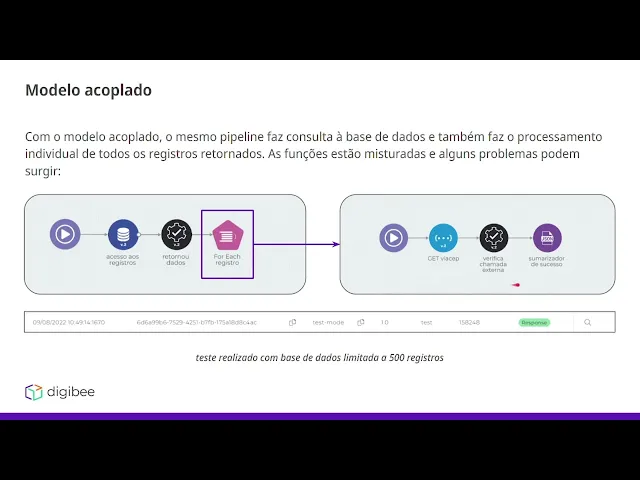
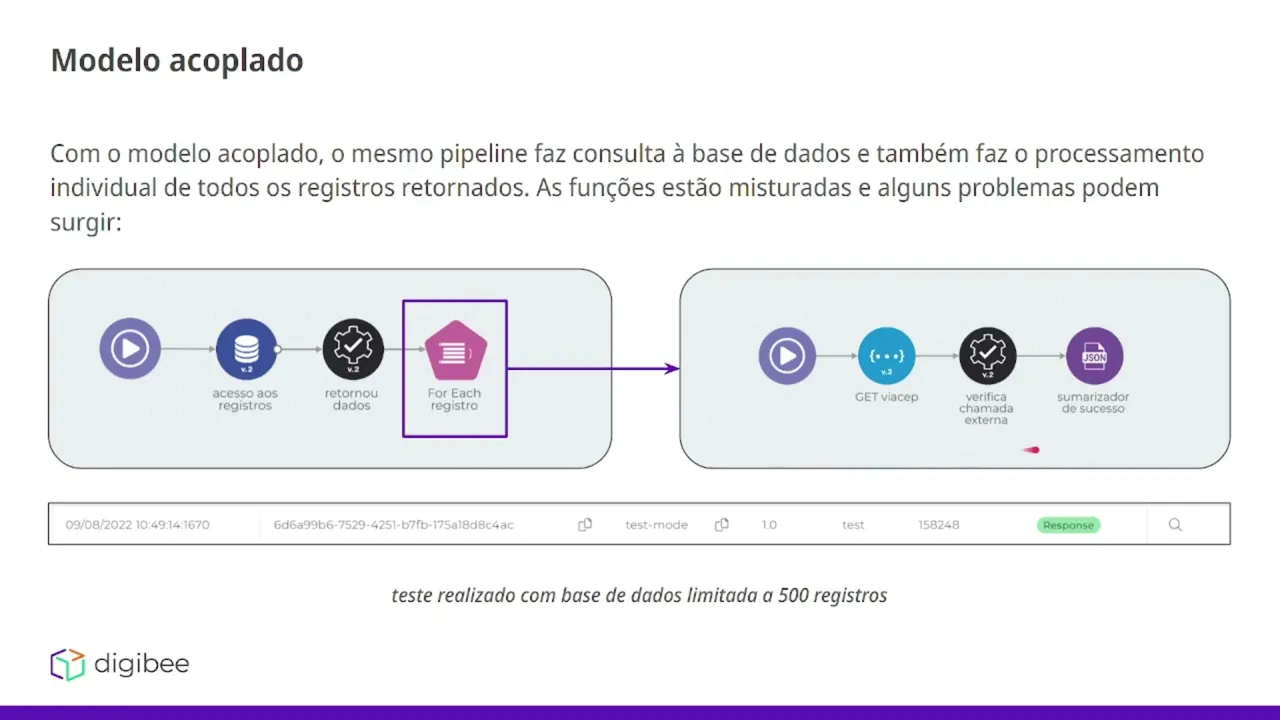
Olá esse é o bootcamp integration developer estamos na etapa de arquitetura e padrões de projeto 1 nesse vídeo falaremos sobre desacoplamento o desacoplamento ele pode ser resumido em separação de responsabilidades específicas e para entender melhor sobre esse conceito vamos ver os exemplos a seguir vamos supor que estamos observando os modelos de um aplicativo de banco para que um banco funcione ele precisa de diversos serviços que estão acoplados por exemplo preciso cadastrar novos usuários preciso fazer transações de cartão de crédito pagar contas preciso também analisar as transações de clientes então existem diversos serviços que não necessariamente tem alguma relação entre si se todos esses serviços estivessem em um único local todo aglomerado e Misturado qualquer tipo de alteração em cada um desses microsserviços teria que ser alterado em todo o projeto a ao mesmo tempo isso é um problema porque caso alguma parte específica precise de manutenção ou precise de uma melhora todo o processo vai ter que parar enquanto há essa manutenção específica para entender melhor sobre esse esse exemplo vamos pegar um modelo acoplado e um modelo desacoplado diretamente na plataforma Então vamos aplicar esse conceito diretamente nos pipelines então com modelo acoplado o mesmo pipeline faz consulta a base de dados e também faz o processamento individual de os registros retornados as funções estão misturadas e alguns problemas podem surgir então no caso seguinte temos um pipeline que possui uma base de dados que tá sendo consultada e para cada dado retornado dessa base nós temos um forit que faz um processamento e o processamento é apenas fazer uma requisição web e logo depois fazer um sumarizados nesse caso aqui nós limitamos a base de dados a 500 registros então aqui dentro do nosso forit 500 chamadas hash seriam feitas em uma única execução qu a gente olha para essa execução temos aqui o tempo de execução então para 500 registros a execução desse pipeline Demorou 2 minutos e 38 segundos isso pode se tornar um problema com o aumento da nossa base de registros aqui caso tivéssemos por exemplo 3. 000 ou 3. 500 registros já seria o suficiente para disparar o erro de timeout no pipeline o erro de timeout ocorre quando a execução de um pipeline Independente de qual seja ultrapassa 15 minutos a plataforma tem uma limitação de execução que é de 15 minutos após esse período todos os pipelines resultarão em timeout então Aqui estamos limitados à volumetria para que o fluxo dê certo se a gente olhar para um caso de pipeline desacoplado esse problema resolvido então com o modelo desacoplado o único pipeline será responsável por fazer a consulta a base de dados e outro será responsável pelo processamento individual por execução de cada registro Então temos aqui um pipeline responsável pela consulta dos registros e publicação de eventos e vemos que a lógica é a mesma temos uma base de dados e para cada registro retornado temos um forit que vai fazer o seguinte aqui substituímos o processamento com uma chamada hash por um evento event publisher que vamos publicar um evento de processamento que vai ser encaminhado pro event broker e O Event broker vai entregar essa mensagem para esse pipeline que é um pipeline responsável pelo processamento de eventos publicados de processamento aqui temos a chamada hash e temos os outros conectores que tínhamos anteriormente apenas de fazer essa mudança o pipeline de consulta de registros saiu de 2 minutos 38 segundos para apenas 3.
3 3 segundos publicando 500 registros agora os pipelines de processamento né uma vez que eles serão publicados e serão ativados 500 vezes eles demoraram 51 segundos para processar 500 registros aqui tivemos uma melhora de mais de 100% na velocidade apenas aplicando o desacoplamento por conta disso temos diversas vantagens e diversos benefícios em fazer esse desacoplamento como por exemplo a manutenção facilitada se mantemos pipelines desacoplados e precisamos fazer alguma alteração em algum processo específico nós podemos fazer essa substituição ou alteração de maneira que os outros serviços não sejam alterados Lembra no pipeline desacoplado em que temos a consulta e o processamento no mesmo lugar caso precisássemos mudar o processamento por exemplo a consulta também para de funcionar já na maneira desacoplada nós podemos fazer uma mudança no processamento enquanto a consulta continua publicando eventos continua funcionando normalmente Pode dar andamento à nossa aplicação um outro exemplo é que uma vez que agora está desacoplado caso a gente precise de um redimensionamento por exemplo de se eu tem um aumento de volumetria para 3000 3500 registros isso não será um problema primeiro porque está desacoplado e segundo porque caso precisássemos poderíamos fazer o redimensionamento aumentando a réplica ou aumentando o poder comput ial do pipeline de maneira individual fazendo então essa escala granular fazendo uma comparação o método acoplado resultou em uma execução de 158. 000 msos que é o equivalente a aproximadamente 2 minutos e 38 segundos e o método desacoplado resultou em uma execução de 3.