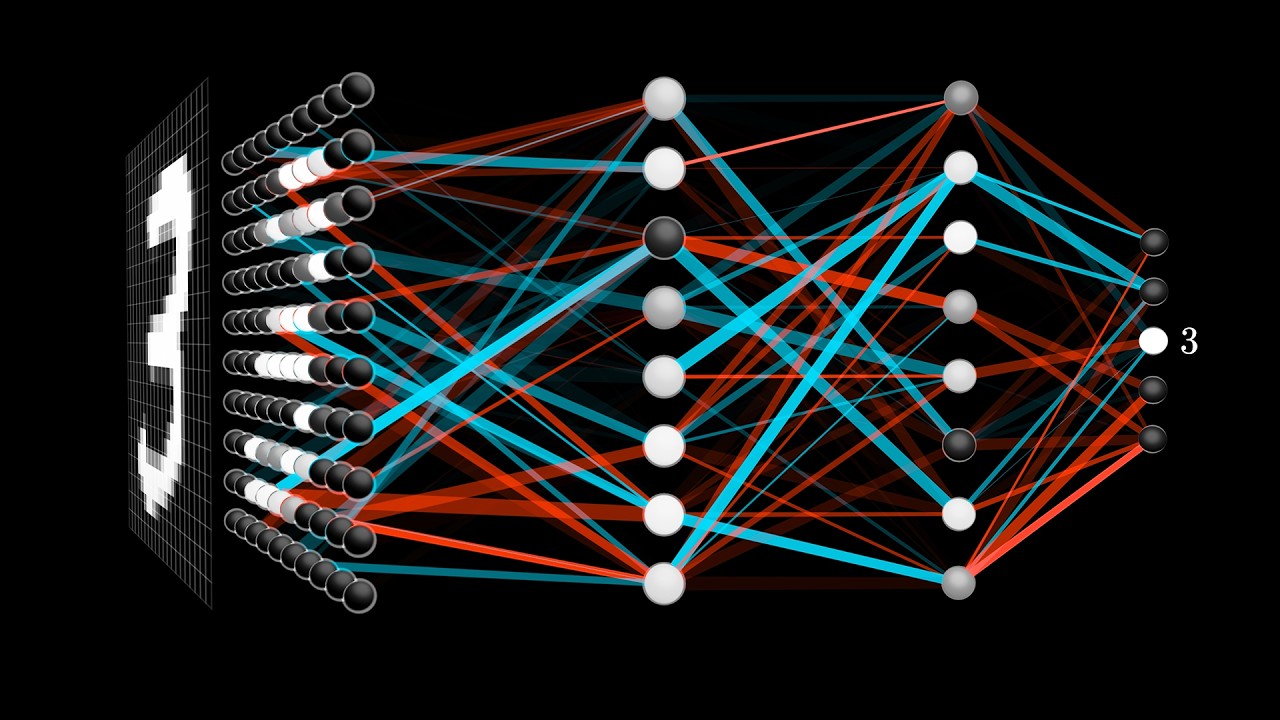
[Música] Olá pessoal tudo bem sejam bem-vindos Então a nossa vídeo aula 15 a nossa prática sobre aprendizado de máquina né que corresponde a nossa quinta semana da disciplina de processamento de linguagem natural então o que que a gente vai ver hoje pessoal bom a gente vai construir uma aplicação aqui bem interessante acho que é de interesse de todo mundo né um detector de Face de fake News na prática nesse nosso detector de fake News vai ser um classificador né que a gente aprendeu né durante as nossas aulas sobre aprendizado de máquina é um classificador que vai classificar textos notícias como sendo notícia real ou notícia fake né que é notícia mentirosa né então esse nosso detector de fake News é um assunto bem interessante porque tá bastante na moda atualmente né e existem diversas aplicações aí é práticas né para trabalhar com isso né porque a gente sabe que quando vai fazer investigação alguma coisa do gênero né é importante isso mas essencial né que isso seja feito de forma automática né porque não tem como alguém ficar acompanhando as notícias do tempo todo e vendo o que que é feito o que que não é fake né É muita coisa né quantidade é muito alta né então nós vamos ver como é que isso pode ser feito que de uma maneira bem simples né E vocês claro né como nas outras aulas vocês podem também trabalhar um pouco mais em cima desse notebook e aprimorar né De acordo com o interesse de vocês né então a gente vai utilizar um aprendizado supervisionado né para construir um classificador que a gente também chama de detector de fake News nossa aula vai ser dividida nessas partes que estão destacadas aqui né Vamos falar um pouquinho sobre a coleta dos dados vamos fazer então uma coleta de um conjunto de dados que a gente possa utilizar né cujos rótulos são conhecidos Então a gente vai ter textos notícias e a gente sabe se é fake ou se é notícia é verdadeira né É vamos trabalhar com dois tipos diferentes de representação desses nossos textos né dois bem simples que a gente já viu aqui né que é um Apple vai ser o bad of Wars que na verdade é o count né que a gente vai chamar né É É um mega fortes mais simples né e o outro é o nosso TF IDF né que a gente faz um pouco aplica aquelas formas que a gente viu também para mudar um pouco os valores que a gente tem na nossa Matriz de representação né E a gente vai trabalhar então com alguns algoritmos de aprendizado de máquina utilizando a ferramenta o pacote nessa etilane do Python né então a gente vai realizar o treinamento de modelos né a gente vai trabalhar com pelo menos dois modelos aqui de classificadores Vamos trabalhar com construção utilizando Diferentemente nesses dois tipos de representação Então a gente vai construir usando a primeira representação ela não construir utilizando a segunda a gente vai fazer avaliação desses modelos dá uma olhada como é que a gente pode ser os resultados que estão sendo obtidos né como Quais que estão se saindo melhor né E depois a gente vai falar um pouquinho sobre a interpretação desse conhecimento adquirido Pelo modelo tá no início Então pessoal como de praxe né a gente vai fazer aqui a importação dos pacotes principais que a gente vai utilizar durante essa aula né e é importante aqui vocês né quando vocês forem executar esse notebook pela primeira vez que vocês tirem esse comentário aqui né e execute a instalação desses pacotes porque eles não necessariamente estão instalados no servidor colab de vocês tá então aqui inicialmente pessoal Nossa coleta de dados né a gente tá fazendo download desse conjunto de dados que Eu mencionei para vocês né um conjunto de dados públicos né com textos e notícias né que são classificadas já préviamente né rotuladas como sendo notícias fakes ou notícias reais né então aqui a gente faz o download coloca não deita frame aqui né um tipo de objeto aqui do nosso nosso Python que a gente já conheceu né trabalhou já com pandas né E aqui é só mandei imprimir né as primeiras as primeiras linhas Desse nosso deck 7 para a gente dar uma olhada né Qual é a cara que ele tem né então a gente vai ter aqui um número identificador vai ter um título o texto que tem nessa notícia e por fim a gente tem um atributo alvo né que é o que disse cada uma dessas notícias representadas em cada uma das Linhas né é uma notícia fake ou uma notícia real tá então aqui a gente tem as cinco primeiros cinco primeiras linhas Desse nosso conjunto de dados que um conjunto de dados bem grande tá vocês podem trabalhar um pouquinho aqui né eu coloquei aqui para vocês um discrim só para a gente dar uma olhada sobre esse atributo Label só para a gente dar uma olhada Como é que tá a distribuição de classes desses nossos textos né dessas nossas notícias a gente vê que tá bem distribuído né então aqui a gente percebe né que esse nosso conjunto de dados está trabalhando com 6. 335 textos então o conjunto bem grande né de de Notícias aí que a gente pode utilizar para aprender adquirir o conhecimento aí a partir do nosso modelo de representação do conhecimento né a gente tem aqui são duas diferenças ali que tá mostrando quantas quantos valores diferentes únicos a gente tem aqui então são dois realmente né são ou efeito ou é real problema binário duas classes né aquela classe mais frequente é a classe real Então a gente tem aqui 3. 171 exemplos que são classe real e o complemento aqui Dá quase a metade né então é muito bem distribuída quase exatamente 50% né é muito próximo então a gente tem uma quantidade boa de Notícias que são reais e uma quantidade boa de Notícias que são é fakes então isso nos ajuda quando a gente tem um data 7 bem distribuído né a gente já conversou bastante sobre as formas de avaliação então aqui por exemplo a gente não precisa entrar em métrica de avaliação como fm porque porque a corasse aqui para nós é um bom é um bom indicativo já né não precisa entrar em tantos detalhes porque tendo uma curasse alta a gente vai saber que ele tá indo bem porque a gente tem um problema bem distribuído né bom vamos então para parte da representação tá pessoal aqui a gente tá criando dois duas formas diferentes de representação dos nossos textos né como a gente já viu nesse tudo a gente viu nas nossas aulas anteriores mas a gente vai precisar de uma forma de representação né que a extração de features que a gente já trabalho já conversou bastante durante a semana né para poder criar Aquela nossa tabela tributo valor né para colocar como entrada do nosso algoritmo de construção de um modelo né de representação do conhecimento ou como entrada do nosso algoritmo de aprendizado de máquina né então aqui pessoal isso a gente já trabalhou bastante né Vocês não precisa entrar em detalhes com vocês mas é só falar um pouquinho né que que a gente tá fazendo aqui primeiro a gente tá utilizando aqui o count factoryzer né do que a gente tem aqui disponível também no site Lane tá para fazer aquela Matriz de Contagem né então a gente vai ter nas linhas dos nossos textos e nas colunas a gente vai ter algumas palavras né que foram selecionadas lá para fazerem partes fazerem parte do [Música] dos atributos né então praticamente Tem tudo aqui né Pode ser que se remova ou não esse Stop Words etc Como está sendo colocado aqui né trabalhando com a língua inglesa né porque o nosso conjunto de dados é todo lindo Inglesa a gente acaba diminuindo um pouquinho o número de palavras mas a gente sabe que é bem próximo vamos dizer assim né do número número total de palavras diferentes que aparecem todos aqueles 6 mil e tantos militantes textos né então só para a gente saber que a gente vai ter uma matriz muito de uma alta dimensionalidade e muito esparsa também vocês lembram disso né porque porque às vezes uma palavra outra muitas palavras né vão aparecer é como Fit ou como atributo nosso conjunto de dados mas só porque elas aparecerem em um outro texto mas do resto tudo vai ser zero Porque não aparece nos outros textos né então a gente sabe que isso aqui não é a melhor forma de representação Mas é só para a gente fazer uma aula prática aqui ver que mesmo assim a gente acaba conseguindo resultados bons né mesmo utilizando esse tipo de representação tá e aqui a gente também fez né já uma divisão entre treino e teste vocês lembram disso né clenitech então o que que é o TNT a gente vai utilizar o conjunto de treinamento para construir o modelo aí depois esse conjunto de teste que é um pedacinho que a gente está deixando para fora né 33% que a gente especifica aqui no parâmetro né então 33% do nosso conjunto de dados ou seja um terço né do nosso dos nossos textos a gente está separando Fazendo de Conta que a gente não sabe qual é o rótulo para depois a gente avaliar o nosso modelo que a gente construiu né e ver se ele tá fazendo uma boa previsão né para dados que a gente supostamente aqui tá tratando como futuros né aqueles que a gente não sabe qual é o rótulo né E aí que a gente consegue avaliar se ele tá ou não generalizando bem né seria adquirir o conhecimento suficiente para poder e bem em classificar né em detectar os outros textos que não foram utilizados durante a sua construção né então aqui a gente só para mostrar para vocês estou imprimindo aqui as 10 primeiras features e a gente vai ver um pouquinho mais embaixo Aqui quantas são as features né são muitos né mais de 5.
000 features que foram geladas né então a cada cada texto vai ter cinco mais cinco mil atributos e aqui é a mesma coisa tá pessoal a mesma ideia que a gente utilizou lá em cima a gente está fazendo aqui agora também para o TF e DF certo a mesma mesma coisa que a gente fez lá em cima tá então a gente vai descendo aqui a gente vai ter o nosso dois dois tipos de representação diferentes né bom aqui a gente só tá dando uma olhada né fazendo uma inspeção né desses vetores que a gente tem aqui para a gente dar uma olhada né Quais são as características deles né então aqui a gente tá imprimindo as primeiras linhas de cada um deles né Fazer Tanto Country a gente transformou em Data Frame antes né como tfdf né DF a gente colocou um DF no fim para dizer que a representação no objeto deita frame desses dois caras que estão aqui nesses dados que a gente tá trabalhando agora né Para a gente dar uma olhada mais ou menos como é que é a cara deles né mas o que que é importante aqui para nós basicamente é olhar o número de coluna Vocês estão vendo aqui eu falei 5. 000 eu tô confundindo né é mais de 56 são quase 57 mil features 6. 000 textos naturalmente é muito maior número de palavras do que de textos né então são quase 57 mil atributos que a gente tem aqui só para vocês terem uma ideia né para cada texto O que que a gente tem de atributos então a o tamanho né da dimensionalidade do nosso problema né claro que isso a gente aprendeu é melhor a gente trabalhar com a ideias que a gente reduz isso e também reduz muito a esparicidade né Vocês estão vendo aqui quando a gente manda imprimir você praticamente só vem zero aqui né porque é difícil achar os zooms são matrizes esparsas né É por isso que a gente sabe que que isso é um problema que vem a ser resolvido depois com os ml bom aqui ele faz uma verificação sujeita as frames são iguais a não só para mostrar para vocês né O resultado é falso né que não não é a mesma coisa porque uma representação é com Country o outro é com tfdf certo então uma vez que a gente tem nossos conjuntos de dados O que que a gente vai fazer agora agora vamos construir né os nossos modelos de aprendizado de máquina Tá vamos começar o procedimento aqui de Treinamento construção e depois avaliação desses modelos e a gente vai construir utilizando duas representações Diferentes né Essas que a gente construiu usando o count né e usando também o nosso tfdf tá aqui Pessoal esse primeiro trecho de código que tá aqui a gente vai criar uma função né que a gente chama de plot confio geometrics né que é para imprimir a matéria de confusão a gente aprendeu lembra que a gente aprendeu nossa matéria de confusão aquela que a gente utiliza para estrear várias medidas das nossas do desempenho do nosso classificadores né E esse cara aqui como ele vai ser em comum para cada classificador que a gente for avaliar a gente vai gerar essa Matriz né então a gente criou uma função aqui que recebe o classificador recebe as classes e etc né tudo que é necessário né para ele imprimir né esses resultados para nós é aí vai ele vai imprimir essa nossa Matriz de confusão tá elas vão ver bonitinho depois como é que fica aqui tem alguns códigos que imprimem os plates né faz os gráficos bonitinho para a gente enxergar melhor tá então o primeiro treinamento que a gente vai fazer aqui pessoal é utilizando o count Vectra utilizando a matriz de representação do Megaforce que Eu mencionei para vocês anteriormente né que é a contagem de palavras para cada um dos textos e a gente vai trabalhar aqui com o modelo na RBS que foi que vocês estudaram aí nessa semana né só para a gente dar uma olhada o que que a gente consegue obter de resultado com eles a gente vai testar um outro também mais adiante eu vou explicar o porquê né uma vantagem que a gente tem de usar em relação a evidência tá então aqui o que que a gente tá fazendo né primeiro a gente vai distanciar né fazer todo aquele procedimento que vocês já já sabem fazer né vai construir aqui é o treinamento quando a gente coloca o Fit né nesse nosso objeto a gente faz aqui a gente tá fazendo treinamento tá usando a representação o treino do count né dessa representação e o y é o alvo para esse conjunto de dados aqui esse conjunto de textos aqui de Treinamento tem que dar esses rótulos que estão aqui no Y que é o atributo alto e ele vai construir o modelo feito esse pessoal E aí que que a gente vai ter um modelo aqui nesse nosso objeto ele é classificar e a gente vai fazer a predição aí quando a gente vai quem quer fazer a predição é usar esse modelo que tá aqui para prever Quais são os valores do rótulo né para o conjunto de teste que é esse cálcio teste aqui então esse aqui é o conjunto de teste ele tá prevendo Qual é o y desse cara aqui para depois a gente comparar tá colocando em prédio Aí faz a comparação né calcular essa como ó para esse esses cara aqui é o gabarito tinha que dar esse resultado aqui que a gente separou lá antes mas o meu modelo preveu esse aqui né então agora vamos ver quanto ele acertou né Quantos por cento ele acertou ele vai mostrar a curaça para nós que tá aqui embaixo 89,33%, 34%, tá depois é que ele tá calculando a matriz de confusão do jeito que eu falei para vocês que ela função que a gente criou lá em cima né tá passando aqui os parâmetros necessários né E tá mostrando para nós a matriz de confusão aqui depois aí calculou depois ela vai imprimir tá E também tá calculando aqui a área da curva rock né a gente não entrou em detalhes sobre não expliquei para vocês o que que seria essa métrica mas é importante vocês darem uma olhada depois eu deixei um link aqui para vocês tá vocês podem dar uma olhada como é que funciona esse tipo de avaliação é interessante quando a gente tem modelos probabilísticos por exemplo como eu na evidez né e a gente acaba usando algumas algumas lineares diferentes a gente vai pilotar uma cor que a gente acaba calculando a área dessa curva para poder fazer a comparação da performance do desempenho né mas eu não vai dar tempo de eu falar isso com vocês aqui em detalhes Tá mas depois vocês podem dar uma olhada é só uma informação adicional que eu preferi deixar em vez de remover para Caso vocês queiram aprender um pouco mais vocês podem aprender Tá bom mas o que que mais importante aqui né também mandei para minha Matriz de confusão que essa mesma que tá aqui mas é que tá em percentual né Essa aqui é a matéria de confusão a gente vai ver a nossa diagonal aqui que são as que acertou e aqui essa volta diagonal são os que ele errou né então ele errou 80 e eu vou 143 eu vou pouco acertou muito mais do que errou né aí a gente for ver aqui ó 86% das notícias fakes ele acertou como fake né e 93% das notícias que são reais ele acertou com como reais né então aqui observado vocês vão ver aqui aqui observado na no eixo Y e no eixo X eu previsto então aqui observado A aquelas que são fake e ele classificou como real 14% delas então ele errou só 14% das fakes e aqui ele levou 7% das reais aquelas que eram reais ele 7% delas e classificou como fake mas talvez se a gente vê que o desempenho foi bem interessante né aqui pessoal é a mesma coisa que a gente fez agora tá eu vou correr um pouquinho aqui só que agora utilizando o teste e DF como essa outra representação como entrada né não estamos mais usando o Country e aqui a gente vê que a curaça diminuir um pouquinho ficou 85% aqui tinha dado quanto mesmo 89 né diminuir um pouquinho mas isso aí tudo depende da divisão que a gente fez os dados Depende de vários outros fatores tá não é só por causa da representação e aqui tá a matriz de confusão a mesma coisa a ideia é a mesma né também a gente acertou muito mais do que a Ronan se a gente for ver aqui né a gente Manteve o maior erro aqui das notícias fake sendo classificadas como reais né então a gente acaba tendo um pouco mais de dificuldade de detectar as fakes vamos ver né outra coisa importante que a gente pode fazer aqui pessoal é tentar ajustar parâmetros do modelo a gente pegou um parâmetro só do nosso modelo que a gente tem aqui do nosso nariz deles né que é o parâmetro Alfa então a gente só vai fazer alguns testes para cada tipo de modelo cada algoritmo diferente vão ter vários parâmetros diferentes que vocês podem utilizar né alterar porque às vezes vai mudar o resultado por causa disso né às vezes não sempre vai né e a gente tentar escolher o maior né o melhor resultado né que nesse caso aqui é maior acurácia né então a gente tá testando diferentes valores de Alfa que entre zero e um variando de 0.
1 então estamos testando várias 00. 1 0. 2 né até 0.
9 né para valor de alta para ver o que que a gente vai dar de resultado o que que muda né alterando esse parâmetro para o nosso problema aqui né certo aqui utilizar a gente tá fazendo só para o tfdf mas vocês podem fazer para representação do count também nesse último modelo que a gente treinou né que deu 85%, Então a gente vai testando alfas diferentes estão vendo aqui ó para cada valor de alta ele tá dando uma acurácia diferente ó Qual que é a maior que a gente encontrou aqui no olho assim rapidinho e parece que é essa aqui de cima 89,76 por cento Você já viu que já melhorou bastante em relação aos 85 que a gente tinha sem otimizar esse parâmetro né Isso aí vocês podem fazer para qualquer tipo de modelo tá outra coisa interessante aqui a gente tentar interpretar os resultados do modelo né na evidência não é um tipo de classificador que a gente tem uma hipertermidade muito alta mas a gente tem uma certa uma certa forma de interpretar por exemplo a gente pegar aqui os pesos né que representam cada um do do do dos coeficientes lá cada coeficiente a gente faz um mapeamento dos coeficientes do do dos atributos aqueles que são mais importantes né pro pro nosso classificador na RBS fazem mapeamento com qual palavra que aquele cara representa e depois a gente ordena que em ordem de importância a gente consegue ver por exemplo aqui quais são as palavras mais importantes para classificar como fake a gente tem aqui alguns valores né palavras ou atributos né teria que ver depois que representa cada um desses atributos aqui né então aqui né que são os coeficientes mais importantes ou para real a gente já tem aqui a palavra Presidente a palavra americana média e assim por diante E aí vocês podem mídia na verdade né que em inglês e aí vocês podem dar uma olhada nisso também resetar tudo isso e ver o que que tá acontecendo tá E aí o que que eu fiz aqui para vocês no final pessoal coloquei também para construir uma árvore de decisão que a área de decisão a grande virtude que ela tem é interpretabilidade do modelo né então a gente vai ver que que a gente tem de ganho de diferença quando a gente constrói margem de decisão então eu fiz a mesma coisa utilizando a representação tfdf tá só que aqui eu criei uma área de decisão Em vez de criar né aqui ver classify em vez de criar um Live deles né E aí que a gente tem a nossa Matriz de confusão que a gente encontrou o resultado não foi tão bom deu 75% né também não utilizamos parâmetros nenhum né mas é só para a gente ver o que que a gente consegue fazer com a área de decisão aquilo imprimir de uma forma simples que nem a gente tem aqui é uma representação em texto né dessa árvore né Para a gente dar uma olhada Porque como é que é nessa área de decisão a gente tem lá um nó Raiz Ó se essa feature aqui se esse atributo se tiver um valor menor que 0.