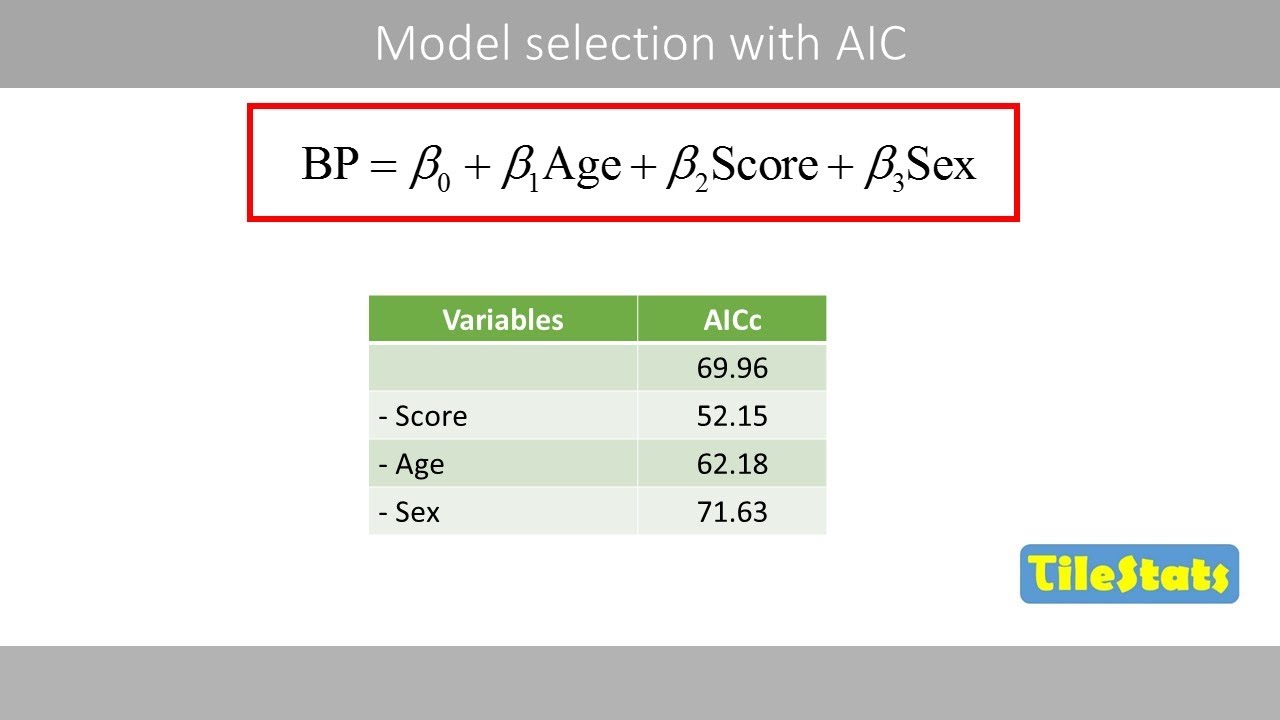
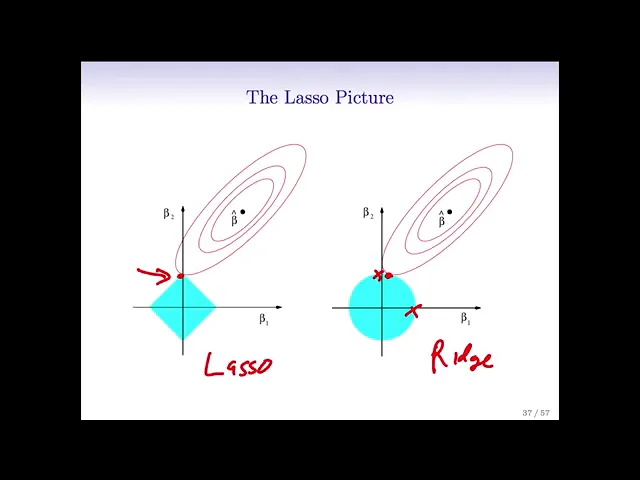
so let's let's talk a bit about um selecting the tuning parameter for ridge regression and the lasso first point is that's important uh the lambda very strongly determines the solution right over a broad spectrum when lambda is zero we get full least squares there's no regularization when labs infinity we get a zero solution in both cases so choosing lambda is extremely important and cross-validation is the weight is is a good technique for doing that note also that we couldn't use the other methods because the d isn't known what other methods am i talking about cp
and aic and bic they all require a number of parameters d and it's not clear what what d is now that's actually something interesting to think about suppose i've well suppose i fit a i've done a ridge regression with i started with 45 variables like in the credit data i've i use a certain lambda let's go back to that just so i can point at something an example here's our ridge example suppose i decide to use the lambda of of a hundred right and i'm here and ask you well what's the d for that model
how many parameters have i fit well if i count the number of parameters the number of non-zero coefficients it's still the the full number 11 right because none of the coefficients are zero so in a sense all of my variables are still there so my my d number of parameters is still is still p 11. but that doesn't somehow seem right right because i've shrunk in the coefficients so they're not fully they're not the number of degrees of freedom isn't it isn't it as large so there's a bit of a subtle point here the number
of parameters is not just how many parameters i've used but how i fit them right so with ridge regression and lasso the shrinkage actually affects the very idea of what we mean by number of parameters so that was a long way of saying that for selecting the tuning parameter for ridge regression and lasso it's really important to use a method that doesn't require the value of d because it's hard to know what d is so cross validation fits the bill perfectly we do exactly what we did for the other methods for for uh for subset
selection for example we divide the data up into k parts we fit the model let's say k equals 10. we fit the model on nine parts say we we apply ridge regression for for a whole range of lambdas for the nine parts and then we we record the error on the tenth part we do that in turn for all ten parts playing the role of the validation set and then we add up all the errors together and we get it we get a cross validation curve as a function of lambda same for the lasso so
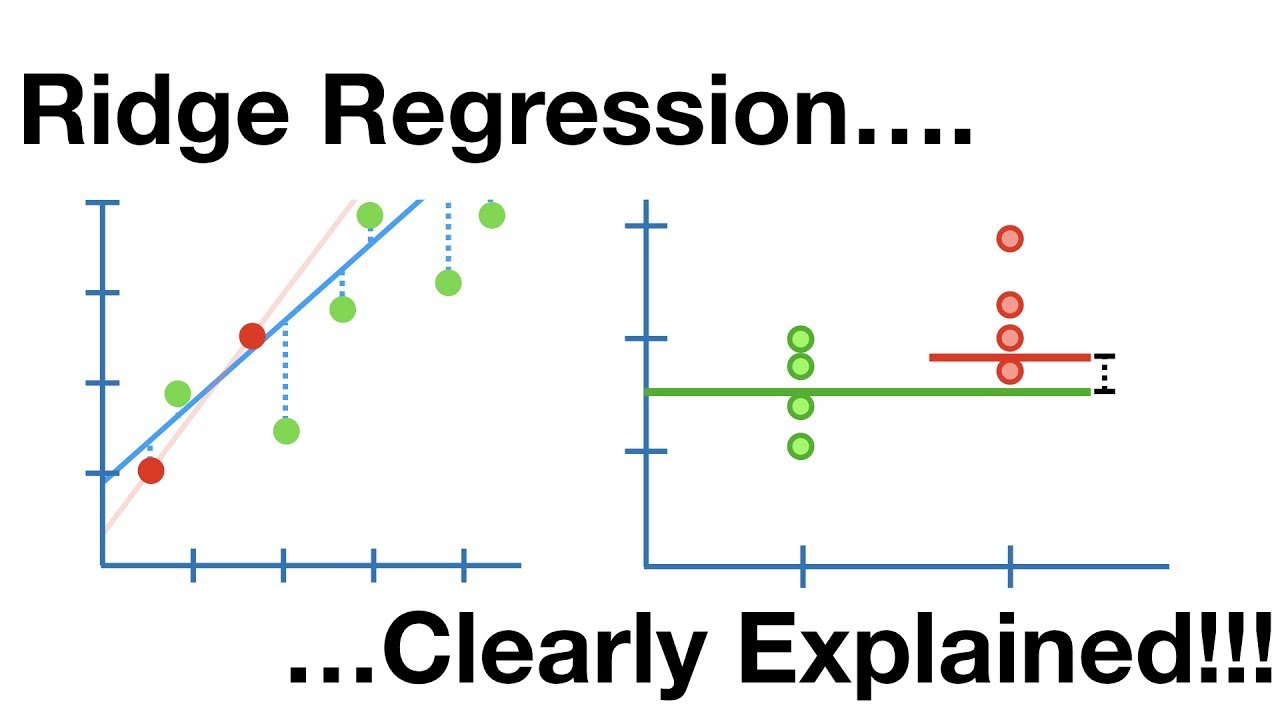
conceptually it's exactly the same as we as crossfire is exactly the same as we applied it in the other in for other methods so let's see what it looks like here for for ridge regression here's here's a result of of cross validation i'm not sure if it's either 5 or 10 full we can check here's cross validation as a function of lambda again remember lambda equals small means essentially the least squares model fully squares over here and lambda equals large means the coefficient has been driven to 0. so this is the cross validation error as
a function of lambda and the minimum is occurring around here around 0.05 here's this here's the same same thing now but we plot plotted as a function of lambda the standardized coefficient so this is here the coefficients for each of the predictors their profiles and we see how they vary as a function of lambda so again over here there's full least squares and here they've been as we move to the right they're shrunken and at the minimum value of the curve this broken line we get a bunch of guys which are essentially zero but not
exactly zero because this is ridge not lasso and then here are the the coefficients for the three active variables um and here's for the this is our this is the simulated data with n equals 50 i think there were two or three truly nonzero coefficients in the population for the last so this is now the the result of cross validation so we've plotted the cross validation error versus the the l1 norm of the lasso solution divided by the l1 norm of the full least square solution that's just to give you a convenient way of scaling
the x axis so that it goes from zero to one right the full least squares estimates give us a value of one and zero estimates of zero give you a value of zero and in between we have the the intermediate lasso solutions so here's the cross validation curve again it's got that u shape that daniella mentioned before and it's minimum is it around here about point point one which is quite severe shrinkage which is good here right because we know that the true model has only three non-zero coefficients and i think it's actually two even
better okay two nonzero coefficients um and we very good because here we seem to pick up exactly two non-zero coefficients the green and the red and the rest are exactly zero so it's in this um made up example it's done exactly the right thing it's from the correct two non-zero features and set everything else exactly equal to zero

![Hands-On Power BI Tutorial 📊Beginner to Pro [Full Course] ⚡](https://img.youtube.com/vi/5X5LWcLtkzg/maxresdefault.jpg)