you've had some strong statements technical statements about the future of artificial intelligence recently throughout your career actually but recently as well uh you've said that autoaggressive LMS are uh not the way we're going to make progress towards superhuman intelligence these are the large language models like GPT 4 like llama 2 and three soon and so on how do they work why are they not going to take us all the way for a number of reasons the first is that there is a number of characteristics of intelligent behavior for example the capacity to understand the world
understand the physical world the ability to remember and retrieve things um persistent memory the ability to reason and the ability to plan those are four essential characteristic of intelligent um systems or entities humans animals LMS can do none of those or they can only do them in a very primitive way and uh they don't really understand the physical world they don't really have persistent memory they can't really reason and they certainly can't plan and so you know if if if you expect the system to become intelligent just you know without having the possibility of doing
those things uh you're making a mistake that is not to say that auto LMS are not useful they're certainly useful um that they're not interesting that we can't build a whole ecosystem of applications around them of course we can but as a path towards human level intelligence they're missing essential components and then there is another tidbit or or fact that I think is very interesting those LMS are TR trained on enormous amounts of textt basically the entirety of all publicly available text on the internet right that's typically on the order of 10 to the 13
tokens each token is typically two bytes so that's two 10 to the 13 bytes as training data it would take you or me 170,000 years to just read through this at eight hours a day uh so it seems like an enormous amount of knowledge right that those systems can accumulate um but then you realize it's really not that much data if you you talk to developmental psychologists and they tell you a four-year-old has been awake for 16,000 hours in his or life um and the amount of information that has uh reached the visual cortex of
that child in four years um is about 10 to the 15 bytes and you can compute this by estimating that the optical nerve carry about 20 megab megabytes per second roughly and so 10^ the 15 bytes for a four-year-old versus 2 * 10^ the 13 bytes for 170,000 years worth of reading what it tells you is that uh through sensory input we see a lot more information than we than we do through language and that despite our intuition most of what we learn and most of our knowledge is through our observation and interaction with the
real world not through language everything that we learn in the first few years of life and uh certainly everything that animals learn has nothing to do with language so it would be good to uh maybe push against some of the intuition behind what you're saying so it is true there's several orders of magnitude more data coming into the human mind much faster and the human mind is able to learn very quickly from that filter the data very quickly you know somebody might argue your comparison between sensory data versus language that language is already very compressed
it already contains a lot more information than the btes it takes to store them if you compare it to visual data so there's a lot of wisdom and language there's words and the way we stitch them together it already contains a lot of information so is it possible that language alone already has enough wisdom and knowledge in there to be able to from that language construct a a world model and understanding of the world an understanding of the physical world that you're saying L LMS lack so it's a big debate among uh philosophers and also
cognitive scientists like whether intelligence needs to be grounded in reality uh I'm clearly in the camp that uh yes uh intelligence cannot appear without some grounding in uh some reality doesn't need to could be you know physical reality it could be simulated but um but the environment is just much richer than what you can express in language language is a very approximate representation of our percepts and our mental models right I mean there there's a lot of TX that we accomplish where we manipulate uh a mental model of uh of the situation at hand and
that has nothing to do with language everything that's physical mechanical whatever when we build something when we accomplish a task a model task of you know grabbing something Etc we plan or action sequences and we do this by essentially Imagining the result of the outcome of sequence of actions that we might imagine and that requires mental models that don't have much to do with language and that's I would argue most of our knowledge is derived from that interaction with the physical world so a lot of a lot of my my colleagues who are more uh
interested in things like computer vision are really on that camp that uh AI needs to be embodied essentially and then other people coming from the NLP side or maybe you know some some other U motivation don't necessarily agree with that um and philosophers are split as well uh and the um the complexity of the world is hard to um it's hard to imagine you know it's hard to represent uh all the complexities that we take completely for granted in the real world that we don't even imagine require intelligence right this is the old marac Paradox
from the pioneer of Robotics hence marac who said you know how is it that with computers it seems to be easy to do high level complex tasks like playing chess and solving integrals and doing things like that whereas the thing we take for granted that we do every day um like I don't know learning to drive a car or you know grabbing an object we can do as computers um and you know we have llms that can pass pass the bar exam so they must be smart but then they can't learn to drive in 20
hours like any 17y old they can't learn to clear up the dinner table and F of the dishwasher like any 10-year-old can learn in one shot um why is that like you what what are we missing what what type of learning or or reasoning architecture or whatever are we missing that um um basically prevent us from from you know having level five sing Cars and domestic robots can a large language model construct a world model that does know how to drive and does know how to fill a dishwasher but just doesn't know how to deal
with visual data at this time so it it can Opera in a space of Concepts so yeah that's what a lot of people are working on so the answer the short answer is no and the more complex answer is you can use all kind of tricks to get uh uh an llm to basically digest um visual representations of representations of images uh or video or audio for that matter um and uh a classical way of doing this is uh you train a vision system in some way and we have a number of ways to train
Vision systems either supervise semi supervised self-supervised all kinds of different ways uh that will turn any image into high level representation basically a list of tokens that are really similar to the kind of tokens that uh typical llm takes as an input and then you just feed that to the llm in addition to the text and you just expect LM to kind of uh you know during training to kind of be able to uh use those representations to help make decisions I mean there been working along those line for for quite a long time um
and now you see those systems right I mean there are llms that can that have some Vision extension but they're basically hacks in the sense that um those things are not like train end to end to to handle to really understand the world they're not train with video for example uh they don't really understand intuitive physics at least not at the moment so you don't think there's something special to you about intuitive physics about sort of Common Sense reasoning about the physical space about physical reality that's that to you is a giant leap that llms
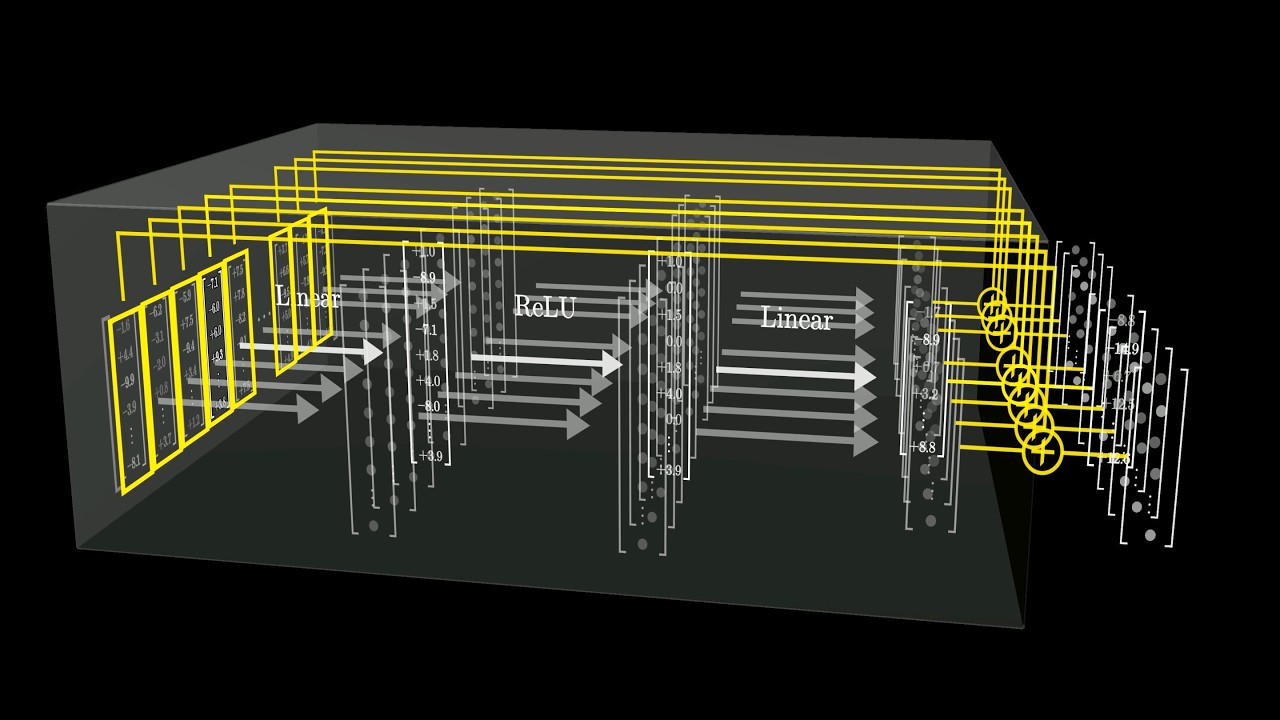
are just not able to do we're not going to be able to do this with the type of llms that we are uh working with today and there's a number of reasons for this but uh the main reason is the way llm LMS are trained is that you you take a piece of text you remove some of the words in that text you Mass them you replace by replace them by blank markers and you train a gtic neural net to predict the words that are missing uh and if you build this neural net in a
particular way so that it can only look at uh words that are to the left of the one is trying to predict then what you have is a system that basically is trying to predict the next word in a text right so then you can feed it um a text a prompt and you can ask it to predict the next word it can never predict the next word exactly and so what it's going to do is uh produce a probability distribution over all the possible words in your dictionary in fact it doesn't predict words it
predicts tokens that are kind of subw units and so it's easy to handle the uncertainty in the prediction there because there's only a finite number of possible words in the dictionary and you can just compute a distribution over them um then what you what the system does is that it it picks word from that distribution of course there's a higher chance of picking words that have a higher probability within that distribution so you sample from that distribution to actually produce a word and then you shift that word into the input and so that allows the
system not to predict the second word right and once you do this you shift it into the input Etc that's called Auto regressive prediction and which is why those llms should be called Auto regressive llms uh but we just called themm and there is a difference between this kind of process and a process by which before producing a word when you talk when you and I talk you and I are bilinguals we think about what we're going to say and it's relatively independent of the language in which we're going to say it when we we
talk about like a I don't know let's say mathematical concept or something the kind of thinking that we're doing and the answer that we're planning to produce is not linked to whether we're going to see it in French or Russian or English Chomsky just rolled his eyes but I understand so you're saying that there's a a bigger abstraction that repres that's uh that goes before language that maps onto language right it's certainly true for a lot of thinking that we that we do is that obvious that we don't like you're saying your thinking is same
in French as it is in English yeah pretty much yeah pretty much or is this like how how flexible are you like if if there's a probability distribution well it it depends what kind of thinking right if it's just uh if it's like producing puns I get much better in French than English about that no but so is there an abstract representation of puns like is your humor an abstract like when you tweet and your tweets are sometimes a little bit spicy uh what's is there an abstract representation in your brain of a tweet before
it maps onto English there is an asct representation of uh Imagining the reaction of a reader to that uh text well you start with laughter and then figure out how to make that happen or so figure out like a reaction you want to cause and and then figure out how to say it right so that it causes that reaction but that's like really close to language but think about like a m mathematical concept uh or um you know imagining you know something you want to build out of wood or something like this right the kind
of thinking you're doing has absolutely nothing to do with language really like it's not you have necessarily like an internal monologue in any particular language you're you're you know imagining mental models of of the thing right I mean if I if I ask you to like imagine what this uh water bottle will look like if I rotate it 90 degrees um that has nothing to do with language and so uh so clearly there is you know a more abstract level of representation uh in which we we do most of our thinking and we plan what
we're going to say if the output is is you know uttered words as opposed to an output being uh you know muscle actions right um we we plan our answer before we produce it and LMS don't do that they just produce one word after the other instinctively if you want it's like it's a bit like the you know subconscious uh actions where you don't like you're distracted you're doing something you completely concentrated and someone comes to you and you know asks you a question and you kind of answer the question you don't have time to
think about the answer but the answer is easy so you don't need to pay attention you sort of respond automatically that's kind of what an llm does right it doesn't think about its answer really uh it retrieves it because it's accumulated a lot of knowledge so it can retrieve some some things but it's going to just spit out one token after the other without planning the answer but you're making it sound just one token after the other one token at a time generation is uh bound to be simplistic but if the world model is sufficiently
sophisticated that one token at a time the the most likely thing it generates is a sequence of tokens is going to be a deeply profound thing okay but then that assumes that those systems actually possess World model so really goes to the I I think the fundamental question is can you build a a really complete World model not complete but a one that has a deep understanding of the world yeah so can you build this first of all by prediction right and the answer is probably yes can you predict can you build it by predicting
words and the answer is most probably no because language is very poor in terms or weak or low bandwidth if you want there's just not enough information there so building World models means observing the world and uh understanding why the world is evolving the way the way it is and then uh the the extra component of a world model is something that can predict how the world is going to evolve as a consequence of action you might take right so what model really is here is my idea of the state of the world at time
te here is an action I might take what is the predicted state of the world at time t+1 now that state of the world doesn't does not need to represent everything about the world it just needs to represent enough that's relevant for this planning of of the action but not necessarily all the details now here is the problem um you're not going to be able to do this with generative models so a genery model has trained on video and we've tried to do this for 10 years you take a video show a system a piece
of video and then ask you to predict the reminder of the video basically predict what's going to happen one frame at a time there the same thing as sort of uh the autoaggressive llms do but for video right either one FR at a time or a group of friends at a time um but yeah uh a large video model if you want uh the idea of of doing this has been floating around for a long time and at at Fair uh some colleagues and I have been trying to do this for about 10 years um
and you can't you can't really do the same trick as with llms because uh you know LMS as I said you can't predict exactly which word is going to follow a sequence of words but you can predict a distribution over our words now if you go to video what you would have to do is predict the distribution over all possible frames in a video and we don't really know how to do that properly uh we we we do not know how to represent distributions over High dimensional continuous spaces in ways that are useful uh and
and that's that they lies the main issue and the reason we can do this is because the world is incredibly more complicated and richer in terms of information than than text text is discret video is High dimensional and continuous a lot of details in this um so if I take a a video of this room uh and the video is you know a camera panning around um there is no way I can predict everything that's going to be in the room as I pan around the system cannot predict what's going to be in the room
as the camera is panning maybe it's going to predict this is this is a room where there's a light and there is a wall and things like that it can't predict what the painting on the wall looks like or what the texture of the couch looks like like certainly not the texture of the carpet so there's no way I can predict all those details so the the way to handle this is one way possibly to handle this which we've been working for a long time is to have a model that has what's called a latent
variable and the latent variable is fed to an Nal net and it's supposed to represent all the information about the world that you don't perceive yet and uh that you need to augment uh the the system for the prediction to do a good job at predicting pixels including the you know fine texture of the of the carpet and the and the couch and and the painting on the wall um uh that has been a complete failure essentially and we've tried lots of things we tried uh just straight neural Nets we tried Gans we tried uh
you know Vees all kinds of regularized Auto encoders we tried um many things we also tried those kind of methods to learn uh good representations of images or video um that could then be used as input to for example an image classification system and that also has basically failed like all the systems that attempt to predict missing parts of an image or video um you know from a corrupted version of it basically so right take an image or a video corrupt it or transform it in some way and then try to reconstruct the complete video
or image from the corrupted version and then hope that internally the system will develop a good representations of images that you can use for object recognition segmentation whatever it is that has been essentially a complete failure and it works really well for text that's the principle that is used for llms right so where is the failure exactly is that that it's very difficult to form a good representation of an image a good in like a good embedding of all all the important information in the image is it in terms of the consistency of image to
image to image to image that forms the video like where what are the if we do a highlight reel of all the ways you failed what what's that look like okay so the reason this doesn't work uh is first of all I have to tell you exactly what doesn't work because there is something else that does work uh so the thing that does not work is training a system to learn representations of images by training it to reconstruct uh a good image from a corrupted version of it okay that's what doesn't work and we have
a whole slew of techniques for this uh that are you know variant of dening Auto encoders something called Mee developed by some of my colleagues at Fair Max Auto encoder so it's basically like the you know llms or or or or things like this where you train the system by corrupting text except you corrupt images you remove Patches from it and you train a gigantic neet to reconstruct the features you get are not good and you know they're not good because if you now train the same architecture but you train it supervised with uh label
data with text textual descriptions of images Etc you do get good representations and the performance on recognition task is much better than if you do this self-supervised pre trining so the AR Ure is good the architecture is good the architecture of the encoder is good okay but the fact that you train the system to reconstruct images does not lead it to produce to learn good generic features of images when you train in a self-supervised way self-supervised by reconstruction Yeah by reconstruction okay so what's the alternative the alternative is joint embedding what is joint embedding what
are what are these architectures that you're so excited about okay so now instead of training system to encode the image and then training it to reconstruct the the full image from a corrupted version you take the full image you take the corrupted or transformed version you run them both through encoders which in general are identical but not necessarily and then you you train a predictor on top of those encoders um to predict the representation of the full input from the representation of the corrupted one okay so don't embedding because you're you're taking the the full
input and the corrupted version or transform version run them both through encoders so you get a joint embedding and then you and then you're you're saying can I predict the representation of the full one from the representation of the corrupted one okay um and I call this JEA so that means joint embedding predictive architecture because this joint embedding and there is this predictor that predicts the weos presentation of the good guy from from the bad guy um and the big question is how do you train something like this uh and until five years ago or
six years ago we didn't have particularly good answers for how you train those things except for one um called contractive contrastive learning where U and the idea of contractive learning is you you take a pair of images that are again an image and a corrupted version or degraded version somehow or transformed version of the original one and you train the predicted representation to be the same as I said if you only do this the system collapses it basically completely ignores the input and produces representations that are constant so the contrastive methods avoid this and and
those things have been around since the early 90s I had a paper on this in 1993 um is you also show pairs of images that you know are different and then you push away the representations from each other so you say not only do representations of things that we know are the same should be the same or should be similar but representation of things that we know are different should be different and that prevents the collapse but it has some limitation and there's a whole bunch of uh techniques that have appeared over the last six
seven years um that can revive this this type of method um some of them from Fair some of them from from Google and other places um but there are limitations to those contrasty method what has changed in the last uh you know three four years is now now we have methods that are non-contrastive so they don't require those negative contrastive samples of images that are that we know are different you can only you TR them only with images that are you know different versions or different views are the same thing uh and you rely on
some other tricks to prevent the system from collapsing and we have half a dozen different methods for this now








![The moment we stopped understanding AI [AlexNet]](https://img.youtube.com/vi/UZDiGooFs54/maxresdefault.jpg)