Thanks once again for joining in today's webinar. I am the Head of Global Training at h2o. ai and among my responsibilities, I also oversee content strategy and creation, as well as certification programs.
For me, promoting a continuous learning culture is very close to my heart, and that's why I'm here today to talk about the platform called Enterprise H2O GPT. Designed to streamline your experience, this platform is tailored for those in search of answers from their company's internal and secure documents and data, all while ensuring non-disclosure to any external cloud providers if this is what you prefer. So to offer a brief overview, this platform harnesses generative AI crafted by our top Kaggle Grandmasters for business and organizational needs, aiming to simplify access to information within your company's internal data.
You might be aware that privacy, data privacy, and data confidentiality are at the core of our legislation nowadays, and actually, are at the core of any sort of legislation. What we did at H2O was to cater for this by offering you the possibility of not taking the data outside of your company but keeping it private to yourself while you are also going to be able to leverage the capabilities of generative AI and especially LLMs. In today's webinar, we will delve into the following topics.
We are going to have a short introduction, a brief overview to set the stage for our discussion. We are also going to learn what RAG or Retrieval Augmented Generation is, and we are going to see why this is important in the context of our platform. Then you are going to discover a bit about what the H2O generative AI ecosystem is all about and what it has to offer.
Of course, we are going to set the stage for discussing features and benefits of our Enterprise H2O GPT, which is our platform that is going to help you act in a very user-friendly manner to be in control of your data and in control of everything that you want to extract from your data. We will have a short demo, a live demonstration that showcases the practical application of the discussed concepts. We are going to jump in right ahead, and by the end of this entire experience, you are going to be able to have your questions answered.
So once again, please don't hesitate to ask them in the Q&A tab, and I'm going to address them at the end of this webinar. Okay, so let's begin with some opening remarks. So in today's AI landscape, there is significant excitement around generative AI and large language models.
That's why you are also here, I assume. This enthusiasm or excitement has prompted companies to recognize the transformative impact of these technologies because it's a real thing, it's happening, and we are here in the hype of all these situations, seeing how generative AI and how LLMs are actually impacting our day-to-day life. So the demand for innovative content, personalized user experiences, and enhanced communication strategies has shifted AI priorities, leading nowadays organizations to adapt and explore how these capabilities can elevate products, services, and overall business strategies.
This evolving AI landscape not only shapes technological progress but also has significant implications for legislation and politics globally, as I just said before, and I'm emphasizing this idea because the demo will contain UA Generative and Artificial Intelligence Act that I would like to explore with you together. As generative AI and LLMs gain prominence, policymakers face the challenges of creating frameworks that balance innovation with ethical considerations and societal impacts, not to mention the data privacy and all this data security that is so important to be aware of when you want to use a platform with confidential data. So what exactly sets generative AI and LLMs apart?
Before we delve into the demo, let's just cover some of the basics. You might already know that generative AI is a broader category that stands out for creating new data, which is a departure from traditional AI, which was focusing on analyzing existing information. So in generative AI, all eyes are on large language models or LLMs.
And these models are armed with a lot of parameters and trained on a large corpus of data, and this helps them excel at crafting human-like text. Why does it matter so much? Well, because as human beings ourselves, our fundamental means of communication relies on language.
We navigate and express ourselves through words and written text, whether expressing thoughts, sharing ideas, or giving out information. The power of language highlights the importance of advancements in technologies like generative AI and large language models. From my perspective, it was inevitable that this moment occurs sooner or later, and it's better that it is sooner so that we all learn how to leverage the power of gen AI, even though not all of us are coders.
These innovations profoundly shape the landscape in which we interact, exchange, and interpret information in the digital era. LLMs shine because they understand and produce remarkably natural, contextually relevant language. The buzz around them stems from their profound impact on natural language processing (NLP), which helps them understand intricate language patterns and context.
So that's why LLMs are so important, and that's why generative AI, which is a broader category of LLMs, is so important. In addition to large language models, there are generative models for audio, video, and images. However, we will focus on text today because humans are prone to wanting to communicate through words and written text.
It's only natural for us to consider incorporating these LLMs and generative AI into our daily work and lives. The benefits behind these tendencies are significant and encompass at least several compelling reasons. Content creation is one of them, as these technologies excel at generating diverse and engaging content.
Creative assistance is another aspect, providing valuable support in creative endeavors by assisting with ideas and innovation. Natural language understanding is crucial, with models that grasp the intricacies of language and context, enhancing communication and comprehension. Personalization of the entire user experience and data augmentation, in case we don't have enough data and want to create similar data, are additional benefits.
These are just a couple of them. However, it's not all smooth sailing for generative AI because it comes with its own set of challenges. Here are some key points that I observed and that I am going to address through presenting to you the platform because our platform was created as an answer to these challenges, and I am super happy about that.
Biasing data, for example, is a challenge. Imagine training a language model using data that unintentionally favors certain perspectives, leading to biased or skewed outputs. That's something we really want to avoid, and platforms that offer gen capabilities need to be able to identify the bias in the data and mention it.
What's great about different tools is that when you are creating the problem or the question based on the documents, you can write and say, "Be mindful of any bias in the data that might occur. " Our platform has been tested, and our algorithms can observe the bias in the data in most cases. It means that we are not only at the forefront of technology, creating new content, but we are also able to identify biases through the algorithm itself.
And that algorithm is able to come back to us and let us know that that's the case, actually, and that's wonderful. Lack of control: Think about trying to navigate through unpredictable outcomes where overseeing and guiding the generated content becomes a very difficult task. So it's not up to us, the user, to control the information but to the platforms that are actually offering these products.
Security concerns and data privacy: That's something that needs to be addressed over and over again because as a user, I want to make sure that when I upload my data to the platform, if I want that data to stay on my local service on-premise, for example, I can have that option. It's not mandatory for me if I want to use the service to upload it on the cloud, and that's definitely a possibility when looking at gen AI capabilities that we, here at H2O AI, offer. Resource intensiveness: That's yet another point that I am interested in developing because the challenge of dealing with a hefty demand for computational power is big.
This computational power is required not only in the training phase but also in the deployment phase of the model. Not all individuals and companies will be able to leverage its potential if they don't have the hardware. So being able as a software provider to give access to efficient algorithms that are also not so intensively computational in terms of resources is extremely important.
Understanding context: That's another challenge that gen AI faces because if you're not providing additional context in the form of prompts or written text, it would be very difficult for the GPT to give you the answers. Understanding context is very difficult, and the difficulty of teaching a system to grasp the subtleties of the context are big. But we want to make sure that we ensure that the content that is being generated is going to make sense and be useful to us.
That's where we started our discussion about developing a platform that wants to give this possibility of having more context to learn about. So understanding context stands out for me as a crucial aspect and significant challenge for large language models. When you ask a question to an LLM, it generates a response without considering additional text.
To receive meaningful answers, you must excel at crafting precise prompts or ask the right questions in a very detailed manner. Additionally, you need to make sure that the latest information to the algorithm is being provided, not only from five months ago. However, as a user, this is, in most cases, out of our control, and thus, LLMs or generative models have limitations in understanding context, resulting in superficial solutions to problems.
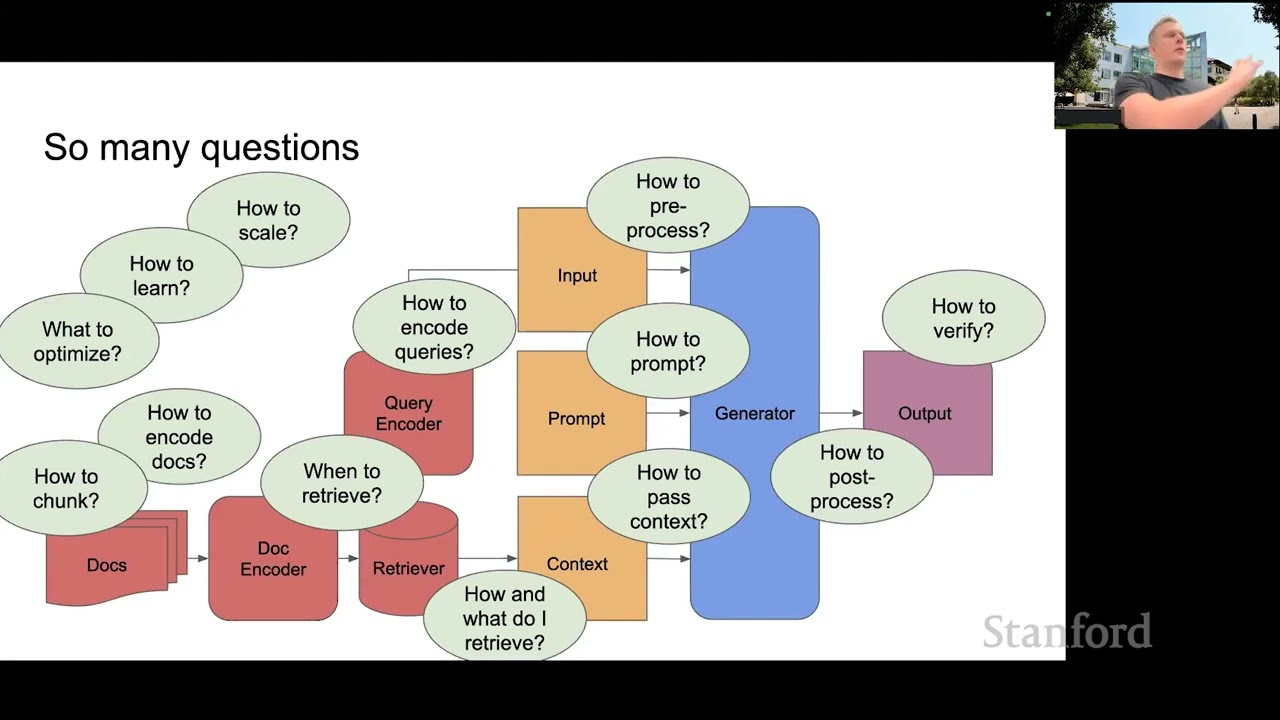
Now, I'm going to explain the idea of RAG. This is where RAG, or Retrieval Augmented Generative Models, comes into play. RAG addresses the challenge of context understanding by using what data scientists call a retrieval system.
This system fetches relevant information to help the generative model better grasp the context, ensuring that the generated content fits the situation accurately. This way, for example, RAG enhances the model's ability to create content that makes sense and aligns well with a given context. RAG is an AI system that blends retrieval models to find information quickly and accurately from a large text database, for example, a PDF document or a huge amount of structured or unstructured databases like search engines.
It then combines this with generative models that create new text based on a prompt or an input, useful for tasks like writing articles or generating chatbot responses. So I assume that the majority of you have until now used more generative models, but the majority of you have not actually had the occasion to implement retrieval models through the interface by extracting information from a given document. This is what we are going to do in the demo.
But before, let's once again make the distinction between the two of them. We have generative models and retrieval models that work together to create something called RAG or Retrieval Augmented Generative Models. They are like machines, LLMs on steroids, let's say like that, because you give them also documents to work with.
Combining these models makes a RAG system powerful and flexible. For instance, it can use a retrieval model to find relevant information swiftly, and then it can use a generative model to create a summary or a response based on that information. This proves valuable in situations where information is intricate, and a simple retriever or generation approach may fall short.
Now, you might be thinking, "Andrea, I got it. I see the distinctions between generative AI and large language models. I understand the pros and cons of generative AI specifically.
I see how RAG can help with contextualization and context understanding in general. But how does this all affect or connect to the H2O AI ecosystem that you want to present? " And I would say that's a great question, and I'm aiming to address this next.
In advancing our generative AI capabilities, our focus has been on harnessing open-source models, which culminate with the development of our H2O GPT, and this is open source. You can test it for yourself on our website, and I would highly encourage you to start playing with H2O GPT. This system includes a large language model that you can select according to your own needs.
You have the possibility to select your own large language model. It has a command-line interface and a user-friendly graphical interface. I already did a webinar on that, so I would encourage you to go on YouTube if you're interested also to learn more about it.
But that's the first stage that we focused on. Then, what we wanted to do is to build on top of it. We've introduced the LLM Studio, a framework that is equipped with a no-code user interface, which is tailored for the fine-tuning of large language models.
Because the majority of the GPTs that are out there don't offer you this possibility of fine-tuning. So H2O LLM Studio is a versatile tool that streamlines the entire fine-tuning process and allows you easy adjustments for various hyperparameters without the need for coding expertise. Once again, we want to take the tools and the knowledge that we have acquired through our machine learning engineers and Kaggle Grandmasters and put it in the hands of the people who are not necessarily interested in learning how to code in Python or going in a lot of depth to modify the parameters of the tools.
That's why we wanted to make it simple. As part of our commitment to innovation, we also integrated RAG technology into our platform. So we leveraged vector databases within RAG, which enhances the capabilities of our platform.
These vector databases improve the system's efficiency in general to retrieve relevant information. Remember, we discussed retrieval models. With the vector databases, we are able to improve the retrieval of the data that we apply our models on.
The integration across H2O GPT, LLM Studio, and RAG with vector databases actually strengthened our approach to enhancing generative AI and contextual understanding in general. So our team of machine learning experts has created a lot of generative tools. It would take a while for me to talk about all of them, but there's a quick overview here on this slide at what our H2O AI and gen ecosystem includes.
At the top of the slide, we started by introducing tools to simplify machine learning in general, such as AutoML capabilities. We developed advanced models using deep learning, adapted, and deployed these models on-premise or on the cloud. We streamlined the app creation process with user-friendly interfaces accessible to everyone, and that was the first step for us.
The second step is exactly what you see underneath when we started to incorporate capabilities of large language models across our platform. This means we now offer tools for the entire generative AI lifecycle from importing and embedding data to pre-processing, fine-tuning, evaluating, and deploying everything related to gen. This extensive package is referred to as H2O LLM Studio Suite.
The entire thing underneath the rectangle is the LLM Studio Suite, with Enterprise H2O GPT being just one of its offerings. So underneath Enterprise H2O GPT is one of the offerings consolidated within a platform that incorporates the entire LLM Studio Suite, and that's what I am aiming to present to you today. H2O AI is Enterprise generative AI, or H2O GPT offers advanced document chat features, including fact-based question answering, a pre-loaded Wikipedia state, offline mode.
It also includes a persistent database with vector embedding, and this system supports a lot of document types that you can query and inquire at your own desire by using easy-to-use interfaces. It employs RAG, so this entire interface uses retrieval models and generative models to give you the best and most accurate answers. This RAG technology is used for context understanding and data understanding overall, guaranteeing that the entire Enterprise GPT ensures safety, control, and transparency for the users.
In addition, it offers the Python API, which lets you use the H2 GPT's advanced capabilities in Python projects, and that's for more coders here. With this API, and if you are a code-savvy person, you can leverage the platform further and tap into large language models and apply gen for content creation. By coding, you can work with the vector database for managing embeddings, implement RAG to enhance data understanding, and all is seamlessly integrated into your Python workflows.
So you can use the interface as such, or you can use the Python API, and it is a powerful tool for data scientists and developers to leverage these features within Python applications. I think that is also another way that we come to the core of us being machine learning engineers in the company and Kaggle grandmasters. We also think that even though we want to facilitate, show the things for everyone, we can also give the possibility for expert coders to go beyond and above to personalize and customize their models even more.
So by saying that, allow me to head to the website and access the Enterprise H2O GPT once again. Please don't hesitate to ask your questions in the Q&A section. I will take them at the end of this demo.
I would love to see what type of curiosities you have with respect to what I presented until now. So don't hesitate to do that. Also, for this demo, you can follow along because this is a platform that is open source and accessible for you in a trial version.
So I would highly encourage you to do that. What I'm going to do right now is to connect on h2o. ai, and that's our website.
If you hover over on the top of the screen to the platform tab, the first thing that you are going to see is a column called generative AI. And so the first row in this column is Enterprise H2O GPT, and it is also written here, private powerful LLM Search Assistant for internal teams to answer questions from large volumes of documents, websites, and workplace content. So what is great here is that we have this emphasis on internal teams.
So we have within this platform a lot of collaborative tools so that when your company is interested in working with this platform, you are able to share all your projects and what we call collections with your team members. You are able to publish them. You are able to actually make them public.
So all sorts of things that we incorporated within the platform so that we enhance these collaborative capabilities. So I clicked on the tool itself, and here you have at the beginning a video that showcases a bit what this platform is about. It is about information retrieval on internal data, privately hosted LLMs, and this way your data stays with you.
So that's like the strong core point that I am willing to emphasize. So in addition to having H2 GPT capabilities where you would ask questions and receive generic answers, you might also be interested in uploading your own internal documents and extracting information from them by leveraging the generative models but actually using retrieval models to find the information. So just think about having let's say a client's internal document that is unique in the world just created by your company for your company's internal use.
This information you will not find anywhere else. You would like to keep this document internal to the company, safely stored. Nevertheless, you would like to actually improve your experience and your work, make it more efficient and faster and more reactive by querying hundreds of pages of this document in a couple of rows.
And so you would receive actually here the output of the document with the page number as well as the accuracy percentage after the output is being created. And that's awesome because not only you will receive a short summary of what your interest is about by querying the Enterprise generative platform, you would also receive the pages previews of where those answers are going to be found. So without further ado, let's just click on the TR now, and we are going to be redirected to a new tab called Enterprise H2 GPT, and the link is the following one: H2Ogpt.
gen. h2o. ai.
So this is open for everyone to use. I'm going to actually walk with you a bit through the platform so you understand the main functionalities of the platform, and we are going to upload the document just to see what the capabilities look like. So here you are prompted on the homepage where you have the dashboard with your identifiers and the possibility to create a new collection, take the collection as a project where you are going to have all your chat sessions as well as all your documents.
As for the moment, I uploaded the document. Let me actually see if I did that. Okay.
And this is a document called EU AI act. So I can see all my documents here when I clicked on the documents or in the form of a list. What is great about this tab is that I can actually select the documents and delete them if I'm interested.
So I'm going to have a row with the type of the file size of it, number of pages, whether or not the status is being complete or indexed in this case, as well as when this was uploaded. So I'm going to pick it so that we can delete it. I want to delete this file so that we will re-upload it once again.
So on the homepage, once again, you have the number of active chat sessions, number of collections, and number of documents. This is the page that you will also be able to see when you connect on it with zero collections, chats, and documents. This is something that we need to create ourselves.
Underneath, you are going to see the entire history of recent chats, collections, and documents. And here, just underneath the home button on the left side of the screen, you will be able to see the three tabs and their particular visualization. So you have collections, documents, and chats.
If I click on collection, what I can do is actually to create a new collection. And I can actually select, let's say, webinar Enterprise GPT, and I can give a description. So take this as a project creation, and I can create this collection.
And here I will be able to upload all my documents that I am interested in using. So once I created the collection, I will be able to see all my collections if I click once again on the tab. So here you will see all your collections or your projects.
And mind you, this is a private collection. So if I am using company Enterprise installed application, I will be able to make it public. Nevertheless, it's not the case because this is an open source.
So we just want to have the control over these functionalities. Within these collections, actually, what I can do is to view the collection itself. And then I am able to enter within the collection that I just created where I can see the number of documents that are being stored, the size of all these documents, as well as when this collection has been created.
On the right side of the screen top, I can click on the settings. And so here I can modify the collection name, the description. I can also share it with my peers or my colleagues in case this is installed on my own company servers.
And what is great about this is actually that I can set prompts by default that will propagate all over my documents and chats that I'm going to use within the collection themselves. So by default, we have an example, but of course, we can change it. So here we have the first system prompt: "You are H2O GPT, an intelligent retrieval augmented gen AI system developed by H2O AI.
" So we are giving context to the collection, what this collection is, generation approach, rack type to use. So here, if I click on the drop-down menu, I have four options. I have the option to use only LLMs, so not rag actually.
So I have the option to generate information without retrieval models. I have the option to use retrieval models, and I have two more advanced options. Of course, we have documentation about this that goes into further details where you are able to use embedded LLMs, rags, as well as query once or twice.
So that's a detail here that maybe code-savvy people are interested in. By default, we are using rag. And since I had the presentation about what it means, now you are able to understand that rag uses retrieval models that are going to extract information from the documents that we are going to upload here.
And we are going to actually have a personalized output that uses generative models for output creation as well as rag models, retrieval models, for personalized outputs. Next, we have a rag prompt after, before context. So pay attention and remember the information below which will help to answer the question or imperative after the context ends.
Of course, you can change it. And usually, if you're using H2 GPT or any other GPTs, you might rephrase this paragraph by giving bullet points. And so you are saying, "Every time when I'm putting something, take into consideration that I want this paragraph that I'm going to input in the chat with bullet points, rephrased maybe shortened, etc.
" Right? So this is a guideline for the GPT to learn how to treat your text, what is the style, maybe if you have clients that let's say are over 60 years of age, you would like to use a more polite version when answering than to people under 20 years of age. You would like to adapt to the times, to the customs, etc.
So all of this is great, and I find it so useful in comparison to any GPTs that don't have this option. You also have the possibility to use a rag prompt after context. So according to only the information in the document sources provided within the text above.
So this is a way to say, "Don't hallucinate, don't create new information because you're also using generative AI. Just give me the strict information that you found from the text and don't create, don't make things up. " Right here, for example, as compared to the challenges that I presented to you, you can say here, "Don't show me any possible bias within the answer or the data.
" So you can create and put here a address within these rag prompts any sort of challenges that GAN has, which are not completely taken care of without the emphasis on specific prompts. And then I can click on update. And what happened is that at the level of this project, all these prompts are going to be taken into consideration by default whenever I am uploading a document and asking through a chat information about the document.
So let's do just that. I'm going to click on "Add Documents. " And I'm going to be able to do multiple things.
I can upload documents from my own PC, from web pages, and from the file system that is connected to the server where the platform is installed. Let's say I want to upload the document from my PC, and I'm going to go to Downloads. Here I have downloaded 350 pages of a new AI act that I'm able to upload within the platform.
This has been successfully taken into consideration, and now I'm going to click on ADD. What happens now is that I am brought to this Jobs tab where I see all my active jobs. As you see, I have already created a couple of jobs where I deleted a document 7 minutes ago, as well as I'm ingesting a new document.
I have also created and tested some of the things just to see that as a user, you have the tracking and the history of what happened on the platform. I see that I have my name here, and this is being uploaded, so the document is being ingested and now has actually completed to be ingested. So once again, I have the collection, and within this collection now, I have a private item that is 860 kilobytes.
Okay, and now what I'm able to do is to search this collection and start my first chat. So I have this EU AI legislation documentation. Maybe I'm interested to ask specific questions with respect to this.
What are the top three legislation proposals with respect to generative AI? Let's see. Like I haven't tested that one, but what happens now is actually Enterprise GPT searches all the 350 pages of documents and is coming up with an answer.
What I like with respect to this is that it's still pending, but I can actually visualize particular parts that are taken into consideration. So when I click on this, I can actually visualize, so I receive a small summary with respect to my question, and also I receive all the pages that have been concerned by the output. So here I have a couple of pages, each of these pages with their output and accuracy score, let's say, with respect to what the algorithm has found.
So the answer is based on the information provided in the document sources that was a prompt, if you remember. The top three legislation proposals with respect to gen AI are: Proposal of a regulation on AI systems which aims to establish a framework for the development, deployment, and use of AI systems in the European Union. I just took this one because I live in France, so actually I was curious to see what happens.
Amendment 114, which proposes to authorize the placing on the market or putting into service of AI systems that have not undergone a conformity assessment, blah, blah, blah. And Amendment 115, which proposes to require providers of high-risk AI systems to register their systems in a UA database. Nice, nice, right?
So actually I really have concrete answers with respect to this document. Of course, if I would be a lawyer and I would have all the keywords possible to ask more specific questions, I would. But I'm not, so what I'm going to do now, let's say I want to save this and make it shorter.
Let's see what happens. So now let's see if actually it was able to detect my query, hoping that it would take into consideration the previous prompt, which I think is actually the case. Shorter version of the information.
So the document discusses the proposed EU Artificial Intelligence Regulation. So actually what I asked is, take this document and try to summarize it as short as possible. The outcome, like I just consolidated with the help of Enterprise H2 GPT, 350 pages in 10 rows or so, right?
Which is great. I think it's great. And what is also great is that you are able to go into the chats and normally you will be able to visualize the chats after a while because you just queried the collection.
So here, I was curious just how the document looks and what it functions, what it looks like now. I will be able, after this page refreshes, actually to be able to see the history of all the chats. And what is great is that I can personalize the chats even more if I want to.
So I personalize the parameters and the settings of this document, but I can go and let's click on start your first chat. And now, I really have, in a sort of a history archive, all the information that I was interested in. So, give me the short summarization of Law 15.
Let's see if it recognizes that this is the law and not an amendment here. So that's what I asked. Okay, okay, sure.
There's a short answer based on the provided document sources. Law 15, also known as the Regulation on Artificial Intelligence, is proposed to ensure that systems are developed and used in a way that respects human rights. Now, make this shorter, please.
Also, observe the fact that you also have all the references, and this is great if you want to go into further details. Like, I think we all use that PDF option, like Ctrl+F, to find a particular keyword in a PDF. Well, take this one as the most updated and advanced version of that thing that also incorporates AI into it, right?
And so, it keeps account of the context, gives you information. Now, I see that my recent chat was created a couple of seconds ago, and I have a preview with respect to what that chat was about. This is great because when I click on it, what can happen is that I'm able to share this chat.
I can copy this link and share it with my friends. I can also click the button "Show Related Chat. " So, here, I will have all the related chats.
Let's say we have hundreds of chats over the month. You're going to see all the related chats that have the same type of information taken care of. What I can do here is actually go beyond and modify the settings of the entire collection or project by adjusting and making it more personalized.
So, for example, I can change the style. I can put here "Use the language of a 10-year-old child. " Let's say I would like for this to be very easy to understand, and I'm updating the information, so I would like maybe to make it shorter.
But now, I am focusing on also having a simpler language. I could have just said that, right? So, maybe I don't understand all the things in this document because they are too specific.
So, what I'm trying to use here are prompts that are predefined so that we can modify the settings and use them in a format that takes into consideration that type of language level or uses the format that is more frequent for non-native speakers of the English language. So, this is it, guys. The idea here is once again to explore it by yourselves.
You're going to have a lot of fun with these collections and just test it by yourselves, uploading documents and extracting information out of it in a very intelligent manner. That's what this entire platform is about. So, don't hesitate to play around.
The last thing I want to show you is the fact that you can actually generate API keys and incorporate them within your Python notebooks. So, here's an API that you can generate, and this is what this code would look like. So, you're able to create a new collection.
We have specific functions and attributes for this. You're able to use this to upload documents and then create chat sessions, query the collections, and reply within these queries. You can also create a test API that you can attach to your own collection.
And you can generate this API that I'm going to copy and keep to incorporate within my own notebooks. There is not enough time for us to do that, but just be aware of the fact that you can use the APIs within Python notebooks to leverage all the potential of the Enterprise GPT platform if you so desire. So, we did a short presentation of the Enterprise H2O GPT platform, and I'm really hoping that you were also able to test yourself some of the things.
To sum up our presentation for today, we began by introducing the difference between generative AI and large language models. Large language models are a subcategory that concerns only text data from the broader category that generative AI is. We also delved into the various benefits and challenges associated with generative AI, setting the stage for an insightful discussion.
I hope through this session, we also learned what RAG is all about or retrieval augmented generation. We saw that it uses something called retrieval models and generative models so that it leverages the capabilities of LLMs beyond the generalization point and adapts it to specific text that you are going to give to it. We also looked at the H2O generative AI ecosystem and saw what the advantages of having a seamlessly integrated platform are all about.
The fact that we offer an end-to-end generative AI platform for any sort of generative AI lifecycle is something that is super useful, at least from what I see from our clients. Our journey here ended with the demo, and I hope I provided to you a practical demonstration and showcased the functionalities of Enterprise H2O GPT, how it can be seamlessly integrated into real-world scenarios. Before taking questions, if you're interested in learning about our LLM learning path that I am going to present, it's a course that I created.
Don't hesitate to connect on YouTube and take the courses out there. We have a lot of courses and information that I would encourage you to check out. It explains theoretical concepts and then shows how they apply to our ecosystem.