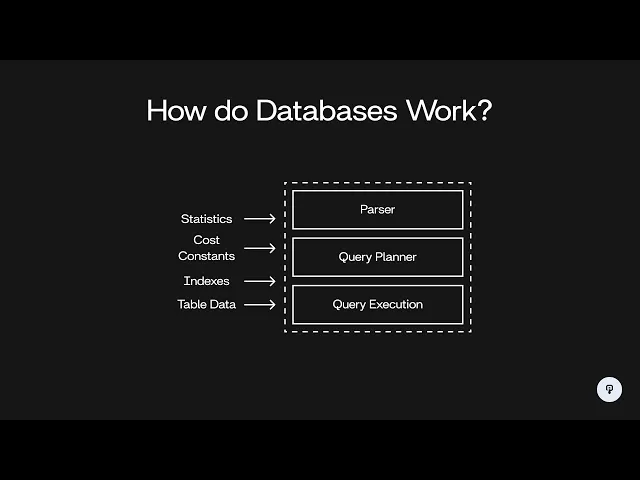
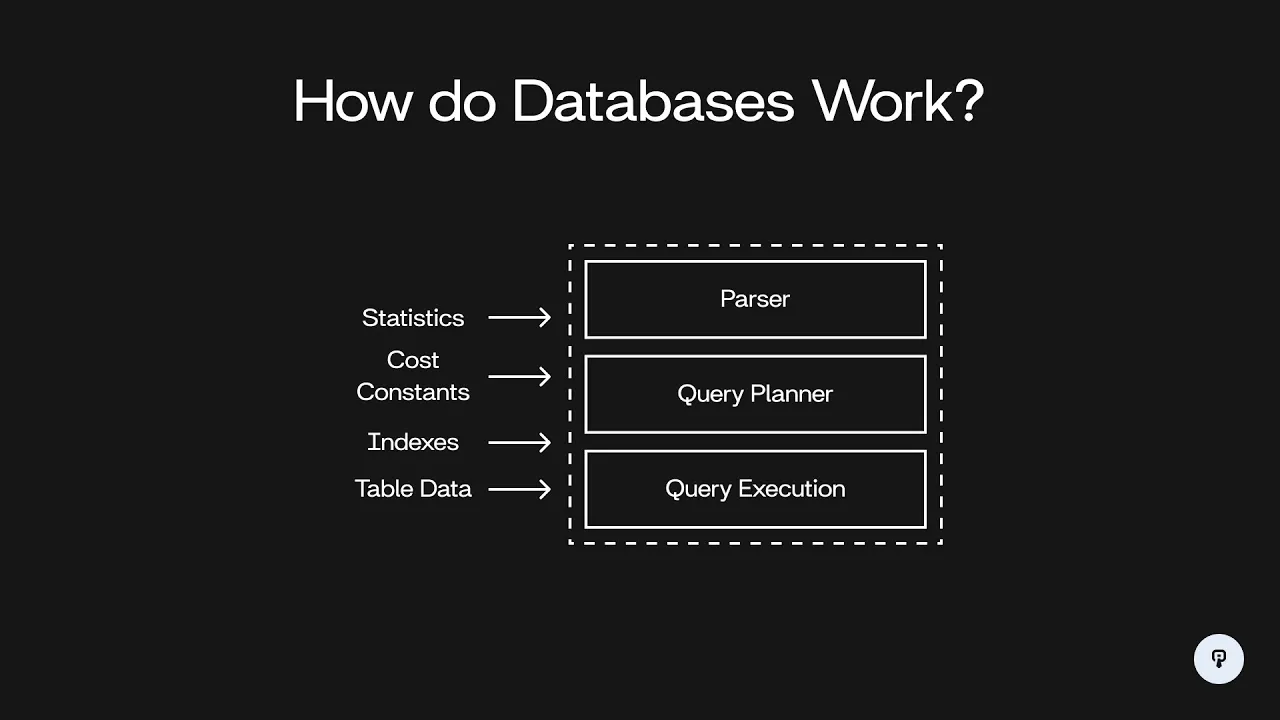
so in this video we're going to be talking about databases specifically how databases parse queries and figure out the most efficient way to actually get the data that you're trying to access from them so to start let's talk about what a database actually is so at its most basic level a database is just something that takes in a query which is going to be some statement usually written in SQL that tells the database what you want to get out of it and then the database is going to do something in the back end and it's going to figure out how to actually get that data and return to you some results and those results are usually going to look like a table where you have rows and Columns of data so this seems pretty simple there's actually a lot of complexity that goes on in the back end to for the database to actually figure out how to execute the query that you give it the main reason for this is that SQL is a declarative language it's describing what data you want to get out of the database not how to actually get that data so if we think about a SQL query it's going to look something like this we have select something from table maybe we want to join on another table and maybe we want to filter on some condition all we're doing is telling it what data we want to access we're telling it that we want these columns we're telling it that we want only data with this condition but we're not telling it exactly how we want to get that data so this is going to be a declarative statement on the other hand we have imperative statements like this where we're telling the database that we want to scan the table for xyzal 1 23 using a hash index and then we're telling it that we want to use a nested Loop join to join on the other table and then after we do both of those things we want to select the two columns A and B the difference between this declarative statement and this imperative statement is that with the imperative statement we're giving specific steps things we want to execute in a certain order and we're telling it exactly how to perform each of those steps whereas with our declarative statement we're leaving it up to the database to choose those things as somebody who's querying a database it's certainly a lot easier if we have this declarative way of talking to our database where we're just telling it what data we want to get out and not how exactly we want it to get that data but internally the database is going to have to translate this declarative statement into something that tells it exactly what to do if you want to learn more about things like hash indexes and join algorithms and how to set up a database in such a way that it can be really efficient I'd recommend that you check out interview pen. com where we have a full series of videos on database fundamentals that'll teach you some of these Concepts all right so let's dive into the process that the database uses to figure out how to execute your query the process generally consists of three main steps we start with a SQL query and then we have a parser that parses that query ensures that it's grammatically correct according to SQL standards and translates that into some sort of data structure that's easier for the database to use in subsequent steps then we have the query planner which is where a lot of the optimization of your query happens and this is going to be the part that goes from that declarative SQL statement to something that tells the database exactly what to do and then finally we have the query execution part which is actually taking that plan of how to execute your query and running that against the actual data that's stored in the database and finally the output of that is your actual result that you get back from the database so now let's dive into each one of these parts starting with the parser the input to the parser is just the sequel statement so let's say we have select AB from table where XYZ equal 3 and ABC equals 5 it's hard for the database to operate on this raw text here so we want to put it into some sort of data structure that is easier for our database to use we're going to use a tree for this and it's going to look something like this so our base query consists of a select a from and a where clause and our select contains these two expressions A and B our from contains the name of the table and our wear Clause consists first of an and which combines two sub expressions and each of those sub Expressions is an equality operation on two other expressions in this case xyzal 3 and abcal 5 this is the same way that most programming languages are parsed we create this parse tree and when our database is actually looking at that expression it can then evaluate this tree recursively instead of having to actually parse the raw text once our parser is done it's time to move on to the query planner the query planner is going to take in this parse tree and what it's going to Output is a different tree that contains the specific steps that the database is going to execute to run that query so for example those steps could consist of doing a join filtering a table scanning a table using an index Etc it turns out there's actually a lot of different ways that most queries can be executed there's a lot of different plans that we could come up with to execute a certain query and each one will take more or less time than others the job of the query planner is to figure out which plan is most effective given certain characteristics of the database let's take a look at an example and see what this looks like so let's say we have a query that looks like this we're selecting from the table a joining it on the table B and then we're filtering on a condition for each one of those tables one approach that we could take to this is to scan both of the tables then filter each table in the relevant condition and then join the two results together another option that we have would be to scan each table and then join them first and then perform both of our filter operations after the join again the job of the query planner is to figure out the cost of each of these operations and then decide which of the operations has the lowest total cost which will be the fastest to execute in order to do this we have to look at some statistics about our data so for example our database is going to keep track of the size of each table so let's say A and B are both 100 rows we now know that we have to scan 100 rows in each of these operations and we can also look at the distribution of each of these columns so let's say there's 10 unique values for y and 10 unique values for Z if we have 100 rows and there's 10 possible values it's pretty likely that we're going to end up with 10 rows in our result after this filter operation then once that's done we can join them together and our operation is done for our second option here where we're doing our filter after the fact our join is actually going to be combining all 100 rows of both of these scan operations we can do a similar thing here where we're looking at the distribution of the values of the columns that are being joined together let's say that we estimate the result we have 300 rows once we do our first filter we end up with 100 rows and once we do our second filter we end up with 10 rows so we looking at these two operations we can see that the one on the left is probably going to be better in this case our hash join only has to operate on 10 records each instead of 100 records each in a second option and our filters only have to operate on a maximum of 100 records whereas with the second option this first filter has to deal with 300 records and the second one has to deal with 100 records so a lot of our operations are going to execute a lot faster on this leftmost plan the query planner also has to take into consideration the different algorithms that can be utilized for a certain operation so for example a hash joint is very efficient in terms of its runtime complexity but it can be very memory intensive this is because it actually has to generate generate a hash table in memory containing every single record in one side of the joint operation if we were in a very memory constrained situation or we had a very large table that we were joining it might not be possible to use a hash join and we might want to fall back to some other type of join algorithm such as a nested Loop now this process becomes a whole lot more interesting when we start to introduce indexes into our database so let's say now that we have the same query as before but now we also have an index on a. y and b.
x so these indexes can be used to increase the speed of this a. yal 5 filter and it can also be used to speed up this join that depends on the b. x field so on the right here we have our plan from the previous slide and on the left here we have a plan that utilizes these indexes so instead of scanning a and then filtering for yal 5 we can instead do an index scan that'll super efficiently find all of the records where a.
y equals 5 and then instead of doing a hash join to merge these two tables together we can do a loop join that uses the index on table B to merge the two together what this Loop joint is essentially going to do is Loop over every single record that we get from table a and then use the index to quickly find the corresponding record in table B so this is clearly a much faster operation and it's therefore going to have a lower cost we only have to deal with the 10 records that we get out of this index instead of having to scan the entire a table and when we're doing our join we don't have to deal with this memory intensive operation and we don't have to scan through both tables it's worth noting however that this Loop join using the index is going to result in random reads from our dis ideally we'd have this b. x index cached in memory so this would mean that random versus sequential reads isn't super important however if the data was stored on disk and we had to fetch data randomly from disk to get the corresponding records in B from the index this could make this Loop join actually take much longer than the hash join even though it's using this index as a performance optimization things like this are configured using constants in the database so there'd be a constant for how long a sequential read takes and how long a random read takes as a database administrator if we know that we have plenty of available memory and most data is going to be cached we can set those constants to be similar so the database will prioritize using these types of algorithms that result in random reads so let's go back and look at a quick overview of our query planner so again we're taking in a parse tree that comes from our parser and that's just an efficient data structure for storing our SQL query our query planner is going to take in things like table statistics so for example the distribution of a certain column and the number of Records in a certain table it's also going to take in those cost constants that are things like how long a random read takes and how long a sequential read takes and it's going to take in information about available indexes that the query can utilize to make itself faster the query planner is going to come up with a bunch of plans and evaluate the cost for each of them and whichever one has the lowest cost is what it'll output as the query plan so the final step here is query execution so that's going to take in that query plan that our query planner came up with and it's going to take in the actual table data right the actual data that is stored in the tables that we're querying and it's going to run that query plan and output the result to the user so we went over some very basic examples of queries that our query planner could come up with but there's a lot of complexity that's involved in real database systems that makes this a lot more complex in a real world system we have to worry about caching and other per performance optimization that the database makes at a low level to ensure that it's very efficient for a variety of systems if you're curious to learn more about these topics and about more advanced techniques that the database uses to optimize queries you should check out the documentation for different database systems such as postgress these systems often have very extensive docs that'll tell you about a lot of the intricacies of how that database system works so if you're curious to learn more you should definitely check those out if you enjoyed this video you can find more content like this on interview pen. com we have tons of more in-depth system design and data structures and algorithms content for any skill level along with a full coding environment and an AI teaching assistant you can also join our Discord where we're always available to answer any questions you might have if you were a friend wants to master the fundamentals of software engineering check us out at interview pen.