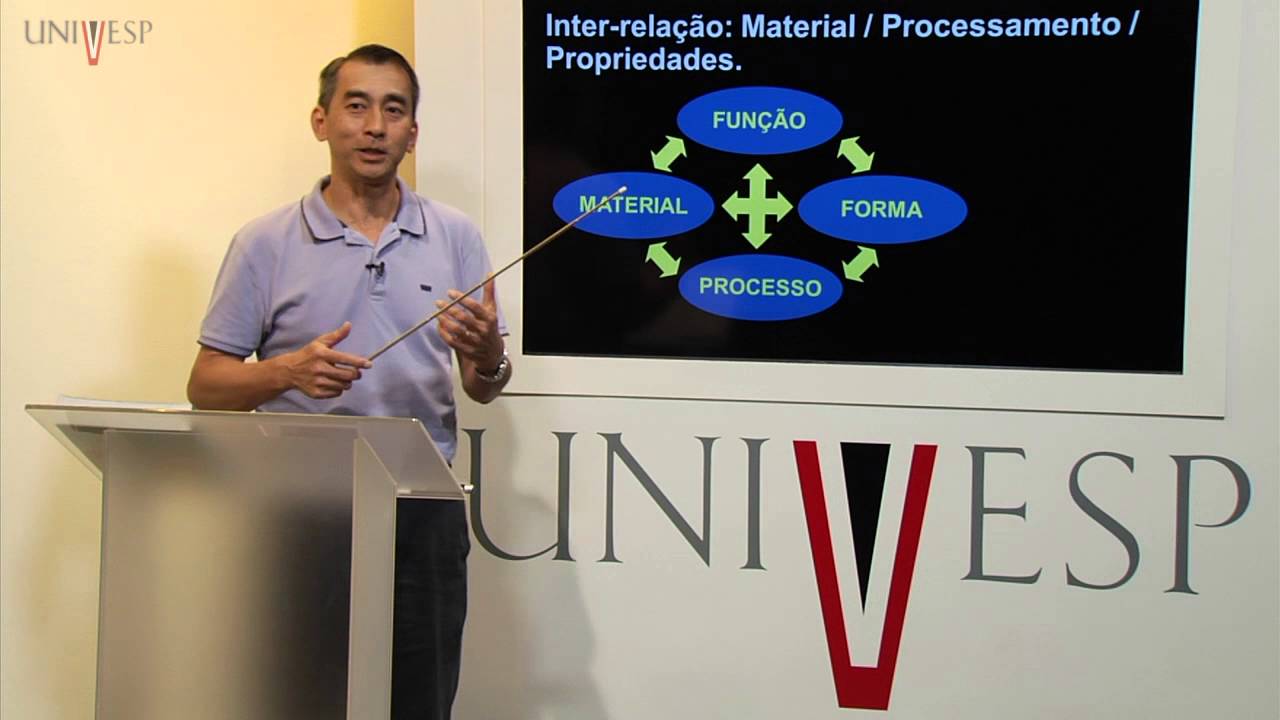
E aí [Música] o Olá bom na aula de hoje a gente vai falar sobre regras de associação Ah tá então as regras de associação são técnicas de mineração de dados para gente lidar com bases de dados são transacionais tá nessas bases o que a gente costuma ter um conjunto de itens que são relacionados ali é uma operação mas que não necessariamente são os mesmos objetos Ah tá então é comum a gente ter esse tipo de base de dados quando a gente fala de dados empresariais Ah tá vamos pegar um exemplo aqui né do que seria
uma situação em que a gente usa a regra de associação então quando a gente faz compras no supermercado a gente está adquirindo vários itens que estão relacionados aquela transação aquela compra é Mas podem ser totalmente diferente de uma outra compra tá então a uma das ideias das regras de associação é tentar identificar itens que tem alguma relação né que estão Associados em transações diferentes e Ah tá então a por exemplo aqui a gente tem uma tabela com uma certa quantidade aqui de transações quatro transações cada uma delas tem um conjunto de itens e os conjuntos
de itens podem te itens em comum ou itens que são totalmente diversos Oi tá aí uma coisa que é um tipo de uso que a gente pode ter para regras de associação é tentar entender o comportamento de compra de cliente ou então a gente pode tentar usar as relações entre os itens para fazer oferecimento de promoções ou campanhas Market e é também para fazer gestão de estoque comprar itens que estão uns Associados aos outros ou até mesmo para fazer uma definição de catálogo Ah tá então um dos objetivos aí não é uma das formas de
a gente olhar essas regras de associação vai fazer a mineração de regras e Associação tá então a gente pode construir essas relações entre os itens que fazem parte de uma mesma base de dados transacional Oi tá aí a gente faz isso gerando regras Entre esses itens né que a gente chama de regras de associação essas regras vão ter então um conjunto que a gente tá procurando observar em relação ao outro conjunto de itens que que a gente espera achar uma relação ou não Tá então são dois conjuntos de itens podem ter um ou mais itens
nesse conjuntos é que a gente vai comparar para verificar se a regra existe ou não Ah tá e aí a gente usa algumas medidas de interesse para avaliar se essas Regras São válidas dentro de uma expectativa ou não E aí Ah tá então vamos pegar um outro exemplo aqui de tabela para a gente tinha aquela tabela de transações e quando a gente vai fazer o uso de regras de associação a gente transforma aquelas transações numa tabela de representação binária tá então a gente pega a cada item presente na transações Coloca ele como uma coluna um
atributo E aí a gente atribui um quando esse tentar presente naquela transação e zero quando não está presente Ah tá então aquela estrutura de regra é representada aqui por x e y na quer dizer que x implica Y tá então o x nesse caso aqui vai ser o antecedente da regra e o y vai ser o consequente tá então um exemplo é a gente pode buscar para uma relação entre a compra de pão e leite né Então nesse caso aqui o pão é a regra o item antecedente da regra leite é o consequente Ah tá
é dentro de uma de uma dos lados da regra Você pode ter um ou mais itens tá nesse caso que a gente tem pão e café implicando em leite bom e Vale observar também que a regra lá ela não é simétrica tá então quando a gente tem aqui no precedente banana e no consequente maçã isso não é a mesma coisa que maçã e banana Essa ordem pode influenciar na essas medidas interesse que a gente vai usar para fazer avaliação Ah tá então dois exemplos de medidas de interesse bastante usados São suporte está o suporte ao
número de transações para as quais uma regra faz a predição correta a gente chama também de utilidade Ah tá outra é confiança a confiança ao número de transações que a regra prediz corretamente para entre as transações para as quais a regra se aplica daí a gente chama ela também de certeza Esse é o problema que a gente quer investigar na quando a gente tá fazendo a mineração de regras de associação é encontrar ali um conjunto de regras que satisfaz um valor mínimo pré-definido de suporte que a gente chama de mim sup e um valor mínimo
para definido de confiança que a gente chama de mim conf tá então a quando a gente acha regras que tem esse suporte confiança mínimo a gente considera uma regra forte Ah tá vale a pena a gente falar também sobre a complexidade de fazer essa mineração de regras de associação da como a gente pode ter vários itens envolvidos ali no base transacional é o número de regras ele vai crescer exponencialmente conforme o número de itens na base Ah tá então a gente em bases reais podem conter ali centenas ou até mesmo milhares de itens aí como
a gente está fazendo a combinação desses itens para verificar regras é o número de operações feitas ali para fazer o processo de mineração pode ser bem grande Ah tá então por exemplo se a gente tiver dois itens numa determinada a base transacional a gente vai ter duas regras uma comparação entre um um objeto precedente aqui no caso você conferência com um quadrado e vice-versa tá já se a gente tiver três itens essa comparação já cresce para 12 regras são todas as combinações possíveis aqui de candidatos aqui há regras válidas Ah tá o total de regras
então é possível ele vai variar aí com o Zene possíveis itens que existem nessa base tá a gente diz que o número né de regras podem ser gerado ele é 3 elevada aê me então M número de itens menos 2 elevado a n + 1 + 1 tá o que significa que por exemplo se a gente tiver oito itens a gente pode ter mais de 6 mil regras e se a gente tiver sem itens distintos a gente pode chegar aí as cinco. 15 vezes 10 elevado a 47 regras então dá para tu me der aqui
do tamanho lá do crescimento que esse conjunto pode ter Ah tá bom falar um pouquinho também sobre o processo de mineração de regras de associação tá então a gente tem algumas etapas aqui que são feitas para gente obter os resultados da mineração tá começando pelo pré-processamento tá então nas regras de associação o pré-processamento geralmente inclui transformar uma base transacional tá naquela base binária né com organizada De forma binária que eu falei anteriormente Então esse é um passo adicional além de todos os outros passos que são feitos no pré-processamento e que a gente a estudante Ah
tá depois a gente parte então no processo para geração dos conjuntos de itens frequentes é a objetivo quando a gente tá fazendo essa busca aí pelos conjuntos de itens frequentes é selecionar um certo número de itens que vai ser usado no processo de busca de regras tá então os itens frequentes são ser aqueles que têm então mínimo um número mínimo pré-estabelecido de suporte tá Então nesse tem uma presença mínima ali na no total da base tá é e qual objetivo então de fazer essa essa atividade é reduzir aquela complexidade né então se a gente consegue
eliminar um conjunto de itens que a gente já já sabe que tem um suporte embaixo a gente diminui a complexidade de geração de regras como tudo é e tal passo seguinte o processo é fazer a mineração de regras com os itens sobraram após análise de suporte tá então nessa fase muitas vezes a gente vai escolher o algoritmo de mineração de regra tá de associação alguns algoritmos de mineração eles são divididos nas duas etapas tá então ele já fazem a verificação ali dos conjuntos de itens e depois geram as regras válidas A então É nessa fase
que a gente vai fazer execução do algoritmo e verificar os resultados obtidos quantidade de regras né e geralmente a gente vai estabelecer ali um padrão tanto de suporte e já Foi verificado na fase anterior quanto o de confiança para determinar quais regras vão ser consideradas como válidas Ah tá aí é a última etapa no processo então fazer avaliação dessas regras utilizando alguns critérios definidos é que a gente vai tratar agora então é para falar um pouquinho dessas Regras eu vou falar antes aqui de uma base na suponha uma base Aqui tem 100 mil registros e
20 atributos tá sobre a venda de equipamentos eletrônicos tá Então imagina aqui que dentro dessa base a gente tem venda de rádios rádios portáteis e de bateria daí a gente quer fazer a verificação aqui de uma regra em que a venda do rádio implica venda de baterias ou pilhas Ah tá então é a gente pode olhar para essa base e perceber que a ocorrência não é o suporte sempre que você vende um rádio Você vende a pilha também então essa ocorrência vai ser de 100 porcento a quer dizer ela tem é uma regra que sempre
acontece né então são dois produtos que estão bem associados quem tá no entanto a quantidade de transações naquela base de 100 mil registros de venda de rádio portátil e apenas em registros né então é o percentual dela na base como todo é pequena então aí vai caber ao analista e ao interessado né nessa análise avaliasse ele quer ou não olhar para aqueles dados e determinar assim o suporte a confiança Ah tá Então dependendo da situação você pode querer olhar esses dados que tem um suporte baixo não suporte de 0,1 porcento porque de repente a confiança
dele é muito alta né de 100 porcento então aí vai depender de caso a caso do objetivo da análise tá Então nesse caso aqui Associação ela é forte né os itens estão sempre relacionados mas a frequência dela é baixa Ah tá então a gente usa algumas medidas de interesse para fazer essa avaliação e elas vão avaliar as características das regras que foram obtidas aí vão determinar também esse a gente vai utilizar um conjunto de itens ou não Ah tá então o que se faz nessa fazer avaliar e a relevância dessas regras para o objetivo da
análise Ah tá as duas mais frequentes são as que a gente já comentou anteriormente um suporte a confiança mas a gente também tem o lift e a convicção EA gente tem um grau de interesse e compreensibilidade então vamos dar uma olhada nessas medidas de interesse Ah tá então suporte o suporte ele vai ser usado para eliminar um conjunto ali de regras que é pouco interessante ou um conjunto de itens que não atende um critério mínimo que se espera para que a gente ia vale é esse conjunto de dados tá então geralmente ele dado em percentual
e essa é a fórmula dele tá então a gente nesse caso aqui tá verificando o suporte de uma regra tá então essa regra né e suporte a gente vai verificar olhando todos os as transações da base e verificando quais dessas transações existe a presença dos dois lados da regra né dos dois itens ou conjuntos de itens tanto Presidente quanto o consequente tá o signo aquele vai se simbolizar para a gente a quantidade de itens aqui que estão presentes na base como um todo Ah tá e o n é a quantidade de transações que tem naquela
base tá então Sigma a gente chama ele disso contagem de suporte para ele vai dar ali para cada transação existente na base no caso aqui olhando para o Sigma do conjunto de itens x tá ele vai olhar todo todas as ocorrências em que x está contido né no certo item de transação e essa transação ela faz parte então do conjunto total de transações T maiúsculo aqui Ah tá é bom a confiança ela vai verificar então ocorrência da parte consequente da regra Ah tá então a fórmula da confiança tá aqui para regra XY é o que
ela vai fazer é algo similar a probabilidade condicional tá então dado que existe aqui uma contagem suporte que contém tanto o lado x quanto Y ele vai verificar a proporção disso em relação a contagem dos esportes somente no Y tá isso vai dar uma proporção de de ocorrências aí que vai dar um valor de confiança quanto maior a confiança que também é dado percentual é melhor ali a geração da regra Ah tá então o suporte a gente pode considerar ele como sendo a significância estatística da regra aí a confiança a gente pode ver como acurácia
neocom precisa aquela regra se mostra no conjunto de dados e a gente tem um lift a convicção também tá então tem alguns casos em que as regras Elas têm pouco suporte né mas elas podem ser úteis Então imagina no caso da Rádio portátil da pilha que você quer avaliar se vale a pena manter aquele item ou aqueles itens sendo vendidos na loja então você pode querer olhar para ir tem que ter um suporte baixo tá uma outra questão é que quando a gente usa a confiança e suporte elas são analisadas separadamente não há uma relação
entre elas que para compor o índice Então nesse caso a gente pode usar lift e convicção Ah tá o livro que ele vai incluir a contagem ali do consequente na medida de confiança a fórmula dele tá daqui então ele vai incluir é o consequente aqui na hora de fazer essa análise Ah tá a convicção ela já vai mostrar e a razão entre a diferença do suporte do consequente e o erro da confiança tá então a gente vai ter o erro da confiança aqui né a diferença ou que não é confiança aqui no denominador Tá e
aí quanto maior valor de convicção melhor aquela regra para análise e a gente tem também as medidas de compreensibilidade grau de interesse para que vão avaliar o que a quantidade relativa de uma regra tá então elas vão considerar o tamanho ali do conjunto de itens pai não só a quantidade de transações presentes tá então no caso da compreensibilidade ele vai fazer aqui o logaritmo da quantidade de itens na que existem ali tanto do X quanto no Y para fazer esse cálculo Ah tá então quanto menor a quantidade de itens que existir no conjunto antecedente melhor
quer dizer tem uma Você tem uma chance maior de estabelecer uma boa regra quando você tem menos itens no lado antecedente Ah tá já o grau de interesse na ele vai calcular aqui a o suporte né a proporção de suporte da regra tanto considerando no denominador o lado antecedente quanto o lado consequente aí Vai Multiplicar isso pela pela diferença aqui né do suporte sobre o total de itens tá então também nesse caso ele vai buscar regras que tem um valor à lide suporte mais baixo Ah tá eu vou mostrar um exemplo aqui então é de
uma uma pequena base de dados aqui usando o suporte confiança tá essa base ela tem um conjunto aqui de transações contendo frutas tá já transformada aqui para para o formato binário Ah tá então vamos olhar aqui duas possíveis regras associando aqui figo e jaca e maçã e uva Ah tá Primeiro vou molhar aqui para regra de figo jaca Primeiro ela tem a base ela tem dez transações aqui tá então ele vai ser igual a 10 EA contagem de suporte de fico e jaca é de três né a gente tem três transações em que as duas
As duas frutas são vendidas juntas Ah tá além disso a gente tem a contagem de suporte só do Figo né o figo que a regra antecedente Ele tá em quatro transações Ah tá então se a gente calcular que o suporte EA confiança com base naqueles dados a gente vai ver que a regra fico jaca tem um suporte trinta por cento e uma confiança de 75 por cento Ah tá bom molhar agora a regra de maçã e uva tá então o número de transações é a mesma só que aqui nesse caso a gente tem a contagem
suporte de oito ocorrências tanto de maçã quanto de uva Ah tá se a gente olhar a contagem do antecedente Também é oito tá então quando a gente vai calcular aqui o suporte a confiança a gente vai ter um suporte de oitenta por cento bem mais alto que na regra anterior e a gente vai tomar a confiança de 100 porcento seja os itens acontecem sempre juntos então é só uma regra comparativamente anterior mais forte aí vai depender do analista na do caso fazer análise e determinar Qual é o suporte a confiança que vai ser usado para
delimitar as regras que devem ser consideradas como válidas certo então esse é o conteúdo da aula de hoje obrigado e até a próxima tchau [Música] E aí [Música] [Música]