[Applause] right good afternoon everyone my name is Manos I'm a Solutions Architect on AWS specializing in big data and analytics so today we're gonna we're gonna be speaking about really about big data we're going to go through architecture part the principles and some design patterns we have to cover quite quite a lot so the way the way we're going to play today and I'm gonna talk to you some of the big data challenges that I see and I discuss with with my customers and then I'm gonna discuss through some architectural principles some things that you
you need to remember when you do your your architecture and then we will simplify the big data processing into smaller steps and then we're gonna dive deeper into each step and I will start identifying some some tools that you you could use on those on those steps then we'll combine all those steps together into some sort of reference architectures and in the end we'll we'll finish with some customer examples now the types of big data analytics we're going to discuss today it's going to be bad and interactive type of analytics streaming analytics and some predictive
analytics some sort of that are powered by some sort of machine learning algorithm now because we're gonna speak about big data and and the cloud and I'd like to step back a little bit and think how the cloud has evolved since AWS pioneered the cloud started with virtualized instances where customers were able to spin up virtual machines and then you were restoring your applications and then you will start running and your code but then that evolved into managed services where AWS took more responsibilities AWS then started to manage more on the software stack so you
didn't have anymore to upgrade lycée application it was managed by AWS but still you had to provision as a customer you had to provision to think about servers you had to think about memory CPU you have to think about all this stuff and this where serverless paradigm comes this is where the serverless and cluster less computing comes which is the evolution we're customers don't have to think anymore about about capacity instead you really focus on on developing your application code and it comes to me when it comes to analytics that that means you're you know
focusing to develop those analytical queries that will make a difference to your applications rather than focusing on upgrading frameworks and upgrading the applications so today we're going to cover and we're going to dive into some tools and there will be quite a lot of tools a lot of which are coming from the open source kind of stack of tools and especially around the hadoop a kind of ecosystem but also I'm going to describe a lot about some AWS services around the analytics so let's let's start with the the challenges first so really what what the
customers wants to understand is 2002 Spanish when we have a problem right they want to the standard what is a reference architecture but that I can use to solve my problem and what tools that architecture has what tools should I use and then different tools how to bring those tools together and then why to choose one tool over the other so today's session is about about about this really about understanding the different options and help you choose the right tools okay before we start all the tools conversations let's let's define some architectural principles so we
have kind of a common framework as we're going to go through those those options the first one is a general kind of good practice and good architecture and principles in general not just when you design big data systems is when you design a pretty much any system is to build the coupled systems really separate the concerns instead of having big monolithic application separate the concerns into smaller systems and then what that allows you to do it allows you to iterate on each and every subsystem and this is how you can truly build and evolve over
time now from a big data point of view and really what means it comes breakdowns into storage processing and analysis of the data and their the the way you store the data really shouldn't really mandate the way and you process the data and equally the way you process the data sitting really Monday the way you analyze the data so they should be independent now the second architectural principles is really use the right the right tool for the job and in order to identify what is the right tool there are a couple of questions that you
kind of need to ask yourself and it really comes down to the data structure and to latency requirements as you might have the third one might not be an architectural principle but certainly something that definitely we recommend our customers do and this is about using magnet services and server less services where possible by doing that and you inherit a lot a lot of engineering effort that AWS has put in place to build those services you inherit a lot of best practices AWS put in place to make this those services scalable to make them highly available
reliable secure and you save also some admin cost because you don't have to again to upgrade applications you don't have to manage service behind the scenes and the other one is to prefer for when it comes to analytical systems and tuinal to to big data systems to to prefer immutable data sets like a data leak and where you want to capture the state of an application to load them as materialized views rather than updating records that introduce complexity and finally and cost is part of any architecture so we will talk today about some ways to
optimize cost when you architect systems analytic systems on AWS okay now let's let's move on to think the simplification of big data processing so what we're going to do now we're going to go on each and every step and the steps are collection storage process and consumption and you see those arrows the those student shouldn't name doesn't have to be a waterfall process right so storage could you could store the data then analyze the data then you cannot kind of the process data said you can then store it back and then analyze so it's kind
of iterative as well so what we're going to do now in the next few slides we're going to go on each and every step and then we're going to start discussing the technology options when it comes to architecture so we'll start with collection so when it comes to collection and the first thing you have to think about is about the type of the data that you are collecting so what are the types of the data I'm Carly I'm collecting so first we have data structures database records these are data that typically are coming from mobile
applications from web applications and let's call those transactions and second category is object or all files and the third is about data streams let's call those events okay now I'm going to dive deeper on each and every category okay so in terms of storage the first the transactions really typically we would store them into a database system either sequel no sequel in-memory cast it's a database system the medial the the files you really would go to an object store and then we'll discuss the options there as well and then the data stream really will go
to a stream storage so again now let's dive deeper a bit and we go now and it's in every category too let's start with the stream storage so when it comes to stream storage what are the options I have on AWS so the first I'd like to kind of introduce Kinesis Amazon Kinesis communities is a family of services and there are two services that I'm going to discuss today it's the Genesis data streams and knishes data firehose and I will explain what is the use case of using those so Amazon Kinesis Amazon Genesis data streams
is a distributed and durable string storage that you can ingest thousands or millions of events per second and what it allows you to do it allows you to have multiple kind of producers - pushing data to the stream and then multiple consumers reading from the stream now Amazon Kinesis is fully service it kind of fits into that category with discussed earlier and what that means when you provision the provision streams and you don't have to you know to think about kind of CPU memory and resources instead you provision charge not they're called and one shard
kind of corresponds to 1,000 writes per second so let's say if your application has 10,000 messages per second that you need to write then you need to provision 10 charts for your stream then what Kinesis allows you will store the data up to up to a week and then you can have your consumers application readings from the stream and that will allow you to do real-time analytics now we have a lot of customers though who don't necessarily want to do real-time analytics what they want to do instead they want to capture the data from the
stream and they want to deliver it to a data lake for further analytics later on and this is where you should consider Kinesis data firehose which is a delivery stream think it as a pipe that will deliver your data to a target and then that target then will be your system that you will do your analytics later on now when it comes to streaming and you know the conversation always will have the word Apache Kafka and Apache Kafka is also high you know a distributed streaming platform it is durable and it's coming from the open
source community so there is huge support for Apache Kafka out there so when it comes to Apache Kafka as of now you can you can kind of fit to the virtualized kind of service where you could install Apache Kafka on Institute's which that means you you you know you have all the configurability by configuring Kafka applications however that means that you have to kind of have admins and around the CAF that you need to administer the Kafka clusters and this is where we released in reinvent Amazon msk which stands msk stands for magnet service for
Kafka so we heard our customers asking us to help them to manage more on the Kafka lair and we have now a service at the moment is in preview but it's in public preview meaning that actually you can go if you're an AWS customers and try it out in fact three days ago it was released in Ireland as well in Europe now Amazon msk will fully manage zookeeper for you and then you know with you know the console or it or the API as you can create character clusters in minutes moving on and we will
have quite a lot of those tables some of them I will skip but the presentation slides will be made available and the key point here when you select and you look over all the options really think of the use case first and if the use case is just a one single message to unconsumed one producer and when you have the consumer reading from the message you want the visibility time out this sort of behavior then sqs is the right service to go for you know to those queuing systems are still are still valid but when
you've got like multiple consumers multiple producers and then is when you have the kinases or Kafka and how to choose between kinases or Kafka what kinases will give you Kinesis will give you a tight AWS integration it's a fully managed service you don't have to think about servers what Kafka will give you the open source kind of tooling around it full configurability with the kind of overhead of the admin overhead which is get reduced let's say when you go to an escape ok moving to the next cutting to the category the file category and the
server is really the de-facto service to store files into AWS is really Amazon s3 and Amazon s3 it will allow you to to store any amount of data and you can retrieve any amount of data there are a lot of use cases for allows ministry in fact is one of the oldest service integrated with the rest of AWS services but one of the use case is very strong use case is to build to use Amazon s3 as the center of your data Lake and there are a couple of reasons why a three is actually good
for being you know the storage for your data Lake it's open and comprehensive and it really that means that you know apart from integrating with the rest of the AWS services actually outside of AWS like Hadoop clusters like our partners cloud era Hortonworks they speak natively to to to s3 now what this trick will allow you by by using it as a storage it will really allow you to decouple storage and compute and this is quite powerful when it comes to big data analytics and I will try to explain a little bit more about that
so by having a storage outside of your let's say Hadoop cluster what that allows you to do it allows you to run what we call transient clusters over your data set and what is the benefit there by having transient clusters excuse me by having to transit clusters you could be fine clusters that are short-lived and you can introduce some sort of steps when you configure them and when the steps complete then the clusters you that cluster can terminate which means that you you've done your analytical job you've stored the output again back to history and
the cluster has completed now what's the benefit there the first apparent the benefit is the cost will aw as you pay on before what you use meaning that if you have a cluster for ten minutes you pay for ten minutes and goes on now the other benefit though which is it's around really the innovation that allows and the flexibility that gives you because you could now you can actually run multiple clusters multiple Hadoop clusters and they might have different configurations so for instance and you might have like SPARC Apache spark that really when you're doing
interactive analytical at a party spark really wants that memory so you can have what you know those are five instances that are memory optimized so that you can have a Hadoop cluster like that but also you can have GPU and Hadoop clusters we to run tensor flow for machine learning so with the same data set to different clusters and really that allows you to and to really build the right Hadoop cluster for that for the job you need to to complete and the regarding the cost I've mentioned also this kind of an is the cost
saving is enhanced by Amazon ec2 spot so there is a really great use case of of spot instances with Hadoop with Hadoop a Amazon EMR and why is that if we think about Hadoop in general Hadoop has or has been architected to tolerate individual or even multiple node loss even when jobs are running and this is a great if you think about the spot instance the spot instances means that you are bidding for unused capacity in AWS data centers and if you combine those two together means that you can do a combination and create like
on-demand instances which is the standard with you know they don't get interrupted is the only money instances and with combinations with spot instances and then you can have your transit cluster and spot instances will give you up to 90% saving when it comes to cost this does matter when you have clusters of 10 20 hundreds of nodes makes a big difference other reasons for s3 being ideal for the data lake to be the storage of the data lake is its durability and it has been designed for a level nines of durability and one of the
reasons that it achieves that durability s3 actually s3 behind the scenes is using our availability zones so within a region when you put data into history s3 will replicate the data automatically for you there is no additional charge for there for that it's it's the default behavior so that is how you know s3 is durable one of the ways that we're on the region's s3 is durable it's secure so s3 will allow you to encrypt data in transit will allow you to encrypt data at rest and it's cost-effective and I would like to actually expand
a little bit more of ways to cost optimize Amazon s3 and one of the ways to optimize Amazon s3 is to use those tiers those data tiers so for the kind of the default standard tier is for frequently accessed data so for the data that you are doing analytics frequently that will go to the Amazon you know standard s3 tier and but then what s3 actually gives you the option to move data to infrequent access and then this is where you save cost by moving the data down to infrequent access and there are let's say
that cold storage which is like archives this is the Amazon glacier which is kind of very cold storage this not doesn't necessarily make the villa the data available for you to do analytics at the same time but with Amazon s3 standard infrequent access actually you don't compromise performance so you can actually have the data available to do analytics it's just the pricing model that works differently but Amazon glacier though you save on cost significantly but the data is stored as archive last week we made also available the deep archive which is the cheapest way to
store data basically on AWS but you're the trade-off there is the retrieval times is hours rather than minutes okay and about HDFS so a lot of some discussions with customers about HDFS like if you're familiar with with Hadoop HDFS is the Hadoop distributed file system is where Hadoop by default would store the data and and customers ask like okay I have the data industry do I need high DFS anymore and the answer is maybe and there are some use cases that you could actually use HDFS so what are the use cases if you are doing
analytics over the same data set actually you could benefit by loading the data into HDFS our - Hadoop you know EMR it comes with HDFS so you could leverage HDFS and if you engineer Hadoop you could potentially get a use of the kind of data locality although it's hard because HDFS is also distributed so there will be data flowing around the nodes but there is that that room for HDFS that can't be used if you if you if you do analytics over the kind of the same rather than fetching it from s3 all the time
do analytics over astray over hates DFS and there is actually a little utility that comes with EMR called Street DCP dist copy that will use a MapReduce job to fetch the data distributed in parallel from from s3 okay I'd like also to mention about metadata in order to fully decouple your date your data though your data from from compute is data is once one part of the equation also metadata is the other part you need to have both outside of the cluster to be able to do those transit claim our clusters and what are the
services about the metadata I'd like to highlight firstly AWS glue catalog so AWS glue catalog is a fully managed data catalog and it's hive metal store compliant now what is the purpose of route galaga glue catalog really it it's there to be the unified central data catalog across your data sources that you want to do analytics on and what then you have the Athena EMR and redshift all the kind of group of AWS services that there are integrated with the glue catalog so you can explore those data sources right away there will be no effort
to to plug them together a glue has a also a kind of a utility let's say the the glue crawlers which is an application that you can point to your data sources and that could be industry that could be also databases and then it will explore the data and will try to identify the metadata for you so that it will create those tables to make it a little bit easier to you know to find those schemas it kind of makes it easier when it comes to data legs and okay I say that so hive Medicaid
when it comes to to data legs you still you still have to go to a few places let's say to create it so we've discussed about s3 for the storage we've discussed about the metadata the glue catalog there are also you know what we hold the I am identity and access management to do security so there are a couple of places that you need to go in in order to create a data Lake so we identified that and then we've released lake formation and that was that is currently in preview so lake formation is there
to help you assist you to create a data lake in AWS within a few minutes so it does build over those services that describe so it will use s3 behind the scenes it will use glue catalog it enhances those and those services with additional metadata and also it will it will introduce some more also some data quality jobs that you will do on the data to kind of deduplicate the data or find matches where there is no common idea available so I'd like to highlight that this is a private preview at the moment so you
need to sign up and then it's kind of a white listing so will be some conversation about your news case before you get your hands let's say - like lake formation and for completeness just to highlight the hide meta store you know glue catalog is one of the options it is the easiest option but for completeness also I would like to point out that you have also have metal store that you could build for instance and you can host it on Amazon RDS ok and moving to databases there was a session on database so I'll
go through a bit quick from databases databases from an analytics point of view could be either our source of the data that we pull the data from the databases so that we can do later analytics can be also the target of analytics you might want to you might have built some analysis some data and then you want to push that data back to to a database so that you have like a real-time dashboard or something really the key message here is the best the best practice released you know you use there right there are so
many database options on AWS you need to use the right tool for the job and just to help you identify the right tool is back to those questions that you need to ask yourself and the main the main two questions is about the data structure and how the data will be accessed so if you are if your data structure is still is kind of a fixed schema then probably sequel is the way to go especially if you have complex relationships and if you have table joints if this is the way you access the data then
you know you should evaluate SQL databases first if your data though has no fixed schema or it has a simple key value pair then you should evaluate first and no sequel database and if your latency requirements are really low to the microsecond then yes you need to think of in-memory cache in front of your database system or the in front of the no sequel database and if you have graph kind of traversal for queering or if you have graph structures in your data you need to evaluate first a graph database so there are quite a
lot of characteristic again those slides will be made available and the main two characteristics its line one which is the use case line three the shape so these two are the ones that we really will hint we will show you what sort of database systems to use okay moving to to the next step processing analysis so when it comes to personalities I'd like to highlight now the services what they do and then some use cases first we start with interactive and but analytics so some service a couple of options there so we've got Amazon elastic
search and Amazon Elastic search will allow you to spin up elastic search clusters in minutes and what are the use cases for elastic search well the strongest use case I am saying is about logs logs analysis so if you have logs and you want to have dashboards with kibana this l.k stack Amazon elastic search is great the other use case I see as well for for data lakes is also some metadata indexing so if you will because elastic search is a search system and it will allow you to actually query using some sort of search
so you could actually do a lot of stuff like even tolerate typos you could do this sort of experience you know search experience to your to your queries you could index metadata to elastic search about your data and then you can have an additional search ability over your data sources in the data Lake this is also another use cases have to be you know something that you are querying for analytics it could also play a role to help you explore your data Amazon redshift and spare ft spectrum the redshift is our fully managed data warehouse
and Amazon redshift is a what we call an OLAP system and online analytical processing systems or in a massive parallel processing system alright so it will allow you to query terabytes of data petabytes of data sorry and Amazon redshift really it's a kind of you know you it would be like a schema and read kind of a system which means you define the scheme upfront kind of highly structured data what you put in in Amazon redshift now there is also an extension Armas Interactive spectrum and Amazon redshift spectrum will allow you to query data in
a three I would like to explain a little bit more what is the use case of spectrum so let's say let's imagine that you have a data warehouse and this is where you drive your monthly or weekly or daily reports from so the data there is high quality data and highly structured data but there is still a lot of the day a lot of data that reside in your data Lake in Amazon s3 and for one reason or the other they didn't make it all the way to the day to the data warehouse maybe was
lower quality but they still hold value so what rates if spectrum will allow you to do it will allow you to combine data from that side of the data like with your high quality data from the data warehouse Amazon relative to this one single interface and actually spectrum will be able to to query to the limits beyond redshift because redshift has you know to petabyte actually to spectrum will go to exabyte because you will utilize the nodes closer to a3 not necessarily your your redshift cluster will just bring the results back to your cluster just
to present it back and Amazon Athena another great service for a kind of the service category that will allow you to do a sequel queries over your data in s3 and the skill set that you will require to be able to query with Athena is really if you have presto skill or you know presto the interface would be an unsecured kind of interface so you know you will do select statements and this sort of stuff and then of course Amazon EMR Amazonia merrily and it's a great service into the manage Hadoop our manaslu Duke service
and it will give you all the frameworks up to date including presto spark hive Heights baits and and and what is great about the Ammar and it's a kind of an exception let's say because actually amazon EMR it's like most of managed services you don't have access like root access you we don't offer that in most managed services that that's not the case for EMR you can actually get root access on EMR and then you can bootstrap it and you can install your own applications and it's a great way to get used to use you
know the there is a huge ecosystem on the hadoop technologies in general outside of AWS you could integrate those with Amazon EMR ok going to stream analytics so regards the stream analytics there are a couple of options again spark streaming with EMR and there is also impact the kinases family the kinases data analytics that you can configure data analytics kinases data analytics to read from Kinesis data streams and then again with some sort of sequel interface to aggregate or do analytics on the streams and you can always create your own applications using the Kinesis client
library all with lambdas I think there was some similar use case in the previous session about how to do you know to read from lamda notifications and moving to predictive analytics and I won't explain every single service I think there was another session earlier which great session from Neil about predictive analytics the key message here I would like to point out and you've got the option of you know you have those three layers from frameworks platforms and applications when it comes to frameworks is for machine learning practitioners you get the Machine the the images with
those frameworks pre-installed but you have to do the machine learning you have to do you know all the complexity of the hyper parameter tuning traditional machine learning kind of tasks the the platforms it's kind of the helping those machine learning experts to do tasks like you know giving them a Jupiter notebook a familiar interface and then you can use the API say it's make your API to create for instance models and then you can deploy the model so it's one kind of place that you can do all your machine learning tasks for the platforms and
for applications then it's just for for developers who don't want to who want to use machine learning in their application but they don't want to implement machine learning so we have some algorithm that you know they're successful at a amazon.com like comprehend the language a language the natural language processing and you can integrate that with either calling those api's and just a couple of examples before we go to before we move on so when it comes to math analytics think of it as a report that are running monthly weekly or daily and the first service
that you know who comes into mind is Amazon EMR with with tools like hive or or spark interactive analytics think of it like as thyself self-service dashboard something that you know maybe you want to get some answers from the system within seconds so the service is there will be redshift afina or EMR running spark or am i running presto when it comes to stream analytics again EMR you can utilize spark spark streaming or those kinases data analytics services and when it comes to predictive predictive analytics will be either bats or or streaming depends which service
you use and there are so many services there from AWS but you know the key key message I would like to say is like the Amazon change maker really is worth noting that because it's the single single place that will form for machine learning practitioners to to do all the machine learning from one place so I'll skip through those slides quickly because we're gonna discuss about the next topic which is the ETL so ETL quite a lot of discussion around it and sometimes we think like when you do ETL which stands from extract transform load
you might lose value as you change the data but what sum is what is a good years for for ETL is really to prepare the data in a format that is really more suitable to do analytics like partition the data converting from a text format into a parka format or an RC format and there are a couple of options when it comes to ETL I'd like to highlight blue cup a blue ETL blue ETL will allow you to run spark or Python shell and it's kind of a serverless type of category where it kind of
abstracts the service server complexity from you you just define data processing unit and then you can schedule those jobs to run if you want to capture a change data capture from from a database then database migration service also an option gluant is not able to do that or you you can look under the partner solutions especially when it comes to change datasets from change data capture from relational databases ok moving to consumption so when it comes to consumption of the data which is kind of our last step when it comes to consumption I say to
cut two main categories one category is really those business users that they want to make sense of the data and what the service there is really you know applications like visualization visual visualization applications like tableau or we have also an Amazon quick site which are our fully managed business intelligence tool and also Cabana Cabana will allow you to run visualizations in front of Amazon Elastic search and the other categories those data scientists that they want to get an access to an endpoint and they wanted us to you know do statistical analysis using our studio for
instance for those you know Athena for instance of the redshift will have a JDBC you know driver that you can make to your data and you can start pulling data from there or you can just directly query them okay and the next now I'm going to put all of them together and it will start actually discussing some some design patterns for the data so we kind of saw that slide before also notice this ETL arrow there that storage and processing you know can go you can analyze and then box store and then analyze again okay
let's see some some design patterns okay that kind of goes back to the temperature kind of data so on the left hand side you see the hot data meaning the data that are short-lived own data but kind of lose value as they age and data that you typically want to retrieve faster and all the other end is the cold data and the ultra Cola says those archives so as the data arrives you see Keaney sees as storage for the day for the kind of a hot data and then for for analysis spark streaming lambda KCl
applications for interactive analytics redshift to query data from to load data from from RDS or Amazon s3 and then allow you to query data and also Amazon Athena or EMR with spark entresto running over s3 and for the bats analytics hive is a kind of a typical tool running over EMR so the lower those tools are the the the bigger is the response time back to to you okay when it comes to streaming analytics and a stream typically a right to Kinesis Amazon Kinesis data streams and and then you might have the data analytics Kinesis
data analytics to do real-time analytics other options you have there it would be lambda to read from the stream will be a KCl your your library or you could actually do like micro batching as a spark streaming does with Amazon EMR and you could utilize when you could utilize those ml applications so for instance if you want to start do some ml as you process the stream you can utilize those endpoints that are already there for you and you can let's say you identified something and you want to do like a fraud alert then you
can use like SNS to push a notification out to users and then you store the data to s3 which is your data leak for further analytics later on and if you want to capture the data just to have a real-time dashboard or something that will feed the dashboard then is a good practice to actually export like an app state and have another system that could be a database like you know DynamoDB for instance and then have some KPI tables or sort of visualizations in front of the streaming data I'd like also to in that case
now I'd like to introduce like a customer use case which is Hearst which is a media and information company among other things they're managing websites for those magazines and they're using Kinesis data stream and I would like to highlight here the use case that you can have multiple consumers from the same stream so with Kinesis data streams one stream one one is we're using lambdas to pull the data from the stream and then doing the analytics and then push the results of the analyses into DynamoDB and then you expose then those tables they are exposed
as from an API and that could drive dashboard but on the other the other route is with key missus data firehose to capture the streaming event and deliver them into s3 for feather analytics later on moving to Interactive now in baton oolitic kind of design patterns again we start with first stream the fact that you might do interactive in but analytics doesn't mean to say that you don't have streaming data so you could have stream data and again in order to capture them and put them to s3 Kinesis data firehose is a great service but
you also might have files that you can deliver directly to s3 and from Kinesis the data firehose and it's a delivery stream think it has just a pipe that delivers so the supported target is apart from s3 is also redshift for data warehousing or elastic search to do those kind of key bond and our sports or doing analysis and from from to do interactive analytics over s3 great a great tool is Athena as well but also running EMR clusters with presto or or spark for interactive analytics for batch analytics now EMR again is a great
great tool or the glute jobs is also is also possible and with EMR you can have the main the main two frameworks that I'm seeing now is a spark and hive not Pig for instance but primarily spark and hive yet so the top layer is the interactive analytics the bottom layer is the batch analytics ok another customer example that I would like also to highlight is FINRA so FINRA is the financial regulator regulatory authority over in the USA and they're using they're using AWS for for a lot of their analytics and they are actually ingesting
everyday even billions of records daily and data are coming from various sources into you know s3 and from s3 they have multiple systems doing analytics and this is this is back to where we say you can have multiple clusters doing analytics and there's clusters would be specific to the workload that you want to support so they have like for instance redshift for for a kind of predefined queries and they have been different EMR clusters they have multiple EMR classes not just to actually as this diagram you have multiple EMR clusters to do interactive analytics or
serve various analytics to detect fraud etc now finner has strict kind of security requirements and they were utilizing things like a VP see that the virtual private cloud and EMR can be hosted into a V PC or redshift can be hosted into a BBC and they also use encryption at rest and in transit from s3 and of course they're using a cloud trail crowd AWS cloud trail is for audit it will capture every single API call that you do to AWS and then you can have an audit trail for any any action that happened on
your infrastructure and then I'd like also to say like the kind of the final pattern is a data like architecture a reference architecture so you can say here the Amazon s3 is really the center of the data Lake plays a central role I'd like to say also with with glue catalog together because you need to have those metadata as well to be able to query so there are again multiple ways to put data into a straight and if you have a relational databases and you want to have those data change data captures then with database
migration service is a great way the other way is with glue ETL jobs to put the data into s3 and streaming data arriving data firehose is a great way you could use Kinesis data analytics to do maybe analytics and then put them back to stream and then put it back to to s3 from Amazon s3 you can then use lambdas or spark streaming or again those KCl applications to to do a real-time kind of of analytics and then you can load the data to some sort of application state or a materialized view so that you
drive those dashboards or you can have them the batch and interactive layer above your data Lake so that you can explore data in the data like services there when we discuss here you know redshift Athena presto spark hive all these sort of tools for budget and interactive analytics okay to summarize I would like to play back those architectural principles that we discussed in the start of the presentation we starting from building decouple systems and really today we discussed how you know those steps from collection to storage to processing and to analysis and you know what
10 tools you have to use so use the right tool for the right job and then own it and every step remember those kind of options you have and those kind of decisions you have to make we discuss also today about managed services and their service services and what are the options that AWS gives you where possible do leverage you inherit a lot of best practice and you do save a lot of a lot of you know reduce the cost especially admin cost and do prefer immutable data sets immutable logs data lay kind of architecture
that you append to the to the data set rather than upgrade updating and overwriting and of course big cost-conscious big data systems don't necessarily have to be expensive and have big cost with that I'd like to thank you for your attention [Applause]




![Hands-On Power BI Tutorial 📊Beginner to Pro [Full Course] ⚡](https://img.youtube.com/vi/5X5LWcLtkzg/maxresdefault.jpg)






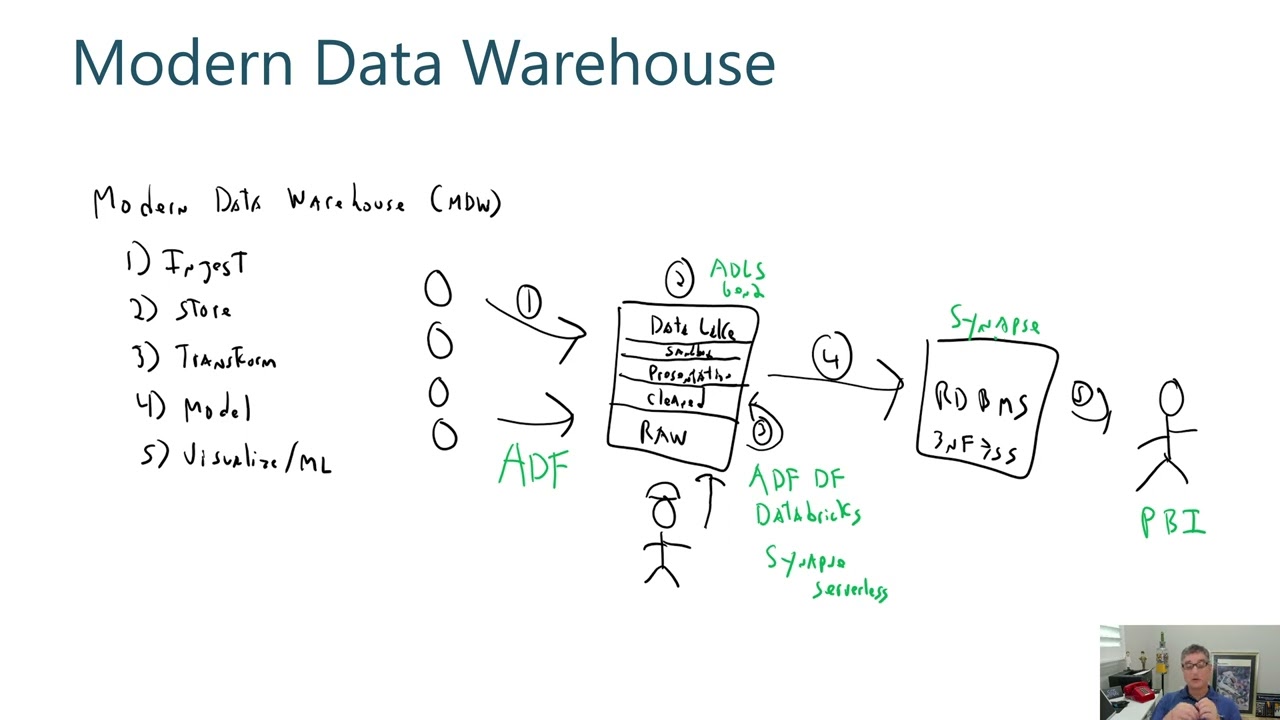
![Azure Data Factory Beginner to Pro Tutorial [Full Course]](https://img.youtube.com/vi/DLmlFlQGQWo/maxresdefault.jpg)







