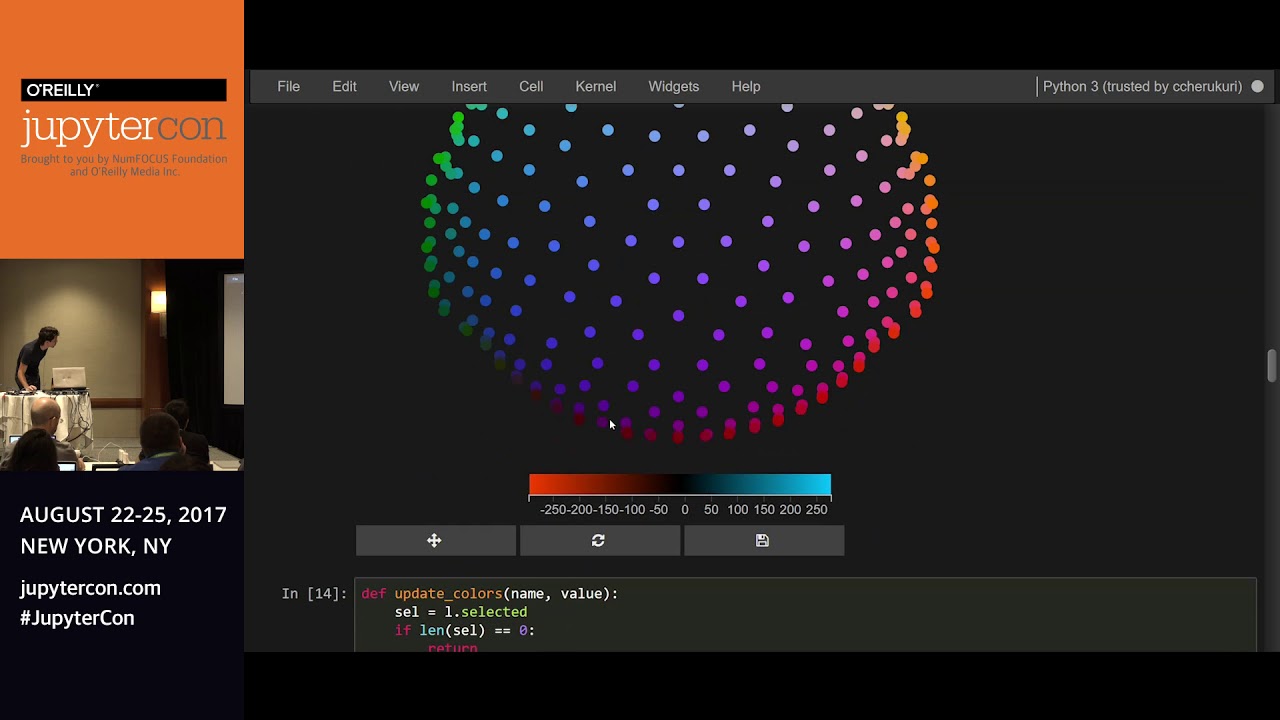
hello professor and everyone first of all we would like to thank our professor thank you for giving us an opportunity to be in his research class uh for our final research project we have chosen this uh detecting fake news on social media as our topic and this is a team project so as a teammate i have juris joes and sanjin already in my team and now let's talk about our project so in our project we have this uh we have covered this content uh we have included the introduction and major problems of this um fake news the purpose of creating this application and architecture methodologies technique we have used result we got and the conclusion and we have also included all the reference that we use for our project so as we all know that fake news exists way before from social media but it multifolds when social media was introduced fake news is a news uh designed to daily uh spread hoax propaganda and disinformation fake news uh story is usually spread through social media sites like facebook twitter etc uh as we all know that uh social media is used for news reading nowadays and before in the past only professional used to collect the news and publish it but nowadays anyone can collect the news and publish therefore the authentic uh authenticity of the news is difficult to know and uh it is difficult uh to know because uh there are also increasing number of fraud website in the internet which increases the number of fake news articles day by day as as compared to the past and uh peoples are profiting by the clickbaits and publishing fake news and online more clicks contributes to more money for content publisher so the major problem is by clicking on the clickbait user are lead to a page that contains the false information and false news and information influence the people's perceptions therefore the rise of this fake news has become a global problem that even a major tech companies like facebook and google are struggling to solve it can be difficult to determine whether a text is factual without additional context and human judgment so the purpose of our project is to develop a method for detecting and classifying the fake news stories using natural language processing and the main goal is to identify the fake news which is a classic text classification issue we gathered our data pre-process the text and translated our articles into a supervised model features our goal is to develop a model that classifies a given news article as either a fake or true so the daily mail their limitation we have faced is like our system does not guarantee 100 accuracy the system is unable to test the data that is uh unrelated to the training data set and uh there are usually two types of uh fake news like visual based and linguistic based type visual based are like photoshop images and videos which are posted in the social medias and linguistic days are mainly the manipulation of text and string content this issue is with blog news or emails now my friend sanjina will continue hello all in this project we propose a machine learning model to identify whether a news article is fake or not based on its content we used nlp to detect the fake news there are several attempts made to use artificial intelligence technologies specifically machine learning techniques and nlp to detect fake news and stop it from spreading as human beings we can read a sentence or a paragraph we can interpret the words with the whole document and understand the context given today's volume of news it is possible to teach a computer how to read and understand the difference between real news and fake news using nlp in this project the main building blocks are data set and machine learning algorithms we got our data set from kegel website where data is published for research purposes our data set consists of seven and seven thousand seven ninety six rows and four columns the first column is unique id the second column title give means the headline of the news and the third column text is the description of the news our data is pre-labeled with fake and real news as fake and real so we have two classes to our data fake and real and initially we use the 30 percent of the data for training the machine learning model and remaining data to test a model that is trained um now coming to the workflow of our model our machine learning process consists of the following steps once first we load the data set once the data set is loaded we need to pre-process the data set by cleaning the text applying some tokenization techniques removing stop words and drop the duplicate words so once we have this set of pre-processed data articles we need to represent them into a numeric format we call this step as vectorization where we extract the future next step is to build a classification model uh from the extracted data and test and evaluate the model in order to predict the outputs of the unlabeled data so to analyze the mod to analyze and model the text after it has been extracted it must first be converted to features techniques we use to convert the data to a number format is tf idf validity of idf vectorization which is term frequency and identity term frequency we use the classifiers like passive aggressive classifier and k-nearest neighbor classifier to train and test the data train the model needs to be tested and evaluated for accuracy on data that it was trained on so after training the data we calculate the accuracy and we compare the accuracy of the two models uh k n and p a to select the best classifier for building our model according to the accuracy of the classifier while predicting on the tester data so we verified accuracy of our two models using confusion matrix next our friend joris will explain the techniques we used in our model here we ah hi professor uh here we used the techniques uh tf idf uh tf is the basis for the pa algorithm uh that is a inverse document frequency that uh tfidf uh the uh the the accuracy is showing here tp plus tn divided by tp plus that's the true positive and true negative uh that that means that that's a real news and compared to that the total how many uh news is coming that is the accuracy calculation the basic method and after that we already discussed this tf idf this is a how many real uses in a total number of documents per document it will calculate first and after that it will multiply with an inverse frequency that is uh the how many total number of documents are there so that it will remove all the stop words um i mean the commonly used english words and all on that way it will calculate and it will give the value that is that value is the basis of the algorithm and this k n algorithm uh is the k nearest neighbor this algorithm is better in the case of a small data set so the pa is better for the large dataset but canon is better for the small dataset that this pa we already uh uh discussed um this is uh uh in our uh after our execution also we saw this is a better algorithm for our case also because that is a dataset is using so in the real-time application of our project like a twitter they are finding the fake news they are using this kind of algorithm passive aggressive algorithm so this is an online learning algorithm you can say and the next slide the result is that yes uh this result we will show you directly uh this is a and this is a result we are getting so we use less number of our data we have the p algorithm um but that but the k n algorithm is better in the case of less number of data but the algorithm is working very better when we have a large number of data uh this is uh so we have an uh confusion matrix also uh after our result execution and on that way you can confirm our result so um my friend sanjana will give the details of the code by sanjira so we wrote our code in python language first we started by import importing num all the libraries such as numpy mlx stand train split pf id of vectorizer confusion matrix accuracy score nearest neighbor classifier and passive aggressive classifier the first step is to load the uh csv file using the panda function method read csv so after loading the data we need to reprocess the data i mean we need to remove first we remove the label from our data set that is fake or true then we need to divide the data to training data and testing data this is the syntax of dividing the data to training and testing so after that we have to convert these um our data set is in the form of word we have to convert it into number format so for that we use this tf idf vectorization and we converted the word to quote number format as shown in the result here we converted each and every word in the document to the number format using dfi ref so after converting that we classified the future extracted data using knn and pa classifiers that will be explained by juries hi browser um this is the execution of our um of our uh project actually um we we have the we are splitting the our data uh to training data and test data so we are testing our result with the with our total data we have a total of nearly 8 000 rows so this 0. 99 means 99 percent is using for the accuracy testing uh i mean the training how many how many data is coming how much 99 percentage so i can run this and we can see the result here um is showing uh the i mean when the 99 percent test data is coming the training data is only one person day so it's a very small amount of data in that case the pa classifier has only 83 of accuracy but the canon cluster is better 75 or percentage it has accuracy so i am just changing this to sorry yeah 0. 01 in that case uh one percentage only will be test size but the 99 page specially for the training data so uh that is a lot of data for the training and the accuracy is increased uh so the pa classifier is better on large data but the k n classifier that is not better i mean really it was 75 now it's decreased to 65 percentage and this is the confusion matrix it is showing and this is our data and this is a splitting of the data and and we are we are taking the uh vectorizer uh i mean the common weights stopwatch english softwares we have we are not using so that we are giving here and after that uh the test data we are transforming and that is where we are printing uh we can see the passive aggressive classifier result is taking like this and this is stored into pa classifier and that prediction we are using here as a score so this is we are seeing the result uh and that you and the confusion matrix also it's printing that we can see here and even uh this is also we can use instead of the excel file we can use as once and one sentence of news like this one and it will show whether this is correct or not here you can see these users are showing us fake according to pa and canon class algorithm and about the uh confusion matrix my friend dava will thank explain so like here we can see uh this plot uh figure like here like whenever we are using the data um 0.
99 percent uh like we are getting this 2445 as a true uh true positive uh and uh 686 as a true false negative and uh 2758 as a true negative and 383 as a true positive so here uh it displays the effect of a classifier here we can see the relationship between the label and classifiers performance and whenever we were using uh using only 0. 01 percent which is 80 rows only then we get this confusion matrix where 37 is a true positive and uh 25 is true negative and one is true negative uh false negative and one is true false positive so now let me show you my powerpoint screen so the yeah so the result we have written here like when our training uh data size is approximately 80 rows the pa classifier has the higher accuracy and k n has only 75 percent so pa classifier is best for uh detecting our fake news and so this is the screenshot of our confusion matrix so uh in conclusion we came that when we use a df-idf vectorizer and have implemented the fake news detection model using k n and uh pa classifier pa algorithm accuracy increases when the training data increases and k n algorithm accuracy decreases proportionally to the training data uh decreases and when the trading data size is approximately 80 percent rose the pa classifier has higher accuracy of 83 percent and k n has 75. 5 percent but when the trading data size is 7900 rows the pa classifier accuracy is 98.
44 and the knn is 65.








![Fake review detection : framework, challenges and future By Vinodhini Ranganathan [MLDS2020]](https://img.youtube.com/vi/ooRAKphG8ic/maxresdefault.jpg)