welcome to the lecture series on reinforcement learning and the Brain in this short video we will look again at policy gradient with LGBT traces so the aim is to close the loop between brain and algorithms between things we know about three-factor learning rules in the brain and algorithms of the style of advantaged ectocratic with eligibility traces ineligibility with eligibility traces in policy gradient we end actor critic we run over an episode observe State action reward we update the eligibility Trace according to these rules and then there are in fact two variants for standard reinforced with
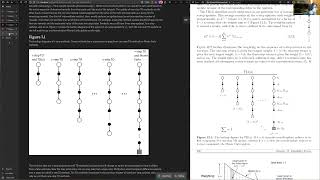
eligibility traces the update of the weights is proportional to the reward for the actor critic with eligibility traces and more specifically specifically the advantage actor critic it is the TD error that's the only difference so we have looked in the exercise at a situation where we have a state space position X which is encoded by radial basis functions and so these neurons here encode the state and these neurons up there encode the actions and the policy is a soft marks of the weighted inputs the states are encoded by the radial basis functions suppose the reward
is here on the right hand side then the way this works is the red is at some position and at this position eligibility traces will be set so the red is here we calculate this we see the update and this is what comes out of the exercise is proportional to a presynaptic factor and proportional to the activity of the postsynaptic neuron so if both neurons are active together then an eligibility Trace is set for this connection and now the next step is the red moves forward and it finds the reward and in this case the
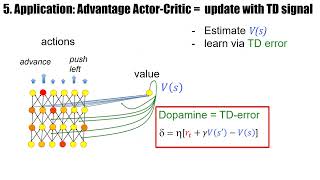
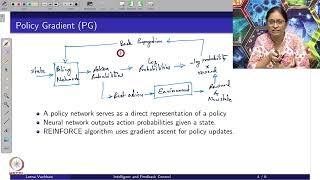
reward leads to a success signal and the marked synapse is going to be changed okay so we have three factors we have the success factor which comes in Via this Delta and we have the two factors pre and post so policy gradient with one hidden layer and the linear softmax readout yields a three Factor rule the eligibility Trace is set by The Joint activity of pre and post-synaptic neurons the update happens proportional to the eligibility trace and the third factor and the third Factor can be either reward or TD error in which case we are
indicating consideration of the advantage Act of critic now just remember the presynaptic neuron here represents the state and the posts nothing neuron the action so it's a true online rule we run over different states it could be implemented in biology because we have three Factor rules it can also be implemented in parallel asynchronous hardware and it's really a non-phon Neumann compute Paradigm no centralized clock no systematic program one step after the other actions are just taking states are encountered and you always update according to these rules so we have made the link between algorithms and
the brain and between algorithms and sort of a brain style compute Paradigm that is non-phonomous if it's implemented in a very distributed fashion the only difference between the two three Factor rules from reinforce and from the advantage actor critic is the way the reward is integrated so the question is in the brain are updates proportional to the reward or are they proportional to the TD error Delta and the claim is the learning rule of the advantage act to creating this eligibility phrases is consistent with a brain like three-factor rule and the condition is that the
brain is able to broadcast a TD signal two things broadcast widespread and second temple difference signal Temple different signal is reward and then the difference of two values