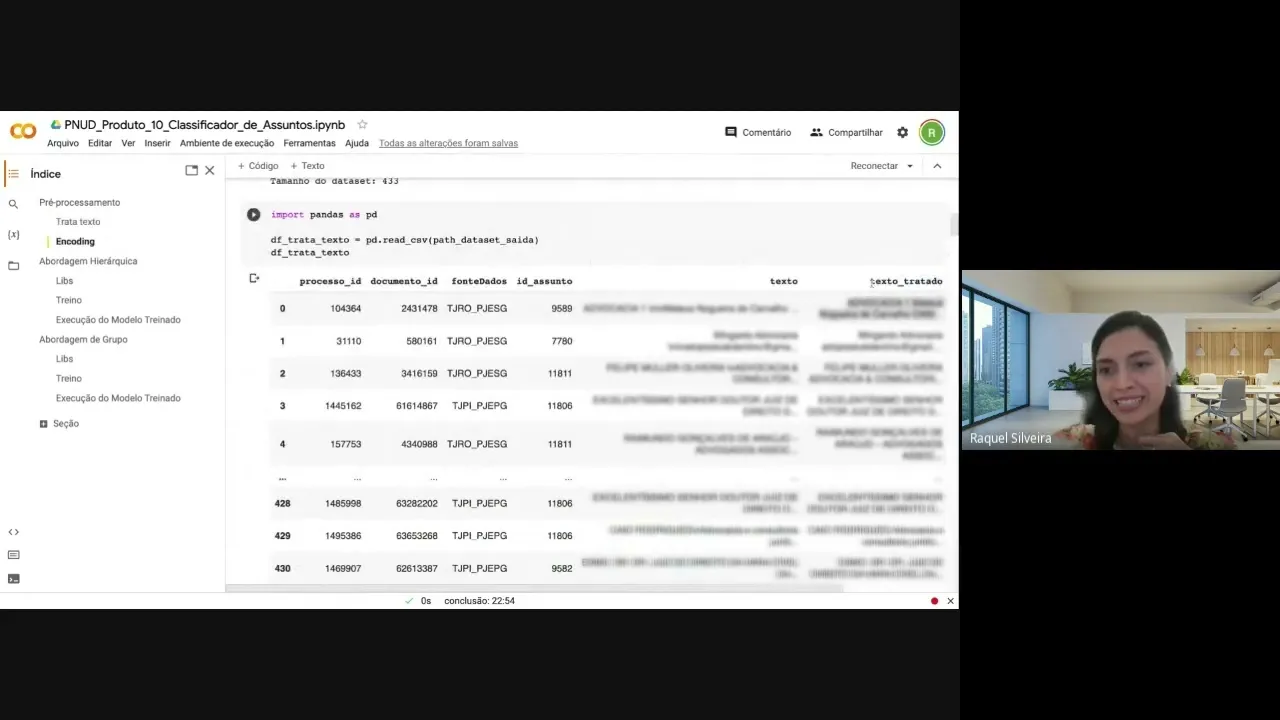
aqui considera que recebe um csv de entrada aplica a função trata texto e nesse pef de saída né ou seja vai ser criado um outro arquivo csv adicionado uma outra coluna que vai ser a coluna de texto tratado tá então aqui estou usando aquela mesma amostra né que que colocamos lá no no Git tá que é uma amostra de 433 dados eh e após a aplicação do TR texto né chamando aqui essa função nós vamos ter eh esse arquivo né PIS aqui só paraa gente poder visualizar como é que sai com todas as colunas que
já tinham né no no na amostra mas esse texto tratado tá então a estrutura né O que faz acrescentar com a utilização dessa função é uma coluna A mais aqui no csv com o texto tratado que é justamente a aplicação desse texto após a função trata texto tá eh a estrutura do arquivo dessa amostra dataset que está disponível vai vir né com o ID do processo com o docum com ID do documento com a fonte de dados e com o ID do assunto esse ID do assunto aqui como o assunto principal tá esses outros aqui
são utilizados mais para estruturação né do qual é a fonte de dados porque a gente separa lá os tribunais né então assim se não se não tiver esses dados não haverá problema para eh o treino uma vez que a gente não utilize as fontes separad da mente Ok então depois da da aplicação do trat texto pela sequência né dos Passos do classificador nós seguimos para a codificação O objetivo dessa codificação É o quê É pegar esse texto tratado e aplicar o codificador do tokenizador do modelo de linguagem tá daí nesse momento aqui no no notebook
do cab a gente até incluiu Quais são as bibliotecas eh requeridas né para cada um desses módulos então Quando nós vamos aplicar o tokenizador né a codificação por meio do tokenizador nós precisamos do Transformers tá então a gente precisa fazer a instalação do Transformers para utilizar esse esse módulo Zinho de codificação então instalamos aqui o o Transformers tá e utilizamos essa função inha em cod Bert né Como Eu mencionei agora a pouco o que que ela vai fazer vai pegar o texto tratado vai aplicar no tokenizador do modelo de linguagem e vai retornar Quais são
os ids de cada um dos tokens e as máscaras de atenção de cada um dos tokens tá então o objetivo dessa função inha vai ser essa P aqui como comentário Qual é a assinatura da função tá ela tem como parâmetro receber eh o pef do dataset nesse caso Esse pef já é o arquivo csv aplicado o trat texto né que é a saída do módulo anterior né já recebe esse csv a gente passa também eh uma pastinha de saída dessa codificação tá daí aqui vai sair sairão dois arquivos eu vou já mostrar para vocês vão
sair dois arquivos e nós podemos também utilizar aqui como um parâmetro qual é o modelo de linguagem que nós queremos utilizar para essa codificação tá eh o defa desse parâmetro está o ber Timbal certo esse essa é a é a representação do é o ID né do modelo de linguagem do ber Timbal mas aqui a gente pode fazer uso de qualquer outro ou seja se porventura treinarmos um outro modelo né que não o bertim Bal que não libert Pt a gente pode aqui passar como parâmetro esse modelo de linguagem tá então essa função em codeb
ela recebe esses três parâmetros o dataset de entrada com o texto tratado se é importante enfatizar isso porque a codificação ela vai ser realizada em cima dessa coluna tá em cima do treo do texto tratado qual vai ser o a saída né o pef de saída E qual vai ser o modelo de linguagem se não passar vai ser utilizado como padrão aqui o ber Timbal certo eu vou mostrar aqui no eh na execução o que que vai sair tá eh a partir da execução desse desse desse módulo quando executarmos eh serão criados dois arquivozilla de
linguagem e um outro arquivozilla temos aí nesse com esses tokens tá eh Vale aqui destacar que a estrutura do Bert nos permite codificar um texto em até 512 tokens né então aqui a gente começa do zero e vai até o 511 tá então a gente tem essa essa estruturação cada uma das colunas corresponde a um token neste caso são obtidos os 512 primeiros tokens do texto e também uma outra estrutura se dá aqui que o token Inicial sempre vai ser o o 101 e o token final sempre vai ser o 102 né isso conforme a
estrutura é do próprio Bert tá daí os tokens entre 1 e 510 são os tokens eh do texto na sequência ou seja feito o tratamento do texto e obtido aqui os ids dos tokens a gente tem uma sessãozinha aqui para a abordagem hierárquica nós dividimos tá duas sessões né uma para abordagem hierárquica e outra para a abordagem de grupo para a abordagem hierárquica nós temos aqui inicialmente as as bibliotecas que serão necessárias tá Se quisermos executar só esse modulo Zinho do treino por exemplo ou de execução nós vamos precisar instalar aqui o Transformers vamos precisar
instalar aqui alguns pacotes do torche tá tanto esses esse pacote Zinho esse outro pacote Zinho e esse outro tá então precisamos aqui desses três pacote zinhos do torche para fazer a instalação são as bibliotecas requeridas para para utilizar o treino da abordagem hierárquica então instalamos aqui as bibliotecas na sequência vamos fazer aqui e a parte do treino para fazer o treino a gente vai ter aqui alguns parâmetros a serem configurados mas vou chegar aqui logo nas funções que a gente vai fazer uso desses parâmetros tá então inicialmente a gente vai chamar aqui o módulo para
obter os dados esse módulo de obtenção dos dados como nós havíamos mencionado anteriormente o que ele vai fazer é organizar os dados que foram anteriormente pré-processados né por meio da função trat texto e codificados lá eh pelos eh pelo tokenizador né obtendo o id e obt nas máscaras de atenção então aqui a gente vai passar alguns parâmetros Tá eu vou utilizar aqui a assinatura real da função tá que tem alguns valores que são defo eh então nessa nesse nesse módulo nós vamos passar aqui o pef do dataset onde esse PF do dataset vai ser eh
O csv que tem lá eh o texto tratado né Isso vai ser útil para que a gente possa pegar os outros dados que tem o csv Deixa eu voltar lá para cima para explicar melhor então esse csv do texto tratado ele vai ter aqui o ID do processo o ID documento a fonte de dados o ID do assunto o texto e o texto tratado especificamente quando a gente obtém lá a gente já fez o tratamento do texto e já pegou os ids pela função eh de codificação do Bert então naquele momento o que vai ser
útil são esses outros dados ou seja o ID do assunto para que a gente saiba qual é o assunto e assim fazer a obtenção da hierarquia tá porque o texto tratado a gente vai obter a partir dos ids que já foi aplicado pela função de codificação então a gente passa aí esse esse csv né para obtenção desses dados o outro pef que nós passamos é o pef que Eu mencionei para vocês dos assuntos Então esse csv ele aqui está sendo utilizado para representar Qual é a hierarquia de cada um dos assuntos Então vai obter por
exemplo assim ó eu tenho um arquivo aqui eu tenho aqui o o o ID 9589 aqui é um assunto que nesse caso a gente precisa saber qual é a hierarquia dele para poder utilizar no classificador hierárquico então naquele arquivo csv de assuntos vai ter dizendo assim ó esse assunto aqui 9589 o nível um da hierarquia é esse o nível dois é esse e o nível TR é esse então ele faz essa atenção da hierarquia de cada um desses assuntos a gente o utiliza para isso enquanto vai conectando lá vou só já pondo aqui o código
pra gente poder ver a estrutura desse arquivo de assuntos então o perfilzinho dele aqui é esse vou criar uma outra célula ó a estrutur Zinha daqu desse arquivo de assuntos vai estar Qual é o código do assunto certo que é o eh aquele assunto que eu estava fazendo referência anteriormente que vai estar vinculado às petições né Então aqui tem o código do assunto nós vamos ter Qual é a descrição desse assunto especificamente aí na sequência a gente tem esses níveis tá ou seja o nível o nível zero aqui é o que corresponde ao assunto raiz
né E a gente tem a descrição dele depois o nível um que é o nível intermediário aí nós vamos ter a descrição dele o nível dois é o nível na folha e nós vamos ter a descrição dele então a gente vai ter isso para osar todos os assuntos né seguindo essa estrutura aqui tá [Música]