[Música] Olá pessoal sejam bem-vindos a sexta semana da nossa disciplina de processamento de linguagem natural e essa semana a gente vai tratar de uma aplicação uma das principais aplicações que a gente tem em PLL que é a classificação de textos Então a gente vai seguir um roteiro aqui né falar um pouquinho sobre o que que seria a classificação de texto Então fazer uma introdução né sobre o tópico depois de entrar um pouco mais de detalhes exatamente o que que seria a classificação de texto de que forma que a gente pode fazer esse tipo de classificação
né e alguns exemplos e aplicações que a gente pode ter aí com processamento de textos né bom primeiro né Para a gente lembrar né que a gente utiliza normalmente o conceito de rebeldens né para poder fazer a representação dos nossos textos a gente viu diferentes tipos de formas de representação dos textos né porque a gente sabe que um texto ele ele tem bastante conteúdo né então várias formas distintas né da gente conseguir representar esse texto e claro que a máquina o trabalho de uma forma diferente da nossa né não é numa tarefa tão simples para
para máquina é trabalhar com esse texto como a gente já viu isso bastante é nas outras semanas do nosso curso né e a gente acaba tendo outras formas de fazer essa representação né que facilitam algumas tarefas em detrimento de outras e etc né e uma das principais né formas da gente representar e trabalhar com texto que são muito utilizadas né Não só agora Mas como já há um bom tempo né são as ideias né Principalmente porque porque ela diminui bastante né significativamente dependendo do do foco né do nível que a gente quer fazer essa redução
da da dimensionalidade ela diminui muito a dimensionalidade é do do das nossas representações principalmente pra gente compara né com aquelas representações de mega of Wars por exemplo né que umas também das desvantagem a gente trabalhar com ideias é que a gente elimina ou reduz muito né a nossa a nossa esparticidade dos dados né porque o embelden ele faz uma representação em que a gente consegue criar representações de uma forma que os valores que a gente tem ali para cada texto eles acabam praticamente sendo todos preenchidos né não tem mais aquele problema do zero né e
ganha também bastante informação assim Principalmente quando a gente vai fazer aquelas operações quando a gente viu também nas outras aulas né para fazer uma soma por exemplo de rei com rainha e diminuir mulher a gente vai ter lá que o resultado pode ser um homem por exemplo a gente coloca algum contexto uma semântica na verdade né nossa na nossa representação né e a gente viu também né que essas mulheres elas podem ser aprendidas né é a gente viu por isso pode ser feito por exemplo com o nosso modelo onde que o Vec né que trabalha
com redes neurais que é o que a gente é também tá vendo durante essa semana né artificiais né e a gente acaba tendo Essa é a menor personalidade que nenhuma mencionei para vocês né e tenta preservar essas características de espaço né do espaço da maior dimensionalidade né então A ideia é que a gente tenha muito ganho quando a gente trabalha com emeds né e uma das principais vantagens também do ibérias que é o que a gente tá eh focando aqui nessa primeira nesse primeiro slide dessa apresentação é que facilita muito também o trabalho depois dos
nossos classificadores quando a gente vai trabalhar com classificação de textos e trabalhar com algoritmos de classificação de aprendizagem de máquina para poder lidar com esse tipo de problema né então aqui para a gente ter uma ideia do que que a gente pode fazer né com com processamento de texto com classificação de texto né tem algumas ideias aqui na verdade análise inteligente de texto no geral Não exatamente na classificação né porque a gente pode ter aqui também aplicações de agrupamento como a gente vê aqui é fazer é muito comum é que a gente trabalha com troca
né com transmissão em troca de informações por exemplo com e-mails artigos em jornais relatórios e livros né tudo isso vai gerar dados para nós que a gente pode utilizar depois para fazer esse processamento né então a gente só para ter uma ideia do que que a gente entende conteúdo O que que a gente tem de possibilidades de texto para trabalhar né todas as aplicações que a gente tá vendo aqui né postagens e redes sociais e páginas web e etc né tudo isso lida muito contexto né então dados para a gente trabalhar para a gente processar
dados textuais a gente não vai faltar né aplicações são diversas né E a gente tem algumas vantagens dos textos em relação aos áudios por exemplo né a gente sabe que para armazenar texto sabe é muito mais é ocupa bem menos espaço né em relação ao áudio né embora seja difícil de processar o texto mas é menos difícil do que processar o áudio né fazer análise né de de conteúdo né tanto pelo ser humano quanto por um áudio então às vezes dependendo de como como que é um áudio a gente consegue fazer melhor é mais rápido
utilizando o texto em relação ao áudio né E também permite assim consultar e recuperar informações de forma mais fácil porque o áudio normalmente a gente teria que ouvir ele inteiro e às vezes ouvi de novo o vídeo novo né não consegue trocar né é o do texto A gente tá no parágrafo pula para um dois três parágrafos à frente só na mudança da direção do olho no áudio não é tão tão simples assim né para a gente fazer né então tem algumas vantagens a gente trabalhar com o texto né Então essa nossa ideia aí né
é o avanço que a gente tem da da do computador né E principalmente na área de aprendizado de máquina né de tentar copiar e tentar utilizar a forma com que o ser humano lida com algumas tarefas né nos coloca aqui também uma série de aplicações né que permite que a gente faça essa análise inteligente né em relação a textos análises no sentido do contexto geral vamos dizer né Por exemplo a organização automática de documentos isso é bastante interessante embora a gente possa tratar isso como uma tarefa de de agrupamento né não uma tarefa de classificação
Mas é uma tarefa inteligente organizar de máquina né é fazer filtro filtragem de expande ou e-mails né de Espanha ou roteamento para determinados departamentos específicos né então o simples tarefa de classificar um e-mail Como spam não que vocês estão acostumados a fazer né a gente já viu esse como exemplo quando falou sobre a questão de ser dados balanceados ou desbalanceados né normalmente porque a maioria dos e-mails eles eles acabam sendo não spam né ficou uma tarefa desbalanceada mas a gente vê também que é uma análise um processamento de texto né então basicamente o que que
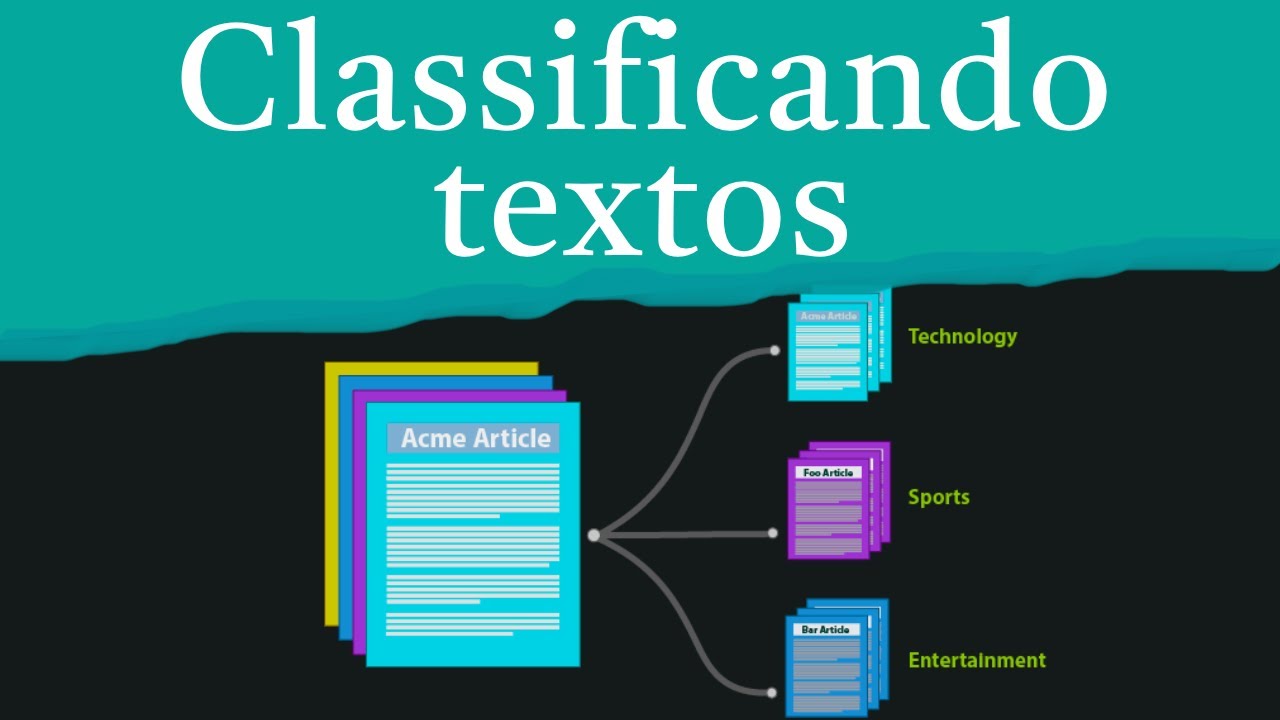
é feito lá dentro uma classificação a gente pega aquele e-mail aquele texto como entrada e classifique aquele texto como sendo espão ou não antes de decidir para onde vou colocar só vou colocar ele na caixa de entrada ou se eu vou colocar ele na caixa de spam né e aqui a gente tem várias outras aplicações como análise de sentimentos humanização de documentos recomendação e etc certo bom então o que que seria falando Mais especificamente agora sobre a classificação de textos né a classificação automática de texto né então ela é uma das tarefas que a gente
mais utiliza né envolvendo o texto envolvendo processamento de linguagem natural né vou envolver na análise inteligente de texto né então basicamente O que que significa isso pessoal que a gente vai atribuir a um texto inteiro isso claro o texto inteiro vai ser sempre subjetivo de relação O que que a gente tá querendo resolver pode ser um documento pode ser uma notícia pode ser uma sentença uma frase um parágrafo né isso tudo vai depender do nível de abstração que a gente está trabalhando né O que qual o interesse que a gente tá querendo é classificar né
mas a ideia é que a entrada seja um palavras né uma sequências sequências de palavras e a saída vai ser um rótulo vai dizer ó esse cara aqui é de uma classe A ou de uma classe B então a basicamente A ideia é rotular o texto por completo certo E aí a gente tem aí né a gente já aprendeu né Como que você trabalha com aprendizado de máquina a gente já viu isso nas semanas anteriores né então a gente vê que é uma grande oportunidade pra gente trabalhar também com os nossos algoritmos de aprendizado de
aprendizado de máquina para fazer essa classificação de textos de forma automática né então qual que seria a ideia normalmente o que que a gente faz a gente aprende o conhecimento para depois por fim normalmente 99% dos casos né a nossa ideia é fazer uma previsão né ou seja aprender com os documentos que a gente tem né com os textos que a gente tem qual é o rótulo que ele pertence para depois poder é utilizar esse nosso classificador que a gente gerou esse conhecimento que a gente adquiriu para fazer a previsão do rótulo rotular documentos textos
que a gente não sabe qual é né então A ideia é basicamente é essa né então isso claro a gente pode ver que isso tudo que a gente tá conversando né o tipo de rótulo tudo vai depender do interesse também da aplicação então às vezes a gente tem os mesmos textos que a gente pode querer rotular de formas distintas elas vão ver alguns exemplos aqui né até fez uma brincadeira para vocês né Para a gente entender basicamente a gente vamos supor que a nossa entrada sejam notícias né é notícias de um website como eu coloquei
aqui peguei uma uma notícia do do globoesporte.com né e falando um pouquinho sobre isso a época em 2017 não faça tanto tempo assim né quando o Grêmio venceu a final da Libertadores da América e foi campeão né tricampeão da Libertadores né E aí a gente pode classificar textos né notícias de acordo com interesses diferentes por exemplo aqui a gente queria a gente pode fazer esses esses rótulos né definir previamente esses rótulos e querer classificar e dizer ó aqui aqui que rótulo dentro e esses que eu tô colocando aqui pertence esse texto aqui então a gente
pode olhar aqui nesse nível né de interesse não é é ele é paulista carioca Gaúcho ou brasileiro a gente colocou alguns rótulos assim para tentar classificar esse texto aí a gente vai lá faz a classificação e classifica como Gaúcho Provavelmente porque o Grêmio é um time é do Estado do Rio Grande do Sul né bom outra forma de fazer esse rótulo né agora a gente vai rolar de diferentes formas Vamos colocar nomes específicos de times né de clubes de futebol então a gente colocou aqui ó definimos esses rótulos aqui Inter Juventude e Grêmio e Brasil
de Pelotas por exemplo né a gente vai lá e faz uma classificação aprende e a partir do que a gente aprendeu com o nosso conhecimento com uma base de dados né ou seja textos que já tem previamente esses rótulos para diferentes notícias algumas fazem parte do Inter outras do Grêmio e do Juventude e etc do Brasil né E a gente vai lá e classifica esse nosso aqui agora como sendo do Grêmio porque porque é uma notícia que é relacionada com o Grêmio né a gente pode trabalhar também com rótulos mais de níveis mais altos de
abstração eu quero saber se essa notícia aqui é interessante ou não é interessante é só isso né Isso se usa bastante nós vamos ver mais adiante também quando a gente trabalha com análise de sentimentos né vai a gente acaba não trabalhando com o texto por completo mais com sentenças normalmente né e saber se aqueles comentários alguma coisa do gêneros tem um feedback positivo né É O negativo por exemplo né então aqui um caso uma classificação binária ó notícia interessante ou não a gente vai lá coloca como sendo interessante aqui por exemplo né na classificação desse
documento ou ainda né fazer um uma brincadeira final aí com vocês né a gente poderia classificar uma sequência de documentos e elas ficar aqueles que fazem parte do melhor time do mundo ou do resto né E aqui Claro a gente colocaria é o Grêmio como sendo o melhor time do mundo vocês devem imaginar já que eu estou usando esse exemplo aqui porque eu sou torcedor do Grêmio naturalmente né certo então aqui a gente tem vários outros exemplos de classificação que a gente pode se deparar aí né na a jornada aí né Então aqui tem alguns
exemplos né dependendo de domínios aqui alguns rótulos diferentes que a gente pode colocar por exemplo e-mails né no domínio de e-mails a gente classificar como sendo spam não ou classificar até por áreas a gente vê que no próprio Gmail tem feito isso Ele criou alguns leigos lá que ele vai colocando quando quando é alguma coisa de de Notícias ou quando é coisa uma uma um e-mail relacionado a propagandas por exemplo né então isso já é feito a gente já fez bastante no dia a dia né a gente tem outras informações aqui que a gente pode
colocar rotular de formas distintas como por exemplo aqui os tweets ou comentários em Facebook e colocar alguns sentimentos que nem mencionei para vocês né como negativo positivo ou neutro ou como esse ofensivo e não ofensivo Então tudo isso vai depender do interesse né com como que a gente vai fazer para criar esses rótulos né definir esses rotas para depois fazer esse aprendizado e fazer a classificação dos nossos documentos né bom então a gente percebe aí né que como Eu mencionei para vocês né que é uma é uma aplicação que a gente tem muitos dados gerados
né quantidade altíssima de dados e isso demanda Claro com que a gente não que a gente trabalha com técnicas cada vez mais é avançadas vamos dizer né para poder lidar com essa quantidade de informação e com a complexidade que a gente vai tendo né A medida que o tempo vai passando a gente vai tendo mais dados e mais complexidade de dados e mais quantidade também então tudo isso demanda né outras técnicas outros métodos para a gente sempre melhorando o estado da arte né E aí tem mais algumas aplicações para vocês darem uma olhada né então
aqui o que que a gente poderia ter aqui de aplicações mais específicas né só para deixar claro então para vocês agora tratando especificamente de classificação de textos né organização recuperação de documentos filtragem e organização de Notícias a gente vê bastante isso também recuperação de informação sistemas de recomendação baseada em textos e a gente vê também a gente vê muito baseado em perfil de usuário e compras Mas a gente pode ver baseado em texto também pega uma empresa que faz propaganda começa a fazer pesquisas em redes sociais por exemplo pegar comentários das pessoas e começar a
partir disso começar a fazer marketing direcionado por exemplo né uma ideia bem simples né que as empresas usam muito hoje não é à toa que a gente fica recebendo notícias a gente faz alguma busca alguma coisa no Google lá pelas tanta gente tá recebendo e-mail né sugerindo coisas que a gente tá querendo comprar né Então tudo isso aqui são aplicações que a gente pode tratar né claro são tarefas Gerais de classificação nesse caso aqui sendo como entrada Então são várias aí dedicação de crimes inclusive então às vezes a gente foca muito em aplicações Ah mas
isso aqui não é bom não é é ruim porque a invasão de privacidade tem essas questões éticas também que são bem importantes devem sempre ser trabalhadas né e isso vale muito para a parte de imagens né mas vale também para textos né a gente tem essa preocupação mas também ajuda muita coisa também para no caso aqui identificação de crimes né muitos crimes aí foram evitados né brigas de torcida de futebol por exemplo ou ameaças de a gente viu na época das eleições também muitas ameaças as pessoas se juntando para fazer atentados e etc e a
polícia trabalha muito com isso também né para poder fazer identificação a partir de mensagens e tal Porque não tem como ficar olhando tudo é vasculhando e dependendo do olho humano para fazer isso porque não tem como trabalhar com tanta informação né então isso tudo é feito de forma automática né bom então basicamente a ideia aqui né que a gente tava conversando né classificação textual tudo isso que a gente conversou para chegar né na na parte que mais interessante vamos dizer assim mais interessante que é trabalhar com texto sim o aprendizado de máquina que é o
que tem utilizado né ultimamente para poder lidar com todas essas tarefas Não especificamente de classificação mas basicamente todas as tarefas que envolvem plm né Por exemplo tradução de textos não é uma classificação mas também trabalha muito com aprendizado de máquina né mas aqui no contexto de classificação né então a gente vê que a gente vai ter uma coleção de partindo de uma coleção de documentos previamente do outro lado A ideia é fazendo são de um modelo de classificação que a gente já viu como já viu que existem várias formas de representar o conhecimento e já
viu também que para cada uma dessas formas de representação do conhecimento para cada um desses modelos de representação de conhecimento a gente tem diversos algoritmos de indução que é partem de um conjunto de dados de entrada e geram né esse modelo de representação de conhecimento feito isso a gente vai ter esse modelo que é um modelo classificação que a gente vai poder utilizar então quando chegar novas documentos que a gente não tem né esse rótulo a gente não conhece esse rótulo né fazer a previsão do rótulo né então classificar esses caras aí é de acordo
com o conhecimento que foi adquirido com os documentos de origem né que a gente já tinha todos rotulados né Então aí a gente tem esses documentos classificados de forma automática mas claro inicialmente a gente precisa é adquirir esse conhecimento para poder depois aplicar esses documentos novos né e abordagem clássica que a gente tem para isso pessoal a gente vai ver que se usa muito ainda e principalmente em relação ao que tem de ser usado Demais atual se usa as duas coisas muito ainda e em conjunto vamos dizer né mas abordagem clássica o que que seria
a gente pegar esse nossos textos como é que a gente vai gerar a gente aprendeu como é que trabalha com aprendizado de máquina ele não trabalha com texto né com documento inteiro né a gente precisa ter uma representação estruturada para isso né e o que que seria essa representação no formato estruturado uma tabela tributo valor por exemplo uma tabela tributo valor em que as linhas a gente teria seus documentos cada documento seria uma linha e nas colunas a gente teria as informações as features né tributos ou características desses documentos né A partir disso então a
gente constrói a nossa algoritmo de aprendizado de máquina e aí faz todo o processo que a gente está aprendendo aqui né para parte da representação a gente passa pela etapa de limpeza padronização dos termos tudo aquilo que a gente viu né que a gente trabalha já quando vai utilizar o algoritmo de aprendizado de máquina não é feito isso né então um exemplo bem claro aqui que é bem utilizado ó vamos representar os textos como vamos utilizar beleza vamos utilizar Então a gente vai ter já nosso formato de acordo com o que a gente tá precisando
as linhas vão ser os documentos as colunas vão ser os remédios que foram gerados e os valores vão estar todos lá bem distribuídos e etc né A partir disso a gente também vai trabalhar né com não com a parte do pré-processamento feito anteriormente do texto também é feito antes da gente ter os nossos ML né mas também a parte de pré-processamento necessária para trabalhar com os algoritmos de aprendizagem de máquina então alguns deles exigem algumas modificações algumas alguns pré-processamento específicos para poder trabalhar por exemplo alguns trabalham com o número outro só trabalha com com valores
categóricos etc Então tudo isso a gente vai continuar fazendo né de forma Vocês já viram na semanas anteriores né então aqui só para deixar bem claro para vocês como que seria essa classificação de texto da forma tradicional que nem mencionei para vocês né então a gente teria que a etapa de treinamento né que seria a partir do input que a gente tem aqui que a nossa entrada né o nosso texto a gente estaria essa extração de features que na verdade aqui seria a nossa representação vamos dizer por exemplo em Anhembi né feito isso a gente
vai ter os nossos mblins ali vamos utilizar Então esse nosso dessa tabela tributo valor com os bnbs para poder construir esse nosso algoritmo de nosso modelo né de machine learning né o nosso utiliza esse algoritmo para poder construir o conhecimento o modelo para depois então a etapa de previsão né essa etapa de Treinamento que Ou seja que é aquisição do conhecimento e a construção do modelo depois aqui é só a parte de previsão que seria o que né pros documentos que a gente quer classificar agora que a gente não sabe rota a gente vai ter
que colocar ele também naquela forma de representação né tirar extraídos em Bad etc e tal mudar pra essa mesma representação porque porque essa representação é a entrada do nosso modelo a gente precisa colocar no mesmo padrão né feito isso a gente utiliza esse modelo de classificação que foi construído aqui a partir do treinamento né treinamento a gente gerou esse modelo que é o que representa o conhecimento e faz a previsão então do rótulo né do nosso documento novo que tá chegando aí a gente não conhecia previamente esse rótulo né então basicamente que a gente tá
fazendo aqui né Essa parte os nossos textos seriam representados por cada uma dessas linhas cada linha seria um texto e aí a gente teria um atributo especial que seria um atributo classe né que ele normalmente a gente coloca como o último atributo e aquele cara que de que define Qual é o rótulo né então A ideia é sempre é a partir desses valores de entrada definir né o mapeamento né de entrada seria tudo que tá aqui dentro e a saída dizer qual é o valor da classe né e a gente Claro na hora de fazer
a representação teria algo desse tipo que nem Eu mencionei pra vocês uma tabela tributo valor né certo abordagem mais atual que a gente tem pessoal é você trabalha também né trabalha muito com a ideia mas a gente teria uma representação vamos dizer assim de uma forma bem genérica falando para vocês uma representação diferente internamente vamos dizer assim né que são internamente é o quê as nossas redes neurais Profundas que a gente vai trabalhar isso na na próxima semana tá então a gente tem um pouco mais de ultimamente que ser utilizado não é só apenas a
representação por em Berlin a gente trabalha com as redes heróis Profundas que elas acabam extraindo mais informações vamos dizer assim desses textos né que a gente chama de contextos e etc nós vamos ver com mais detalhes e e acabo fazendo a classificação entendo os melhores resultados aí no estado da arte tá então na aula de hoje a gente fez uma introdução falando um pouquinho sobre classificação de textos e alguns exemplos e aplicações aí nos preparando para nossa próxima vídeo aula que vai ser falar um pouquinho sobre redes neurais Profundas Tá bom até mais então pessoal
[Música] [Música]