supported workloads on the databricks lake house platform data warehousing in this video you'll learn how The databricks Lakehouse platform supports the data warehousing workload with databrick SQL and the benefits of data warehousing with the databricks lake house platform traditional data warehouses are no longer able to keep up with the needs businesses in today's world and although organizations have attempted using complicated and complex architectures with data warehouses for bi and data Lakes for AI and ml too many challenges have come to light with those structures to provide value from the data in a timely or cost
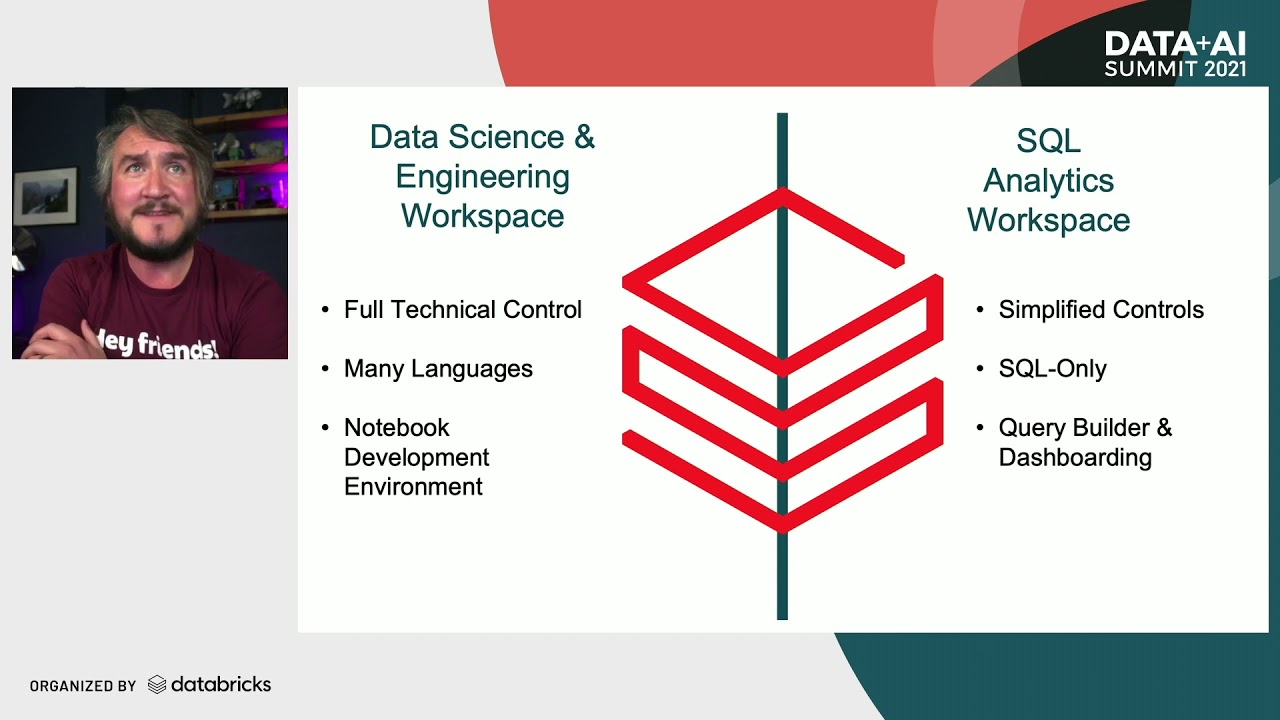
effective manner with the Advent of the data lake house data warehousing workloads finally have a home and the databricks lake house platform provides several features and tools to support this workload especially with databrick SQL when we refer to the data warehousing workload we are referencing SQL analytics and bi tasks such as ingesting transforming and querying data building dashboards and delivering business insights The databricks Lakehouse platform supports these tasks with databrick SQL and databrick serverless SQL data practitioners can complete their data analysis tests all in one location using the SQL and bi tools of their choice
and deliver real-time business insights at the best price for performance organizations can unify all their analytics and simplify their architecture by using databricks SQL some of the key benefits include the best price for performance cloud data warehouses provide greater scale and elasticity needed to handle the rapid influx of new data and the databricks lake house platform offers instant elastic SQL serverless compute that can lower overall infrastructure costs on average between 20 to 40 percent this also reduces or removes the resource management overhead from the workload of the data and platform Administration teams built in governance
supported by Delta Lake the databricks lake house platform allows you to keep a single copy of all your data in your existing data Lakes seamlessly integrated with unity catalog you can discover secure and manage all of your data with fine-grained governance data lineage and standard SQL a rich ecosystem tools for conducting bi on data Lakes are few and far between often requiring data analysts to use developer interfaces or tools designed for data scientists that require specific Knowledge and Skills The databricks Lakehouse platform allows you to work with your preferred tools such as DBT 5tran power
bi or Tableau teams can quickly collaborate across the organization without having to move or transfer data thus leading to the breakdown of silos data engineering teams are challenged with needing to enable data analysts at the speed a business requires data needs to be ingested and processed ahead of time before it can be used for bi The databricks Lakehouse platform provides a complete end-to-end data warehousing solution empowering data teams and business users by providing them with the tools to quickly and effortlessly work with data all in one single platform data engineering in this video you'll learn
why data quality is so important for data engineering how the databricks lighthouse platform supports the data engineering workload what Delta live tables are and how they support data transformation and how databricks workflows support data orchestration in the lake house data is a valuable asset to businesses and it can be collected and brought into the platform or ingested from hundreds of different sources cleaned in various different ways then shared and utilized by multiple different teams for their projects the data engineering workload focuses around ingesting that data transforming it and orchestrating it out to the different data
teams that utilize it for day-to-day insights Innovation and tasks however while the data teams rely on getting the right data at the right time for their analytics data science and machine learning tasks data Engineers often face several challenges trying to meet these needs as data reaches New Heights in volume velocity and variety several of the challenges to the data engineering workload are complex data ingestion methods where data Engineers need to use an always running streaming platform or keep track of which files haven't been ingested yet or having to spend time hand coding error-prone repetitive data
ingestion tasks data engineering principles need to be supported such as Agile development methods isolated development and production environments CI CD and Version Control transformations third-party tools for orchestration increases the operational overhead and decreases the reliability of the system Performance Tuning of pipelines and architectures requires knowledge of the underlying architecture and constantly observing throughput parameters and with platform inconsistencies between the various data warehouse and data Lake providers businesses struggle trying to get multiple products to work in their environments due to different limitations workloads development languages and governance models The databricks Lakehouse platform makes modern data engineering
simple as there is no industry-wide definition of what this means databricks offers the following a unified data platform with managed data ingestion schema detection enforcement and evolution paired with declarative Auto scaling data flow integrated with a lighthouse native orchestrator that supports all kinds of workflows the databricks lighthouse platforms gives data Engineers an end-to-end engineering solution for ingesting transforming processing scheduling and delivering data the complexity of building and managing pipelines and running ETL workloads is automated directly on the data lake so data Engineers can focus on quality and reliability the key capabilities of data engineering on
the lake house include easy data ingestion where petabytes of data can be automatically ingested quickly and reliably for analytics data science and machine learning automated ETL pipelines help reduce development time and effort so data Engineers can focus on implementing business logic and data quality checks in data Pipelines data quality checks can be defined and errors automatically addressed so data teams can confidently trust the information they're using batch and streaming data latency can be tuned with cost controls without data Engineers having to know complex stream processing details automatic recovery from common errors during a pipeline operation
data pipeline observability allows data Engineers to monitor overall data pipeline status and visibly track pipeline health simplified operations for deploying data pipelines to production or for rolling back pipelines and minimizing downtime and lastly scheduling an orchestration is simple clear and reliable for data processing tasks with the ability to run non-interactive tasks as a directed acylic graph on a databricks compute cluster High data quality is the goal of modern data engineering within the lake house so a critical workload for data teams is to build ETL pipelines to ingest transform and orchestrate data for machine learning and
Analytics databricks data engineering enables data teams to unify batch and streaming operations on a simplified architecture provide modern SW engineered data pipeline development and testing build reliable data analytics and AI workflows on any Cloud platform and meet regulatory requirements to maintain world-class governance the lake house provides an end-to-end data engineering and ETL platform that automates the complexity of building and maintaining pipelines and running ETL workloads so data engineers and analysts can focus on quality and reliability to drive valuable insights as data loads into the Delta lake lake house databricks automatically infers the schema and involves
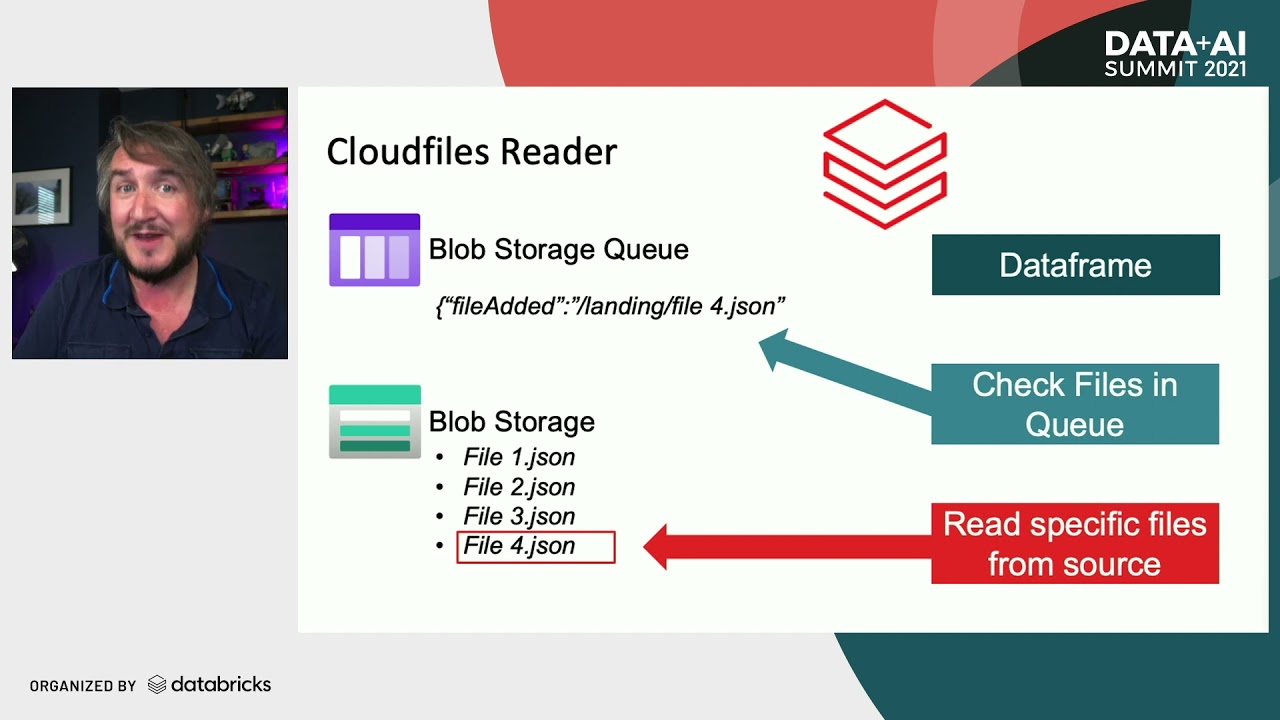
it as the data comes in The databricks Lakehouse platform also provides autoloader and an optimized data ingestion tool that processes new data files as they arrive in the lake house cloud storage it auto detects the schema and enforces it on your data guaranteeing data quality data ingestion for data analysts and analytics Engineers is easy with the copy into SQL command that follows the lake first approach and loads data from a folder into a Delta lake table when run only new files from The Source will be processed data transformation through the use of The Medallion architecture
shown earlier is an established and reliable pattern for improving data quality however implementation is challenging for many data engineering teams attempts to hand code the architecture are hard for data engineers and data pipeline creation is simply impossible for data analysts not able to code with spark structure streaming in Scala or python so even in small scale implementations data engineering time is spent on tooling and managing infrastructure instead of transformations Delta live tables DLT is the first ETL framework that uses a simple declarative approach to building reliable data pipelines DLT automatically Auto scales the infrastructure so
data analysts and Engineers spend less time on tooling and can focus on getting value from their data Engineers treat their data as code and apply software engineering best practices to deploy reliable pipelines at scale DLT fully supports both Python and SQL and is tailored to work with bull streaming and batch workloads by speeding up deployment and automating complex tasks DLT reduces implementation time software engineering principles are applied for data engineering to Foster the idea of treating your data as code and Beyond Transformations there are many things to include in the code that defines your data
such as declaratively Express entire data flows in SQL or python and natively enable modern software engineering best practices such as separate production and development environments testing before deploying using parameterization to deploy and manage environments unit testing and documentation unlike other products DLT supports both batch and streaming workloads in a single API reducing the need for Advanced Data engineering skills orchestrating and managing end-to-end production workflows can be a challenge if a business relies on external or cloud-specific tools that are separate from the lake house platform the structure also reduced the overall reliability of production workloads limits
of observability and increases the complexity in the environment for end users databricks workflows is the first fully managed orchestration service embedded in The databricks Lakehouse platform workflows allows data teams to build reliable data analytics and ML workflows on any Cloud without needing to manage a complex infrastructure databricks workflows allow you to orchestrate data flow pipelines written in DLT or DBT machine learning pipelines and other tasks such as notebooks or python Wheels as a fully managed feature databricks workflows eliminates operational overhead for data Engineers with an easy point-and-click authoring experience all data teams can utilize databricks
workflows while you can create workflows with the UI you can use the databricks workflows API or external orchestrators such as Apache airflow even with an external orchestrator databricks workflows monitoring acts like a window that includes externally triggered workflows Delta live tables is one of the many task types for databricks workflows and is where the managed data flow pipelines with DLT join with the easy point-click authoring experience of databricks workflows this example illustrates an end-to-end workflow where data is streamed from Twitter according to search terms ingested with autoloader using automatic schema detection and then cleaned and
transformed with Delta live tables pipelines written in SQL finally the data is run through a pre-trained Bert language model from hugging face for sentiment analysis of the tweets as you can see different tasks for ingestion cleansing and transforming the data and machine learning are all combined in a single workflow using workflows tasks can be scheduled to provide daily overviews of social media coverage and customer sentiment so needless to say you can orchestrate anything with databricks workflows data streaming in this video you'll learn what streaming data is and how the data streaming workload in the databricks
lake house platform is supported in the last few years we have seen an explosion of real-time streaming data and it is overwhelming traditional data processing platforms that were never designed with streaming data in mind constantly generated by every individual every machine and every organization on the planet businesses require this data to make necessary decisions and keep Pace with their respective industries from transactions to operational systems to customer and employee interactions to third-party data services in the cloud and Internet of Things data from sensors and devices real-time data is everywhere all this real-time data creates new
opportunities to build Innovative real-time applications to detect fraud provide personalized offerings to customers dynamically adjust pricing in real time and predict when a machine or part is going to fail and much more the databricks lake house platform empowers three primary categories of streaming use cases real-time analysis by supplying your data warehouses and bi tools and dashboards with real-time data for instant insights and faster decision making real-time machine learning first with training of machine learning models on real-time data as it's coming in and second with the application of those models to score new events leading to
machine learning inference in real time and real-time applications applications can mean a lot of things so this might be an embedded application for real-time and analytics or machine learning but it also could be as simple as that if then business rules based on streaming data triggering actions in real time further different Industries with have different use cases for streaming data making it highly important for the future of data processing and Analytics for example in a retail environment real-time inventory helps support business activities pricing and supply chain demands in Industrial Automation streaming and predictive analysis help
manufacturers improve production processes and product quality sending alerts and shutting down production automatically if there is an active dip in quality for healthcare streaming patient monitor data can help encourage appropriate medication and Care is provided when is needed without delay for financial institutions real-time analysis of transactions can detect fraud activity and send alerts and by using machine learning algorithms firms can gain Insight from fraud analytics to identify patterns and there are still many more use cases for the value of streaming data to businesses so the top three reasons for using the databricks lake house platform
for streaming data are the ability to build streaming pipelines and applications faster simplified operations from automated tooling and unified governance for real-time and historical data one of the key takeaways is that the databricks lake house platform unlocks many different real-time use cases Beyond those already mentioned giving you the ability to solve really high value problems for your business the databricks lighthouse platform has the capability to support the data streaming workload to provide real-time analytics machine learning and applications all in one platform data streaming helps business teams to make quicker better decisions development teams to deliver
real-time and differentiated experiences and operations teams to detect and react to operational issues in real time data streaming is one of the fastest growing workloads for the lake house architecture and is the future of all data processing data science and machine learning in this video you'll learn about the challenges businesses face in attempting to harness machine learning and AI Endeavors and how the databricks lake house platform supports the data science and machine learning workload for successful machine learning and AI projects businesses know machine learning and AI have a myriad of benefits but realizing these benefits
proves challenging for businesses brave enough to attempt machine learning and AI several of the challenges businesses face include siled and disparate Data Systems complex experimentation environments and getting models served to a production setting additionally businesses have multiple concerns when it comes to using machine learning such as there are so many tools available covering each phase of the ml lifecycle but unlike traditional software development machine learning development benefits from trying multiple tools available to see if results improve experiments are hard to track as there are so many parameters tracking the parameters code and data that went
into producing a model can be cumbersome reproducing results is difficult especially without detailed tracking and when you want to release your trained code for use in production or even debug a problem reproducing past steps of the ml workflow is key and it's hard to deploy ml especially when there are so many available tools for moving a model to production and as there is no standard way to move models there is always a new risk with each new deployment The databricks Lakehouse platform provides a space for data scientists ml engineers and developers to use data and
derive Innovative insights build powerful predictive models all within the space of machine learning and AI with data all in one location data scientists can perform exploratory data analysis easily in the notebook style experience with support from multiple languages and built-in visualizations and dashboards code can be shared securely and confidently for co-authoring and commenting with automatic versioning git Integrations and role-based access controls from data ingestion to model training and tuning all the way through to production model serving and versioning the databricks like house platform brings the tools you need to simplify those tasks the databricks machine
learning runtimes help you get started with experimenting and are optimized and pre-configured with the most popular libraries with GPU support for distributed training and Hardware acceleration you can scale as needed ml flow is an open source machine learning platform created by databricks and is managed service within the databricks Lakehouse platform with ML flow you can track model training sessions from within the runtimes and package and reuse models with ease a feature store is available allowing you to create new features and reuse existing ones for training and scoring machine learning models automl allows both beginner and
experienced data scientists to get started with low to no code experimentation automl points to your data set automatically trains models and tunes hyper parameters to save you time in the machine learning process additionally automl reports back metrics related to the results as well as the code necessary to repeat the training customize to your data set this glass box feature means you don't need to feel trapped by vendor lock-in the databricks lake house platform provides a world-class experience for model versioning monitoring and serving within the same platform used to generate the models themselves lineage and governance
is tracked throughout the entire ml lifecycle so Regulatory Compliance and security concerns can be reduced saving costs down the road with tools like mlflow and automl and built on top of Delta Lake the databricks lake house platform makes it easy for data scientists to experiment create models and serve them to production and monitor them all in one place